 電子發燒友App
電子發燒友App


背景
在復雜的分布式系統中,往往需要對大量的數據進行唯一標識,比如在對一個訂單表進行了分庫分表操作,這時候數據庫的自增ID顯然不能作為某個訂單的唯一標識。除此之外還有其他分布式場景對分布式ID的一些要求:
趨勢遞增: 由于多數RDBMS使用B-tree的數據結構來存儲索引數據,在主鍵的選擇上面我們應該盡量使用有序的主鍵保證寫入性能。
單調遞增: 保證下一個ID一定大于上一個ID,例如排序需求。
信息安全: 如果ID是連續的,惡意用戶的扒取工作就非常容易做了;如果是訂單號就更危險了,可以直接知道我們的單量。所以在一些應用場景下,會需要ID無規則、不規則。
就不同的場景及要求,市面誕生了很多分布式ID解決方案。本文針對多個分布式ID解決方案進行介紹,包括其優缺點、使用場景及代碼示例。
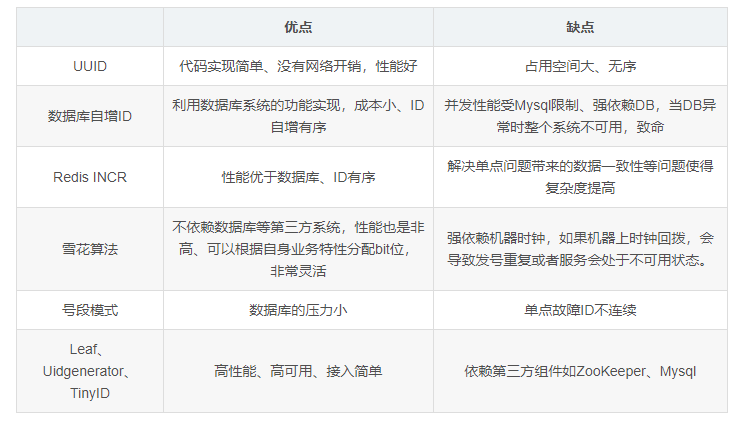
1、UUID
UUID(Universally Unique Identifier)是基于當前時間、計數器(counter)和硬件標識(通常為無線網卡的MAC地址)等數據計算生成的。包含32個16進制數字,以連字號分為五段,形式為8-4-4-4-12的36個字符,可以生成全球唯一的編碼并且性能高效。
JDK提供了UUID生成工具,代碼如下:
import?java.util.UUID; public?class?Test?{ ????public?static?void?main(String[]?args)?{ ????????System.out.println(UUID.randomUUID()); ????} }
輸出如下
b0378f6a-eeb7-4779-bffe-2a9f3bc76380
UUID完全可以滿足分布式唯一標識,但是在實際應用過程中一般不采用,有如下幾個原因:
存儲成本高: UUID太長,16字節128位,通常以36長度的字符串表示,很多場景不適用。
信息不安全: 基于MAC地址生成的UUID算法會暴露MAC地址,曾經梅麗莎病毒的制造者就是根據UUID尋找的。
不符合MySQL主鍵要求: MySQL官方有明確的建議主鍵要盡量越短越好,因為太長對MySQL索引不利:如果作為數據庫主鍵,在InnoDB引擎下,UUID的無序性可能會引起數據位置頻繁變動,嚴重影響性能。
2、數據庫自增ID
利用Mysql的特性ID自增,可以達到數據唯一標識,但是分庫分表后只能保證一個表中的ID的唯一,而不能保證整體的ID唯一。為了避免這種情況,我們有以下兩種方式解決該問題。
2.1、主鍵表
通過單獨創建主鍵表維護唯一標識,作為ID的輸出源可以保證整體ID的唯一。舉個例子:
創建一個主鍵表
CREATE?TABLE?`unique_id`??( ??`id`?bigint?NOT?NULL?AUTO_INCREMENT, ??`biz`?char(1)?NOT?NULL, ??PRIMARY?KEY?(`id`), ?UNIQUE?KEY?`biz`?(`biz`) )?ENGINE?=?InnoDB?AUTO_INCREMENT=1?DEFAULT?CHARSET?=utf8;
業務通過更新操作來獲取ID信息,然后添加到某個分表中。
BEGIN; REPLACE?INTO?unique_id?(biz)?values?('o')?; SELECT?LAST_INSERT_ID(); COMMIT;
?
?
