 電子發燒友App
電子發燒友App


本例從零開始基于transformers庫逐模塊搭建和解讀Llama模型源碼(中文可以翻譯成羊駝)。
并且訓練它來實現一個有趣的實例:兩數之和。
輸入輸出類似如下:
輸入:"12345+54321="
輸出:"66666"
我們把這個任務當做一個文本生成任務來進行。輸入是一個序列的上半部分,輸出其下半部分.
這和文本生成的輸入輸出結構是類似的,所以可以用Llama來做。
目前大部分開源LLM模型都是基于transformers庫來做的,它們的結構大部分都和Llama大同小異。
俗話說,魔鬼隱藏在細節中,深入理解Llama模型的的源碼細節,將會幫助你打通和開源LLM模型相關的基礎原理(如旋轉位置編碼以及長度外推),并讓你熟悉各種參數的配置和使用(如past_key_value,attention_mask的使用等等)。
一,準備數據
import?random import?numpy?as?np import?torch from?torch.utils.data?import?Dataset,DataLoader #?定義字典 words?=?', , ,1,2,3,4,5,6,7,8,9,0,+,=' vocab?=?{word:?i?for?i,?word?in?enumerate(words.split(','))} vocab_r?=?[k?for?k,?v?in?vocab.items()]?#反查詞典
#兩數相加數據集 def?get_data(min_length=10,max_length=20): ????#?定義詞集合 ????words?=?['0',?'1',?'2',?'3',?'4',?'5',?'6',?'7',?'8',?'9'] ????#?每個詞被選中的概率 ????p?=?np.array([7,?5,?5,?7,?6,?5,?7,?6,?5,?7]) ????p?=?p?/?p.sum() ????#?隨機采樣n1個詞作為s1 ????n1?=?random.randint(min_length,?max_length) ????s1?=?np.random.choice(words,?size=n1,?replace=True,?p=p) ????s1?=?s1.tolist() ????#?隨機采樣n2個詞作為s2 ????n2?=?random.randint(min_length,?max_length) ????s2?=?np.random.choice(words,?size=n2,?replace=True,?p=p) ????s2?=?s2.tolist() ????#?x等于s1和s2字符上的相加 ????x?=?s1?+?['+']?+?s2?+?['='] ???? ????#?y等于s1和s2數值上的相加 ????y?=?int(''.join(s1))?+?int(''.join(s2)) ????y?=?list(str(y)) ???? ????#?加上首尾符號 ????x?=?['']?+?x? ????y?=??y?+?[' '] ???? ????return?x,y x,y?=?get_data()? print(''.join(x)+''.join(y)," ")
3914835626735057733+318829464988=3914835945564522721
#?定義數據集 class?TwoSumDataset(torch.utils.data.Dataset): ????def?__init__(self,size?=?100000,?min_length=10,max_length=20): ????????super(Dataset,?self).__init__() ????????self.size?=?size ????????self.min_length=min_length ????????self.max_length=max_length ????def?__len__(self): ????????return?self.size ????def?__getitem__(self,?i): ????????x,y?=?self.get(i) ???????? ????????#?編碼成token ????????context_ids?=?[vocab[i]?for?i?in?x] ????????target_ids?=?[vocab[i]?for?i?in?y] ???????? ????????input_ids?=?context_ids?+?target_ids ???????? ????????#-100標志位后面會在計算loss時會被忽略不貢獻損失,我們集中優化target部分生成的loss ????????labels?=?[-100]*len(context_ids)+?target_ids ????????masks?=?[0?if?t==vocab['']?else?1?for?t?in?input_ids] ???????? ????????example?=?{'input_ids':input_ids, ??????????????????'labels':labels,'attention_mask':masks} ???????? ????????return?example ???? ????def?get(self,i): ????????return?get_data(self.min_length,self.max_length) ???? ???? ????def?show_example(self,example): ????????input_ids,labels?=?example['input_ids'],example['labels'] ????????x?=?''.join([vocab_r[a]?for?a,b?in?zip(input_ids,labels)?if?b==-100]) ????????y?=?''.join([vocab_r[a]?for?a,b?in?zip(input_ids,labels)?if?b!=-100]) ????????print(x+y) ???????? ???????? ???? ds_train?=?TwoSumDataset(size?=?100000,min_length=10,max_length=20) ds_val?=?TwoSumDataset(size?=?10000,min_length=10,max_length=20) example?=?ds_train[0] ds_train.show_example(example)
12878683929048906366+11274414130675477=12889958343179581843
def?data_collator(examples:?list): ????len_ids?=?[len(example["input_ids"])?for?example?in?examples] ????longest?=?max(len_ids)?#之后按照batch中最長的input_ids進行padding ???? ????input_ids?=?[] ????labels_list?=?[] ????masks_list?=?[] ???? ????for?length,?example?in?sorted(zip(len_ids,?examples),?key=lambda?x:?-x[0]): ????????ids?=?example["input_ids"] ????????labs?=?example["labels"] ????????masks?=?example['attention_mask'] ???????? ????????ids?=?[vocab['']]?*?(longest?-?length)+ids? ????????labs?=?[-100]?*?(longest?-?length)+labs ????????masks?=?[0]*(longest?-?length)+masks ???????? ????????input_ids.append(torch.LongTensor(ids)) ????????labels_list.append(torch.LongTensor(labs)) ????????masks_list.append(torch.LongTensor(masks)) ?????????? ????input_ids?=?torch.stack(input_ids) ????labels?=?torch.stack(labels_list) ????attention_mask?=?torch.stack(masks_list) ????return?{ ????????"input_ids":?input_ids, ????????"labels":?labels, ????????"attention_mask":attention_mask ????} #?數據加載器 dl_train?=?DataLoader(dataset=ds_train, ?????????batch_size=200, ?????????drop_last=True, ?????????shuffle=True, ?????????collate_fn?=?data_collator???????? ????????) dl_val?=?DataLoader(dataset=ds_val, ?????????batch_size=200, ?????????drop_last=True, ?????????shuffle=False, ?????????collate_fn?=?data_collator?? ????????)
for?batch?in?dl_train: ????break?
batch?
{'input_ids': tensor([[ 1, 11, 6, ..., 7, 11, 2],
[ 0, 1, 6, ..., 5, 4, 2],
[ 0, 1, 7, ..., 8, 8, 2],
...,
[ 0, 0, 0, ..., 10, 11, 2],
[ 0, 0, 0, ..., 12, 3, 2],
[ 0, 0, 0, ..., 11, 12, 2]]),
'labels': tensor([[-100, -100, -100, ..., 7, 11, 2],
[-100, -100, -100, ..., 5, 4, 2],
[-100, -100, -100, ..., 8, 8, 2],
...,
[-100, -100, -100, ..., 10, 11, 2],
[-100, -100, -100, ..., 12, 3, 2],
[-100, -100, -100, ..., 11, 12, 2]]),
'attention_mask': tensor([[1, 1, 1, ..., 1, 1, 1],
[0, 1, 1, ..., 1, 1, 1],
[0, 1, 1, ..., 1, 1, 1],
...,
[0, 0, 0, ..., 1, 1, 1],
[0, 0, 0, ..., 1, 1, 1],
[0, 0, 0, ..., 1, 1, 1]])}
?
?
二,定義模型
下面,我們會像搭積木建城堡那樣從低往高地構建LLaMA模型。
先構建4個基礎組件:旋轉位置編碼,多頭注意力、前饋網絡、層歸一化。類似用最基礎的積木塊搭建了 墻壁,房頂,房門,窗戶 這樣的模塊。
然后用這4個基礎組件構建中間成品: 解碼層。類似用基礎組件構建了房間。
接著用多個中間成品解碼層的堆疊組裝成了LlamaModel完整模型,相當于通過構建多個房間建成了城堡的主體結構。
最后我們在LlamaModel基礎上設計了兩種不同的輸出head,一種是語言模型Head,得到了LlamaForCausalLM,可用于文本生成。
另外一種是分類head,得到了LlamaForSequenceClassification,可用于文本分類。
相當于我們在城堡主體結構完成的基礎上設計了兩種不同的裝修風格,一種是加裝了一些游樂設施以便用于商業活動,另一種則是加裝了一些武器以便用于軍事活動。
1, 旋轉位置編碼: RoPE (使用旋轉矩陣實現的絕對位置編碼,可以起到相對位置編碼的效果)
2, 多頭注意力: LlamaAttention (用于融合不同token之間的信息)
3, 前饋網絡: LlamaMLP (用于逐位置將多頭注意力融合后的信息進行高維映射變換)
4, 層歸一化: LlamaRMSNorm (用于穩定輸入,相當于保持每個詞向量的方向不變,但對模長標準化。)
5, Llama解碼層: LlamaDecoderLayer (同時具備信息融合,信息轉換功能的基本結構單元)
6, Llama解碼器: LlamaModel (多個解碼層的堆疊)
7,Llama語言模型: LlamaForCausalLM (解碼器加上語言模型head,可用于文本生成)
8,Llama分類模型: LlamaForSequenceClassification (解碼器加上分類head,可用于文本分類)
?
