 電子發燒友App
電子發燒友App


TLDR(AI Claude 的總結)
本文來自一位 Python 開發者對一個龐大的 Python 項目的代碼結構的總結。
該項目包含近 3 萬個 Python 文件,由全球 400 多名開發者共同維護。為了應對代碼日益增長的復雜性,項目采用了分層架構的設計。即將代碼庫劃分為多個層級,并限制不同層級之間的依賴關系,依賴只能從上層流向下層。
文章詳細介紹了該項目的分層結構,以及如何利用 Import Linter 工具來強制執行分層規則。通過追蹤被忽略的非法 import 語句數量,可以衡量分層結構實現的進度。
分層架構確實能夠有效降低大型項目的復雜度,方便獨立開發。但也存在一些缺點,比如容易在高層產生過多代碼,完全實施分層需要花費時間等。總體來說,盡早引入分層架構,能夠減少后期的重構工作量,是管理大型 Python 項目的一個有效方式。
本文通過一個真實的大規模 Python 項目案例,生動地介紹了分層架構的實施過程、優勢和不足,對于管理大型項目很有借鑒作用。
前言
大家好,我是來自 Kraken Technologies 的 Python 開發者 David。我在的 Kraken 工作是維護一個 Python 應用,根據最新統計它擁有 27637 個模塊的。是的,你沒看錯,這個項目擁有近 28K 獨立的 Python 文件(不包括測試代碼)。
我與全球其他 400 名開發人員一同維護這個龐然大物,不斷地為它合并新的代碼。任何人只需要在 Github 上獲得一位同事的批準,就能修改代碼文件,并啟動軟件的部署,該軟件在 17 家不同的能源和公用事業公司運行著,擁有數百萬的客戶群體。
看到上面的描述,你大概率會下意識地認為這個項目的代碼肯定無比的混亂。坦白講,我也會這么想。但事實是,至少在我工作的領域,大量的開發人員可以在一個大型的 Python 項目上高效地工作。
實現這個目標的要素有很多,其中許多要素來自文化與規則而非技術,在本篇博文中,我想著重講一下我們是如何通過優化代碼組織結構來實現這一目標的。
分層架構
如果你已經負責維護某個應用的代碼倉庫一段時間,肯定會感受到隨著時間的推移代碼復雜度越來越高。在不斷開發與維護的過程中,應用中各部分的邏輯代碼混合在一起,獨立地分析應用中的某個模塊變得越來越困難。
這也是我們早期維護代碼倉庫時遇到的問題,經過研究后我們決定采用分層架構(即將代碼庫劃分成多個組件(也就是層級,后面不再注釋),并限制各組件間的引用關系)來應對這一問題。
分層(Layering)是一種較為常見的軟件架構模式,在這種模式下不同的組件(即層級,后面不在重復注釋)會被以(概念上)棧的形式組織起來。在這個棧中,下層組件不能依賴(引入)其上層組件。
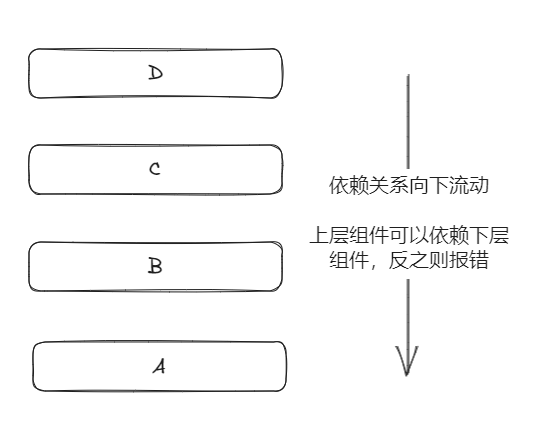 依賴向下關系流動的分層架構
依賴向下關系流動的分層架構
例如,在上圖中,C 可以依賴 B 和 A,但不能依賴 D。
分層架構的應用很寬泛,你可以自由地定義組件。例如:你可以將多個可獨立部署的服務視作多個組件,也可以直接將項目中不同部分的源碼文件視作不同的組件。
依賴關系的定義也很寬泛。通常,只要兩個組件間存在直接交叉(即使只發生在概念層級上),我們就認為它們之間存在依賴關系。間接交叉(例如通過配置傳遞)通常不被視為依賴關系。
如何在 Python 項目中應用分層架構
分層架構在 Python 項目中的最佳實踐是:將 Python 模塊作為分層依據,將導入語句視為依賴依據。
以如下項目倉庫目錄舉例:
?
myproject ?__init__.py ?payments/ ??__init__.py ??api.py ??vendor.py ?products.py ?shopping_cart.py
?
目錄中模塊之間的嵌套關系是分層的最佳依據。假設,我們決定按照一下順序進行分層:
?
#?依賴關系向下流動(即上層可以依賴下層) shopping_cart payments products
?