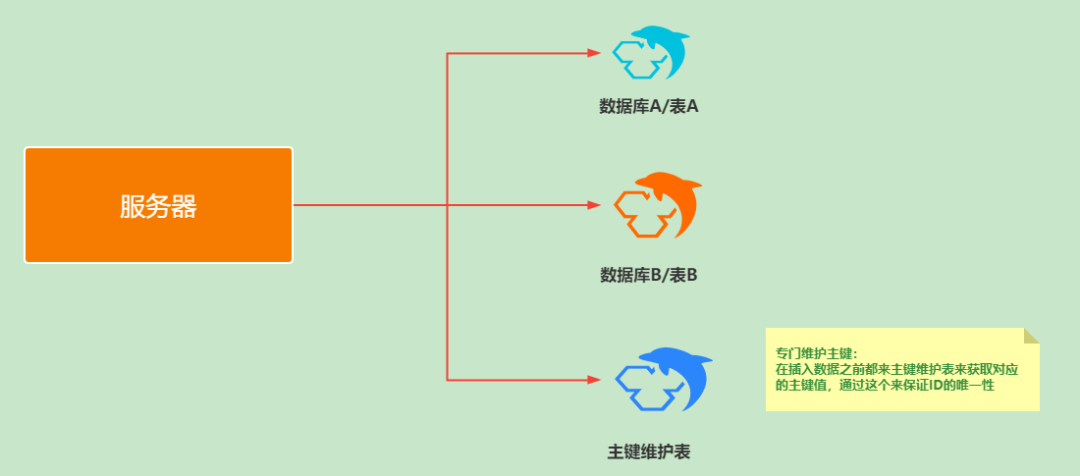
2.2、ID自增步長設置
我們可以設置Mysql主鍵自增步長,讓分布在不同實例的表數據ID做到不重復,保證整體的唯一。
如下,可以設置Mysql實例1步長為1,實例1步長為2。

查看主鍵自增的屬性
show?variables?like?'%increment%'
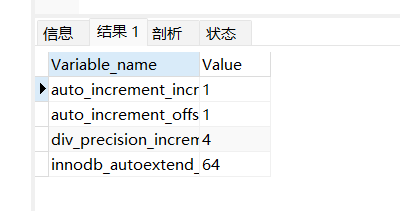
顯然,這種方式在并發量比較高的情況下,如何保證擴展性其實會是一個問題。
3、號段模式
號段模式是當下分布式ID生成器的主流實現方式之一。其原理如下:
號段模式每次從數據庫取出一個號段范圍,加載到服務內存中。業務獲取時ID直接在這個范圍遞增取值即可。
等這批號段ID用完,再次向數據庫申請新號段,對max_id字段做一次update操作,新的號段范圍是(max_id ,max_id +step]。
由于多業務端可能同時操作,所以采用版本號version樂觀鎖方式更新。
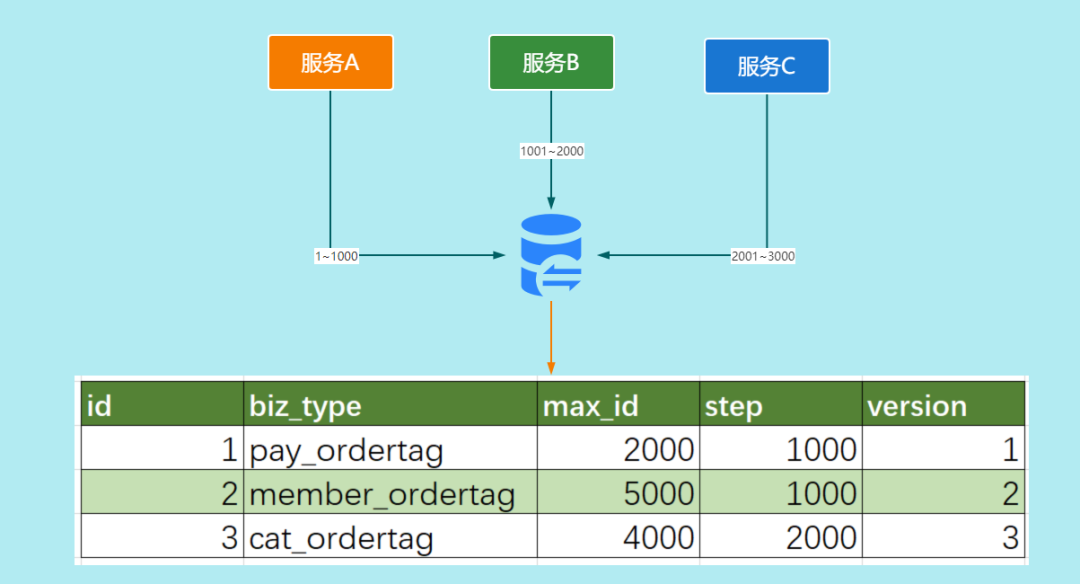
例如 (1,1000] 代表1000個ID,具體的業務服務將本號段生成1~1000的自增ID。表結構如下:
CREATE?TABLE?id_generator?(
??id?int(10)?NOT?NULL, ??max_id?bigint(20)?NOT?NULL?COMMENT?'當前最大id', ??step?int(20)?NOT?NULL?COMMENT?'號段的長度', ??biz_type????int(20)?NOT?NULL?COMMENT?'業務類型', ??version?int(20)?NOT?NULL?COMMENT?'版本號,是一個樂觀鎖,每次都更新version,保證并發時數據的正確性', ??PRIMARY?KEY?(`id`) )?