?
import?math from?typing?import?List,?Optional,?Tuple,?Union import?torch import?torch.nn.functional?as?F import?torch.utils.checkpoint from?torch?import?nn from?torch.nn?import?BCEWithLogitsLoss,?CrossEntropyLoss,?MSELoss from?transformers.activations?import?ACT2FN from?transformers.modeling_outputs?import?BaseModelOutputWithPast,?CausalLMOutputWithPast,?SequenceClassifierOutputWithPast from?transformers.modeling_utils?import?PreTrainedModel from?transformers.utils?import?add_start_docstrings,?add_start_docstrings_to_model_forward,?logging,?replace_return_docstrings from?transformers.models.llama.configuration_llama??import?LlamaConfig from?transformers.models.llama.modeling_llama?import?LLAMA_INPUTS_DOCSTRING,LLAMA_START_DOCSTRING logger?=?logging.get_logger('llama') config?=?LlamaConfig( ????vocab_size=len(vocab), ????hidden_size=512, ????intermediate_size=2752, ????num_hidden_layers=8, ????num_attention_heads=16, ????hidden_act='silu', ????max_position_embeddings=128, ????initializer_range=0.02, ????rms_norm_eps=1e-06, ????use_cache=True, ????pad_token_id=0, ????bos_token_id=1, ????eos_token_id=2, ????tie_word_embeddings=False )?
?
?
1,旋轉位置編碼 RoPE
旋轉位置編碼即使用旋轉矩陣表示位置編碼(Rotary Position Encoding),簡稱RoPE。
關于RoPE的3個核心要點知識如下:
RoPE的設計思想是使用絕對位置編碼來達到相對位置編碼的效果。
RoPE的實現方式是使用旋轉矩陣來表示絕對位置編碼。
使用NTK擴展方法可以讓RoPE在短文本上訓練并在長文本上做預測。
參考文章:
《博采眾長的旋轉式位置編碼》https://kexue.fm/archives/8265
《RoPE是一種進制編碼》https://kexue.fm/archives/9675
(1)絕對位置編碼和相對位置編碼
位置編碼一般可以分成絕對位置編碼和相對位置編碼。
絕對位置編碼的優點是計算簡單高效,缺點是一般效果不如相對位置編碼。
相對位置編碼的優點是效果較好,缺點是計算效率不如絕對位置編碼。
絕對位置編碼:
相對位置編碼:
在相對位置編碼中,注意力權重的結果僅僅和參與注意力計算的token向量的相對位置有關,不和絕對位置直接關聯。
這符合NLP領域在序列長度方向上具有平移不變性的特點,所以相對位置編碼一般效果會優于絕對位置編碼。
不過絕對位置編碼并非一無是處,絕對位置編碼只需要初始化時對序列的每個位置(數量正比于序列長度)賦予位置編碼即可,后續無需干預。
而相對位置編碼要在計算過程中獲取許多個(數量正比于序列長度平方)相對位置。
因此絕對位置編碼更加簡單高效。
(2)使用旋轉矩陣表示位置編碼
上述討論可以看到,絕對位置編碼和相對位置編碼互有優劣,那么有沒有什么辦法能夠對二者進行取長補短呢?
有的,這個方法就是RoPE,它的設計思想就是使用絕對位置編碼來達到相對位置編碼的效果。
那么旋轉位置編碼如何使用絕對位置編碼來達到相對位置編碼的效果的呢?答案是使用旋轉矩陣來表示位置編碼。
其中 為旋轉矩陣,滿足性質 。于是,有:
符合 相對位置編碼形式。
perfect! 我們用絕對位置編碼實現了相對位置編碼的效果。
那么,旋轉矩陣長什么樣呢?
在二維情形長下面樣子。
在NLP領域,詞向量的維度一般會很高(例如4096)。
利用矩陣的分塊思想,可以證明高維情形下擴展成下述形式依舊滿足旋轉矩陣性質
其中 ,即越高的維度對應三角函數的系數越小,周期越大,變化越緩慢。
由于旋轉矩陣是稀疏矩陣,直接使用乘法計算會很浪費算力,可以將旋轉位置編碼過程由矩陣乘法運算簡化成兩次向量的哈達瑪積求和。
(3)旋轉位置編碼的長度擴展
在LLM的應用中,有一個非常重要的參數,叫做LLM支持的上下文長度(max context length)。
更長的上下文長度允許我們進行更多輪次的對話,允許我們對更長的本文進行總結分析,也允許我們生成更長的文章。
但是在訓練LLM的時候,我們的訓練語料大部分是不夠長的,許多LLM訓練時候設計的最大文本長度都是只有2k,也就是最長2048個token。
那么,能否在訓練的時候使用較短的文本,而在推理的時候擴展到長文本上呢?
是有可能的,我們可以對RoPE進行長度擴展。
我們介紹3種擴展方案。
第一種是直接外推:直接外推其實就是繼續沿用現有的位置編碼公式,不做任何修改。
在擴展長度不太長的時候,例如由2k擴展到2.5k時,這種方法可能對性能的影響并不大。
因為旋轉位置編碼只和相對位置m-n的大小有關,一般具有遠程衰減性,即相對距離越大的兩個token,其相關性一般越弱。
因此如果我們的模型已經從訓練數據那里學習到了token之間的相關性相對于相對距離在0-2k的一個合適的衰減規律的時候,可以設想把這個規律應用到0-2.5k也是沒有太大的問題的。
但是如果我們要擴展到更長的長度,例如從2k擴展到32k,這種直接外推的方案通常會嚴重地影響性能。因為我們學習到的衰減規律有可能在5k的那里就完全衰減截斷基本降為0了,這樣我們就無法捕捉相對距離長于5k的兩個token之間的相互作用,外推就會導致性能下降。
總結一下,直接外推對衰減規律在長距離情況下的使用容易出現問題,導致性能下降。
為了減少長度外推對性能的影響,我們可以讓訓練好的模型在更長的上下文上做少許步驟的微調。
第二種是線性內插:線性內插需要改變位置編碼公式,等效于將位置序號等比例縮小。
編碼公式變化如 ,當從2k擴展到32k,等效于需要將位置序號變成原來的1/16.
線性內插沒有改變模型學習到的衰減規律的應用范圍,不考慮微調的話,其效果一般好于直接外推方案。
但是,擴展倍數非常大的時候,例如從2k擴展到32k,其性能也會明顯的受到影響。
因為在這種情況下,衰減規律在短距離情況下的使用會受到較嚴重的影響,本來距離為1的兩個token,長度擴展后相當于變成了距離為1/16,衰減規律在短距離時可能具有非常大的變化率,因此對相關性的評估可能會極端地偏離合理值。
應用線性內插時,在長文本上做少許步驟的微調也能夠明顯地改善性能。
第三種是NTK擴展方式:這種方式綜合了外推和內插的優點,做長度擴展后即使不微調也能夠保持較好的性能。
前面的分析我們知道直接外推對衰減規律在長距離情況下的使用容易出問題,在短距離情況下的使用不受影響。
而線性內插對衰減規律在短距離情況下的使用容易出現問題,在長距離的情況下影響較小。
我們能否將它們綜合起來,在短距離情況下具有外推特性(與擴展前基本一致),在長距離情況下具有內插特性(縮放到擴展前的范圍),從而使得長距離情況下和短距離情況下衰減規律的使用都不太受到影響呢。
我們觀察RoPE位置編碼第行的元素計算公式,可以發現越大,三角函數對應的角頻率系數越小,或者說越低頻,對應的三角函數變化越慢。
容易得到如下直觀結論:短距離之間的差異(例如1和5的差異),主要體現在高頻分量(i比較小)上,長距離之間的差異(例如5000和10000的差異),主要體現在低頻分量(i比較大)上。
為了在短距離情況下具有外推特性,而在長距離情況下具有內插特性,我們可以設計一個和有關的位置序號縮放因子,使得在最高頻()時取值為1(與擴展前基本一致),而在最低頻時()恰好為縮放倍數的倒數(縮放到擴展前的范圍)。
一種有效的選擇方案是的指數函數,其效果相當于對中的做一個縮放,根據邊界條件容易求得合適的縮放因子為 。
NTK擴展方式的要點是高頻外推,低頻內插,實現方法是直接對底數base進行縮放,類似進制編碼轉換。
采用NTK擴展到長文本,即使不做微調,性能會只會略有下降。
下面是RoPE以及三種長度擴展方式的實現。
?
