 電子發燒友App
電子發燒友App


前言
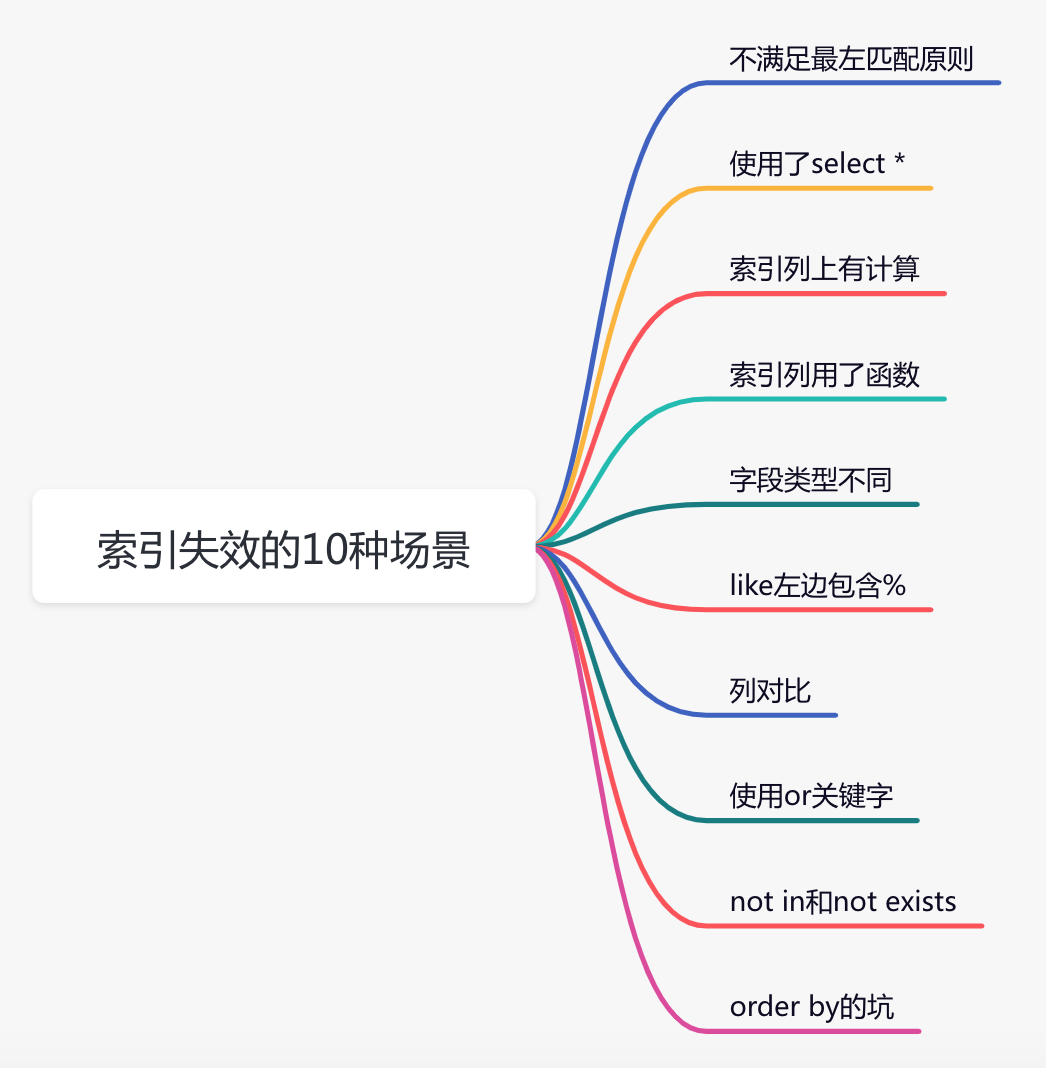
當你在遇到了一條慢?SQL?需要進行優化時,你第一時間能想到的優化手段是什么?
