 電子發燒友App
電子發燒友App


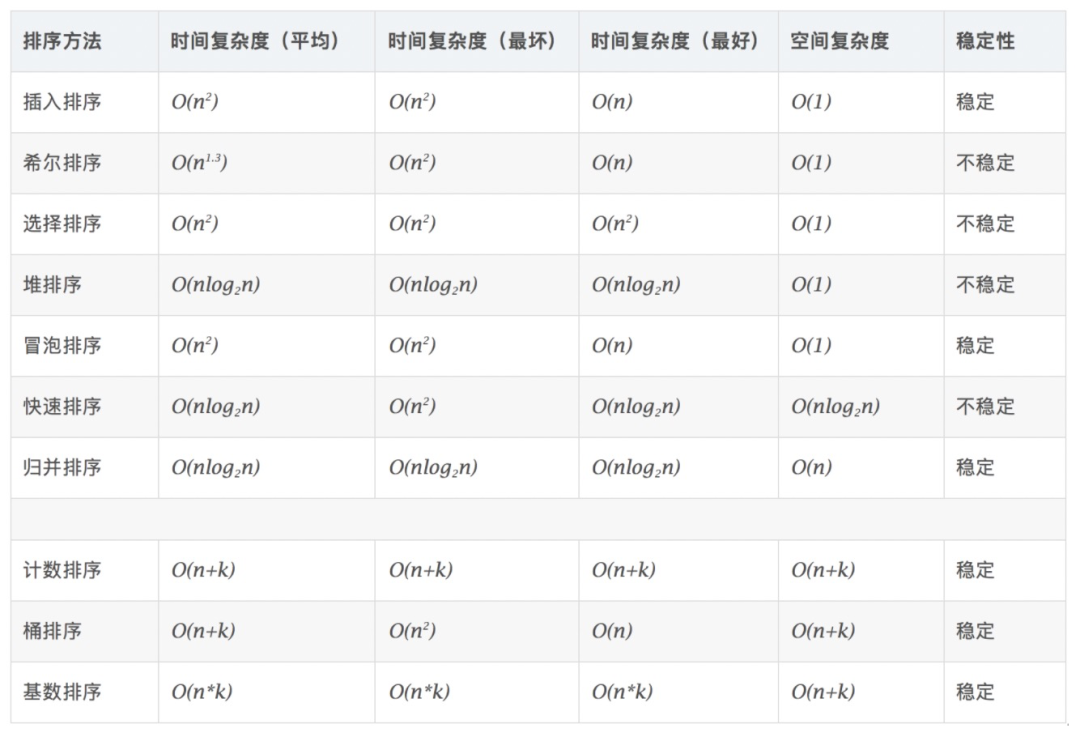
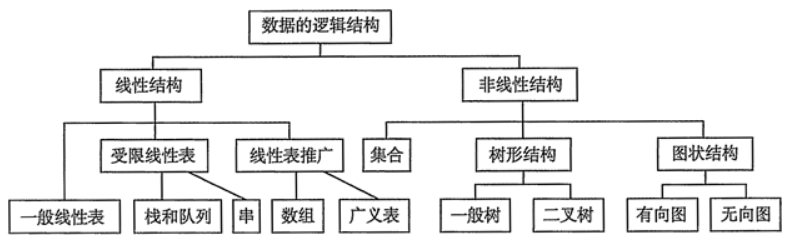
快速介紹8種常用數據結構
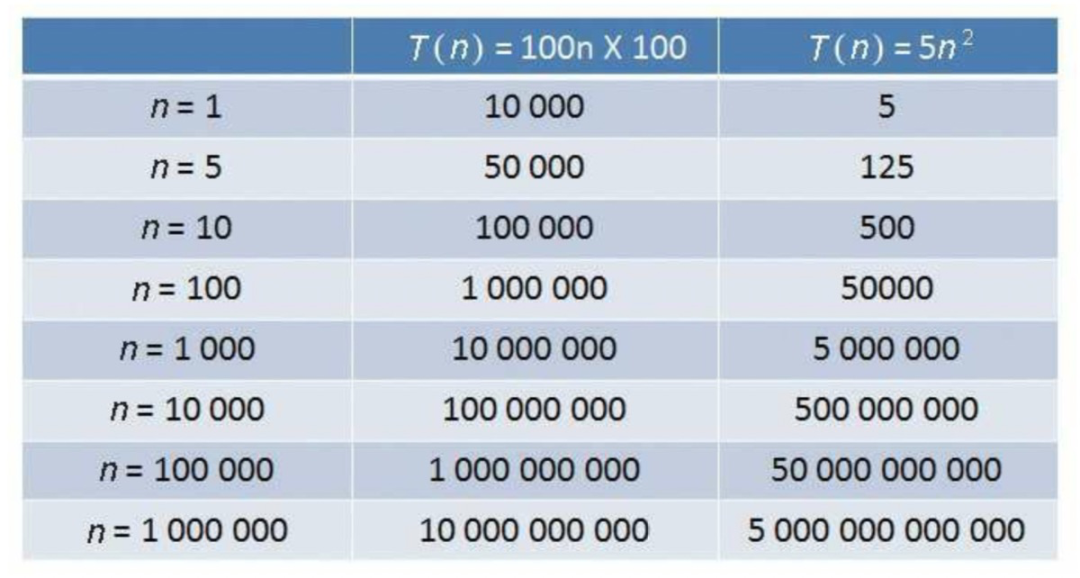
數據結構是一種特殊的組織和存儲數據的方式,可以使我們可以更高效地對存儲的數據執行操作。數據結構在計算機科學和軟件工程領域具有廣泛而多樣的用途。
幾乎所有已開發的程序或軟件系統都使用數據結構。此外,數據結構屬于計算機科學和軟件工程的基礎。當涉及軟件工程面試問題時,這是一個關鍵主題。因此,作為開發人員,我們必須對數據結構有充分的了解。
在本文中,我將簡要解釋每個程序員必須知道的幾種常用數據結構。
數組是固定大小的結構,可以容納相同數據類型的項目。它可以是整數數組,浮點數數組,字符串數組或什至是數組數組(例如二維數組)。數組已建立索引,這意味著可以進行隨機訪問。
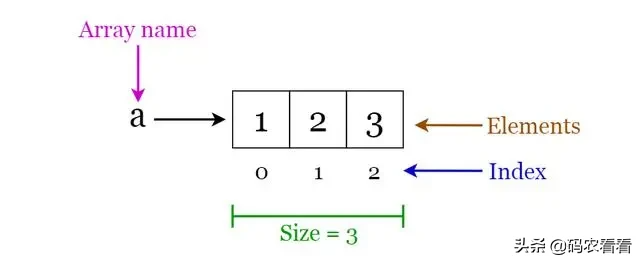
Fig 1. Visualization of basic Terminology of Arrays
· 遍歷:遍歷所有元素并進行打印。
· 插入:將一個或多個元素插入數組。
· 刪除:從數組中刪除元素
· 搜索:在數組中搜索元素。您可以按元素的值或索引搜索元素
· 更新:在給定索引處更新現有元素的值
· 用作構建其他數據結構的基礎,例如數組列表,堆,哈希表,向量和矩陣。
· 用于不同的排序算法,例如插入排序,快速排序,冒泡排序和合并排序。
鏈表是一種順序結構,由相互鏈接的線性順序項目序列組成。因此,您必須順序訪問數據,并且無法進行隨機訪問。鏈接列表提供了動態集的簡單靈活的表示形式。
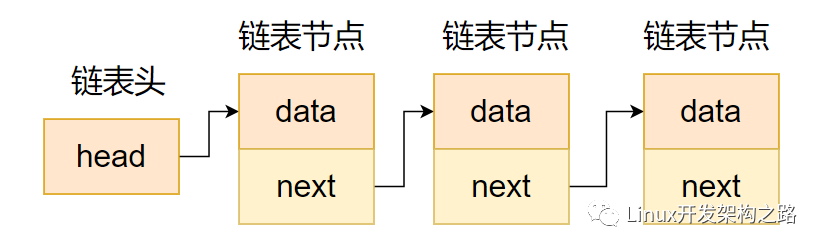