?
class?LlamaRotaryEmbedding(torch.nn.Module):
????def?__init__(self,?dim,?max_position_embeddings=2048,?base=10000,?device=None):
????????super().__init__()
????????self.dim?=?dim
????????self.max_position_embeddings?=?max_position_embeddings
????????self.base?=?base
????????inv_freq?=?1.0?/?(self.base?**?(torch.arange(0,?self.dim,?2).float().to(device)?/?self.dim))
????????self.register_buffer("inv_freq",?inv_freq,?persistent=False)?#persistent=False將不會作為state_dict
????????#?Build?here?to?make?`torch.jit.trace`?work.
????????self._set_cos_sin_cache(
????????????seq_len=max_position_embeddings,?device=self.inv_freq.device,?dtype=torch.get_default_dtype()
????????)
????def?_set_cos_sin_cache(self,?seq_len,?device,?dtype):
????????self.max_seq_len_cached?=?seq_len
????????t?=?torch.arange(self.max_seq_len_cached,?device=device,?dtype=self.inv_freq.dtype)
????????freqs?=?torch.einsum("i,j->ij",?t,?self.inv_freq)
????????#?Different?from?paper,?but?it?uses?a?different?permutation?in?order?to?obtain?the?same?calculation
????????emb?=?torch.cat((freqs,?freqs),?dim=-1)
????????self.register_buffer("cos_cached",?emb.cos()[None,?None,?:,?:].to(dtype),?persistent=False)
????????self.register_buffer("sin_cached",?emb.sin()[None,?None,?:,?:].to(dtype),?persistent=False)
????def?forward(self,?x,?seq_len=None):
????????#?x:?[bs,?num_attention_heads,?seq_len,?head_size]
????????#超過預設的max_position_embeddings則重新計算更大的Rope緩存,否則直接在緩存上切片
????????if?seq_len?>?self.max_seq_len_cached:?
????????????self._set_cos_sin_cache(seq_len=seq_len,?device=x.device,?dtype=x.dtype)
????????return?(
????????????self.cos_cached[:,?:,?:seq_len,?...].to(dtype=x.dtype),
????????????self.sin_cached[:,?:,?:seq_len,?...].to(dtype=x.dtype),
????????)
????
class?LlamaLinearScalingRotaryEmbedding(LlamaRotaryEmbedding):
????"""LlamaRotaryEmbedding?extended?with?linear?scaling.?Credits?to?the?Reddit?user?/u/kaiokendev"""
????def?__init__(self,?dim,?max_position_embeddings=2048,?base=10000,?device=None,?scaling_factor=1.0):
????????self.scaling_factor?=?scaling_factor
????????super().__init__(dim,?max_position_embeddings,?base,?device)
????def?_set_cos_sin_cache(self,?seq_len,?device,?dtype):
????????self.max_seq_len_cached?=?seq_len
????????t?=?torch.arange(self.max_seq_len_cached,?device=device,?dtype=self.inv_freq.dtype)
????????t?=?t?/?self.scaling_factor?#線性內插相當于將位置序號等比例縮小
????????freqs?=?torch.einsum("i,j->ij",?t,?self.inv_freq)
????????#?Different?from?paper,?but?it?uses?a?different?permutation?in?order?to?obtain?the?same?calculation
????????emb?=?torch.cat((freqs,?freqs),?dim=-1)
????????self.register_buffer("cos_cached",?emb.cos()[None,?None,?:,?:].to(dtype),?persistent=False)
????????self.register_buffer("sin_cached",?emb.sin()[None,?None,?:,?:].to(dtype),?persistent=False)
class?LlamaDynamicNTKScalingRotaryEmbedding(LlamaRotaryEmbedding):
????"""LlamaRotaryEmbedding?extended?with?Dynamic?NTK?scaling.?Credits?to?the?Reddit?users?/u/bloc97?and?/u/emozilla"""
????def?__init__(self,?dim,?max_position_embeddings=2048,?base=10000,?device=None,?scaling_factor=1.0):
????????self.scaling_factor?=?scaling_factor
????????super().__init__(dim,?max_position_embeddings,?base,?device)
????def?_set_cos_sin_cache(self,?seq_len,?device,?dtype):
????????self.max_seq_len_cached?=?seq_len
????????if?seq_len?>?self.max_position_embeddings:
????????????base?=?self.base?*?(
????????????????(self.scaling_factor?*?seq_len?/?self.max_position_embeddings)?-?(self.scaling_factor?-?1)
????????????)?**?(self.dim?/?(self.dim?-?2))??#NTK擴展方式直接對base進行縮放
????????????inv_freq?=?1.0?/?(base?**?(torch.arange(0,?self.dim,?2).float().to(device)?/?self.dim))
????????????self.register_buffer("inv_freq",?inv_freq,?persistent=False)
????????t?=?torch.arange(self.max_seq_len_cached,?device=device,?dtype=self.inv_freq.dtype)
????????freqs?=?torch.einsum("i,j->ij",?t,?self.inv_freq)
????????
????????#此處處理邏輯與原始的ROPE有差異,原始邏輯如下
????????#emb?=?torch.cat((freqs,?freqs),?dim=-1)
????????#emb[...,0::2]=freqs
????????#emb[...,1::2]=freqs
????????
????????
????????#?Different?from?paper,?but?it?uses?a?different?permutation?in?order?to?obtain?the?same?calculation
????????emb?=?torch.cat((freqs,?freqs),?dim=-1)
????????self.register_buffer("cos_cached",?emb.cos()[None,?None,?:,?:].to(dtype),?persistent=False)
????????self.register_buffer("sin_cached",?emb.sin()[None,?None,?:,?:].to(dtype),?persistent=False)
????????
????????
def?rotate_half(x):
????"""Rotates?half?the?hidden?dims?of?the?input."""
????
????#此處邏輯與原始的ROPE有所差異,原始邏輯如下
????#x1?=?x[...,?0::2]?
????#x2?=?x[...,?1::2]
????#res?=?torch.cat((x1,?x2),?dim=-1)
????#res[...,0::2]=-x2
????#res[...,1::2]=x1
????#return?res
????
????x1?=?x[...,?:?x.shape[-1]?//?2]?
????x2?=?x[...,?x.shape[-1]?//?2?:]
????return?torch.cat((-x2,?x1),?dim=-1)
def?apply_rotary_pos_emb(q,?k,?cos,?sin,?position_ids):
????#?The?first?two?dimensions?of?cos?and?sin?are?always?1,?so?we?can?`squeeze`?them.
????cos?=?cos.squeeze(1).squeeze(0)??#?[seq_len,?dim]
????sin?=?sin.squeeze(1).squeeze(0)??#?[seq_len,?dim]
????cos?=?cos[position_ids].unsqueeze(1)??#?[bs,?1,?seq_len,?dim]
????sin?=?sin[position_ids].unsqueeze(1)??#?[bs,?1,?seq_len,?dim]
????q_embed?=?(q?*?cos)?+?(rotate_half(q)?*?sin)
????k_embed?=?(k?*?cos)?+?(rotate_half(k)?*?sin)
????return?q_embed,?k_embed
x?=?torch.randn(1,8,4,2) rope?=?LlamaRotaryEmbedding(dim=8) cos,sin?=?rope.forward(x,seq_len=4) print(cos.shape)? print(cos)
torch.Size([1, 1, 4, 8])
tensor([[[[ 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000,
1.0000],
[ 0.5403, 0.9950, 0.9999, 1.0000, 0.5403, 0.9950, 0.9999,
1.0000],
[-0.4161, 0.9801, 0.9998, 1.0000, -0.4161, 0.9801, 0.9998,
1.0000],
[-0.9900, 0.9553, 0.9996, 1.0000, -0.9900, 0.9553, 0.9996,
1.0000]]]])
?
?
2,多頭注意力 LlamaAttention
這里的LlamaAttention 基本上和《Attention Is All You Need》論文里的是一致的,主要差異有以下一些。
1,k和v的head數量可以是q的head數量的幾分之一,類似分組卷積的思想,可以減少參數規模。
2,rope位置編碼是每次做多頭注意力時都進行一次,而不是原論文只在輸入的時候進行一次。
3,允許傳入key和value的states的緩存past_key_value,這在多輪對話中可以減少重復計算,起到加速效果。
4,attention_mask是通過加法形式作用到softmax之前的attention矩陣上的。
?