大部分人第一反應可能都是添加索引,在大多數情況下面,索引能夠將一條?SQL?語句的查詢效率提高幾個數量級。
索引的本質:用于快速查找記錄的一種數據結構。
索引的常用數據結構:
二叉樹
紅黑樹
Hash 表
B-tree?(B樹,并不叫什么B減樹)
B+tree
數據結構圖形化網址:https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
索引查詢
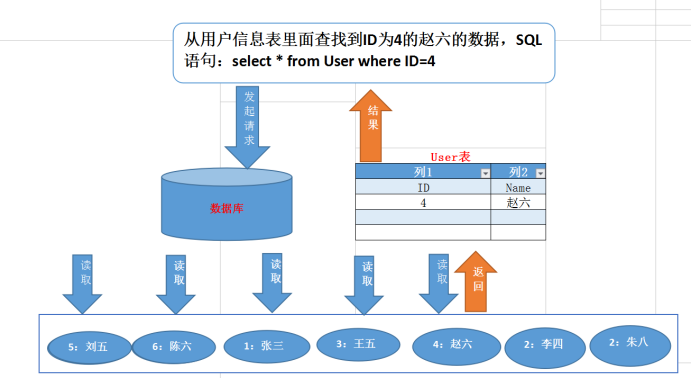
大家知道?select * from t where col = 88?這么一條?SQL?語句如果不走索引進行查找的話,正常地查就是全表掃描:從表的第一行記錄開始逐行找,把每一行的?col?字段的值和?88?進行對比,這明顯效率是很低的。
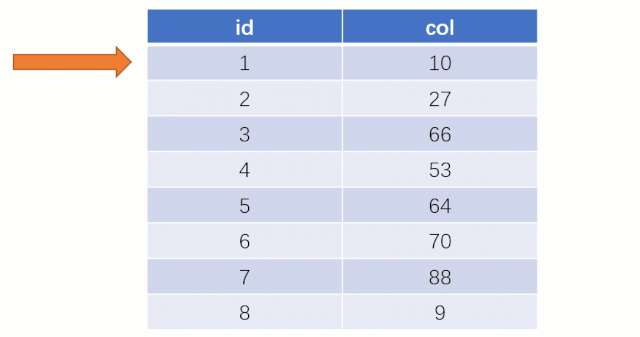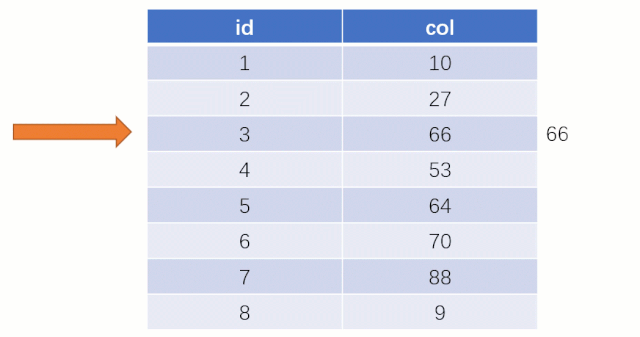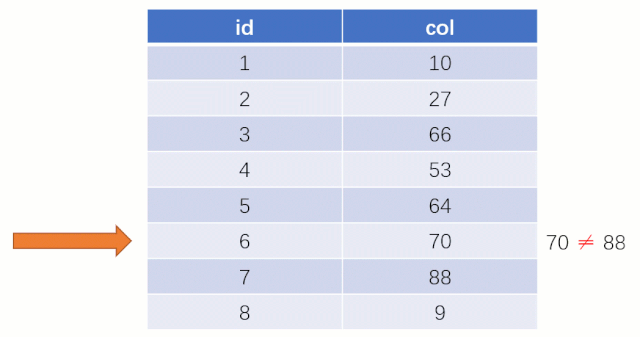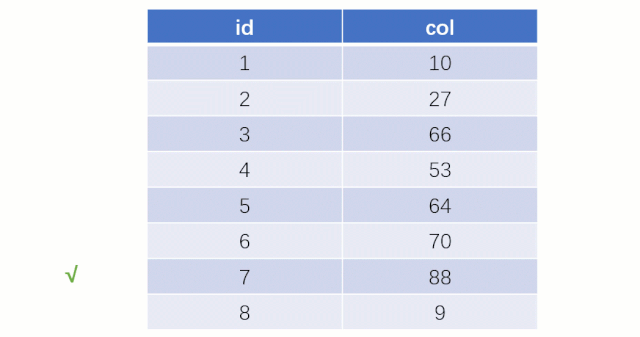
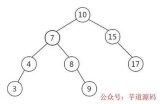
而如果走索引的話,查詢的流程就完全不一樣了(假設現在用一棵平衡二叉樹數據結構存儲我們的索引列)
此時該二叉樹的存儲結構(Key - Value):Key 就是索引字段的數據,Value 就是索引所在行的磁盤文件地址。
當最后找到了?88?的時候,就可以把它的 Value 對應的磁盤文件地址拿出來,然后就直接去磁盤上去找這一行的數據,這時候的速度就會比全表掃描要快很多。
