 電子發燒友App
電子發燒友App


遇到網絡故障的時候,你一般會最先使用哪條命令進行排障?
除了Ping,還有Traceroute、Show、Telnet又或是Clear、Debug等等。
今天安排的,是Traceroute排障命令詳解,給你分享3個經典排障案例哈。
01
Traceroute原理和功能
Traceroute是為了探測源節點到目的節點之間數據報文所經過的路徑。
利用IP報文的TTL域在每經過一個路由器的轉發后減一,當TTL=0時則向源節點報告TTL超時這個的特性。
Traceroute首先發送一個TTL為1的Icmp request報文,因此第一跳發送回一個ICMP錯誤消息以指明此數據報不能被發送(因為TTL超時)。
之后Traceroute再發送一個TTL為2的報文,同樣第二跳返回TTL超時,這個過程不斷進行,直到到達目的地。
此時,由于數據報中使用了無效的端口號(缺省為33434),目的主機會返回一個ICMP的目的地不可達消息,表明該Traceroute操作結束。
Traceroute記錄下每一個ICMP TTL超時消息的源地址,從而提供給用戶報文到達目的地所經過的網關IP地址。
Traceroute 命令用于測試數據報文從發送主機到目的地所經過的網關。
主要用于檢查網絡連接是否可達,以及分析網絡什么地方發生了故障。
02
不同平臺的Traceroute命令
?01??RGNOS平臺的Traceroute命令?
舉個例子,在銳捷RG系列路由器上,Traceroute命令的格式如下:
Traceroute host?『destination』
例如:查看到目的主機10.15.50.1 中間所經過的網關。
RG#?traceroute 10.15.50.1 ?Type esc/CTRL^c/CTRL^z/q to abort. traceroute 192.168.0.1?......? 1 10.110.40.1????????
????1 4 ms??5 ms??5 ms ?2 10.110.0.64??????????
??10 ms??5 ms??5 ms ?3 10.110.7.254????????
??10 ms??5 ms??5 ms ?4 10.3.0.177??????????????
175 ms??160 ms??145 ms ?5 129.9.181.254???
?????185 ms??210 ms??260 ms ?6 10.15.50.1??????????
????230 ms??185 ms??220 ms Trace complete successfully.
?02??Windows平臺的Tracert 命令?
在PC機上或Windwos為平臺的服務器上,Tracert命令的格式如下:
tracert?[?-d?]?[?-h maximum_hops?]?[?-j host-list?]?[?-w timeout?]?host
-d :不解析主機名。
-h:指定最大TTL大小。
-j:設定松散源地址路由列表。
-w:用于設置UDP報文的超時時間,單位毫秒;例如:查看到目的主機10.15.50.1 中間所經過的前兩個網關。
:>tracert?-h 2 10.15.50.1 Tracing route to 10.15.50.1 over a maximum of 2 hops: ??1?????3 ms?????2 ms?????2 ms??10.110.40.1 ??2?????5 ms?????3 ms?????2 ms??10.110.0.64 Trace complete.
03
使用Traceroute命令進行故障排除
?排障案例①??使用Traceroute命令定位不當的網絡配置點?