?
def?repeat_kv(hidden_states:?torch.Tensor,?n_rep:?int)?->?torch.Tensor:
????"""
????This?is?the?equivalent?of?torch.repeat_interleave(x,?dim=1,?repeats=n_rep).?The?hidden?states?go?from?(batch,
????num_key_value_heads,?seqlen,?head_dim)?to?(batch,?num_attention_heads,?seqlen,?head_dim)
????"""
????batch,?num_key_value_heads,?slen,?head_dim?=?hidden_states.shape
????if?n_rep?==?1:
????????return?hidden_states
????hidden_states?=?hidden_states[:,?:,?None,?:,?:].expand(batch,?num_key_value_heads,?n_rep,?slen,?head_dim)
????return?hidden_states.reshape(batch,?num_key_value_heads?*?n_rep,?slen,?head_dim)
class?LlamaAttention(nn.Module):
????"""Multi-headed?attention?from?'Attention?Is?All?You?Need'?paper"""
????def?__init__(self,?config:?LlamaConfig):
????????super().__init__()
????????self.config?=?config
????????self.hidden_size?=?config.hidden_size
????????self.num_heads?=?config.num_attention_heads
????????self.head_dim?=?self.hidden_size?//?self.num_heads
????????self.num_key_value_heads?=?config.num_key_value_heads
????????self.num_key_value_groups?=?self.num_heads?//?self.num_key_value_heads
????????self.max_position_embeddings?=?config.max_position_embeddings
????????if?(self.head_dim?*?self.num_heads)?!=?self.hidden_size:
????????????raise?ValueError(
????????????????f"hidden_size?must?be?divisible?by?num_heads?(got?`hidden_size`:?{self.hidden_size}"
????????????????f"?and?`num_heads`:?{self.num_heads})."
????????????)
????????self.q_proj?=?nn.Linear(self.hidden_size,?self.num_heads?*?self.head_dim,?bias=False)
????????self.k_proj?=?nn.Linear(self.hidden_size,?self.num_key_value_heads?*?self.head_dim,?bias=False)
????????self.v_proj?=?nn.Linear(self.hidden_size,?self.num_key_value_heads?*?self.head_dim,?bias=False)
????????self.o_proj?=?nn.Linear(self.num_heads?*?self.head_dim,?self.hidden_size,?bias=False)
????????self._init_rope()
????def?_init_rope(self):
????????if?self.config.rope_scaling?is?None:
????????????self.rotary_emb?=?LlamaRotaryEmbedding(self.head_dim,?max_position_embeddings=self.max_position_embeddings)
????????else:
????????????scaling_type?=?self.config.rope_scaling["type"]
????????????scaling_factor?=?self.config.rope_scaling["factor"]
????????????if?scaling_type?==?"linear":
????????????????self.rotary_emb?=?LlamaLinearScalingRotaryEmbedding(
????????????????????self.head_dim,?max_position_embeddings=self.max_position_embeddings,?scaling_factor=scaling_factor
????????????????)
????????????elif?scaling_type?==?"dynamic":
????????????????self.rotary_emb?=?LlamaDynamicNTKScalingRotaryEmbedding(
????????????????????self.head_dim,?max_position_embeddings=self.max_position_embeddings,?scaling_factor=scaling_factor
????????????????)
????????????else:
????????????????raise?ValueError(f"Unknown?RoPE?scaling?type?{scaling_type}")
????def?_shape(self,?tensor:?torch.Tensor,?seq_len:?int,?bsz:?int):
????????return?tensor.view(bsz,?seq_len,?self.num_heads,?self.head_dim).transpose(1,?2).contiguous()
????def?forward(
????????self,
????????hidden_states:?torch.Tensor,
????????attention_mask:?Optional[torch.Tensor]?=?None,
????????position_ids:?Optional[torch.LongTensor]?=?None,
????????past_key_value:?Optional[Tuple[torch.Tensor]]?=?None,
????????output_attentions:?bool?=?False,
????????use_cache:?bool?=?False,
????)?->?Tuple[torch.Tensor,?Optional[torch.Tensor],?Optional[Tuple[torch.Tensor]]]:
????????bsz,?q_len,?_?=?hidden_states.size()
????????if?self.config.pretraining_tp?>?1:
????????????key_value_slicing?=?(self.num_key_value_heads?*?self.head_dim)?//?self.config.pretraining_tp
????????????query_slices?=?self.q_proj.weight.split(
????????????????(self.num_heads?*?self.head_dim)?//?self.config.pretraining_tp,?dim=0
????????????)
????????????key_slices?=?self.k_proj.weight.split(key_value_slicing,?dim=0)
????????????value_slices?=?self.v_proj.weight.split(key_value_slicing,?dim=0)
????????????query_states?=?[F.linear(hidden_states,?query_slices[i])?for?i?in?range(self.config.pretraining_tp)]
????????????query_states?=?torch.cat(query_states,?dim=-1)
????????????key_states?=?[F.linear(hidden_states,?key_slices[i])?for?i?in?range(self.config.pretraining_tp)]
????????????key_states?=?torch.cat(key_states,?dim=-1)
????????????value_states?=?[F.linear(hidden_states,?value_slices[i])?for?i?in?range(self.config.pretraining_tp)]
????????????value_states?=?torch.cat(value_states,?dim=-1)
????????else:
????????????query_states?=?self.q_proj(hidden_states)
????????????key_states?=?self.k_proj(hidden_states)
????????????value_states?=?self.v_proj(hidden_states)
????????query_states?=?query_states.view(bsz,?q_len,?self.num_heads,?self.head_dim).transpose(1,?2)
????????key_states?=?key_states.view(bsz,?q_len,?self.num_key_value_heads,?self.head_dim).transpose(1,?2)
????????value_states?=?value_states.view(bsz,?q_len,?self.num_key_value_heads,?self.head_dim).transpose(1,?2)
????????kv_seq_len?=?key_states.shape[-2]
????????if?past_key_value?is?not?None:
????????????kv_seq_len?+=?past_key_value[0].shape[-2]
????????cos,?sin?=?self.rotary_emb(value_states,?seq_len=kv_seq_len)
????????query_states,?key_states?=?apply_rotary_pos_emb(query_states,?key_states,?cos,?sin,?position_ids)
????????if?past_key_value?is?not?None:
????????????#?reuse?k,?v,?self_attention
????????????key_states?=?torch.cat([past_key_value[0],?key_states],?dim=2)
????????????value_states?=?torch.cat([past_key_value[1],?value_states],?dim=2)
????????past_key_value?=?(key_states,?value_states)?if?use_cache?else?None
????????#?repeat?k/v?heads?if?n_kv_heads??1:
????????????attn_output?=?attn_output.split(self.hidden_size?//?self.config.pretraining_tp,?dim=2)
????????????o_proj_slices?=?self.o_proj.weight.split(self.hidden_size?//?self.config.pretraining_tp,?dim=1)
????????????attn_output?=?sum([F.linear(attn_output[i],?o_proj_slices[i])?for?i?in?range(self.config.pretraining_tp)])
????????else:
????????????attn_output?=?self.o_proj(attn_output)
????????if?not?output_attentions:
????????????attn_weights?=?None
????????return?attn_output,?attn_weights,?past_key_value
????
????
?
?
3,前饋網絡 LlamaMLP
前饋網絡是一個2層的感知機MLP。
先從hidden_size維度up_proj到intermediate_size維度,然后再down_proj還原為hidden_size維度。
這里的主要特色是引入了一個gate_proj配合激活函數來實現一個門控注意力的作用。
?
