 電子發燒友App
電子發燒友App


乍一看,Linux是非常復雜的,有許多令人眼花繚亂的部件同時運行和通信。例如網絡服務器可以與數據庫服務器對話,而數據庫服務器又可以使用許多其他程序使用的共享庫。所有這些是如何運作的,以及你如何能夠理解其中的任何內容?
理解操作系統如何工作的最有效方法是通過抽象--即你可以忽略構成你試圖理解的部分的大多數細節,而專注于其基本目的和操作。例如,當你乘坐汽車時,你通常不需要考慮諸如固定汽車內部馬達的安裝螺栓或建造和維護汽車行駛道路的人等細節。你真正需要知道的是汽車的作用(把你運送到別的地方)和一些關于如何使用它的基本知識(如何操作車門和安全帶)。
如果你只是乘客,這種抽象程度管用。但如果你還需要駕駛它,你就必須深入挖掘,把你的抽象概念分成幾個部分。你現在把你的知識擴展到三個方面:汽車本身(比如它的尺寸和性能),如何操作控制裝置(方向盤、加速踏板等),以及道路的特點。
當你試圖尋找和修復問題時,抽象化有很大的幫助。例如,假設你正在駕駛汽車,行駛過程中很不順利。你可以快速評估剛才提到的三個與汽車相關的基本抽象,以確定問題的來源。如果前兩個抽象概念(你的車或你的駕駛方式)都不是問題,那么排除這兩個抽象概念應該相當容易,這樣你就可以把問題縮小到道路本身。你可能會發現,道路是顛簸的。現在,如果你愿意,你可以更深入地挖掘你對道路的抽象,找出道路惡化的原因,或者,如果道路是新的,為什么建筑工人做了糟糕的工作。
軟件開發人員在構建操作系統及其應用程序時,將抽象作為工具。在計算機軟件中,有許多抽象的細分術語--包括子系統、模塊和包--但我們在本章將使用組件這個術語,因為它很簡單。在構建一個軟件組件時,開發人員通常不會過多考慮其他組件的內部結構,但他們會考慮他們可以使用的其他組件(這樣他們就不必再編寫任何額外的不必要的軟件)以及如何使用它們。
本章對構成Linux系統的組件作了高層次的概述。盡管每個組件的內部構成都有大量的技術細節,但我們將忽略這些細節,而專注于這些組件對整個系統的作用。我們將在隨后的章節中研究這些細節。
1.1 Linux系統中的抽象級別和層數
使用抽象將計算系統分割成組件,使事情更容易理解,但沒有組織也不行。我們將組件排列成層或級別,根據組件在用戶和硬件之間的位置,對組件進行分類(或分組)。網絡瀏覽器、游戲等位于頂層;在底層,我們有計算機硬件中的內存--0和1。操作系統占據了中間的許多層。
Linux系統有三個主要層次。圖1-1顯示了這些層次和每個層次中的一些組件。硬件處于底層。硬件包括內存以及一個或多個中央處理單元(CPU),用于執行計算和從內存讀寫。磁盤和網絡接口等設備也是硬件的一部分。
下一個層次是內核,它是操作系統的核心。內核是駐留在內存中的軟件,它告訴CPU去哪里尋找下一個任務。內核作為中介,管理硬件(尤其是主內存),是硬件和任何運行程序之間的主要接口。
進程--由內核管理的運行程序--共同構成了系統的上層,稱為用戶空間。(進程的一個更具體的術語是用戶進程,不管用戶是否直接與該進程進行交互。例如,所有的網絡服務器都作為用戶進程運行)。

圖1-1:一般的Linux系統組織
內核和用戶進程的運行方式有一個重要區別:內核在內核模式下運行,而用戶進程在用戶模式下運行。在內核模式下運行的代碼可以不受限制地訪問處理器和主內存。這是強大但危險的特權,允許內核輕易地破壞和崩潰整個系統。只有內核可以訪問的內存區域被稱為內核空間。
相比之下,用戶模式限制了對(通常是相當小的)內存子集的訪問和CPU的安全操作。用戶空間指的是用戶進程可以訪問的主內存的部分。如果進程犯了錯誤而崩潰,其后果是有限的,可以由內核來清理。這意味著,如果你的網絡瀏覽器崩潰了,它可能不會使已經在后臺運行了幾天的科學計算崩潰。
理論上用戶進程失控不會對系統的其他部分造成嚴重損害。在現實中,這取決于你認為什么是 "嚴重破壞",以及進程的特定權限,因為有些進程被允許做得比其他進程多。例如,用戶進程可以完全破壞磁盤上的數據嗎?如果有權限,可以,而且這是相當危險的。然而,有一些保障措施來防止這種情況,大多數進程根本不允許以這種方式進行破壞。
