 電子發燒友App
電子發燒友App


? 本文主要分享如何快速上手ARM匯編開發的經驗、匯編開發中常見的Bug以及Debug方法、用的Convolution Dephtwise算子的匯編實現相對于C++版本的加速效果三方面內容。 ?
? 01前言
神經網絡模型能夠在移動端實現快速推理離不開高性能算子,直接使用ARM匯編指令來進行算子開發無疑會大大提高算子的運算性能。初次接觸匯編代碼可能會覺得其晦澀難懂然后望而卻步,但ARM匯編開發一旦入門就會覺得語言優美簡潔,如果再切換到ARM INTRISIC指令開發反而覺得沒有直接寫匯編碼來的方便。我會在第一節分享純小白如何快速上手ARM匯編開發的經驗,第二節會列舉在匯編開發中常見的Bug以及Debug方法,第三節會展示常用的Convolution Dephtwise算子的匯編實現相對于C++版本的加速效果。如果你已經能很熟練地使用ARM匯編指令進行開發了,可以跳過第一節。
? 02從簡單函數上手
? ? 學習匯編開發重要的一點是通過學習現有函數的匯編代碼來實現自己的需求
我寫的第一個匯編算子是MaxPooling算子,算子本身的計算過程非常簡單。但當我開始實現MaxPooling的匯編代碼時,我不知道第一行代碼怎么寫,不知道開頭和結尾怎么寫,不知道中間的計算邏輯怎么寫。當時我就在MNN庫的source文件夾下面找到了一份邏輯簡單的、自己非常熟悉的Relu算子當做參照來實現MaxPooling. 之所以我推薦用一個邏輯簡單的、自己非常熟悉的算子當做學習匯編的模版,是因為當算子的計算邏輯簡單時,我們才能把注意力放在匯編函數的聲明、傳參、讀取數據、存儲結果、返回等等這些大的流程上面,至于內部的函數實現(如何計算一行數據的最大值,如何去計算一個寄存器中所有數據的累加和等等)可以暫時不去關注。學習一個新的東西時,我們找的例子模版不能過于復雜,因為這會導致我們將注意力放在例子本身的實現細節中,而忽略了如何去入門,這樣會增加我們的學習成本。 ?
匯編函數的開頭與結尾
函數定義以asm_function開頭,后加函數名(以MNNAvgPoolInt8 ARM64為例):
?
asm_function MNNAvgPoolInt8 // 加上函數的傳參注釋,方便后續對照使用對應的寄存器 // void MNNAvgPoolInt8(int8_t* dst, int8_t* src, size_t outputWidth, // size_t inputWidth, size_t kernelx, size_t kernely, size_t stridesx, // ssize_t paddingx, ssize_t factor); // Auto load: x0: dst, x1: src, x2: outputWidth, x3: inputWidth, // x4: kernelx, x5: kernely, x6: stridesx, x7: paddingx // Load from sp: // w8: factor
?
傳參:ARM64 用于傳參的寄存器有8個:x0-x7. 如果函數的參數大于8,就需要使用sp寄存器讀取剩余參數。例如AvgPoolInt8算子中的第9個參數factor讀取:
?
// x8寄存器存儲參數factor的值,不是必須使用x8寄存器,用其他寄存器也是可以的。 ldr x8, [sp, #0]? ARM寄存器使用不當會導致程序crash。這里總結了ARM32和AMR64的寄存器基本使用規則。ARM32中通用寄存器和向量寄存器都有16個,每個向量寄存器的最大使用長度是128位。ARM32中用于傳參的寄存器有4個:r0-r3。ARM32中r13寄存器就是sp寄存器,指向棧頂;r14寄存器也叫lr寄存器,存儲函數的返回值地址;r15寄存器也叫pc寄存器,存儲將要執行的下一條指令的地址。在進行匯編開發時,一般不使用r13和r15寄存器來存儲臨時變量。r9寄存器的使用在各個平臺上可能不同,為了防止出錯,一般也不用來存儲臨時變量。當不需要使用r14存儲返回值地址的信息時,也可以使用其存儲臨時變量。下圖中我總結了ARM32中寄存器的基本使用規則,關于各寄存器更加詳細的介紹參考。 ?