?
class?LlamaMLP(nn.Module): ????def?__init__(self,?config): ????????super().__init__() ????????self.config?=?config ????????self.hidden_size?=?config.hidden_size ????????self.intermediate_size?=?config.intermediate_size ????????self.gate_proj?=?nn.Linear(self.hidden_size,?self.intermediate_size,?bias=False) ????????self.up_proj?=?nn.Linear(self.hidden_size,?self.intermediate_size,?bias=False) ????????self.down_proj?=?nn.Linear(self.intermediate_size,?self.hidden_size,?bias=False) ????????self.act_fn?=?ACT2FN[config.hidden_act] ????def?forward(self,?x): ????????if?self.config.pretraining_tp?>?1: ????????????slice?=?self.intermediate_size?//?self.config.pretraining_tp ????????????gate_proj_slices?=?self.gate_proj.weight.split(slice,?dim=0) ????????????up_proj_slices?=?self.up_proj.weight.split(slice,?dim=0) ????????????down_proj_slices?=?self.down_proj.weight.split(slice,?dim=1) ????????????gate_proj?=?torch.cat( ????????????????[F.linear(x,?gate_proj_slices[i])?for?i?in?range(self.config.pretraining_tp)],?dim=-1 ????????????) ????????????up_proj?=?torch.cat([F.linear(x,?up_proj_slices[i])?for?i?in?range(self.config.pretraining_tp)],?dim=-1) ????????????intermediate_states?=?(self.act_fn(gate_proj)?*?up_proj).split(slice,?dim=2) ????????????down_proj?=?[ ????????????????F.linear(intermediate_states[i],?down_proj_slices[i])?for?i?in?range(self.config.pretraining_tp) ????????????] ????????????down_proj?=?sum(down_proj) ????????else: ????????????down_proj?=?self.down_proj(self.act_fn(self.gate_proj(x))?*?self.up_proj(x)) ????????return?down_proj
?
?
4,層歸一化 LlamaRMSNorm
這里的層歸一化叫做RMSNorm,和標準的LayerNorm有少許差異。
首先是沒有移除均值,直接除的RootMeanSquare,然后也沒有加上bias。
這兩個小的修正可以保證在層歸一化不會改變hidden_states對應的詞向量的方向,只會改變其模長。
在一定的意義上具有合理性。
?
?
class?LlamaRMSNorm(nn.Module): ????def?__init__(self,?hidden_size,?eps=1e-6): ????????""" ????????LlamaRMSNorm?is?equivalent?to?T5LayerNorm ????????""" ????????super().__init__() ????????self.weight?=?nn.Parameter(torch.ones(hidden_size)) ????????self.variance_epsilon?=?eps ????def?forward(self,?hidden_states): ????????input_dtype?=?hidden_states.dtype ????????hidden_states?=?hidden_states.to(torch.float32) ????????variance?=?hidden_states.pow(2).mean(-1,?keepdim=True) ????????hidden_states?=?hidden_states?*?torch.rsqrt(variance?+?self.variance_epsilon) ????????return?self.weight?*?hidden_states.to(input_dtype) ????
?
?
5,Llama解碼層
解碼層LlamaDecoderLayer由LlamaAttention,LlamaMLP,以及兩個LlamaRMSNorm組成,并使用了兩次殘差結構。
?
?
class?LlamaDecoderLayer(nn.Module): ????def?__init__(self,?config:?LlamaConfig): ????????super().__init__() ????????self.hidden_size?=?config.hidden_size ????????self.self_attn?=?LlamaAttention(config=config) ????????self.mlp?=?LlamaMLP(config) ????????self.input_layernorm?=?LlamaRMSNorm(config.hidden_size,?eps=config.rms_norm_eps) ????????self.post_attention_layernorm?=?LlamaRMSNorm(config.hidden_size,?eps=config.rms_norm_eps) ????def?forward( ????????self, ????????hidden_states:?torch.Tensor, ????????attention_mask:?Optional[torch.Tensor]?=?None, ????????position_ids:?Optional[torch.LongTensor]?=?None, ????????past_key_value:?Optional[Tuple[torch.Tensor]]?=?None, ????????output_attentions:?Optional[bool]?=?False, ????????use_cache:?Optional[bool]?=?False, ????)?->?Tuple[torch.FloatTensor,?Optional[Tuple[torch.FloatTensor,?torch.FloatTensor]]]: ????????""" ????????Args: ????????????hidden_states?(`torch.FloatTensor`):?input?to?the?layer?of?shape?`(batch,?seq_len,?embed_dim)` ????????????attention_mask?(`torch.FloatTensor`,?*optional*):?attention?mask?of?size ????????????????`(batch,?1,?tgt_len,?src_len)`?where?padding?elements?are?indicated?by?very?large?negative?values. ????????????output_attentions?(`bool`,?*optional*): ????????????????Whether?or?not?to?return?the?attentions?tensors?of?all?attention?layers.?See?`attentions`?under ????????????????returned?tensors?for?more?detail. ????????????use_cache?(`bool`,?*optional*): ????????????????If?set?to?`True`,?`past_key_values`?key?value?states?are?returned?and?can?be?used?to?speed?up?decoding ????????????????(see?`past_key_values`). ????????????past_key_value?(`Tuple(torch.FloatTensor)`,?*optional*):?cached?past?key?and?value?projection?states ????????""" ????????residual?=?hidden_states ????????hidden_states?=?self.input_layernorm(hidden_states) ????????#?Self?Attention ????????hidden_states,?self_attn_weights,?present_key_value?=?self.self_attn( ????????????hidden_states=hidden_states, ????????????attention_mask=attention_mask, ????????????position_ids=position_ids, ????????????past_key_value=past_key_value, ????????????output_attentions=output_attentions, ????????????use_cache=use_cache, ????????) ????????hidden_states?=?residual?+?hidden_states ????????#?Fully?Connected ????????residual?=?hidden_states ????????hidden_states?=?self.post_attention_layernorm(hidden_states) ????????hidden_states?=?self.mlp(hidden_states) ????????hidden_states?=?residual?+?hidden_states ????????outputs?=?(hidden_states,) ????????if?output_attentions: ????????????outputs?+=?(self_attn_weights,) ????????if?use_cache: ????????????outputs?+=?(present_key_value,) ????????return?outputs
?
?
6,Llama解碼器
LlamaModel由多個Llama解碼層堆疊而成。
有幾個理解上的要點:
1,_make_causal_mask用于構造下三角這種mask結構以實現語言模型的單向注意力。
2,_expand_mask用于將傳入的等特殊符號相關的mask信息展開成和attention矩陣相同的張量結構。
3,設置gradient_checkpointing=True可以節約顯存。其主要應用了torch.utils.checkpoint.checkpoint方法。它的原理非常簡單,在對decoder_layer進行forward時不保存中間激活值從而節約顯存,backward時重新計算相關值,從而通過時間換取了空間。
4,gradient_checkpointing和use_cache不能同時設置為True,前者是為了節約顯存時間換空間的,后者是為了節約時間空間換時間。
?
?