讓我們考慮以下有關鏈表的術語。您可以通過參考圖2來獲得一個清晰的主意。
· 鏈表中的元素稱為節點。
· 每個節點都包含一個密鑰和一個指向其后繼節點(稱為next)的指針。
· 名為head的屬性指向鏈接列表的第一個元素。
· 鏈表的最后一個元素稱為尾。

Fig 2. Visualization of basic Terminology of Linked Lists
以下是可用的各種類型的鏈表。
· 單鏈列表—只能沿正向遍歷項目。
· 雙鏈表-可以在前進和后退方向上遍歷項目。節點由一個稱為上一個的附加指針組成,指向上一個節點。
· 循環鏈接列表—鏈接列表,其中頭的上一個指針指向尾部,尾號的下一個指針指向頭。
· 搜索:通過簡單的線性搜索在給定的鏈表中找到鍵為k的第一個元素,并返回指向該元素的指針
· 插入:在鏈接列表中插入一個密鑰。插入可以通過3種不同的方式完成;在列表的開頭插入,在列表的末尾插入,然后在列表的中間插入。
· 刪除:從給定的鏈表中刪除元素x。您不能單步刪除節點。刪除可以通過3種不同方式完成;從列表的開頭刪除,從列表的末尾刪除,然后從列表的中間刪除。
· 用于編譯器設計中的符號表管理。
· 用于在使用Alt Tab(使用循環鏈表實現)的程序之間進行切換。
堆棧是一種LIFO(后進先出-最后放置的元素可以首先訪問)結構,該結構通常在許多編程語言中都可以找到。該結構被稱為"堆棧",因為它類似于真實世界的堆棧-板的堆棧。
Image Source: pixabay
下面給出了可以在堆棧上執行的2個基本操作。請參考圖3,以更好地了解堆棧操作。
· Push 推送:在堆棧頂部插入一個元素。
· Pop 彈出:刪除最上面的元素并返回。
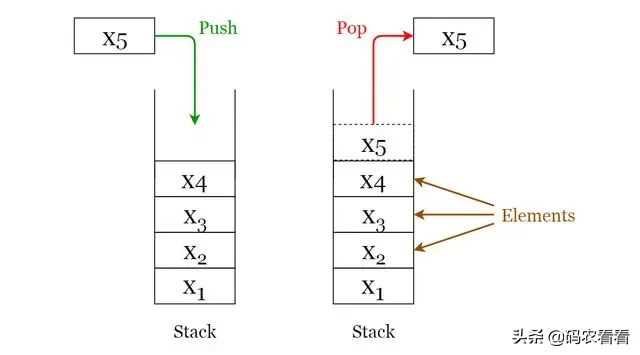