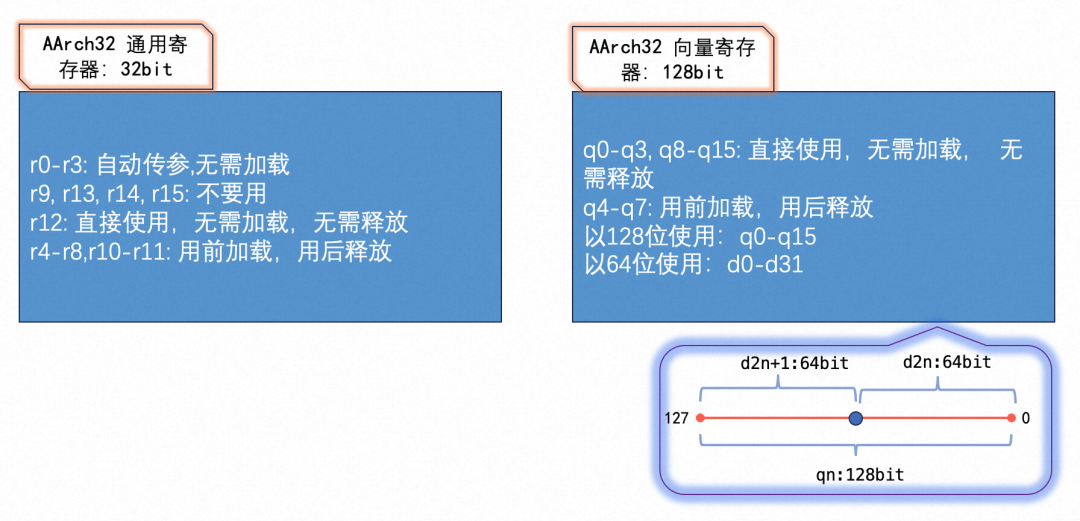
?
ARM64中通用寄存器和向量寄存器的個數比ARM32多一倍,有32個。ARM64中向量寄存器的使用更加靈活,可以8bit,16bit,32bit,64bit使用。例如,v0表示128位的向量寄存器,d0,s0,h0分別表示v0的低64位,32位,16位。注意,d1,s1,h1表示v1寄存器的低64位,32位,16位,而不是緊接著v0的第二個相應位。ARM64的寄存器使用見下圖。
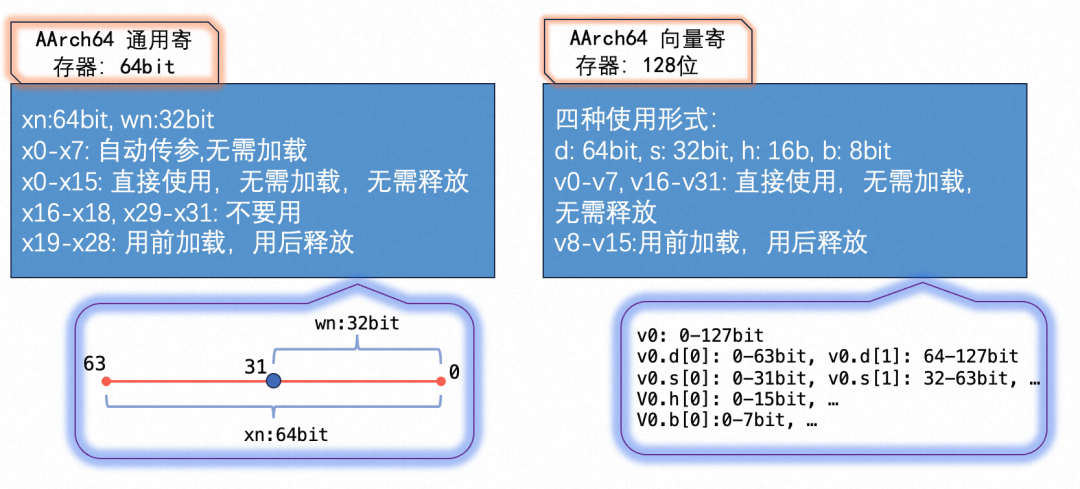
? 我們可以用浮點操作指令把向量寄存器中的數當做標量來進行計算,需要注意在ARMV8中浮點操作指令不支持對16bit的浮點數進行計算,僅支持做16bit和32bit, 64bit之間的轉換。 ?
