 電子發(fā)燒友App
電子發(fā)燒友App


裸機(jī)開(kāi)發(fā)與RTOS開(kāi)發(fā)一個(gè)非常重要的區(qū)別在于多線程之間的消息傳遞和數(shù)據(jù)共享問(wèn)題,然而在這中間變量的原子操作是一個(gè)非常重要的話題,不同的處理器架構(gòu)和編譯選項(xiàng)都可能生成不同的指令,從而影響到變量的原子操作,導(dǎo)致一些異常、數(shù)據(jù)錯(cuò)亂等問(wèn)題。
那么今天分享今天找了一下這塊的內(nèi)容,跟大家分享一下:
這個(gè)是在面試的時(shí)候遇到的問(wèn)題,當(dāng)時(shí)沒(méi)有答出來(lái)。回到家以后查了查,整理記錄下來(lái)。
原問(wèn)題:什么指令集支持原子操作?其原理是什么? 如果考慮到全部的指令集,問(wèn)題太大了,這里簡(jiǎn)化下。以X86和ARM為例。
原子操作是不可分割的操作,在執(zhí)行完畢時(shí)它不會(huì)被任何事件中斷。在單處理器系統(tǒng)(UniProcessor,簡(jiǎn)稱(chēng) UP)中,能夠在單條指令中完成的操作都可以認(rèn)為是原子操作,因?yàn)橹袛嘀荒馨l(fā)生在指令與指令之間。
比如,C語(yǔ)言代碼

如果未經(jīng)優(yōu)化,有可能生成如下匯編:
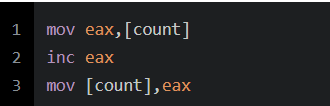
這樣在有多個(gè)進(jìn)程執(zhí)行這段代碼時(shí),就有可能產(chǎn)生并發(fā)問(wèn)題:
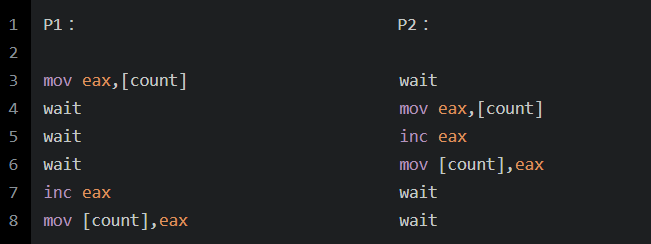
這就會(huì)出現(xiàn)問(wèn)題。
在單處理器中,解決這個(gè)問(wèn)題的方法是,將count++語(yǔ)句翻譯成單指令操作

X86指令集支持inc操作,這樣count操作可以在一條指內(nèi)完成。
進(jìn)程的上下文切換總是在一條指令執(zhí)行之后完成,所以不會(huì)出現(xiàn)上述的并發(fā)問(wèn)題。對(duì)于單處理器來(lái)說(shuō),一條處理器指令就是一個(gè)原子操作。
同樣,ARM里的SWP和X86里的XCHG都是對(duì)于單處理器來(lái)說(shuō),是原子操作。
但是,在多處理器系統(tǒng)(Symmetric Multi-Processor,簡(jiǎn)稱(chēng) SMP)中情況有所不同,由于系統(tǒng)中有多個(gè)處理器在獨(dú)立的運(yùn)行,即使在能單條指令中完成的操作也可能受到干擾。因?yàn)檫@個(gè)時(shí)候并發(fā)的主題不再是進(jìn)程,而是處理器。
X86架構(gòu)
Intel X86指令集提供了指令前綴lock用于鎖定前端串行總線FSB,保證了指令執(zhí)行時(shí)不會(huì)收到其他處理器的干擾。
比如:

使用lock指令前綴之后,處理期間對(duì)count內(nèi)存的并發(fā)訪問(wèn)(Read/Write)被禁止,從而保證了指令的原子性。
X86LOCK如圖所示:
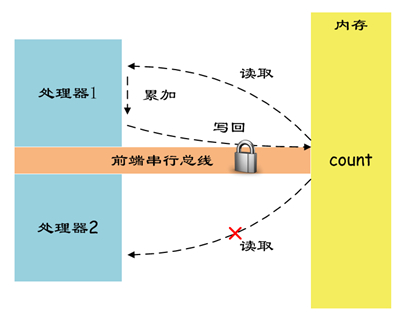
其原理在Intel開(kāi)發(fā)手冊(cè)有如下說(shuō)明:
Description
Causes the processor’s LOCK# signal to be asserted during execution of the accompanying instruction (turns the instruction into an atomic instruction). In a multiprocessor environment, the LOCK# signal ensures that the processor has exclusive use of any shared memory while the signal is asserted.