注意
Linux內核可以運行內核線程,它們看起來很像進程,但可以訪問內核空間,比如kthreadd和kblockd。
1.2 硬件: 了解主內存
在計算機系統的所有硬件中,主內存可能是最重要的。在其最原始的形式中,主內存只是大的存儲區,用于存儲一堆0和1。每個0或1的插槽被稱為比特。這就是運行中的內核和進程所在的地方--它們只是大量的比特集合。所有來自外圍設備的輸入和輸出都流經主內存,也是一堆比特。CPU只是內存的一個操作者;它從內存中讀取指令和數據,并將數據寫回內存。
在提到內存、進程、內核和計算機系統的其他部分時,你會經常聽到狀態這個詞。嚴格說來,狀態是特定的比特排列。例如,如果你的內存中有四個比特,0110、0001和1011代表三種不同的狀態。
當你考慮到進程可以很容易地由內存中的數百萬比特組成時,在談論狀態時,使用抽象的術語往往更容易。與其用比特來描述一態,不如用比特來描述一個東西在這一刻已經做了什么或正在做什么。例如,你可以說,"該進程正在等待輸入 "或 "該進程正在執行其啟動的第二階段"。
注意:因為人們通常用抽象的術語而不是實際的比特來指代狀態,所以術語image指的是比特的特定物理排列。
1.3 內核
為什么我們要討論主存和狀態?內核所做的一切幾乎都是圍繞著主存展開的。內核的任務之一是將內存分割成許多子區,它必須在任何時候都保持這些子區的某些狀態信息。每個進程都有自己的內存份額,而內核必須確保每個進程都保持自己的份額。
內核負責管理四個一般系統領域的任務:
-
進程 內核負責確定哪些進程被允許使用CPU。
-
內存 內核需要跟蹤所有的內存--哪些是當前分配給特定進程的,哪些可能是進程間共享的,哪些是空閑的。
-
設備驅動程序 內核作為硬件(如磁盤)和進程之間的接口。通常內核的工作是操作硬件。
-
系統調用和支持 進程通常使用系統調用來與內核通信。
現在我們將簡要地探討這些領域的每一個問題。
注意
如果你對內核的詳細工作原理感興趣,有兩本好的教科書:《Operating System Concepts》第10版,作者是Abraham Silberschatz、Peter B. Galvin和Greg Gagne(Wiley,2018);《Modern Operating Systems》第4版,作者是Andrew S. Tanenbaum和Herbert Bos(Prentice Hall,2014)。
1.3.1 進程管理
進程管理描述了進程的啟動、暫停、恢復、調度和終止。啟動和終止進程背后的概念是相當直接的,但描述進程在正常運行過程中如何使用CPU就比較復雜了。
在任何現代操作系統上,許多進程都是 "同時 "運行的。例如,你可能在一臺臺式電腦上同時打開網絡瀏覽器和電子表格。然而,事情并不像他們所看到的那樣:這些應用程序背后的進程通常不會完全在同一時間運行。
考慮單核CPU的系統。許多進程可能能夠使用CPU,但在任何時候只有一個進程能夠實際使用CPU。在實踐中,每個進程使用CPU一小部分時間,然后暫停;然后另一個進程使用CPU另一小部分時間;然后另一個進程輪流使用,如此反復。一個進程將CPU的控制權交給另一個進程的行為被稱為上下文切換。
每一塊時間被稱為一個時間片,為進程提供足夠的時間進行重要的計算(事實上,進程經常在一個時間片內完成其當前任務)。然而,由于時間片非常小,人類無法感知它們,而且系統似乎在同時運行多個進程(一種被稱為多任務的能力)。
內核負責上下文切換。為了理解它是如何工作的,讓我們想想這樣一種情況:進程在用戶模式下運行,但它的時間片已經到了。這就是發生的情況:
- CPU(實際的硬件)根據一個內部計時器中斷當前進程,切換到內核模式,并將控制權交還給內核。
- 內核記錄了CPU和內存的當前狀態,這對于恢復剛剛被中斷的進程至關重要。
- 內核執行在前一個時間片中可能出現的任何任務(比如從輸入和輸出(I/O)操作中收集數據)。
- 內核現在已經準備好讓另一個進程運行。內核分析準備運行的進程列表并選擇一個。
- 內核為這個新進程準備好內存,然后為CPU做準備。