fadd Sd, Sn, Sm // 32bit Single precision fsub Dd, Dn, Dm // 64bit Double precision fcvt Sd, Hn // half-precision to single-precision fcvt Dd, Hn // half-precision to double-precision fcvt Hd, Sn // single-precision to half-precision fcvt Hd, Dn // double-precision to half-precision?
?
對上圖中的“用完恢復”寄存器的使用:一些復雜的函數需要的向量寄存器或者通用寄存器可能會非常多,那就需要我們在開頭加載這些寄存器,不然會報錯segment fault.加載方法如下:
?
// d8-d15表示使用v8-v15這8個寄存器的64位, (2* 64)/8=16, // 這就是每次sp移位時(#16*i)中16的來源。 stp d14, d15, [sp, #(-16 * 9)]! stp d12, d13, [sp, #(16 * 1)] stp d10, d11, [sp, #(16 * 2)] stp d8, d9, [sp, #(16 * 3)] stp x27, x28, [sp, #(16 * 4)] stp x25, x26, [sp, #(16 * 5)] stp x23, x24, [sp, #(16 * 6)] stp x21, x22, [sp, #(16 * 7)] stp x19, x20, [sp, #(16 * 8)]?
?
在函數的結尾需要釋放這些寄存器:
?
ldp x19, x20, [sp, #(16 * 8)] ldp x21, x22, [sp, #(16 * 7)] ldp x23, x24, [sp, #(16 * 6)] ldp x25, x26, [sp, #(16 * 5)] ldp x27, x28, [sp, #(16 * 4)] ldp d8, d9, [sp, #(16 * 3)] ldp d10, d11, [sp, #(16 * 2)] ldp d12, d13, [sp, #(16 * 1)] ldp d14, d15, [sp], #(16 * 9) ret // 最后需加上ret返回? ARM32中寄存器的數量只有ARM64的一半,自動傳參的寄存器僅r0-r3這四個寄存器,其他寄存器的加載方式和ARM64也不同,我們依然以MNNAvgPoolInt8為例,代碼的解釋和新手閉坑的地方我直接在下面的注釋中寫明。
// 函數定義
asm_function MNNAvgPoolInt8
// void MNNAvgPoolInt8(int8_t* dst, int8_t* src, size_t outputWidth,
// size_t inputWidth, size_t kernelx, size_t kernely, size_t stridesx,
// ssize_t paddingx, ssize_t factor);
// Auto load: r0: dst, r1: src, r2: outputWidth, r3: inputWidth
// r4: kernelx, r5: kernely, r7: stridesx, r8: paddingx, lr: factor
// 其他寄存器加載, 注意lr寄存器每次必須被push進來(可以不使用),不然會報錯segment fault.
push {r4-r8, r10-r11, lr}
// 上一行push了8個寄存器,那么sp指針會向低地址移動(8*4=32)個字節(ARM32每個指針占4個字節),
// 所以第五個參數“kernelx”加載時需要將sp的地址加(#32).
// 虛擬內存中棧是從高地址向低地址擴展的,而函數傳參是從右往左傳去棧中的,
// 所以后面的參數地址會比前面的高,即相對sp寄存器的地址增加的更多。
ldr r4, [sp, #32] // kernelx
ldr r5, [sp, #36] // kernely
ldr r7, [sp, #40] // stridesx
ldr r8, [sp, #44] // paddingx
ldr lr, [sp, #48] // factor
// 加載向量寄存器一定要放在利用sp寄存器來讀取所有函數參數之后,
// 否則不能正常讀取函數參數
vpush?{q4-q7}
?
ARM32 結尾對寄存器的釋放
?
// 不需要pop lr寄存器,但是必須pop pc寄存器。
// ARM32結尾不需要寫 ret, 這和ARM64不同。
vpop {q4-q7}
pop {r4-r8, r10-r11, pc}
?