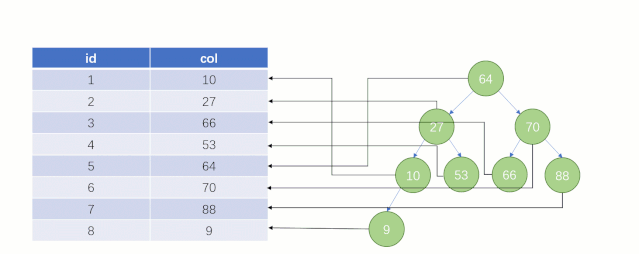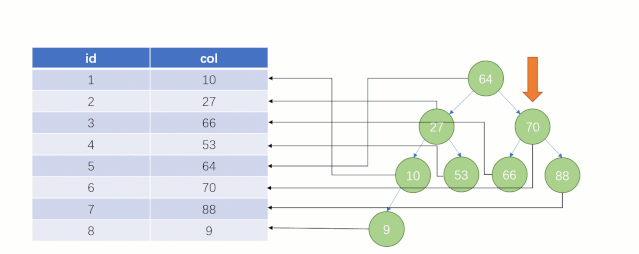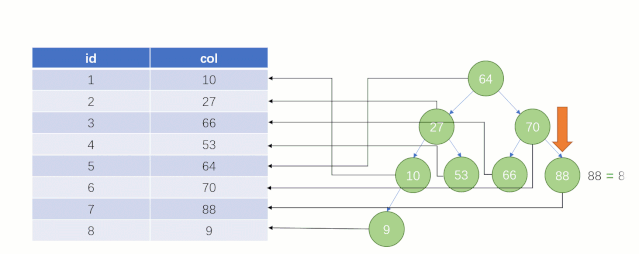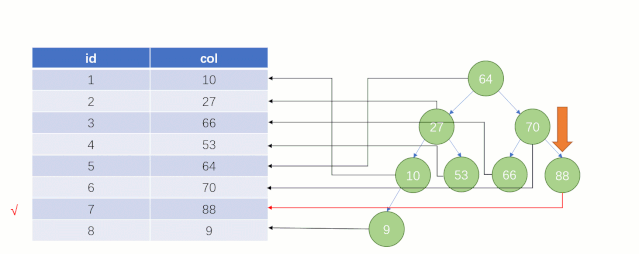
但實際上?MySQL?底層并沒有用二叉樹來存儲索引數據,是用的?B+tree(B+樹)。
為什么不采用二叉樹
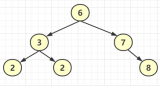
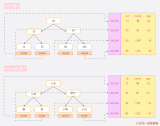
假設此時用普通二叉樹記錄?id?索引列,我們在每插入一行記錄的同時還要維護二叉樹索引字段。
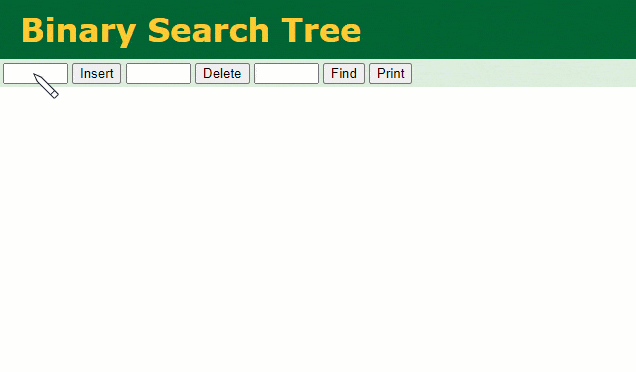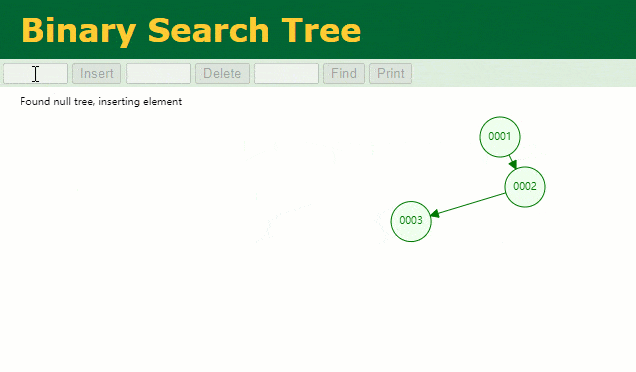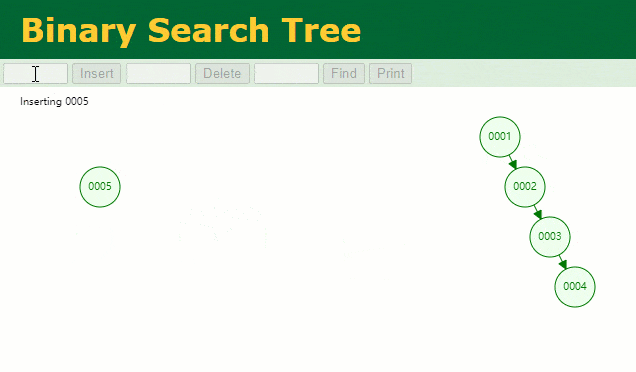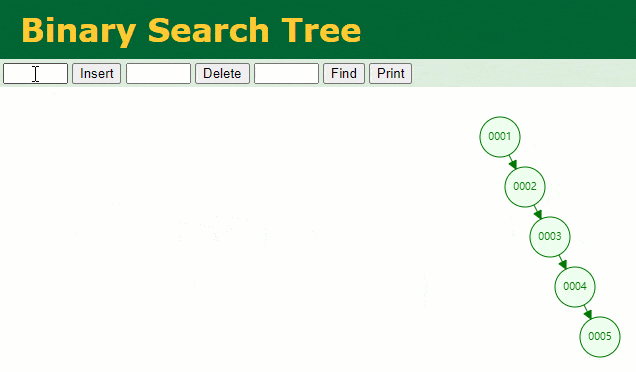
此時當我要找?id = 7?的那條數據時,它的查找過程如下:
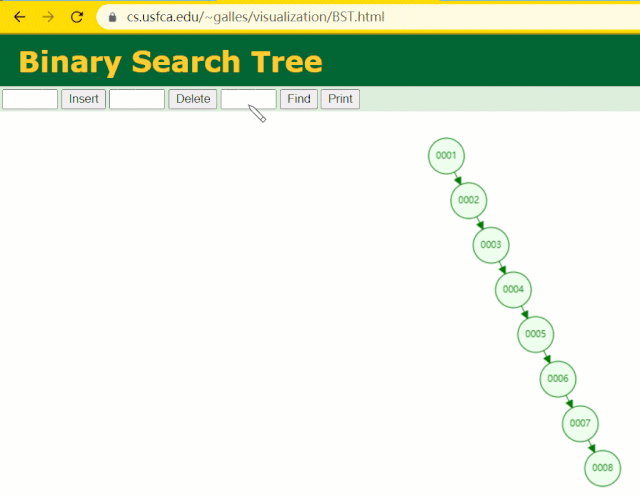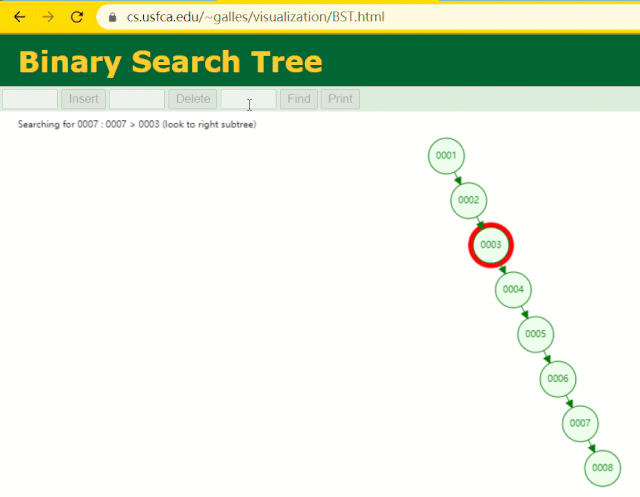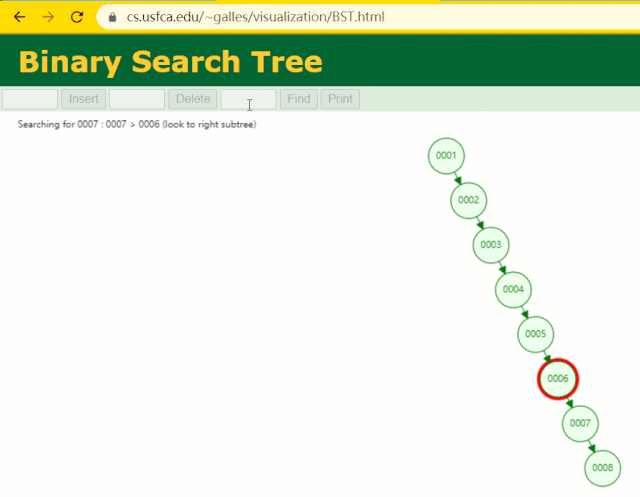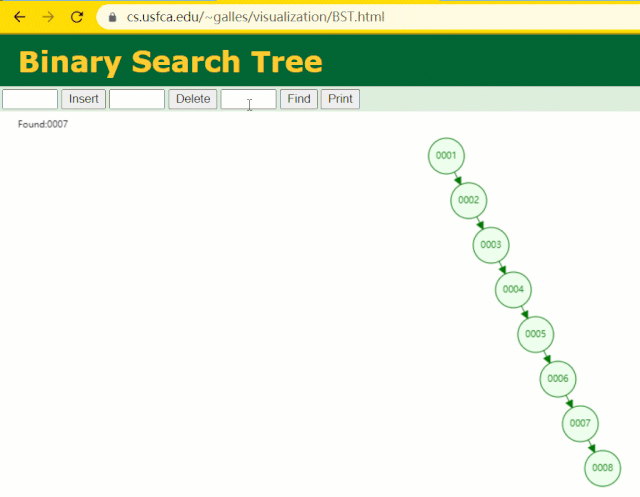
此時找?id = 7?這一行記錄時找了?7?次,和我們全表掃描也沒什么很大區別。顯而易見,二叉樹對于這種依次遞增的數據列其實是不適合作為索引的數據結構。
為什么不采用 Hash 表
“
Hash 表:一個快速搜索的數據結構,搜索的時間復雜度 O(1)