#?Copied?from?transformers.models.bart.modeling_bart._make_causal_mask def?_make_causal_mask( ????input_ids_shape:?torch.Size,?dtype:?torch.dtype,? ????device:?torch.device,?past_key_values_length:?int?=?0 ): ????""" ????Make?causal?mask?used?for?bi-directional?self-attention. ????""" ????bsz,?tgt_len?=?input_ids_shape ????mask?=?torch.full((tgt_len,?tgt_len),?torch.finfo(dtype).min,?device=device) ????mask_cond?=?torch.arange(mask.size(-1),?device=device) ????mask.masked_fill_(mask_cond??0: ????????mask?=?torch.cat([torch.zeros(tgt_len,?past_key_values_length,?dtype=dtype,?device=device),?mask],?dim=-1) ????return?mask[None,?None,?:,?:].expand(bsz,?1,?tgt_len,?tgt_len?+?past_key_values_length) #?Copied?from?transformers.models.bart.modeling_bart._expand_mask def?_expand_mask(mask:?torch.Tensor,?dtype:?torch.dtype,?tgt_len:?Optional[int]?=?None): ????""" ????Expands?attention_mask?from?`[bsz,?seq_len]`?to?`[bsz,?1,?tgt_seq_len,?src_seq_len]`. ????""" ????bsz,?src_len?=?mask.size() ????tgt_len?=?tgt_len?if?tgt_len?is?not?None?else?src_len ????expanded_mask?=?mask[:,?None,?None,?:].expand(bsz,?1,?tgt_len,?src_len).to(dtype) ????inverted_mask?=?1.0?-?expanded_mask ????return?inverted_mask.masked_fill(inverted_mask.to(torch.bool),?torch.finfo(dtype).min) @add_start_docstrings( ????"The?bare?LLaMA?Model?outputting?raw?hidden-states?without?any?specific?head?on?top.", ????LLAMA_START_DOCSTRING, ) class?LlamaPreTrainedModel(PreTrainedModel): ????config_class?=?LlamaConfig ????base_model_prefix?=?"model" ????supports_gradient_checkpointing?=?True ????_no_split_modules?=?["LlamaDecoderLayer"] ????_skip_keys_device_placement?=?"past_key_values" ????def?_init_weights(self,?module): ????????std?=?self.config.initializer_range ????????if?isinstance(module,?nn.Linear): ????????????module.weight.data.normal_(mean=0.0,?std=std) ????????????if?module.bias?is?not?None: ????????????????module.bias.data.zero_() ????????elif?isinstance(module,?nn.Embedding): ????????????module.weight.data.normal_(mean=0.0,?std=std) ????????????if?module.padding_idx?is?not?None: ????????????????module.weight.data[module.padding_idx].zero_() ????def?_set_gradient_checkpointing(self,?module,?value=False): ????????if?isinstance(module,?LlamaModel): ????????????module.gradient_checkpointing?=?value @add_start_docstrings( ????"The?bare?LLaMA?Model?outputting?raw?hidden-states?without?any?specific?head?on?top.", ????LLAMA_START_DOCSTRING, ) class?LlamaModel(LlamaPreTrainedModel): ????""" ????Transformer?decoder?consisting?of?*config.num_hidden_layers*?layers.?Each?layer?is?a?[`LlamaDecoderLayer`] ????Args: ????????config:?LlamaConfig ????""" ????def?__init__(self,?config:?LlamaConfig): ????????super().__init__(config) ????????self.padding_idx?=?config.pad_token_id ????????self.vocab_size?=?config.vocab_size ????????self.embed_tokens?=?nn.Embedding(config.vocab_size,?config.hidden_size,?self.padding_idx) ????????self.layers?=?nn.ModuleList([LlamaDecoderLayer(config)?for?_?in?range(config.num_hidden_layers)]) ????????self.norm?=?LlamaRMSNorm(config.hidden_size,?eps=config.rms_norm_eps) ????????self.gradient_checkpointing?=?False ????????#?Initialize?weights?and?apply?final?processing ????????self.post_init() ????def?get_input_embeddings(self): ????????return?self.embed_tokens ????def?set_input_embeddings(self,?value): ????????self.embed_tokens?=?value ????#?Copied?from?transformers.models.bart.modeling_bart.BartDecoder._prepare_decoder_attention_mask ????def?_prepare_decoder_attention_mask(self,?attention_mask,?input_shape,?inputs_embeds,?past_key_values_length): ????????#?create?causal?mask ????????#?[bsz,?seq_len]?->?[bsz,?1,?tgt_seq_len,?src_seq_len] ????????combined_attention_mask?=?None ????????if?input_shape[-1]?>?1: ????????????combined_attention_mask?=?_make_causal_mask( ????????????????input_shape, ????????????????inputs_embeds.dtype, ????????????????device=inputs_embeds.device, ????????????????past_key_values_length=past_key_values_length, ????????????) ????????if?attention_mask?is?not?None: ????????????#?[bsz,?seq_len]?->?[bsz,?1,?tgt_seq_len,?src_seq_len] ????????????expanded_attn_mask?=?_expand_mask(attention_mask,?inputs_embeds.dtype,?tgt_len=input_shape[-1]).to( ????????????????inputs_embeds.device ????????????) ????????????combined_attention_mask?=?( ????????????????expanded_attn_mask?if?combined_attention_mask?is?None?else?expanded_attn_mask?+?combined_attention_mask ????????????) ????????return?combined_attention_mask ????@add_start_docstrings_to_model_forward(LLAMA_INPUTS_DOCSTRING) ????def?forward( ????????self, ????????input_ids:?torch.LongTensor?=?None, ????????attention_mask:?Optional[torch.Tensor]?=?None, ????????position_ids:?Optional[torch.LongTensor]?=?None, ????????past_key_values:?Optional[List[torch.FloatTensor]]?=?None, ????????inputs_embeds:?Optional[torch.FloatTensor]?=?None, ????????use_cache:?Optional[bool]?=?None, ????????output_attentions:?Optional[bool]?=?None, ????????output_hidden_states:?Optional[bool]?=?None, ????????return_dict:?Optional[bool]?=?None, ????)?->?Union[Tuple,?BaseModelOutputWithPast]: ????????output_attentions?=?output_attentions?if?output_attentions?is?not?None?else?self.config.output_attentions ????????output_hidden_states?=?( ????????????output_hidden_states?if?output_hidden_states?is?not?None?else?self.config.output_hidden_states ????????) ????????use_cache?=?use_cache?if?use_cache?is?not?None?else?self.config.use_cache ????????return_dict?=?return_dict?if?return_dict?is?not?None?else?self.config.use_return_dict ????????#?retrieve?input_ids?and?inputs_embeds ????????if?input_ids?is?not?None?and?inputs_embeds?is?not?None: ????????????raise?ValueError("You?cannot?specify?both?decoder_input_ids?and?decoder_inputs_embeds?at?the?same?time") ????????elif?input_ids?is?not?None: ????????????batch_size,?seq_length?=?input_ids.shape ????????elif?inputs_embeds?is?not?None: ????????????batch_size,?seq_length,?_?=?inputs_embeds.shape ????????else: ????????????raise?ValueError("You?have?to?specify?either?decoder_input_ids?or?decoder_inputs_embeds") ????????seq_length_with_past?=?seq_length ????????past_key_values_length?=?0 ????????if?past_key_values?is?not?None: ????????????past_key_values_length?=?past_key_values[0][0].shape[2] ????????????seq_length_with_past?=?seq_length_with_past?+?past_key_values_length ????????if?position_ids?is?None: ????????????device?=?input_ids.device?if?input_ids?is?not?None?else?inputs_embeds.device ????????????position_ids?=?torch.arange( ????????????????past_key_values_length,?seq_length?+?past_key_values_length,?dtype=torch.long,?device=device ????????????) ????????????position_ids?=?position_ids.unsqueeze(0).view(-1,?seq_length) ????????else: ????????????position_ids?=?position_ids.view(-1,?seq_length).long() ????????if?inputs_embeds?is?None: ????????????inputs_embeds?=?self.embed_tokens(input_ids) ????????#?embed?positions ????????if?attention_mask?is?None: ????????????attention_mask?=?torch.ones( ????????????????(batch_size,?seq_length_with_past),?dtype=torch.bool,?device=inputs_embeds.device ????????????) ????????attention_mask?=?self._prepare_decoder_attention_mask( ????????????attention_mask,?(batch_size,?seq_length),?inputs_embeds,?past_key_values_length ????????) ????????hidden_states?=?inputs_embeds ????????if?self.gradient_checkpointing?and?self.training: ????????????if?use_cache: ????????????????logger.warning_once( ????????????????????"`use_cache=True`?is?incompatible?with?gradient?checkpointing.?Setting?`use_cache=False`..." ????????????????) ????????????????use_cache?=?False ????????#?decoder?layers ????????all_hidden_states?=?()?if?output_hidden_states?else?None ????????all_self_attns?=?()?if?output_attentions?else?None ????????next_decoder_cache?=?()?if?use_cache?else?None ????????for?idx,?decoder_layer?in?enumerate(self.layers): ????????????if?output_hidden_states: ????????????????all_hidden_states?+=?(hidden_states,) ????????????past_key_value?=?past_key_values[idx]?if?past_key_values?is?not?None?else?None ????????????if?self.gradient_checkpointing?and?self.training: ????????????????def?create_custom_forward(module): ????????????????????def?custom_forward(*inputs): ????????????????????????#?None?for?past_key_value ????????????????????????return?module(*inputs,?output_attentions,?None) ????????????????????return?custom_forward ????????????????layer_outputs?=?torch.utils.checkpoint.checkpoint( ????????????????????create_custom_forward(decoder_layer), ????????????????????hidden_states, ????????????????????attention_mask, ????????????????????position_ids, ????????????????????None, ????????????????) ????????????else: ????????????????layer_outputs?=?decoder_layer( ????????????????????hidden_states, ????????????????????attention_mask=attention_mask, ????????????????????position_ids=position_ids, ????????????????????past_key_value=past_key_value, ????????????????????output_attentions=output_attentions, ????????????????????use_cache=use_cache, ????????????????) ????????????hidden_states?=?layer_outputs[0] ????????????if?use_cache: ????????????????next_decoder_cache?+=?(layer_outputs[2?if?output_attentions?else?1],) ????????????if?output_attentions: ????????????????all_self_attns?+=?(layer_outputs[1],) ????????hidden_states?=?self.norm(hidden_states) ????????#?add?hidden?states?from?the?last?decoder?layer ????????if?output_hidden_states: ????????????all_hidden_states?+=?(hidden_states,) ????????next_cache?=?next_decoder_cache?if?use_cache?else?None ????????if?not?return_dict: ????????????return?tuple(v?for?v?in?[hidden_states,?next_cache,?all_hidden_states,?all_self_attns]?if?v?is?not?None) ????????return?BaseModelOutputWithPast( ????????????last_hidden_state=hidden_states, ????????????past_key_values=next_cache, ????????????hidden_states=all_hidden_states, ????????????attentions=all_self_attns, ????????)