??核心功能的實現
? 寫匯編代碼之前,我們一定要先實現C++版本的代碼,保證C++版本的算子在ARM移動端的計算結果是正確的。這樣做有兩個目的:第一,保證我們對算子的理解是正確并清晰的,否則寫匯編算子就是浪費時間;第二,為匯編算子的輸出結果提供標準答案,因為同樣的 C++ 代碼在不同的平臺上的計算結果可能會略有不同(但差異不會很大),我們需要保證匯編版本的算子和C++版本的算子計算結果在ARM平臺上完全一致。 ?
匯編代碼中條件判斷和分支跳轉
? MaxPooling算子通過遍歷局部區域的所有元素,進而找到區域內的最大值。這就涉及到循環指令、地址跳轉指令和比較兩個向量寄存器中對應元素。關于指令的解釋我直接在代碼注釋中寫明。 ?
比較兩個向量寄存器中對應元素的大小
?
/* smax, smin 比較整型數數據的大小 ARM匯編有符號整數的指令一般以s開頭(signed int) 無符號整數的指令一般以u開頭(unsigned int) 浮點數據的指令一般以f開頭(float) */ // 比較v0和v1寄存器中的16個int8_t數據, // 并將對應位置上的較大值存儲在v2的相應位置上 // b 表示以8位來讀取數據,相應的匯編中 h:16位, s:32位, d:64位 smax v2.16b, v0.16b, v1.16b smin v10.4s, v11.4s, v12.4s //比較v11和v12的4個int32_t數據的大小?
?
循環執行某一段代碼
如果需要在ARM匯編中循環執行一段代碼,那我們需要自定義一個符號來標記這一段代碼。以MaxPooling算子為例,假設每一個像素點含有16個Channel,我們需要得到被kernel覆蓋到的9個像素點上對應Channel的最大值,即重復執行比較指令9次。例如用Loop來標記我們需要循環的代碼段:
?
1. mov w7, #-0x80 // 給通用寄存器賦值-128,即int8_t類型的最小值
2. dup v0.16b, w7 // 初始化v0, v0中存儲了16個-128
3. mov x10, #9 // 計數
// 循環
Loop:
3. ld1 {v1.16b}, [x0] // 從地址x0中加載16個int8的數據到v1寄存器,與v0做比較
4. smax v0.16b, v0.16b, v1.16b // 用v0記錄最終的比較結果
5. add x0, x0, #1 // 移動像素點的地址,這里我們假設9個像素點是連續的
6. sub x10, x10, #1 // 比較完一個像素點的16個Channel大小后,計數減1
7. cmp x10, #0 // cmp是compare的縮寫:比較x10和0的大小
8. bgt Loop // bgt是branch greater than的縮寫,滿足條件就跳到分支Loop執行
// 循環執行結束
9. st1 {v0}, [x1] // 存儲寄存器v0中的16個int8_t數據到地址x1中
// ARM 匯編代碼是按照從上到下的順序來執行的,
// 所以跳出Loop不需要額外的指令來表示結束該分支
// 當不滿足x10>0時,會直接執行第9行代碼
? ??如何查找需要的指令 ?
靈活地運用各種匯編指令往往能提高算子性能。
利用現成的匯編代碼查找指令
? 當我們閱讀一些匯編代碼時,根據匯編指令去查詢其功能是非常容易的,甚至根據指令名我們可以猜測出他的功能。但是當我們第一次寫匯編代碼時,想知道實現某個功能可以使用哪些指令往往很難。此時最關鍵的一點,需要我們思考哪個函數中會用到我將要實現的功能,然后去參考他的匯編實現過程。比如寫Pooling算子的匯編代碼時不知道如何去進行循環代碼段的編寫,我們就可以參考矩陣乘算子的匯編代碼去學習分支跳轉,寄存器的比較等指令。當我們不知道如何用匯編指令去實現浮點數轉整數的四舍五入時,MNN中現成的Float2Int8函數一定會有相應的指令實現這個功能。當我們編寫了越來越多的匯編代碼,會接觸到更多的匯編指令,解決問題的思路和視野也更開闊。 ?
