 電子發燒友App
電子發燒友App


推進下一代低延遲以太網

今天的人工智能應用是由大型語言模型(llm)驅動的,這些模型是在大量非結構化數據上訓練的。llm的有效性與訓練中使用的參數數量成正比。例如,GPT-3擁有1750億個參數,而GPT-4預計將超過1萬億個參數。為了跟上人工智能性能的預期改進,預計LLM參數將每四個月翻一番。集群規模的計算是滿足下一代人工智能指數級計算需求的必要條件,而在這個時代,更快的互聯速率對于實現更高效的機架通信的重要性變得明顯,需要下一代低延遲以太網。
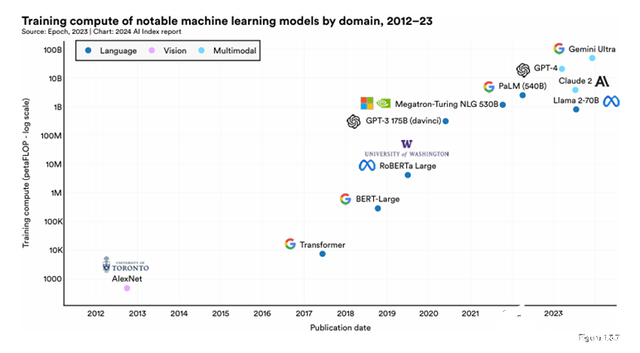
從集群規模面,云廠商公開的資料顯示目前亞馬遜基于以太網的集群超過6萬臺服務器,Oracle超過3萬臺服務器,Meta超過2萬臺,字節超過1萬臺。這些超大集群網絡都有部署基于以太網的后端網絡。
從市場預測面,相關機構預測以太網的在RDMA板塊的增速將逐步超越Infiniband,預計到2026年將獲得比Infiniband更高的市場收入。
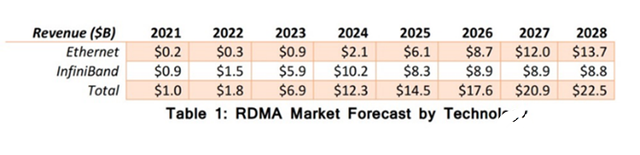
(Source: 650 Group)
從成本面,舉個例子,Meta最新采用了基于InfiniBand網絡的2.4萬卡數據中心,總投資可達9.1億美金,其中InfiniBand網絡部分的成本就占了20%以上;單個交換機成本超過35000美金,總體交換機開銷在接近7000萬美金。
相比之下,采用了博通芯片的相關交換機售價僅為其一半不到。如果該數據中心采用以太網,Meta可以節省超過9100萬美金。從云廠商/下游廠商的長期成本和性價比來看,隨著以太網性能的持續提升以及其具備的普遍性和經濟性,在滿足整體算力需求及延遲性能的條件下,下游廠商未來使用以太網的意愿有望持續提升。
國內外 all In 以太網進階賽
超級以太網聯盟和SNIA主席J Metz表示:“在AI訓練過程中,尾部延遲或者說組件間的通信速度,直接影響GPU的利用率。尾部延遲越低,計算資源的工作效率就越高。然而,將尾部延遲降至200納秒以下——對這些應用程序和工作負載來說的理想水平并非PCIe和CXL等互連技術所能實現的。超級以太網的誕生將傳統以太網推向了一個新的高度,使其準備好迎接需要超低延遲和高速度的新一代HPC和AI工作負載。”