為了滿足上述架構的要求,我們需要禁止?payments?中的模塊從?shopping_cart?模塊中引入內容,但可以從?products?模塊中引入內容(參考圖 1)。
分層也可以嵌套,因此我們可以在 payments 模塊中繼續分層,例如:
?
api vendor
?
設置多少分層以及以什么順序進行排列沒有唯一正確的答案,需要我們不斷的在實踐中總結。但是合理的運用分層架構確實能夠有效地降低項目結構的復雜度,使其能夠更易于理解和修改。
我們是如何在 Kraken 的項目中實踐分層架構的
在我編寫這邊文章的時候,已經有 17 家不同的能源和公共事業相關的企業購買了 Kraken 的許可證。我們在內部稱呼這些企業為 client,并為每一家企業都運行了一個獨立的實例。也正因如此,Kraken 的不同實例間形成了一種「同根不同枝」的特點。
通俗地講就是不同實例間的很多行為其實是共享的,但是每個 client 也都有屬于自己的定制代碼,以滿足他們特定的需求。從地域層面來講也如此,在英國運行的所有 client 之間存在一定的共性(他們屬于同類的能源行業),而日本的 Octopus Energy 則不共享這些的共性。
隨著 Kraken 平臺的成長,我們也在不斷地優化著我們的分成架構,來幫助我們更好地滿足不同客戶的需求。目前的分層的頂層結構大致如下:
?
#?依賴關系向下流動(即上層可以依賴下層) kraken/ ????__init__.py ???? ????client/ ????????__init__.py ????????oede/ ????????oegb/ ????????oejp/ ????????... ???? ????territories/ ????????__init__.py ????????deu/ ????????gbr/ ????????jpn/ ????????... ???? ????core/
?
client 組件在結構的頂部。每一個 client 在該層都有一個專屬的子包(例如,oede 對應 Octopus Energy Germany)。在此之下的是 territories 組件,用于滿足不用國家所需的特定行為,同樣為不同地區設置了不同的子包。最底層是 core 組件,包含了所用 client 都會用到的通用代碼。
我們還制定了一個特別的規則:client 組件下的子包必須是獨立的(即不能被其他 client 引用),territories 組件下的子包也是如此。
將 Kraken 以這種分層結構構建之后,我們可以在有限的區域內(例如一個組件的子包)便捷地進行代碼的更新和維護。由于 client 組件位于結構的頂部,因此不會有任何其他組件會直接依賴于它,這樣我們就能更方便地更改特定 client 有關的內容,而且不必但因會影響到其他 client 的行為。
同樣,只更改 territories 組件內的一個子包也不會影響到其他的子包。這樣,我們就可以快速、獨立地進行跨團隊開發,尤其是當我們進行的更改只影響少量 Kraken 實例的時候。
通過 Import Linter 確保項目中的分層實現
雖然引入了分層結構,但我們很快發現,僅僅在理論上論述分層是不夠的。開發人員經常會不小心進行分層間的違規引入。我們需要以某種方式確保分層結構的理論能夠在代碼結構中被遵循,為了達到此目的我們在項目中引入了第三方庫 Import Linter。
Import Linter 是一款開源工具,用于檢查項目中的引用邏輯是否遵循了指定的結構。首先,我們需要在一個 INI 文件中定義一個描述目標需求的配置,類似這樣:
?
[importlintertop-level] name?=?Top?level?layers type?=?layers layers?= ????kraken.clients ????kraken.territories ????Kraken.core
?
我們還可以使用另外兩個配置文件強制不同的 clients、territories 之間相互獨立。類似這樣:
?
#?文件?1 [importlinterclient-independence] name?=?Client?independence type?=?independence layers?= ????kraken.clients.oede ????kraken.clients.oegb ????kraken.clients.oejp ????... #?文件?2 [importlinterterritory-independence] name?=?Territory?independence type?=?independence layers?= ????kraken.territories.deu ????kraken.territories.gbr ????kraken.territories.jpn ????...
?
然后,你可以在命令行運行?lint-import,它會告訴你項目中是否有任何導入行為違反了我們配置中的要求。我們會在每次拉取代碼的時候運行此功能,因此如果有人使用了不合規的導入,檢查就會失敗,代碼也就不會被合并。
上面展示的并不是我們項目全部的配置文件。團隊成員可以在應用程序的更深處添加自己的分層,例如:kranken.ritories.jpn 本身就是分層。我們目前擁有超過 40 個配置文件用于規定我們的分層結構。
消除技術債
我們沒有辦法在確定是由分層架構的第一時間就使整個項目符合架構需求。因此,我們使用了 Import Linter 中的一項特性,該功能允許您在檢查非法導入之前忽略對某些導入的檢查。
?
[importlintermy-layers-contract] name?=?My?contract type?=?layers layers?= ????kraken.clients ????kraken.territories ????kraken.core ignore_imports?= ????kraken.core.customers?-> ????kraken.territories.gbr.customers.views ????kraken.territories.jpn.payments?->?kraken.utils.urls ????(and?so?on...)
?