- 內核告訴CPU新進程的時間片將持續多長時間。
- 內核將CPU切換到用戶模式,并將CPU的控制權交給該進程。
上下文切換回答了內核何時運行這一重要問題。答案是,在上下文切換期間,它在進程的時間片之間運行。
在多CPU系統的情況下,就像目前大多數機器一樣,事情變得稍微復雜一些,因為內核不需要放棄對當前CPU的控制,就可以讓一個進程在不同的CPU上運行,而且一次可以運行不止一個進程。然而,為了最大限度地利用所有可用的CPU,內核通常會執行這些步驟(并可能使用某些技巧來為自己多爭取一點CPU時間)。
1.3.2 內存管理
內核必須在上下文切換期間管理內存,這可能是一項復雜的工作。以下條件必須成立:
- 內核必須在內存中擁有自己的私有區域,用戶進程不能訪問。
- 每個用戶進程都需要自己的內存區域。
- 用戶進程不能訪問另一個進程的私有內存。
- 用戶進程可以共享內存。
- 用戶進程中的一些內存可以是只讀的。
- 系統可以通過使用磁盤空間作為輔助來使用比實際存在的更多的內存。
現代CPU包括一個內存管理單元(MMU memory management unit ),它可以實現一種叫做虛擬內存的內存訪問方案。當使用虛擬內存時,進程并不直接通過其在硬件中的物理位置來訪問內存。相反,內核將每個進程設置成好像它自己有一整臺機器的樣子。當進程訪問它的一些內存時,MMU會攔截訪問,并使用內存地址圖將內存位置從進程的角度轉換為機器中的實際物理內存位置。內核仍然必須初始化并持續維護和改變這個內存地址圖。例如,在上下文切換過程中,內核必須將該地圖從離開的進程改變為進入的進程。
注意: 內存地址映射的實現被稱為頁表。
你將在第8章中了解更多關于如何查看內存性能的信息。
1.3.3 設備驅動和管理
內核對設備的作用相對簡單。設備通常只能在內核模式下訪問,因為不適當的訪問(比如用戶進程要求關閉電源)會使機器崩潰。值得注意的困難是,不同的設備很少有相同的編程接口,即使這些設備執行相同的任務(例如,兩個不同的網卡)。因此,設備驅動歷來是內核的一部分,它們努力為用戶進程提供統一的接口,以簡化軟件開發者的工作。
系統調用和支持
還有一些其他類型的內核功能可供用戶進程使用。例如,系統調用(或稱syscalls)執行一些特定的任務,而這些任務單靠用戶進程是不能很好地完成的,或者根本就不能完成。例如,打開、讀取和寫入文件的行為都涉及系統調用。
兩個系統調用,fork()和exec(),對于理解進程如何啟動很重要:
fork() 當進程調用fork()時,內核會創建一個幾乎相同的進程副本。
exec() 當一個進程調用exec(program)時,內核加載并啟動程序,取代當前進程。
除了init(見第6章),Linux系統中所有新的用戶進程都是由于fork()而啟動的,大多數時候,你也會運行exec()來啟動一個新的程序,而不是運行一個現有進程的副本。非常簡單的例子是你在命令行上運行的任何程序,例如顯示一個目錄內容的ls命令。當你在終端窗口中輸入ls時,在終端窗口中運行的shell調用fork()來創建一個shell的副本,然后這個shell的新副本調用exec(ls)來運行ls。圖1-2顯示了啟動像ls這樣的程序的進程和系統調用的流程。

圖1-2: 啟動一個新的進程
注意
系統調用通常用括號來表示。在圖1-2所示的例子中,要求內核創建另一個進程的進程必須執行fork()系統調用。這個符號來自于C語言中調用的寫法。你不需要知道C語言來理解本書,只要記住系統調用是進程和內核之間的交互。此外,本書還簡化了某些組的系統調用。例如,exec()指的是整個系統調用家族,它們都執行類似的任務,但在編程上有所不同。還有一個稱為線程的進程的變種,我們將在第8章中介紹。
內核還支持具有傳統系統調用以外的功能的用戶進程,其中最常見的是偽設備(pseudodevices)。偽設備對用戶進程來說看起來像設備,但它們是純粹用軟件實現的。這意味著它們在技術上不需要在內核中出現,但它們通常出于實際原因而出現。例如,內核的隨機數生成器設備(/dev/random)就很難在用戶進程中安全實現。