1、現象描述:
組網情況如下圖所示:
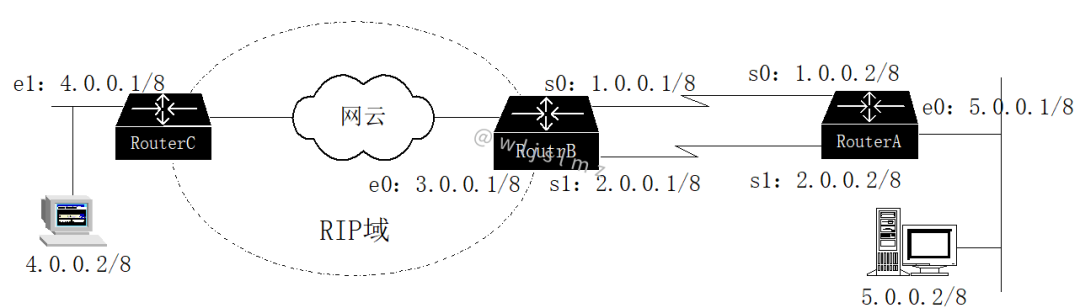
某校園網中,RouterB和RouterC同屬于一個運行RIPv2路由協議的網絡,主機4.0.0.2訪問數據庫服務器5.0.0.2,用戶抱怨訪問性能差。
2、相關信息:
在主機上ping ?5.0.0.2顯示如下:
C:Documents and Settingsc>ping?-n 10?-l 1000 5.0.0.2 Pinging 5.0.0.2 with 1000 bytes of data: Reply from 5.0.0.2:?bytes=1000 time=552ms TTL=250 Reply from 5.0.0.2:?bytes=1000 time=5735ms TTL=250 Reply from 5.0.0.2:?bytes=1000 time=551ms TTL=250 Reply from 5.0.0.2:?bytes=1000 time=5734ms TTL=250 Reply from 5.0.0.2:?bytes=1000 time=549ms TTL=250 Reply from 5.0.0.2:?bytes=1000 time=5634ms TTL=250 Reply from 5.0.0.2:?bytes=1000 time=555ms TTL=250 Reply from 5.0.0.2:?bytes=1000 time=5738ms TTL=250 Reply from 5.0.0.2:?bytes=1000 time=455ms TTL=250 Reply from 5.0.0.2:?bytes=1000 time=5811ms TTL=250
3、原因分析:
上面的Ping顯示出一個規律,奇數報文的返回時長短,而偶數報文返回時長很長(是奇數報文的10倍多)。
可以初步判斷奇數報文和偶數報文是通過不同的路徑傳輸的。
現在我們需要使用Traceroute命令來追蹤這不同的路徑。在RouterC上,Traceroute遠端RouterA的以太網接口5.0.0.1。
RouterC(config)#traceroute
Target IP address or host:?5.0.0.1 Maximum number of hops to search for target?[30]:10 Repeat count for each echo[3]:8 Wait timeout milliseconds for each reply?[2000]: Type esc/CTRL^c/CTRL^z/q to abort. traceroute 5.0.0.1?...... 1????6 ms??4 ms??4 ms??4 ms??4 ms??4 ms??4 ms??4 ms???4.0.0.1 ??。。。。。。(中間省略) 5??20 ms??16 ms??15 ms??16 ms??16 ms??16 ms??16 ms??16 ms??3.0.0.2 6??30 ms??278 ms??25 ms??279 ms??25 ms??278 ms??25 ms??277 ms??5.0.0.1 RouterC(config)#
從上面的顯示可看到,直至3.0.0.2,UDP探測報文的返回時長都基本一。
而到5.0.0.1時,則發生明顯變化,呈現奇數報文時長短,偶數報文時長長的現象。
于是判斷,問題發生在RouterB和RouterA之間。
通過詢問該段網絡的管理員,得知這兩路由器間有一主一備兩串行鏈路,主鏈路為2.048Mbps(s0口之間),備份鏈路為128Kbps(s1口之間)。
網絡管理員在此兩路由器間配置了靜態路由。
RouterB上如下配置:
RouterB(config)#?ip route 5.0.0.0 255.0.0.0 1.0.0.2 RouterB(config)#?ip route 5.0.0.0 255.0.0.0 2.0.0.2
RouterA上如下配置:
outerA(config)#?ip route 0.0.0.0 0.0.0.0 1.0.0.1 RouterA(config)#?ip route 0.0.0.0 0.0.0.0 2.0.0.1
于是問題就清楚了。
例如RouterB,由于管理員配置時沒有給出靜態路由的優先級,這兩條路由項的管理距離就同為缺省值1。
然后就同時出現在路由表中,實現的是負載分擔,而不能達到主備的目的。
4、處理過程:
可以有兩種處理方法。
一個是,繼續使用靜態路由,進行配置更改 RouterB上進行如下更改:
RouterB(config)#?ip route 5.0.0.0 255.0.0.0 1.0.0.2?(主鏈路仍使用缺省1)
RouterB(config)#?ip route 5.0.0.0 255.0.0.0 2.0.0.2 100(備份鏈路的降低至100)
RouterA上進行如下更改:
RouterA(config)#?ip route 0.0.0.0 0.0.0.0 1.0.0.1
RouterA(config)#?ip route 0.0.0.0 0.0.0.0 2.0.0.1 100
這樣,只有當主鏈路發生故障,備份鏈路的路由項才會出線在路由表中,從而接替主鏈路完成報文轉發,實現主備目的。
第二個是,在兩路由器上運行動態路由協議,如OSPF,但不要運行RIP協議(因為RIP協議是僅以hop作為Metric的)。
5、建議和總結:
本案例的目的不是為了解釋網絡配置問題,而是用來展示Ping命令和Traceroute命令的相互配合來找到網絡問題的發生點。
尤其在一個大的組網環境中,維護人員可能無法沿著路徑逐機排查,此時,能夠迅速定位出發生問題的線路或路由器就非常重要了。
?排障案例②??使用Traceroute命令發現路由環路?