利用關鍵詞在ARM官網查找指令
ARM官網列舉了所有匯編指令的用法,其中ARM64的指令手冊比ARM32更易查找和理解。一般ARM64的指令在ARM32系統都能找到對應的等效指令。偶爾我們也需要ARM Intrisic指令來完成一些簡單函數的開發,Intrisic指令可以參考。利用好功能的關鍵詞能提高查找指令的速度。例如某次編程中我需要查找哪些指令能實現“int8+int16->int16"的功能,顯然關鍵詞是"add". 官網中會列舉適用于各種場景的向量加法指令,很快就可以定位到"saddw v0.8h, v1.8h, v2.8b"指令。
03ARM匯編Debug方法和常見錯誤列舉
?利用好“打印printf”
匯編代碼的調試一直是個難題,不能像C++代碼那樣一步步Debug查看變量的值,只能通過在函數調用的外層加打印的方式來查看匯編代碼的執行結果。不過只要我們能利用好打印,匯編代碼的BUG排查就能簡單不少!具體來說,如果我們需要查看某個中間變量的值,我們可以在代碼內部用返回值地址來存儲該值,從而我們可以在匯編代碼的外部打印該地址存儲的內容,這樣間接地檢查代碼執行的邏輯是否符合預期。
??函數傳參錯誤
函數傳參錯誤非常容易被忽視,因為這個錯誤很少會直接報錯"segment fault",而是發現匯編算子的結果和C++版本不一致時,經過一步步排查才發現傳參就出現了錯誤。畢竟我們發現結果錯誤時,更習慣于去檢查匯編代碼中最復雜的邏輯,不太會想到代碼開頭的函數傳參就已經錯了。目前為止,我遇到過的傳參錯誤就只有以下兩種:
1、除了整型以外的數據傳參應該用指針傳入,而不是直接傳入參數值。浮點參數傳遞方式與編譯器及參數配置相關,可能不同平臺下傳遞方式不一樣。如果直接浮點數值傳參,帶來的結果有可能是:浮點參數后面的參數數值都是前一個參數的數據,也就是發生了傳參的偏移,導致計算結果對不上;如果恰巧你需要從某個參數中load數據,該參數的值受到了浮點參數錯誤傳遞的影響,那有可能會報segment fault的錯誤。
?
// 正確傳參,用指針傳遞浮點常數para0 void func(float* para0, float* dst) // 錯誤傳參,直接傳入常數para0 void func(float para0, float* dst)? 2、傳參寄存器使用錯誤
ARM64 自動傳參的寄存器有8個:x0-x7,ARM32 自動傳參的寄存器有4個: r0-r3。如果參數個數大于8(4),就需要從sp寄存器的相對位置來load參數。
asm_function MNNAvgPoolInt8 // 加上函數的傳參注釋,方便后續對照使用對應的寄存器 // void MNNAvgPoolInt8(int8_t* dst, int8_t* src, size_t outputWidth, // size_t inputWidth, size_t kernelx, size_t kernely, size_t stridesx, // ssize_t paddingx, ssize_t factor); // Auto load: x0: dst, x1: src, x2: outputWidth, x3: inputWidth, // x4: kernelx, x5: kernely, x6: stridesx, x7: paddingx // Load from sp: // w8: factor?
?
3、整型參數建議使用ssize_t和size_t傳參
定義一個函數:void func(int8_t* dst, int8_t* src, float* params0, float* params1, int width, int height, int kernelx, int kernely, int needBroadcast)
按照前面的介紹,第9個參數needBroadcast應該由sp寄存器來加載,如:ldr x8, [sp, #0],如果我們需要比較needBroadcast和0的大小,寫成:cmp x8, #0,無論x8是否為0,代碼的判斷結果都會是false.除非將判斷語句寫成:cmp w8, #0. 出現這種問題的原因在于,ssize_t和size_t這兩種類型,ARM64和ARM32會將其分別看做是64位和32位的數據,而對于int類型的數據,ARM64和ARM32上都會是32位的數據,而ARM64的通用寄存器以x來使用是64位的(即x1,x2...),以w來使用才是32位的(即w1,w2...)。所以要比較x8與0的大小關系,應是:cmp,w8,#0.