?
?
7,Llama語言模型
Llama語言模型 LlamaForCausalLM是在Llama解碼器LlamaModel的基礎上增加了一個lm_head作為Generator。
從而實現了一個完整的語言模型。
除此之外,Llama語言模型還實現了以下重要功能。
1,loss計算功能。當forward方法中傳入labels時,會自動計算語言模型的交叉熵損失。注意labels中的-100會被忽略不參與計算。
2,文本生成generate方法。這個方法繼承自PreTrainedModel,可以設置model.generation_config.num_beams選擇束搜索的束寬度,默認為1即貪心搜索。
?
?
_CONFIG_FOR_DOC?=?"LlamaConfig" class?LlamaForCausalLM(LlamaPreTrainedModel): ????_tied_weights_keys?=?["lm_head.weight"] ????def?__init__(self,?config): ????????super().__init__(config) ????????self.model?=?LlamaModel(config) ????????self.vocab_size?=?config.vocab_size ????????self.lm_head?=?nn.Linear(config.hidden_size,?config.vocab_size,?bias=False) ????????#?Initialize?weights?and?apply?final?processing ????????self.post_init() ????def?get_input_embeddings(self): ????????return?self.model.embed_tokens ????def?set_input_embeddings(self,?value): ????????self.model.embed_tokens?=?value ????def?get_output_embeddings(self): ????????return?self.lm_head ????def?set_output_embeddings(self,?new_embeddings): ????????self.lm_head?=?new_embeddings ????def?set_decoder(self,?decoder): ????????self.model?=?decoder ????def?get_decoder(self): ????????return?self.model ????@add_start_docstrings_to_model_forward(LLAMA_INPUTS_DOCSTRING) ????@replace_return_docstrings(output_type=CausalLMOutputWithPast,?config_class=_CONFIG_FOR_DOC) ????def?forward( ????????self, ????????input_ids:?torch.LongTensor?=?None, ????????attention_mask:?Optional[torch.Tensor]?=?None, ????????position_ids:?Optional[torch.LongTensor]?=?None, ????????past_key_values:?Optional[List[torch.FloatTensor]]?=?None, ????????inputs_embeds:?Optional[torch.FloatTensor]?=?None, ????????labels:?Optional[torch.LongTensor]?=?None, ????????use_cache:?Optional[bool]?=?None, ????????output_attentions:?Optional[bool]?=?None, ????????output_hidden_states:?Optional[bool]?=?None, ????????return_dict:?Optional[bool]?=?None, ????)?->?Union[Tuple,?CausalLMOutputWithPast]: ????????output_attentions?=?output_attentions?if?output_attentions?is?not?None?else?self.config.output_attentions ????????output_hidden_states?=?( ????????????output_hidden_states?if?output_hidden_states?is?not?None?else?self.config.output_hidden_states ????????) ????????return_dict?=?return_dict?if?return_dict?is?not?None?else?self.config.use_return_dict ????????#?decoder?outputs?consists?of?(dec_features,?layer_state,?dec_hidden,?dec_attn) ????????outputs?=?self.model( ????????????input_ids=input_ids, ????????????attention_mask=attention_mask, ????????????position_ids=position_ids, ????????????past_key_values=past_key_values, ????????????inputs_embeds=inputs_embeds, ????????????use_cache=use_cache, ????????????output_attentions=output_attentions, ????????????output_hidden_states=output_hidden_states, ????????????return_dict=return_dict, ????????) ????????hidden_states?=?outputs[0] ????????if?self.config.pretraining_tp?>?1: ????????????lm_head_slices?=?self.lm_head.weight.split(self.vocab_size?//?self.config.pretraining_tp,?dim=0) ????????????logits?=?[F.linear(hidden_states,?lm_head_slices[i])?for?i?in?range(self.config.pretraining_tp)] ????????????logits?=?torch.cat(logits,?dim=-1) ????????else: ????????????logits?=?self.lm_head(hidden_states) ????????logits?=?logits.float() ????????loss?=?None ????????if?labels?is?not?None: ????????????#?Shift?so?that?tokens??
?
8,Llama分類模型
LlamaForSequenceClassification是一個序列分類模型。
這個分類模型可以用來訓練RLHF流程中的Reward模型。
?
?
@add_start_docstrings( ????""" ????The?LLaMa?Model?transformer?with?a?sequence?classification?head?on?top?(linear?layer). ????[`LlamaForSequenceClassification`]?uses?the?last?token?in?order?to?do?the?classification,?as?other?causal?models ????(e.g.?GPT-2)?do. ????Since?it?does?classification?on?the?last?token,?it?requires?to?know?the?position?of?the?last?token.?If?a ????`pad_token_id`?is?defined?in?the?configuration,?it?finds?the?last?token?that?is?not?a?padding?token?in?each?row.?If ????no?`pad_token_id`?is?defined,?it?simply?takes?the?last?value?in?each?row?of?the?batch.?Since?it?cannot?guess?the ????padding?tokens?when?`inputs_embeds`?are?passed?instead?of?`input_ids`,?it?does?the?same?(take?the?last?value?in ????each?row?of?the?batch). ????""", ????LLAMA_START_DOCSTRING, ) class?LlamaForSequenceClassification(LlamaPreTrainedModel): ????def?__init__(self,?config): ????????super().__init__(config) ????????self.num_labels?=?config.num_labels ????????self.model?=?LlamaModel(config) ????????self.score?=?nn.Linear(config.hidden_size,?self.num_labels,?bias=False) ????????#?Initialize?weights?and?apply?final?processing ????????self.post_init() ????def?get_input_embeddings(self): ????????return?self.model.embed_tokens ????def?set_input_embeddings(self,?value): ????????self.model.embed_tokens?=?value ????@add_start_docstrings_to_model_forward(LLAMA_INPUTS_DOCSTRING) ????def?forward( ????????self, ????????input_ids:?torch.LongTensor?=?None, ????????attention_mask:?Optional[torch.Tensor]?=?None, ????????position_ids:?Optional[torch.LongTensor]?=?None, ????????past_key_values:?Optional[List[torch.FloatTensor]]?=?None, ????????inputs_embeds:?Optional[torch.FloatTensor]?=?None, ????????labels:?Optional[torch.LongTensor]?=?None, ????????use_cache:?Optional[bool]?=?None, ????????output_attentions:?Optional[bool]?=?None, ????????output_hidden_states:?Optional[bool]?=?None, ????????return_dict:?Optional[bool]?=?None, ????)?->?Union[Tuple,?SequenceClassifierOutputWithPast]: ????????r""" ????????labels?(`torch.LongTensor`?of?shape?`(batch_size,)`,?*optional*): ????????????Labels?for?computing?the?sequence?classification/regression?loss.?Indices?should?be?in?`[0,?..., ????????????config.num_labels?-?1]`.?If?`config.num_labels?==?1`?a?regression?loss?is?computed?(Mean-Square?loss),?If ????????????`config.num_labels?>?1`?a?classification?loss?is?computed?(Cross-Entropy). ????????""" ????????return_dict?=?return_dict?if?return_dict?is?not?None?else?self.config.use_return_dict ????????transformer_outputs?=?self.model( ????????????input_ids, ????????????attention_mask=attention_mask, ????????????position_ids=position_ids, ????????????past_key_values=past_key_values, ????????????inputs_embeds=inputs_embeds, ????????????use_cache=use_cache, ????????????output_attentions=output_attentions, ????????????output_hidden_states=output_hidden_states, ????????????return_dict=return_dict, ????????) ????????hidden_states?=?transformer_outputs[0] ????????logits?=?self.score(hidden_states) ????????if?input_ids?is?not?None: ????????????batch_size?=?input_ids.shape[0] ????????else: ????????????batch_size?=?inputs_embeds.shape[0] ????????if?self.config.pad_token_id?is?None?and?batch_size?!=?1: ????????????raise?ValueError("Cannot?handle?batch?sizes?>?1?if?no?padding?token?is?defined.") ????????if?self.config.pad_token_id?is?None: ????????????sequence_lengths?=?-1 ????????else: ????????????if?input_ids?is?not?None: ????????????????sequence_lengths?=?(torch.eq(input_ids,?self.config.pad_token_id).long().argmax(-1)?-?1).to( ????????????????????logits.device ????????????????) ????????????else: ????????????????sequence_lengths?=?-1 ????????pooled_logits?=?logits[torch.arange(batch_size,?device=logits.device),?sequence_lengths] ????????loss?=?None ????????if?labels?is?not?None: ????????????labels?=?labels.to(logits.device) ????????????if?self.config.problem_type?is?None: ????????????????if?self.num_labels?==?1: ????????????????????self.config.problem_type?=?"regression" ????????????????elif?self.num_labels?>?1?and?(labels.dtype?==?torch.long?or?labels.dtype?==?torch.int): ????????????????????self.config.problem_type?=?"single_label_classification" ????????????????else: ????????????????????self.config.problem_type?=?"multi_label_classification" ????????????if?self.config.problem_type?==?"regression": ????????????????loss_fct?=?MSELoss() ????????????????if?self.num_labels?==?1: ????????????????????loss?=?loss_fct(pooled_logits.squeeze(),?labels.squeeze()) ????????????????else: ????????????????????loss?=?loss_fct(pooled_logits,?labels) ????????????elif?self.config.problem_type?==?"single_label_classification": ????????????????loss_fct?=?CrossEntropyLoss() ????????????????loss?=?loss_fct(pooled_logits.view(-1,?self.num_labels),?labels.view(-1)) ????????????elif?self.config.problem_type?==?"multi_label_classification": ????????????????loss_fct?=?BCEWithLogitsLoss() ????????????????loss?=?loss_fct(pooled_logits,?labels) ????????if?not?return_dict: ????????????output?=?(pooled_logits,)?+?transformer_outputs[1:] ????????????return?((loss,)?+?output)?if?loss?is?not?None?else?output ????????return?SequenceClassifierOutputWithPast( ????????????loss=loss, ????????????logits=pooled_logits, ????????????past_key_values=transformer_outputs.past_key_values, ????????????hidden_states=transformer_outputs.hidden_states, ????????????attentions=transformer_outputs.attentions, ????????)?