Fig 3. Visualization of basic Operations of Stacks
此外,為堆棧提供了以下附加功能,以檢查其狀態。
· Peep 窺視:返回堆棧的頂部元素而不刪除它。
· isEmpty:檢查堆棧是否為空。
· isFull:檢查堆棧是否已滿。
· 用于表達式評估(例如:用于解析和評估數學表達式的調車場算法)。
· 用于在遞歸編程中實現函數調用。
隊列是一種FIFO(先進先出-首先放置的元素可以首先訪問)結構,該結構通常在許多編程語言中都可以找到。該結構被稱為"隊列",因為它類似于現實世界中的隊列-人們在隊列中等待。
Image Source: pixabay
下面給出了可以在隊列上執行的2個基本操作。請參考圖4,以更好地了解堆棧操作。
· 進隊:將元素插入隊列的末尾。
· 出隊:從隊列的開頭刪除元素。

Fig 4. Visualization of Basic Operations of Queues
· 用于管理多線程中的線程。
· 用于實施排隊系統(例如:優先級隊列)。
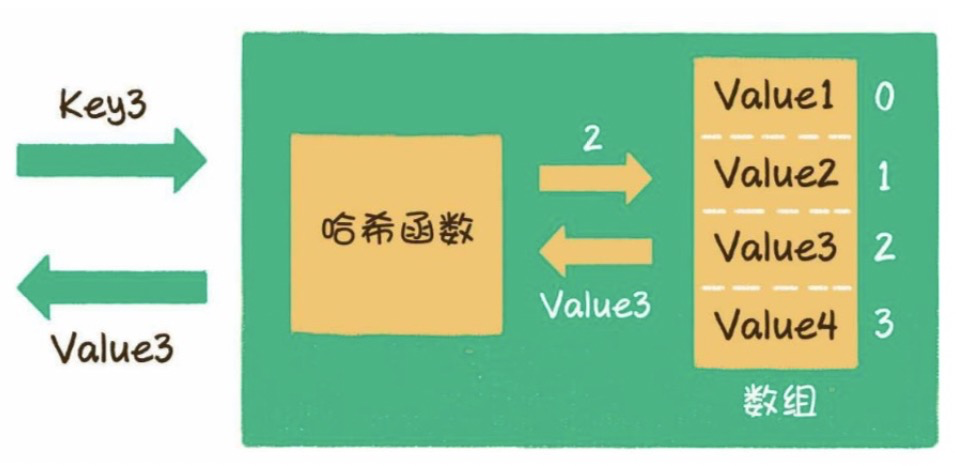
哈希表是一種數據結構,用于存儲具有與每個鍵相關聯的鍵的值。此外,如果我們知道與值關聯的鍵,則它有效地支持查找。因此,無論數據大小如何,插入和搜索都非常有效。
當存儲在表中時,直接尋址使用值和鍵之間的一對一映射。但是,當存在大量鍵值對時,此方法存在問題。該表將具有很多記錄,并且非常龐大,考慮到典型計算機上的可用內存,該表可能不切實際甚至無法存儲。為避免此問題,我們使用哈希表。
名為哈希函數(h)的特殊函數用于克服直接尋址中的上述問題。
在直接訪問中,帶有密鑰k的值存儲在插槽k中。使用哈希函數,我們可以計算出每個值都指向的表(插槽)的索引。使用給定鍵的哈希函數計算的值稱為哈希值,它表示該值映射到的表的索引。