對于上述問題的更好的解決辦法是,函數聲明時將needBroadcast參數的類型定義成ssize_t,因為該參數的取值可能是-1,1,0, 我們將其定義成有符號類型。在匯編代碼中再次使用 cmp x8, #0來比較結果就是正確的了,當然此時我們還是用w8和0比較的話,結果也是正確的。
??ARM32 向量寄存器和參數加載的順序問題
? 在匯編開發中我遇到過這樣的問題,定義一個函數如下:
// void MNNAvgPoolInt8(int8_t* dst, int8_t* src, size_t outputWidth,
// size_t inputWidth, size_t kernelx, size_t kernely, size_t stridesx,
// ssize_t paddingx, ssize_t factor);
asm_function MNNAvgPoolInt8
// Auto load: r0: dst, r1: src, r2: outputWidth, r3: inputWidth
// Load from sp: r4: kernelx, r5: kernely, r7: stridesx, r8: paddingx, lr: factor
2. push {r4-r8, r10-r11, lr}
3. vpush {q4-q6}
4. ldr r4, [sp, #32]
5. ldr r5, [sp, #36]
6. ldr r7, [sp, #40]
7. ldr r8, [sp, #44]
8.?ldr?lr,?[sp,?#48]???????//?lr:?factor
?
這樣可能不會出現報錯segment fault,但是參數的加載結果是錯的。原因在于第3行vpush應該在通過sp加載完所有的函數參數之后,而不是在此之前。因為push了8個通用寄存器入棧之后,再push向量寄存器入棧,那么函數參數相對于sp寄存的位置就不再是(8x4=32). 相對位置的偏移發生了變化。第3行的代碼應該在第8行后面。 ?
??ARM64 通用寄存器的使用問題
? 在ARM64中給通用寄存器賦整型數值
// 通用寄存器的賦值只能用32位來使用寄存器 mov w10, #0 // right mov x10, #0 // error // 后續計算中要使用x10來進行加減乘的計算,需要將w10擴展成x10: uxtw x10, w10 // w10中32位數據在x10的低32位中保持不變,x10的高32位填充為0.? sub, add等指令只能對整型數據操作,浮點類型數據需要使用fsub, fadd等
fmov v1.4s, #1.0 fmov v2.4s, #0.2 fsub v1.4s, v1.4s, v2.4s?
?
??四舍五入的問題
ARM32和ARM64中浮點數取整的方式不一樣。ARM32中浮點數轉換成整數的指令(vcvt.s32.f32)是向負無窮取整的,在ARM32中沒有四舍五入的取整指令。需要在ARM32中實現四舍五入,可以這樣做:
?
//對寄存器q3中的4個浮點數據做四舍五入取整 // q3: -1.4, 4.5, 1.1, -2.7 -> q3: -1, 4, 1, -3 vmov.f32 q1, #0.5 vmov.f32 q2, #-0.5 vcgt.f32 q12, q3, #0 vbsl.f32 q12, q1, q2 // bitwise select. vadd.f32 q13, q12, q3 vcvt.s32.f32 q3, q13? ARM64提供的取整指令更加靈活方便,有:
// q10: -1.4, 4.5, 1.1, -2.7 fcvtas q1, q10 // q1: -1, 5, 1, -3 就近取整 fcvtzs q2, q10 // q2: -1, 4, 1, -2 向0取整 fcvtms q3, q10 // q3: -2, 4, 1, -3 向負無窮取整 fcvtps q4, q10 // q4: -1, 5, 2, -3 向正無窮取整 fcvtns q4, q10 // q4: -2, 4, 2, -2 向最近的偶數取整?
?
??整型數據和浮點數據進行數學運算的問題
整型數據與浮點數據進行相加或相乘等數學運算之前,一定要先將整型數據轉換成浮點數據再進行數學運算,否則計算結果會出錯。該過程經常出現在Int8量化算子的開發中,往往是量化算子很難消除的計算負擔。用Binary multiply的Int8量化算子舉例說明該過程:
?