*The LOCK prefix can be prepended only to the following instructions and only to those forms of the instructions where the destination operand is a memory operand: ADD, ADC, AND, BTC, BTR, BTS, CMPXCHG, CMPXCH8B, CMPXCHG16B, DEC, INC, NEG, NOT, OR, SBB, SUB, XOR, XADD, and XCHG. If the LOCK prefix is used with one of these instructions and the source operand is a memory operand, an undefined opcode exception (#UD) may be generated. An undefined opcode exception will also be generated if the LOCK prefix is used with any instruction not in the above list. The XCHG instruction always asserts the LOCK# signal regardless of the presence or absence of the LOCK prefix.*
The LOCK prefix is typically used with the BTS instruction to perform a read-modify-write operation on a memory location in shared memory environment.
The integrity of the LOCK prefix is not affected by the alignment of the memory field. Memory locking is observed for arbitrarily misaligned fields.
在執(zhí)行伴隨的指令期間使處理器的LOCK#信號(hào)有效(將指令變?yōu)樵又噶睿T诙嗵幚砥鳝h(huán)境中,LOCK#信號(hào)確保處理器在信號(hào)有效時(shí)獨(dú)占使用任何共享存儲(chǔ)器。
LOCK前綴只能附加在下面的指令之前,并且只適用于那些目標(biāo)操作數(shù)是內(nèi)存操作數(shù)的指令格式:ADD,ADC,AND,BTC,BTR,BTS,CMPXCHG,CMPXCH8B,CMPXCHG16B,DEC,INC, NEG,NOT,OR,SBB,SUB,XOR,XADD和XCHG。
如果LOCK前綴與這些指令之一一起使用,并且源操作數(shù)是內(nèi)存操作數(shù),則可能會(huì)生成未定義的操作碼異常(#UD)。如果LOCK前綴與任何不在上述列表中的指令一起使用,也會(huì)產(chǎn)生未定義的操作碼異常。無(wú)論是否存在LOCK前綴,XCHG指令都始終聲明LOCK#信號(hào)。