注意:從技術上講,訪問偽設備的用戶進程必須使用系統調用來打開設備,所以進程不能完全避免系統調用。
1.4 用戶空間
如前所述,內核為用戶進程分配的主內存被稱為用戶空間。因為進程只是內存中的一個狀態(或image),所以用戶空間也指整個運行中的進程集合的內存。(你也可能聽到用更非正式的術語userland來表示用戶空間;有時這也意味著在用戶空間運行的程序。)
Linux系統中的大部分實際操作都發生在用戶空間。盡管從內核的角度來看,所有的進程本質上是平等的,但它們為用戶執行不同的任務。對于用戶進程所代表的系統組件的種類,有基本的服務級別(或層)結構。圖1-3顯示了一組組件在Linux系統中是如何配合和互動的。基本服務在最底層(最接近內核),實用服務在中間,而用戶接觸的應用程序在最上面。圖1-3是一個大大簡化的圖,因為只顯示了六個組件,但是你可以看到頂部的組件是最接近用戶的(用戶界面和網絡瀏覽器);中間層的組件包括網絡瀏覽器使用的域名緩存服務器;底部還有幾個較小的組件。
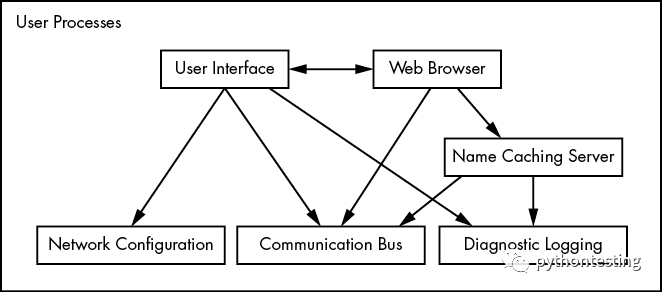
底層往往由小的組件組成,執行單一的、不復雜的任務。中間層有較大的組件,如郵件、打印和數據庫服務。最后,頂層的組件執行復雜的任務,用戶經常直接控制。組件也使用其他組件。一般來說,如果一個組件想使用另一個組件,第二個組件要么處于同一服務級別,要么低于這個級別。
然而,圖1-3只是對用戶空間安排的近似描述。在現實中,用戶空間并沒有什么規則。例如,大多數應用程序和服務都會寫被稱為日志的診斷信息。大多數程序使用標準的syslog服務來寫日志信息,但有些程序喜歡自己做所有的日志。
此外,對一些用戶空間的組件也很難進行分類。服務器組件,如Web和數據庫服務器,可以被認為是非常高級的應用程序,因為它們的任務往往很復雜,所以你可能會把這些放在圖1-3的最高層。然而,用戶應用程序可能依賴于這些服務器來執行他們不愿自己做的任務,所以你也可以為把它們放在中間層提供理由。
1.5 用戶
Linux內核支持Unix用戶的傳統概念。用戶是可以運行進程和擁有文件的實體。用戶通常與用戶名相關聯,例如,系統可以有名為billyjoe的用戶。然而,內核并不管理用戶名;相反,它通過簡單的數字標識符(稱為用戶ID)來識別用戶。(你將在第7章中了解更多關于用戶名與用戶ID的對應關系)。
用戶的存在主要是為了支持權限和邊界。每個用戶空間的進程都有一個用戶所有者,而進程據說是作為所有者運行的。用戶可以終止或修改自己進程的行為(在一定范圍內),但它不能干擾其他用戶的進程。此外,用戶可以擁有文件,并選擇是否與其他用戶分享這些文件。
Linux系統除了對應于使用該系統的真實人類的用戶外,通常還有一些用戶。你將在第三章中詳細了解這些用戶,但最重要的用戶是root。root用戶是前述規則的一個例外,因為root可以終止和改變其他用戶的進程,并訪問本地系統中的任何文件。由于這個原因,root被稱為超級用戶。在傳統的Unix系統中,能夠以root身份操作的人,也就是有root權限的人,就是管理員。
注意:以root身份操作可能是危險的。因為系統會讓你做任何事情,即使它對系統有害,也很難識別和糾正錯誤。出于這個原因,系統設計者不斷嘗試使root權限盡可能不被需要--例如,不需要root權限就可以在筆記本上切換無線網絡。此外,盡管root用戶很強大,但它仍然運行在操作系統的用戶模式,而不是內核模式。
組是用戶的集合。組的主要目的是允許一個用戶與組內的其他成員共享文件訪問。
1.6 展望未來
到目前為止,你已經看到了什么構成了運行中的Linux系統。用戶進程構成了你直接與之交互的環境;內核管理著進程和硬件。內核和進程都駐留在內存中。
這些都是很好的背景信息,但你不能僅僅通過閱讀來了解Linux系統的細節,你需要親身體驗。下一章將通過教授你一些用戶空間的基礎知識開始你的旅程。在這一過程中,你會了解到本章沒有討論的Linux系統的主要部分:長期存儲(磁盤、文件等)。畢竟,你需要把你的程序和數據儲存在某個地方。










 工商網監
工商網監
評論