Hash 函數:將一個任意類型的 key,可以轉換成一個 int 類型的下標
”
假設此時用 Hash 表記錄?id?索引列,我們在每插入一行記錄的同時還要維護 Hash 表索引字段。
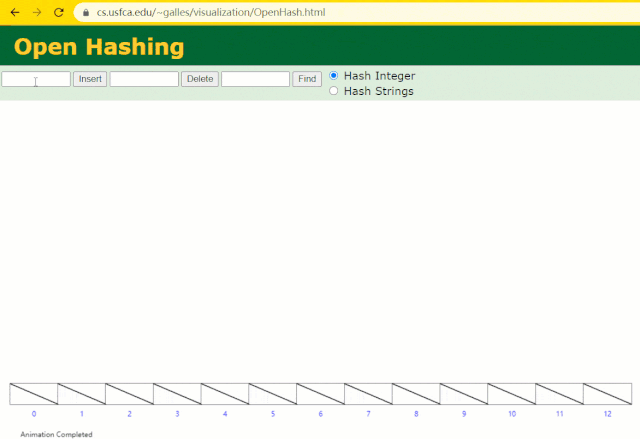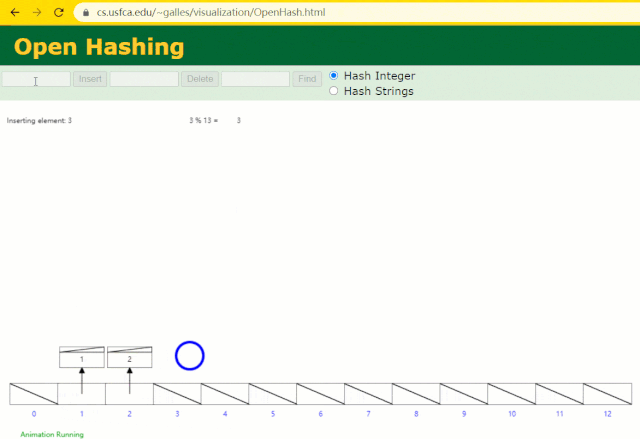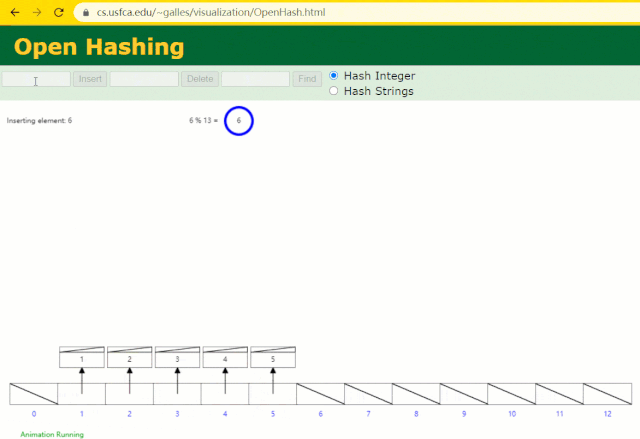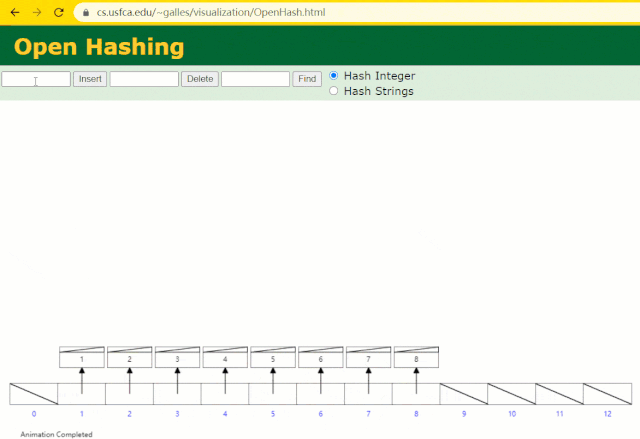
這時候開始查找?id = 7?的樹節點僅找了?1?次,效率非常高了。
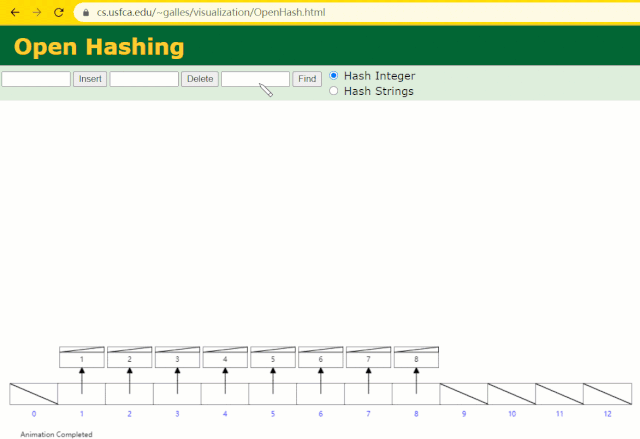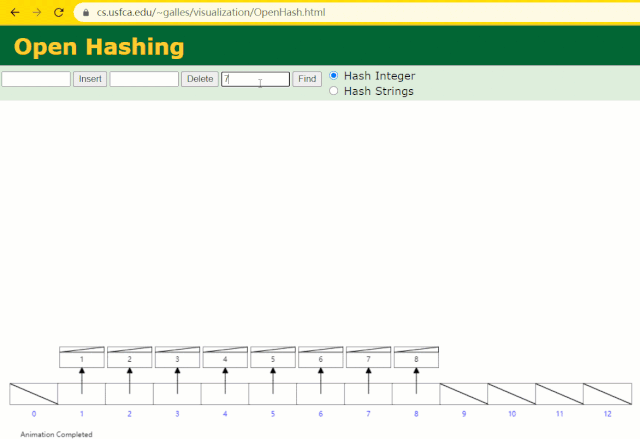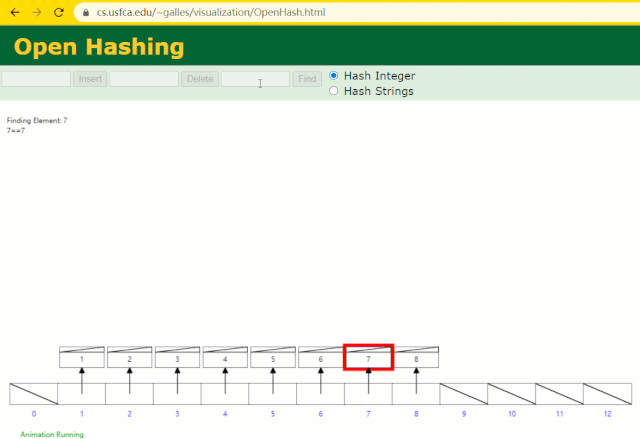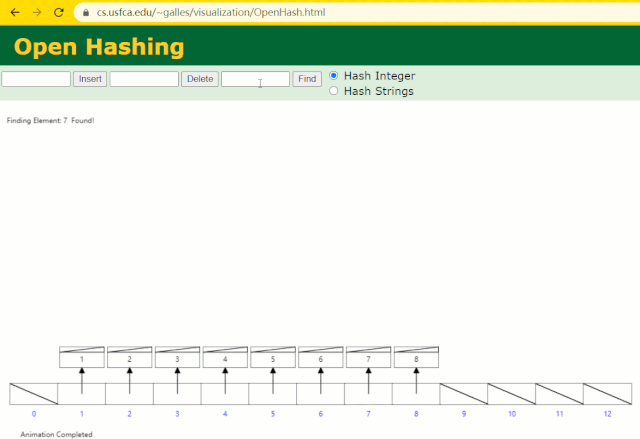
但?MySQL?的索引依然不采用能夠精準定位的Hash 表。因為它不適用于范圍查詢。
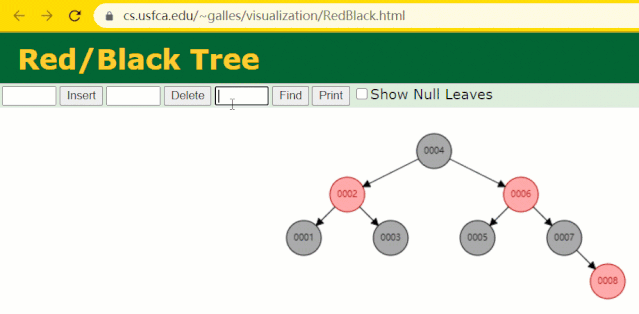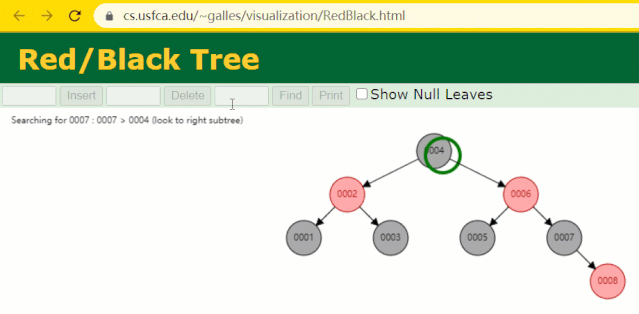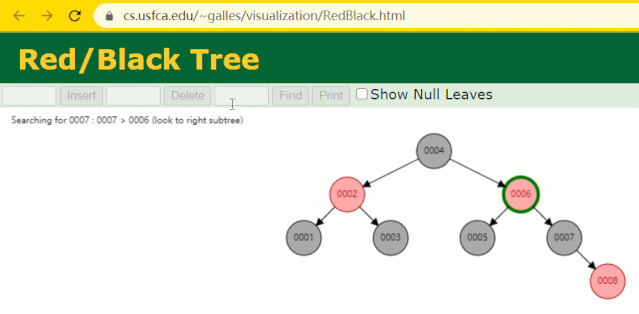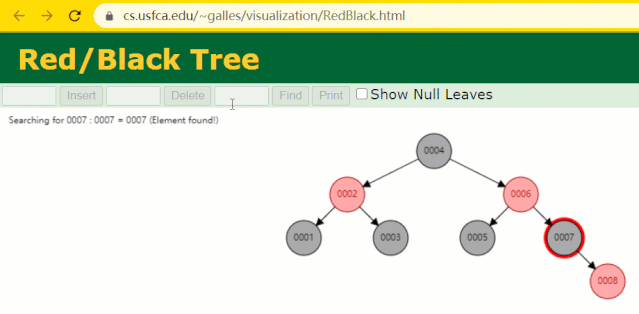
為什么不采用紅黑樹
“
紅黑樹是一種特化的 AVL樹(平衡二叉樹),都是在進行插入和刪除操作時通過特定操作保持二叉查找樹的平衡;
若一棵二叉查找樹是紅黑樹,則它的任一子樹必為紅黑樹。
”
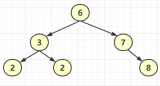