此后,我們使用項目構建時被 Import Linter 忽略的導入語句的數量作為跟蹤技術債完成度的指標。這樣,我們就能觀察到隨著時間的推移技術債的情況是否有所改善,以及改善的速度如何。
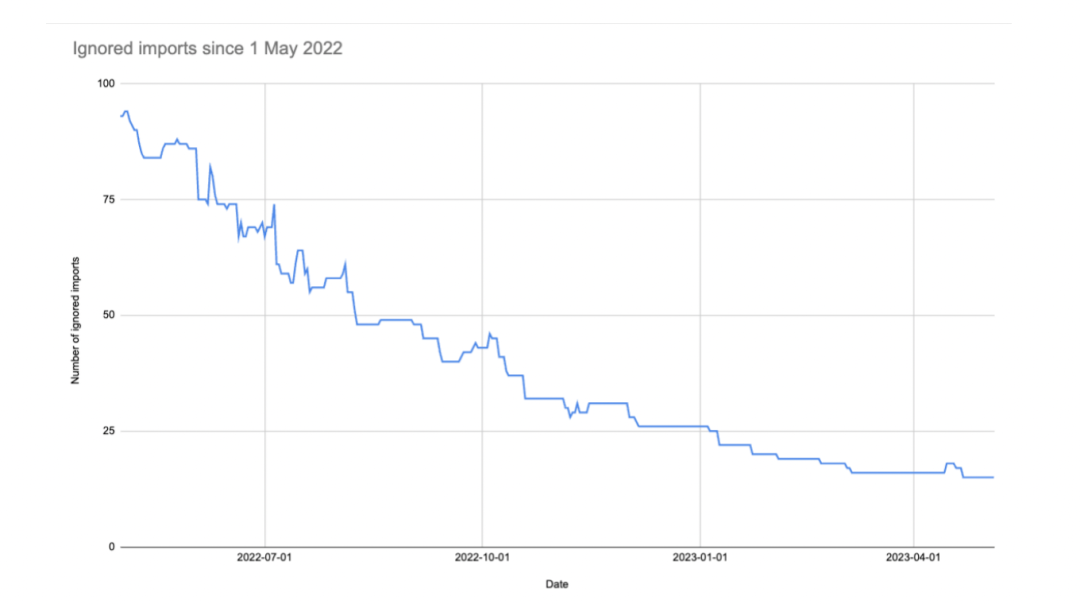 Ignored imports since 1 May 2022
Ignored imports since 1 May 2022
上圖是我們過去一年多的時間里被我們忽略的有問題的引入語句數量的變化。我會定期分享這張圖,想大家展示我們最新的工作進度,并鼓勵我們的開發者努力做到完全遵守分層結構的約定。我們對其他幾個技術債也使用了這種燃盡圖的方法去展示。
沒有銀彈,談談分層架構的缺點
復雜現實
現實世界無比的復雜,依賴關系遍布在項目的各個角落。在采用分層架構后,你會經常遇到想要打破現有層級關系的情況,會經常在不經意間從低層級的組件中調用高層級的組件。
幸運的是,總有辦法解決這類問題,那就是所謂的 控制反轉(Ioc),在 Python 中你可以很容易地做到這一點,只是需要轉換一下思維方式。不過使用這個方法會增加「局部復雜性」,但為了讓項目整體變得更加簡單,這點代價還是值得的。
結構中高層代碼過多
在分層結構中,層數越高的組件天然地越容易更改。正因如此,我們特地簡化了修改特定 clinents 或 territories 的代碼流程。另一方面,core 是一切其他代碼的基礎,修改它就成為了一件高成本、高風險的事情。
高成本、高風險的底層代碼修改行為讓我們望而卻步,促使我們編寫更多針對特定客戶或地區的高層級代碼。最終的結果就是,高層的代碼比我們想象中要多的多的多。我們仍在學習如何解決這個問題。
目前為止我們仍未完全完成
還記得之前提到過的被設置在 Import Linter 特殊配置文件中被忽略的 import 嗎?多年過去了,它仍未被全部解決,根據統計還有最少 15 個。最后的這幾個 import 也是最頑固、最難以被優化的。
我們需要付出很多的時間才能重構完一個現有項目,所以,越早分層需要面對的麻煩就越少。
總結
Kraken 的分層結構使我們在如此龐大的代碼體量下仍舊保持著健康的開發和維護,而且操作難度相對較小,特別是在考慮到它的規模的情況下。如果不對數以萬計的模塊之間的依賴關系加以限制,我們的項目倉庫很可能會像揉亂的線團一樣復雜。
但是我們選擇的代碼架構順利的幫助我們在單一的 Python 代碼庫中進行大量工作。看似不可能,但這就是事實。
如果你正在開發一個大型的 Python 項目,或者哪怕是一個相對較小的項目,不發試試分層結構,還是那句話:越早分層需要面對的麻煩就越少。
















 工商網監
工商網監
評論