這種分布式ID生成方式不強依賴于數據庫,不會頻繁的訪問數據庫,對數據庫的壓力小很多。但同樣也會存在一些缺點比如:服務器重啟,單點故障會造成ID不連續。
4、Redis INCR
基于全局唯一ID的特性,我們可以通過Redis的INCR命令來生成全局唯一ID。
Redis分布式ID的簡單案例
/** ?*??Redis?分布式ID生成器 ?*/ @Component public?class?RedisDistributedId?{ ????@Autowired ????private?StringRedisTemplate?redisTemplate; ????private?static?final?long?BEGIN_TIMESTAMP?=?1659312000l; ????/** ?????*?生成分布式ID ?????*?符號位????時間戳[31位]??自增序號【32位】 ?????*?@param?item ?????*?@return ?????*/ ????public?long?nextId(String?item){ ????????//?1.生成時間戳 ????????LocalDateTime?now?=?LocalDateTime.now(); ????????//?格林威治時間差 ????????long?nowSecond?=?now.toEpochSecond(ZoneOffset.UTC); ????????//?我們需要獲取的?時間戳?信息 ????????long?timestamp?=?nowSecond?-?BEGIN_TIMESTAMP; ????????//?2.生成序號?--》?從Redis中獲取 ????????//?當前當前的日期 ????????String?date?=?now.format(DateTimeFormatter.ofPattern("yyyydd")); ????????//?獲取對應的自增的序號 ????????Long?increment?=?redisTemplate.opsForValue().increment("id:"?+?item?+?":"?+?date); ????????return?timestamp?<同樣使用Redis也有對應的缺點:ID 生成的持久化問題,如果Redis宕機了怎么進行恢復?
5、雪花算法
Snowflake,雪花算法是有Twitter開源的分布式ID生成算法,以劃分命名空間的方式將64bit位分割成了多個部分,每個部分都有具體的不同含義,在Java中64Bit位的整數是Long類型,所以在Java中Snowflake算法生成的ID就是long來存儲的。具體如下:
第一部分: 占用1bit,第一位為符號位,不適用
第二部分: 41位的時間戳,41bit位可以表示241個數,每個數代表的是毫秒,那么雪花算法的時間年限是(241)/(1000×60×60×24×365)=69年
第三部分: 10bit表示是機器數,即 2^ 10 = 1024臺機器,通常不會部署這么多機器
第四部分: 12bit位是自增序列,可以表示2^12=4096個數,一秒內可以生成4096個ID,理論上snowflake方案的QPS約為409.6w/s
雪花算法案例代碼:
public?class?SnowflakeIdWorker?{
????//?==============================Fields=========================================== ????/** ?????*?開始時間截?(2020-11-03,一旦確定不可更改,否則時間被回調,或者改變,可能會造成id重復或沖突) ?????*/ ????private?final?long?twepoch?=?1604374294980L; ????/** ?????*?機器id所占的位數 ?????*/ ????private?final?long?workerIdBits?=?5L; ????/** ?????*?數據標識id所占的位數 ?????*/ ????private?final?long?datacenterIdBits?=?5L; ????/** ?????*?支持的最大機器id,結果是31?(這個移位算法可以很快的計算出幾位二進制數所能表示的最大十進制數) ?????*/ ????private?final?long?maxWorkerId?=?-1L?^?(-1L?<?maxWorkerId?||?workerId??maxDatacenterId?||?datacenterId?雪花算法強依賴機器時鐘,如果機器上時鐘回撥,會導致發號重復。通常通過記錄最后使用時間處理該問題。
6、美團(Leaf)
Leaf同時支持號段模式和snowflake算法模式,可以切換使用。
snowflake模式依賴于ZooKeeper,不同于原始snowflake算法也主要是在workId的生成上,Leaf中workId是基于ZooKeeper的順序Id來生成的,每個應用在使用Leaf-snowflake時,啟動時都會都在Zookeeper中生成一個順序Id,相當于一臺機器對應一個順序節點,也就是一個workId。
號段模式是對直接用數據庫自增ID充當分布式ID的一種優化,減少對數據庫的頻率操作。相當于從數據庫批量的獲取自增ID,每次從數據庫取出一個號段范圍,例如 (1,1000] 代表1000個ID,業務服務將號段在本地生成1~1000的自增ID并加載到內存。
7、百度(Uidgenerator)
UidGenerator是百度開源的Java語言實現,基于Snowflake算法的唯一ID生成器。它是分布式的,并克服了雪花算法的并發限制。單個實例的QPS能超過6000000。需要的環境:JDK8+,MySQL(用于分配WorkerId)。
百度的Uidgenerator對結構做了部分的調整,具體如下:
時間部分只有28位,這就意味著UidGenerator默認只能承受8.5年(2^28-1/86400/365),不過UidGenerator可以適當調整delta seconds、worker node id和sequence占用位數。
8、滴滴(TinyID)
Tinyid是在美團(Leaf)的leaf-segment算法基礎上升級而來,不僅支持了數據庫多主節點模式,還提供了tinyid-client客戶端的接入方式,使用起來更加方便。但和美團(Leaf)不同的是,Tinyid只支持號段一種模式不支持雪花模式。Tinyid提供了兩種調用方式,一種基于Tinyid-server提供的http方式,另一種Tinyid-client客戶端方式。
總結比較
編輯:黃飛
?













 工商網監
工商網監
評論