假設此時用紅黑樹記錄?id?索引列,我們在每插入一行記錄的同時還要維護紅黑樹索引字段。
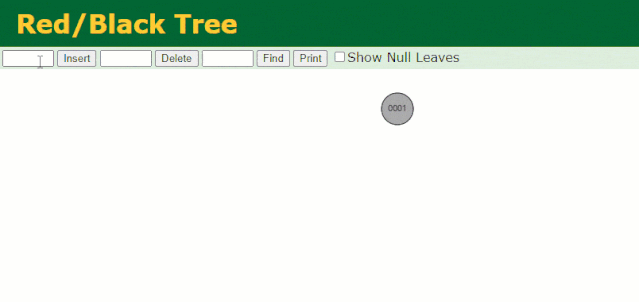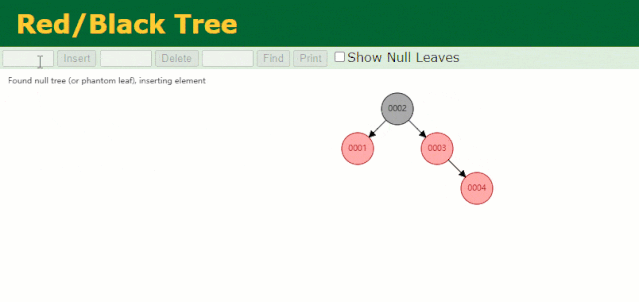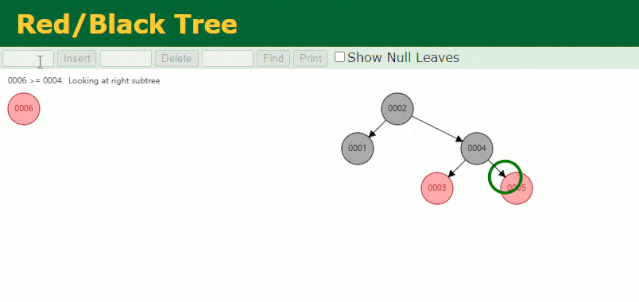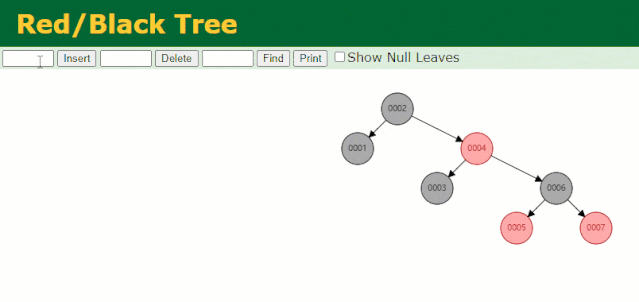
插入過程中會發現它與普通二叉樹不同的是當一棵樹的左右子樹高度差 > 1 時,它會進行自旋操作,保持樹的平衡。
這時候開始查找?id = 7?的樹節點只找了?3?次,比所謂的普通二叉樹還是要更快的。
但?MySQL?的索引依然不采用能夠精確定位和范圍查詢都優秀的紅黑樹。
因為當?MySQL?數據量很大的時候,索引的體積也會很大,可能內存放不下,所以需要從磁盤上進行相關讀寫,如果樹的層級太高,則讀寫磁盤的次數(I/O交互)就會越多,性能就會越差。
B-tree
“
紅黑樹目前的唯一不足點就是樹的高度不可控,所以現在我們的切入點就是樹的高度。
目前一個節點是只分配了一個存儲 1 個元素,如果要控制高度,我們就可以把一個節點分配的空間更大一點,讓它橫向存儲多個元素,這個時候高度就可控了。這么個改造過程,就變成了?B-tree。
”
B-tree?是一棵絕對平衡的多路樹。它的結構中還有兩個概念
“
度(Degree):一個節點擁有的子節點(子樹)的數量。(有的地方是以度來說明?B-tree?的,這里解釋一下)
階(order):一個節點的子節點的最大個數。(通常用?m?表示)
關鍵字:數據索引。
”
一棵 m 階?B-tree?是一棵平衡的 m 路搜索樹。它可能是空樹,或者滿足以下特點:
除根節點和葉子節點外,其它每個節點至少有??個子節點;
為 m / 2 然后向上取整
每個非根節點所包含的關鍵字個數 j 滿足:?- 1 ≤ j ≤ m - 1;