// Int8 量化的乘法算子,輸入和輸出均是Int8類型,但考慮到int8xint8會可能會導致越界, // 在量化算子的實現過程中會將兩個輸入數據分別轉換成Float32數據之后相乘, // 再將Float32的結果量化到Int8類型. sxtl v0.8h, v0.8b // int8x8_t -> int16x8_t sxtl v1.8h, v1.8b // int8x8_t -> int16x8_t sxtl v2.4s, v0.4h // v0的低64位數據:int16x4_t -> int32x4_t sxtl2 v3.4s, v0.8h // v0的高64位數據:int16x4_t -> int32x4_t sxtl v4.4s, v1.4h sxtl2 v5.4s, v1.8h scvtf v2.4s, v2.4s // int32x4_t -> float32x4_t scvtf v3.4s, v3.4s scvtf v4.4s, v4.4s scvtf v5.4s, v5.4s fmul v2.4s, v2.4s, v6.4s // v6.4s: float32x4_t 量化scale參數 fmul v3.4s, v3.4s, v6.4s fmul v4.4s, v4.4s, v6.4s fmul v5.4s, v5.4s, v6.4s ...? 此處有同學可能會質疑這么麻煩還有必要開發Int8量化的乘法算子嗎?具體原因可以參考之前關于開發Pooling量化算子的ATA文章,開頭有說明原因。 ?
?
?Segment fault出現的可能原因總結
在這里總結目前我遇到過的程序crash情況,后續也會在此添加更多的bug。
數據加載、存儲時,地址寄存器使用錯誤
函數參數加載地址時是否使用了錯誤的寄存器;
寫代碼過程中,是否給存儲地址的寄存器賦值了,導致寄存器的內容改變;
循環加載、存儲數據時,原地址累加是否導致了越界;
寄存器開頭和結尾是否相應地pushpop(stpldp)
通用寄存器的加減出錯,大多由于賦值錯誤或函數加載錯誤而間接導致
通用寄存器的內容是否符合預期,可使用Printf的辦法驗證
ARM64和ARM32中用于自動加載函數參數的寄存器個數分別是8個、4個
ARM64中通用寄存器賦值只能用32位,即w0,w1...根據需要決定是否使用uxtw擴展到相應的x0,x1...
函數參數類型聲明錯誤,導致加載錯誤
非整型函數參數一律用指針傳遞
整型常數參數盡量使用ssize_t, size_t
是否設置了循環退出條件,比如用于計數寄存器是否每次減1,循環退出條件是否能滿足
有一些寄存器是否忘記push就直接使用了,參考1.1節中的圖查詢哪些寄存器需要用完恢復
? 04ARM匯編的加速效果 ?
拿ConvolutionDepthwise的Int8量化算子舉例說明,C++版本的算子實現和ARM匯編版本的性能差距。測試模型中含有超過20個ConvolutionDepthwise算子。測試機我選擇了高端機華為Mate40 Pro和中端機華為P30 Pro,并使用ARM V8.2平臺的相關指令編寫匯編算子。測試結果中顯示的時間是該模型中所有ConvolutionDepthwise算子的耗時總和,顯然在ARM V8.2 64位平臺上,匯編算子的性能提高了約4.7倍。
| ? | C++版本 | ARM V8.2 匯編 |
|---|---|---|
| 華為Mate40 Pro | 11.28 ms | 1.98 ms |
| 華為P30 Pro | 12.83 ms | 2.22 ms |
05團隊介紹 ?
大淘寶技術Meta Team,負責面向消費場景的3D/XR基礎技術建設和創新應用探索,通過技術和應用創新找到以手機及XR 新設備為載體的消費購物3D/XR新體驗。團隊在端智能、商品三維重建、3D引擎、XR引擎等方面有深厚的技術積累。先后發布端側推理引擎MNN,端側實時視覺算法庫PixelAI,商品三維重建工具Object Drawer等技術。團隊在OSDI、MLSys、CVPR、ICCV、NeurIPS、TPAMI等頂級學術會議和期刊上發表多篇論文。
審核編輯:湯梓紅









 工商網監
工商網監
評論