2023年7月,超以太網聯盟(Ultra Ethernet Consortium,簡稱UEC)成立,其中成員包括AMD、Arista、博通、思科、Meta和微軟等,旨在解決以太網實際應用過程中的諸多不足。英偉達采取了以太網與IB并行的經營策略,其Spectrum-X解決方案同樣基于以太網設計。據外媒消息,英偉達在今年7月份也加入了UEC ,有望助力推進其在以太網層面的產品及相關業務部署。
Nvidia is a member of the UEC because our strategy is to support networking specifications that can be beneficial to our customers. We may want to offer a UEC version of Ethernet in the future, alongside Spectrum-X and potentially other specifications in the future. (外媒原文)
超以太網聯盟(UEC)將專注于為高性能人工智能優化和可擴展的完整的經濟高效的以太網架構。為了實現其集成解決方案的使命,它成立了八個工作組:物理層、鏈路層、傳輸層、軟件層、存儲、管理、合規與測試、性能與調試。
下圖簡約說明了AI架構拓撲的一種類型,其中有幾個不同的網絡,每個網絡都有不同的功能。前端是傳統的以太網網絡連接,而后端是向外擴展(UEC)網絡。還有一個擴展網絡連接cpu和xPU加速器。
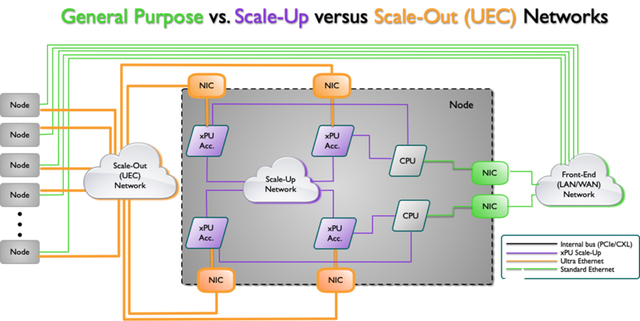
Source: Ultra Ethernet Consortium
從上圖來看,Scale UP網絡層面主要是通過xPU加速芯片片內及片間通信來完成,而Scale Out網絡層面則重點指出了智能網卡與xPU加速芯片以及UEC網絡間的通信。
國內生態以太網超節點項目在行動
近期,ODCC(開放數據中心委員會)網絡工作組啟動了ETH-X超節點系列項目。該項目由中國信通院、騰訊聯合服務器廠商,交換機廠商、ODM廠商、芯片等上下游合作伙伴共同推動,以產品化樣機以及相關技術規范為目標,打造大型多GPU互聯算力集群系統。
ETH-X超節點項目提供了一種新的探索方向,旨在基于以太網技術,實現高帶寬容量,構建一個開放且可擴展的Scale Up超節點體系。據ODCC披露,ETH-X超節點在訓練和推理側模型場景下,Scale up帶來的性能(從通信數據速度和計算效率兩大層面)提升遠超過成本的增加并能夠實現綜合收益的提升。
交換機基于以太網的不俗表現
Scale Out網絡從Tray to Tracy, Rack to Rack互聯層面上來說,Leaf Switch 和 智能網卡NIC都是非常關鍵的互聯組件。在 Datacenter 規模擴大過程中,服務器數量的增加以及集群更高帶寬更低延遲的通信需求一定會帶來智能網卡和Leaf Switch 的需求增長。
Leaf Switch是一種機架級交換機,主要用于將同一機架內的多臺服務器通過高速網絡互聯起來。它可以與服務器的網卡對接,從而組成機架內部的高速網絡。在以太網層面,交換機領軍廠商Arista 以及數據中心多方案解決方案提供商Broadcom就是具有代表性的企業。
交換機行業巨頭Arista Network在一次財報電話會議上披露,該公司與Broadcom合作開發的AI集群,基于Arista以太網產品的運行速度至少比英偉達的InfiniBand快了10%。而且Arista的以太網產品在Meta今年三月推出的兩個超大規模算力集群中,性能完全不遜色于Infiniband。此外,Arista預計到2025年能夠連接1萬到10萬個GPU。

博通在數據中心領域具有更強勢的地位,其產品線覆蓋交換機、Xpu加速芯片、高速光模塊等。博通也是最早首發光模塊CPO形態樣機的一家公司。該公司在24年6月舉行的FY24 Q2業績會上宣稱目前八個最大的GPU集群當中,有七個使用以太網,并且博通認為25年所有的超大規模集群都將采用以太網組網;
在產品方面,隨著集群網絡對于智能網卡速率要求往400G及以上不斷演進,博通在上半年發布了最新的高可擴展,高性能,低功耗400G PCIe Gen 5.0以太網網卡產品組合。以解決人工智能數據中心中XPU帶寬和集群規模快速增長時的連接瓶頸。

奇異摩爾:基于以太網RoCE v2 RDMA的全棧互聯架構解決方案
在網絡互聯層面的互聯架構產品解決方案均基于以太網RDMA RoCE V2,相比私有協議和網絡,具有更開源的軟硬件兼容性。
我們的互聯架構解決方案同時可覆蓋Scale Up & Scale Out網絡擴展方案,全面加速服務器集群互聯通信。
目前800Gps以太網已經實現商用部署,1.6Tbps以太網有望在2025年實現成熟商用。在服務器集群與GPU卡間互聯側,奇異摩爾AI原生智能網卡SmartNIC(高達800G速率)與網絡互聯加速芯粒系列均基于以太網RDMA 技術構建,更符合國內智算中心主流的軟硬件系統搭建,滿足集群間/GPU卡間高速通信需求。
奇異摩爾的Die2Die IP 基于UCIeV 1.1國際標準協議,提供32 Gbp可作為第三方獨立IP,兼容各家產品的互聯互通。同時我們也是國內為數不多布局Central I/O Die 互聯芯粒的廠商并已成功實現流片(如AMD基于CPU內建 I/O die)。I/O Die 系列產品包括2.5D/3D 互聯芯粒,通過UCIe V 1.1 D2D形成片內不同模塊的互聯,支持各類互聯接口,皆在賦能國內芯片企業制造出更高算力、更高性能的芯片。
寫在最后,未來的超大規模網絡是基于以太網還是Infiniband,又或是并存的一種網絡生態。正如AMD 蘇媽所堅持的,“行業沒有一種萬能的解決方案,因此模塊化和開放性將允許整個生態系統在他們想要創新的地方進行創新。”無論是UEC,還是UCIe 標準,未來可預見的是更多標準與生態的出現。半導體行業正是這樣一個引領科技創新的產業,在不斷的技術應用探索中,推動現代科技的發展,為人類社會帶來變革。





























 工商網監
工商網監
評論