節點的關鍵字從左到右遞增排列,有 k 個關鍵字的非葉子節點正好有 (k + 1) 個子節點;
所有的葉子結點都位于同一層。
名字取義(題外話,放松一下)
以下摘自維基百科
魯道夫·拜爾(Rudolf Bayer)和 艾華·M·麥克雷(Ed M. McCreight)于1972年在波音研究實驗室(Boeing Research Labs)工作時發明了?B-tree,但是他們沒有解釋 B 代表什么意義(如果有的話)。
道格拉斯·科默爾(Douglas Comer)解釋說:兩位作者從來都沒解釋過?B-tree?的原始意義。我們可能覺得 balanced, broad 或 bushy 可能適合。其他人建議字母 B 代表 Boeing。源自于他的贊助,不過,看起來把?B-tree?當作 Bayer 樹更合適些。
高德納(Donald Knuth)在他1980年5月發表的題為 "CS144C classroom lecture about disk storage and B-trees" 的論文中推測了?B-tree?的名字取義,提出 B 可能意味 Boeing 或者 Bayer 的名字。
查找
B-tree?的查找其實和二叉樹很相似:
二叉樹是每個節點上有一個關鍵字和兩個分支,B-tree?上每個節點有 k 個關鍵字和 (k + 1) 個分支。
二叉樹的查找只考慮向左還是向右走,而?B-tree?中需要由多個分支決定。
B-tree?的查找分兩步:
首先查找節點,由于?B-tree?通常是在磁盤上存儲的所以這步需要進行磁盤IO操作;
查找關鍵字,當找到某個節點后將該節點讀入內存中然后通過順序或者折半查找來查找關鍵字。若沒有找到關鍵字,則需要判斷大小來找到合適的分支繼續查找。
操作流程
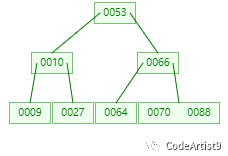