?
三,訓練模型
下面,我們來訓練一個LlamaForCausalLM 實現兩數之和的任務。
?
?
config?=?LlamaConfig( ????vocab_size=len(vocab), ????hidden_size=512, ????intermediate_size=2752, ????num_hidden_layers=8, ????num_attention_heads=16, ????num_key_value_heads=4, ????rope_scaling?=?None, ????hidden_act='silu', ????max_position_embeddings=128, ????initializer_range=0.02, ????rms_norm_eps=1e-06, ????use_cache=True, ????pad_token_id=0, ????bos_token_id=1, ????eos_token_id=2, ????tie_word_embeddings=False, ????pretraining_tp?=?1, ????max_new_tokens?=?100 )?#試算一下 model?=?LlamaForCausalLM(config) out?=?model.forward(**batch) print(out.loss)?
?
tensor(2.7630, grad_fn=)
?
?
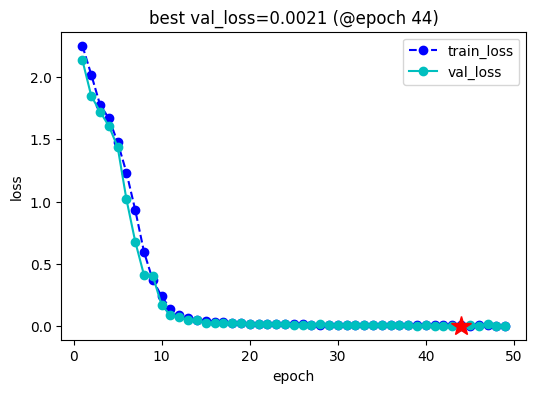
from?torchkeras?import?KerasModel? from?accelerate?import?Accelerator? class?StepRunner: ????def?__init__(self,?net,?loss_fn,?accelerator=None,?stage?=?"train",?metrics_dict?=?None,? ?????????????????optimizer?=?None,?lr_scheduler?=?None ?????????????????): ????????self.net,self.loss_fn,self.metrics_dict,self.stage?=?net,loss_fn,metrics_dict,stage ????????self.optimizer,self.lr_scheduler?=?optimizer,lr_scheduler ????????self.accelerator?=?accelerator?if?accelerator?is?not?None?else?Accelerator()? ????????if?self.stage=='train': ????????????self.net.train()? ????????else: ????????????self.net.eval() ???? ????def?__call__(self,?batch): ???????? ????????#loss ????????with?self.accelerator.autocast(): ????????????loss?=?self.net(**batch).loss ????????#backward() ????????if?self.stage=="train"?and?self.optimizer?is?not?None:???????? ????????????self.accelerator.backward(loss) ????????????if?self.accelerator.sync_gradients: ????????????????self.accelerator.clip_grad_norm_(self.net.parameters(),?1.0) ????????????self.optimizer.step() ????????????if?self.lr_scheduler?is?not?None: ????????????????self.lr_scheduler.step() ????????????self.optimizer.zero_grad() ???????????? ????????all_loss?=?self.accelerator.gather(loss).sum() ???????? ????????#losses?(or?plain?metrics?that?can?be?averaged) ????????step_losses?=?{self.stage+"_loss":all_loss.item()} ???????? ????????#metrics?(stateful?metrics) ????????step_metrics?=?{} ???????? ????????if?self.stage=="train": ????????????if?self.optimizer?is?not?None: ????????????????step_metrics['lr']?=?self.optimizer.state_dict()['param_groups'][0]['lr'] ????????????else: ????????????????step_metrics['lr']?=?0.0 ????????return?step_losses,step_metrics ???? KerasModel.StepRunner?=?StepRunner?keras_model?=?KerasModel(model,loss_fn?=?None, ????????optimizer=torch.optim.AdamW(model.parameters(),lr=3e-5)) #加載?之前訓練過的權重 ckpt_path?=?'llama_twosum' keras_model.fit(train_data?=?dl_train, ????????????????val_data?=?dl_val, ????????????????epochs=100,patience=5, ????????????????monitor='val_loss',mode='min', ????????????????ckpt_path?=?ckpt_path, ????????????????mixed_precision='fp16' ???????????????)?
?
四,使用模型
?
?
from?transformers.generation.utils?import?GenerationConfig model.generation_config?=?GenerationConfig.from_dict({'num_beams':1, ????????????????????????????'max_new_tokens':100, ????????????????????????????'max_length':200})model.generation_config.num_beams=1 model.generation_config.max_new_tokens?=?100? model.generation_config.max_length=200def?get_ans(tensor)?->"str": ????s?=?"".join([vocab_r[i]?for?i?in?tensor.tolist()]) ????ans?=?s[s.find('=')+1:s.find('')].replace(' ','').replace(' ','') ????return?ans x,y?=?get_data()? print('x:?'+''.join(x).replace('','')) print('y:?'+''.join(y).replace(' ','')) x: 3481340050+90157504501803= y: 90160985841853input_ids?=?torch.tensor([[vocab[i]?for?i?in?x]])? out?=?model.generate(inputs=input_ids)out??
?
tensor([[ 1, ?5, ?6, 10, ?3, ?5, ?6, 12, 12, ?7, 12, 13, 11, 12, ?3, ?7, ?9, ?7,12, ?6, ?7, 12, ?3, 10, 12, ?5, 14, 11, 12, ?3, ?8, 12, 11, 10, ?7, 10,6, ?3, 10, ?7, ?5, ?2, ?2, ?2, ?2, ?2, ?2, ?2, ?2, ?2, ?2, ?2, ?2, ?2,2, ?2, ?2, ?2, ?2, ?2, ?2, ?2, ?2, ?2, 12, ?2, ?2, ?2, ?2, ?2, ?2, ?2,2, 12, ?3, 12, ?3]])
?
?
get_ans(out[0])?
?
'90160985841853'
五,評估模型
?
?
from?tqdm?import?tqdm? loop?=?tqdm(range(1,201)) correct?=?0 for?i?in?loop: ????x,y?=?get_data()? ????input_ids?=?torch.tensor([[vocab[i]?for?i?in?x]])? ????out?=?model.generate(inputs=input_ids) ????pred?=?get_ans(out[0]) ????gt?=?''.join(y).replace('','') ????if?pred==gt: ????????correct+=1 ????loop.set_postfix(acc?=?correct/i) ???? print("acc=",correct/len(loop)) ?
?
acc= 0.99
漂亮,我們的測試準確率達到了99%!
編輯:好
?

















 工商網監
工商網監
評論