LOCK前綴通常與BTS指令一起使用,以在共享存儲(chǔ)器環(huán)境中的存儲(chǔ)器位置上執(zhí)行讀取 – 修改 – 寫(xiě)入操作。
LOCK前綴的完整性不受存儲(chǔ)器字段對(duì)齊的影響。內(nèi)存鎖定是針對(duì)任意不對(duì)齊的字段。
操作系統(tǒng)中的實(shí)現(xiàn)
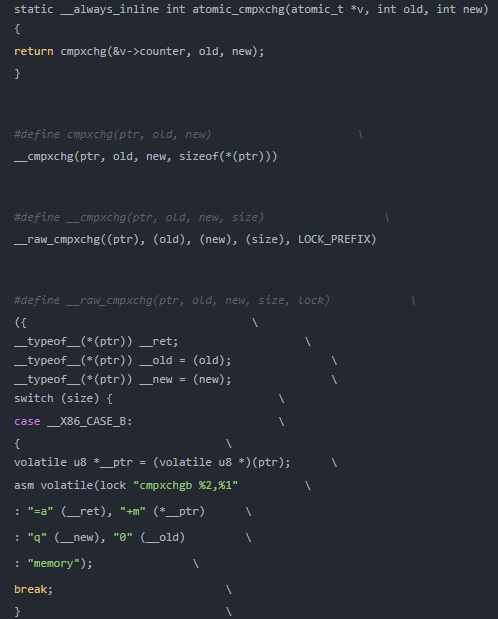
Linux源碼中對(duì)于原子自增一是如下定義的:

LOCK_PREFIX的定義如下所示:
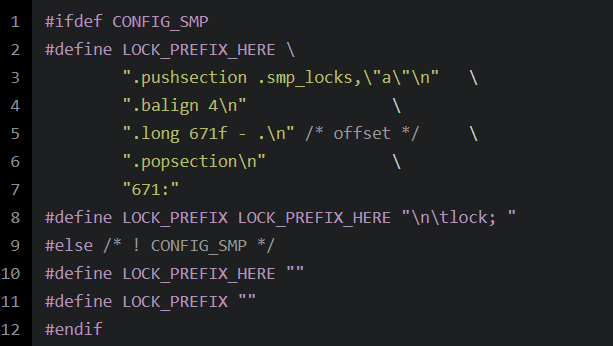
可見(jiàn):在對(duì)稱(chēng)多處理器架構(gòu)的情況下,LOCK_PREFIX被解釋為指令前綴lock。而對(duì)于單處理器架構(gòu),LOCK_PREFIX不包含任何內(nèi)容。
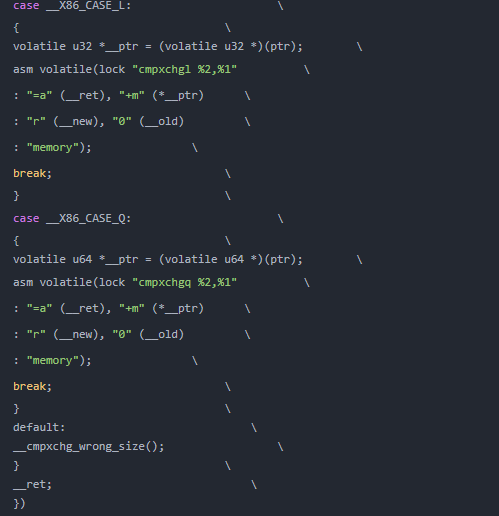
另外,對(duì)于CAS,有cmpxchg指令進(jìn)行操作。代碼如下:
ARM架構(gòu)
在ARM架構(gòu)下,沒(méi)有LOCK#指令,其具體實(shí)現(xiàn)如下:## ARMv6之前 早期的ARM架構(gòu)是不支持SMP的,這些單核架構(gòu)的CPU實(shí)現(xiàn)原子操作的方式就是通過(guò)關(guān)閉CPU中斷來(lái)完成的。
在Linux對(duì)于ARM架構(gòu)的代碼下
有如下:
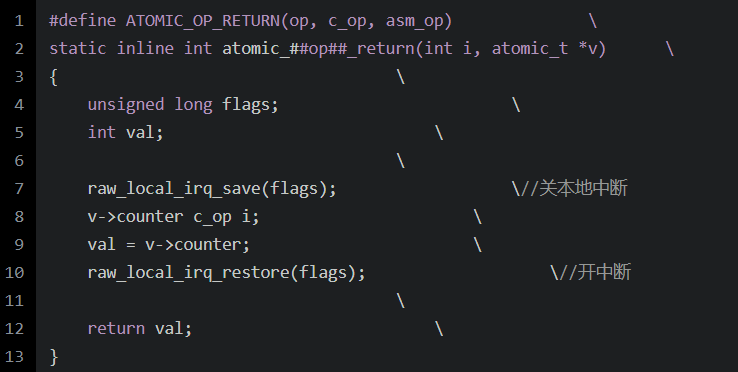
這個(gè)是好多操作共用的一套代碼。
對(duì)于cmpxchg:
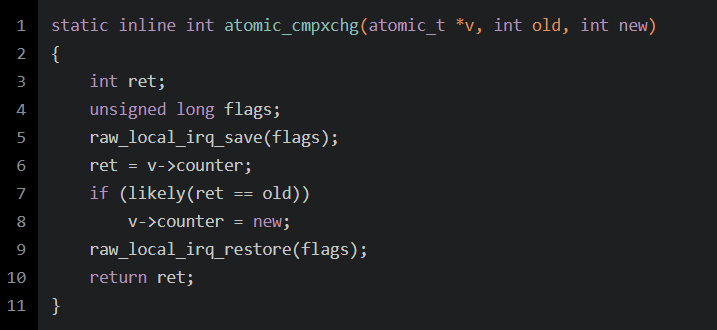
可以看到,對(duì)v->counter的操作是一個(gè)臨界區(qū),指令的執(zhí)行不能被打斷,內(nèi)存的訪問(wèn)也需要保持沒(méi)有干擾。
ARMv6以前的版本通過(guò)關(guān)本地中斷來(lái)保護(hù)這塊臨界區(qū),看起來(lái)相當(dāng)簡(jiǎn)單,其奧秘就在于ARMv6以前的版本不支持SMP。
比如經(jīng)典的read-modify-write問(wèn)題,其本質(zhì)是保持一個(gè)對(duì)內(nèi)存read和write訪問(wèn)的原子性問(wèn)題,也就是說(shuō)內(nèi)存的讀和寫(xiě)的訪問(wèn)不能被打斷。對(duì)該問(wèn)題的解決可以通過(guò)硬件、軟件或者軟硬件結(jié)合的方法來(lái)進(jìn)行。
早期的ARM CPU給出的方案就是依賴(lài)硬件:SWP這個(gè)匯編指令執(zhí)行了一次讀內(nèi)存操作、一次寫(xiě)內(nèi)存操作,但是從程序員的角度看,SWP這條指令就是原子的,讀寫(xiě)之間不會(huì)被任何的異步事件打斷。