現在需要查找元素:88
第一次:磁盤IO
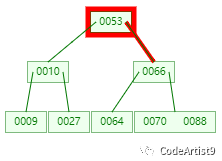
第二次:磁盤IO
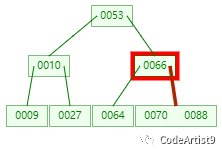
第三次:磁盤IO
然后這有一次內存比對,分別跟 70 與 88 比對,最后找到 88。
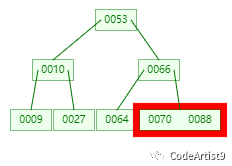
從查找過程中發現,B-tree?比對次數和磁盤IO的次數其實和二叉樹相差不了多少,這么看來并沒有什么優勢。
但是仔細一看會發現,比對是在內存中完成中,不涉及到磁盤IO,耗時可以忽略不計。
另外?B-tree?中一個節點中可以存放很多的關鍵字(個數由階決定),相同數量的關鍵字在?B-tree?中生成的節點要遠遠少于二叉樹中的節點,相差的節點數量就等同于磁盤IO的次數。這樣到達一定數量后,性能的差異就顯現出來了。
插入
當?B-tree?要進行插入關鍵字時,都是直接找到葉子節點進行操作。
根據要插入的關鍵字查找到待插入的葉子節點;
因為一個節點的子節點的最大個數(階)為 m,所以需要判斷當前節點關鍵字的個數是否小于 (m - 1)。
是:直接插入
否:發生節點分裂,以節點的中間的關鍵字將該節點分為左右兩部分,中間的關鍵字放到父節點中即可。
操作流程
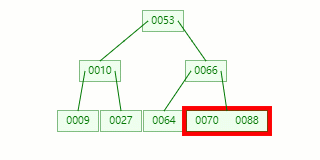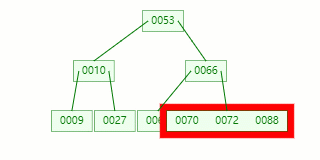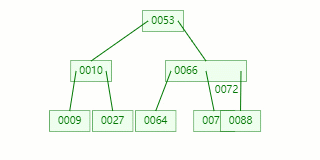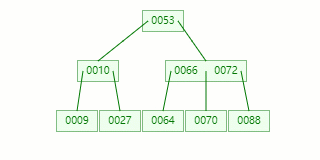
比如我們現在需要在 Max Degree(階)為 3 的?B-tree插入元素:72