1、現象描述:
組網情況如下圖所示:
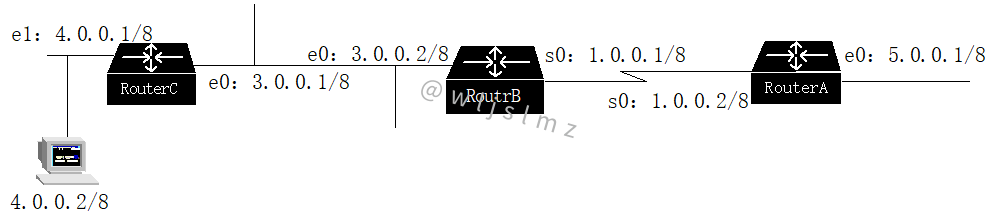
三臺路由器均配置靜態路由,完成后,登錄到RouterA上Ping主機4.0.0.2,發現不通。
2、相關信息:
RouterA#?ping??4.0.0.2
Sending 5,?100-byte ICMP Echos to 4.0.0.2, timeout is 2000 milliseconds. ..... Success rate is 0 percent?(0/5) RouterA#?traceroute 4.0.0.2 ?Type esc/CTRL^c/CTRL^z/q to abort. traceroute 4.0.0.2?...... 1??6 ms??4 ms??4 ms???1.0.0.1(RouterB) ?2??8 ms??8 ms??8 ms???1.0.0.2(RouterA) ?3??12 ms??12 ms??12 ms 1.0.0.1(RouterB) ?4??16 ms??16 ms??16 ms 1.0.0.2(RouterA) ?。。。。。。
3、原因分析:
從上面的Traceroute命令的顯示可以立即發現,在RouterA和RouterB間產生了路由環路。
由于是配置的是靜態路由,基本可以斷定是RouterA或RouterB的靜態路由配置錯誤。?
檢查RouterA的路由表,配置的是缺省靜態路由:ip route 0.0.0.0 0.0.0.0 1.0.0.1,沒有問題。
檢查RouterB的路由表,配置到4.0.0.0網絡的靜態路由為:ip route 4.0.0.0 255.0.0.0 1.0.0.2――下一跳配置的是1.0.0.2,而不是3.0.0.1。這正是錯誤所在。
4、處理過程:
修改RouterB的配置如下:
RouterB(config)#?no ip route 4.0.0.0 255.0.0.0 1.0.0.2
RouterB(config)#?ip route 4.0.0.0 255.0.0.0 3.0.0.1
故障排除。
5、建議和總結:
Traceroute命令能夠很容易發現路由環路等潛在問題。
當路由器A認為路由器B知道到達目的地的路徑,而路由器B也認為路由器A知道目的地時,就是路由環路發生了。
使用Ping命令只能知道接收端出現超時錯誤,而Traceroute能夠立即發現環路所在――如果Traceroute命令兩次或者多次顯示同樣的接口。
當通過Traceroute發現路由環路后,如果配置為:
靜態路由:幾乎可以肯定是手工配置有問題,如本案例所示。
OSPF協議:可能是地址聚合產生的問題。
多路由協議:可能是路由引入產生的問題。
編輯:黃飛









 工商網監
工商網監
評論