· h:哈希函數
· k:應確定其哈希值的鍵
· m:哈希表的大小(可用插槽數)。一個不接近2的精確乘方的素數是m的一個不錯的選擇。
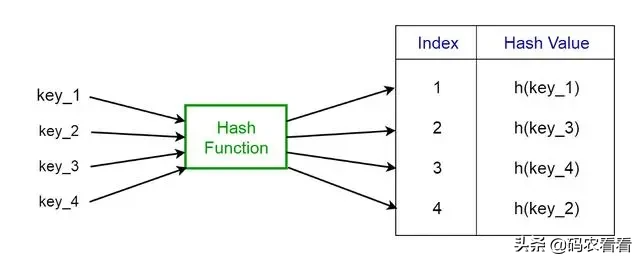
Fig 5. Representation of a Hash Function
· 1→1→1
· 5→5→5
· 23→23→3
· 63→63→3
從上面給出的最后兩個示例中,我們可以看到,當哈希函數為多個鍵生成相同的索引時,就會發生沖突。我們可以通過選擇合適的哈希函數h并使用鏈接和開放式尋址等技術來解決沖突。
· 用于實現數據庫索引。
· 用于實現關聯數組。
· 用于實現"設置"數據結構。
樹是一種層次結構,其中數據按層次進行組織并鏈接在一起。此結構與鏈接列表不同,而在鏈接列表中,項目以線性順序鏈接。
在過去的幾十年中,已經開發出各種類型的樹木,以適合某些應用并滿足某些限制。一些示例是二叉搜索樹,B樹,紅黑樹,展開樹,AVL樹和n元樹。
顧名思義,二進制搜索樹(BST)是一種二進制樹,其中數據以分層結構進行組織。此數據結構按排序順序存儲值,我們將在本課程中詳細研究這些值。
二叉搜索樹中的每個節點都包含以下屬性。
· key:存儲在節點中的值。
· left:指向左孩子的指針。
· 右:指向正確孩子的指針。
· p:指向父節點的指針。
二叉搜索樹具有獨特的屬性,可將其與其他樹區分開。此屬性稱為binary-search-tree屬性。
令x為二叉搜索樹中的一個節點。
· 如果y是x左子樹中的一個節點,則y.key≤x.key
· 如果y是x的右子樹中的節點,則y.key≥x.key
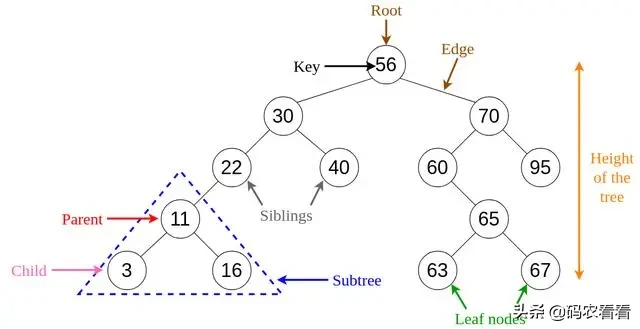
Fig 6. Visualization of Basic Terminology of Trees.