具體底層的硬件是如何做的呢?這時(shí)候,硬件會(huì)提供一個(gè)lock signal,在進(jìn)行memory操作的時(shí)候設(shè)定lock信號(hào),告訴總線這是一個(gè)不可被中斷的內(nèi)存訪問(wèn),直到完成了SWP需要進(jìn)行的兩次內(nèi)存訪問(wèn)之后再clear lock信號(hào)。
多說(shuō)一點(diǎn)關(guān)于SWP和SWPB的內(nèi)容
這兩個(gè)指令是用來(lái)同步的,不是用來(lái)執(zhí)行原子操作的。在將獨(dú)占訪問(wèn)引入ARM架構(gòu)之前,SWP和SWPB指令常用于同步。
其局限性是:如果中斷在觸發(fā)交換操作時(shí)觸發(fā),則處理器必須在執(zhí)行中斷之前完成指令的加載和存儲(chǔ)部分,從而增加中斷延遲。由于獨(dú)立加載和獨(dú)占存儲(chǔ)是單獨(dú)的指令,因此在使用新的同步基元時(shí)會(huì)降低此效果。
但是在多核系統(tǒng)中,交換指令期間阻止所有處理器訪問(wèn)主存會(huì)降低系統(tǒng)性能。在處理器工作在不同頻率但是共享相同主存的多核系統(tǒng)中,情況尤其如此。
所以在ARMv6及以后的版本中,棄用了SWP, ARMv6架構(gòu)引入了獨(dú)占訪問(wèn)內(nèi)存為止的概念,提供了更靈活的原子內(nèi)存更新。
ARMv6體系結(jié)構(gòu)以Load-Exclusive和Store-Exclusive同步原語(yǔ)LDREX和STREX的形式引入了Load Link和Store Conditional指令。從ARMv6T2開(kāi)始,這些指令在ARM和Thumb指令集中可用。獨(dú)立加載和專(zhuān)有存儲(chǔ)提供了靈活和可擴(kuò)展的同步,取代了棄用的SWP和SWPB指令。
后來(lái)使用的是LDREX和STREX指令,在armv7之后就用了ldrex和strex:
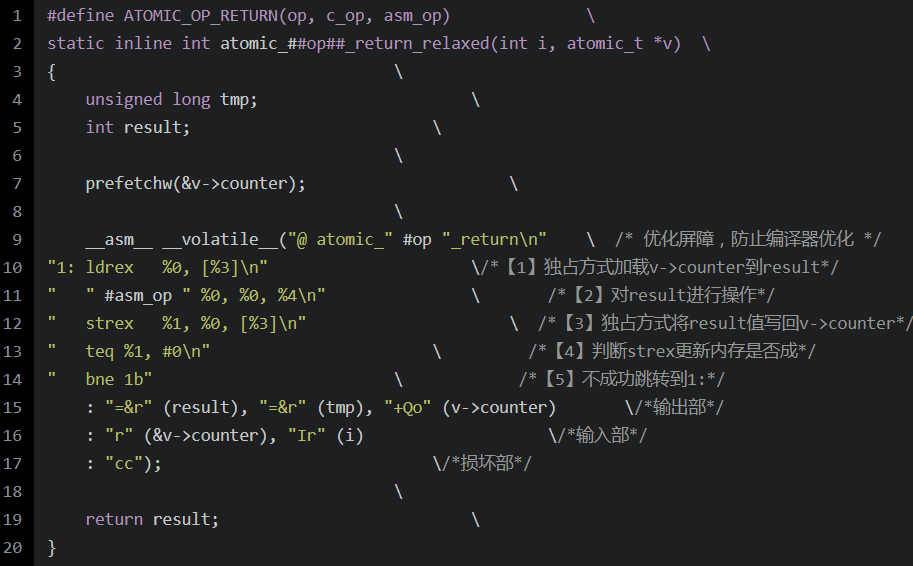
訪存指令LDREX/STREX和普通的LDR/STR訪存指令不一樣,它是“獨(dú)占”訪存指令。這對(duì)指令訪存過(guò)程由一個(gè)稱(chēng)作“exclusive monitor”的部件來(lái)監(jiān)視是否可以進(jìn)行獨(dú)占訪問(wèn)。
獨(dú)占訪存指令:
(1)LDREX R1 ,[R0] 指令是以獨(dú)占的方式從R0所指的地址中取一個(gè)字存放到R0中;
(2)STREX R2,R1,[R0] 指令是以獨(dú)占的方式用R1來(lái)更新內(nèi)存,如果獨(dú)占訪問(wèn)條件允許,則更新成功并返回0到R2,否則失敗返回1到R2。
審核編輯:湯梓紅













 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論