· 二叉樹:用于實現表達式解析器和表達式求解器。
· 二進制搜索樹:用于許多不斷輸入和輸出數據的搜索應用程序中。
· 堆:由JVM(Java虛擬機)用來存儲Java對象。
· Trap:用于無線網絡。
堆是二叉樹的一種特殊情況,其中將父節點與其子節點的值進行比較,并對其進行相應排列。
讓我們看看如何表示堆。堆可以使用樹和數組表示。圖7和8顯示了我們如何使用二叉樹和數組來表示二叉堆。
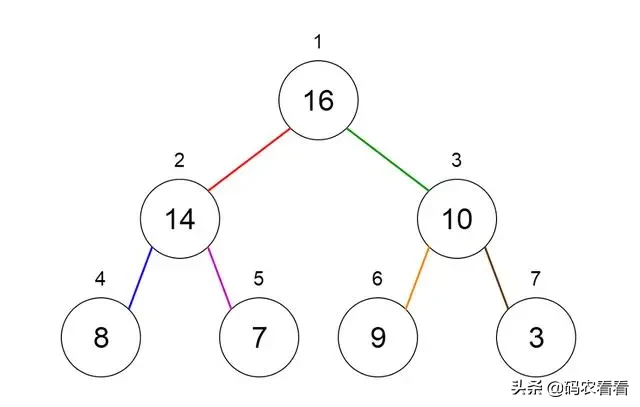
Fig 7. Binary Tree Representation of a Heap
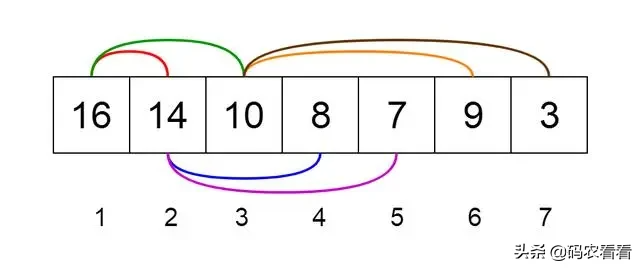
Fig 8. Array Representation of a Heap
堆可以有2種類型。
· 最小堆-父項的密鑰小于或等于子項的密鑰。這稱為min-heap屬性。根將包含堆的最小值。
· 最大堆數-父項的密鑰大于或等于子項的密鑰。這稱為max-heap屬性。根將包含堆的最大值。
· 用于實現優先級隊列,因為可以根據堆屬性對優先級值進行排序。
· 可以在O(log n)時間內使用堆來實現隊列功能。
· 用于查找給定數組中k個最小(或最大)的值。
· 用于堆排序算法。
一個圖由一組有限的頂點或節點以及一組連接這些頂點的邊組成。
圖的順序是圖中的頂點數。圖的大小是圖中的邊數。
如果兩個節點通過同一邊彼此連接,則稱它們為相鄰節點。
如果圖形G的所有邊緣都具有指示什么是起始頂點和什么是終止頂點的方向,則稱該圖形為有向圖。
我們說(u,v)從頂點u入射或離開頂點u,然后入射到或進入頂點v。
自環:從頂點到自身的邊。
如果圖G的所有邊緣均無方向,則稱其為無向圖。它可以在兩個頂點之間以兩種方式傳播。
如果頂點未連接到圖中的任何其他節點,則稱該頂點為孤立的。
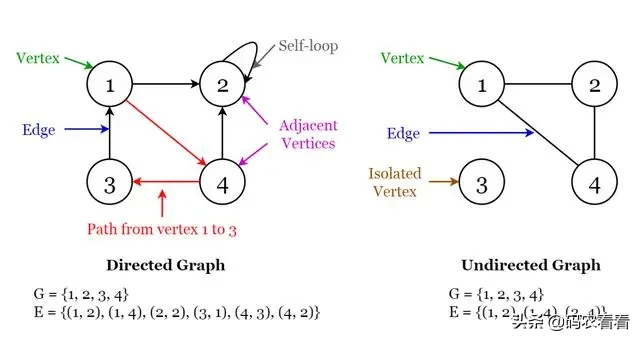
Fig 9. Visualization of Terminology of Graphs
· 用于表示社交媒體網絡。每個用戶都是一個頂點,并且在用戶連接時會創建一條邊。
· 用于表示搜索引擎的網頁和鏈接。互聯網上的網頁通過超鏈接相互鏈接。每頁是一個頂點,兩頁之間的超鏈接是一條邊。用于Google中的頁面排名。
· 用于表示GPS中的位置和路線。位置是頂點,連接位置的路線是邊。用于計算兩個位置之間的最短路徑。
[1]算法簡介,第三版,作者:托馬斯·H·科門(Thomas H. Cormen),查爾斯·E·雷森(Charles E. Leiserson),羅納德·L·里維斯特(Ronald L. Rivest)和克利福德·斯坦(Clifford Stein)。
[2]來自Wikipedia的數據結構列表
審核編輯:湯梓紅










 工商網監
工商網監
評論