查找待插入的葉子節點
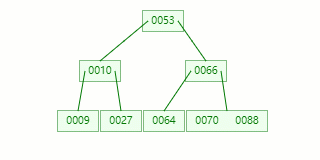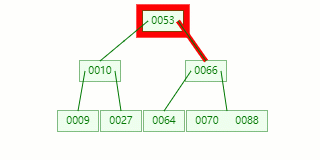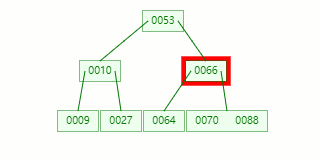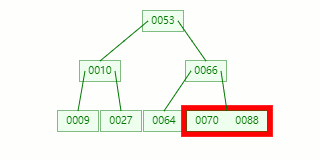
節點分裂:本來應該和 [70,88] 在同一個磁盤塊上,但是當一個節點有 3 個關鍵字的時候,它就有可能有 4 個子節點,就超過了我們所定義限制的最大度數 3,所以此時必須進行分裂:以中間關鍵字為界將節點一分為二,產生一個新節點,并把中間關鍵字上移到父節點中。
Tip?: 當中間關鍵字有兩個時,通常將左關鍵字進行上移分裂。
刪除
刪除操作就會比查找和插入要麻煩一些,因為要被刪除的關鍵字可能在葉子節點上,也可能不在,而且刪除后還可能導致?B-tree?的不平衡,又要進行合并、旋轉等操作去保持整棵樹的平衡。
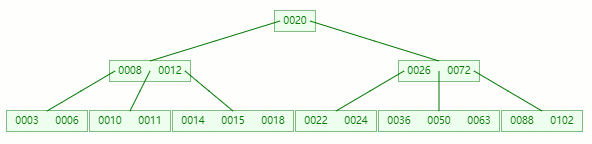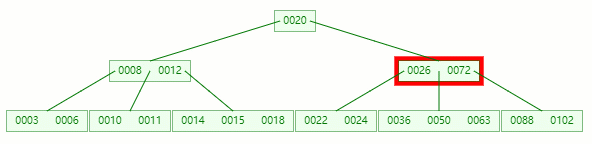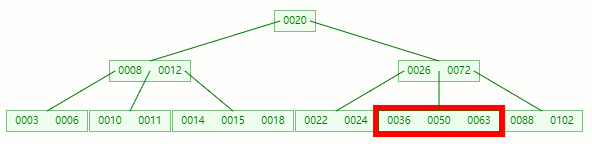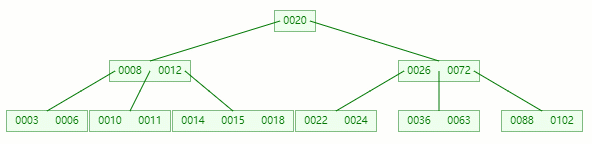
隨便拿棵樹(5 階)舉例子
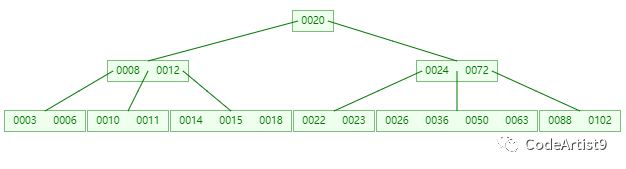
情況一:直接刪除葉子節點的元素
刪除目標:50
查找元素 50 位置
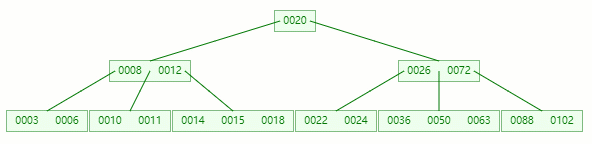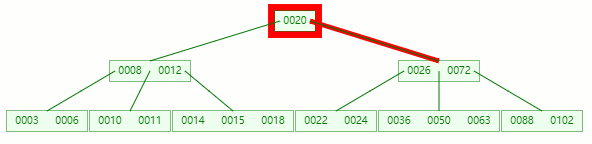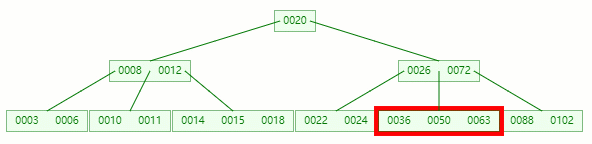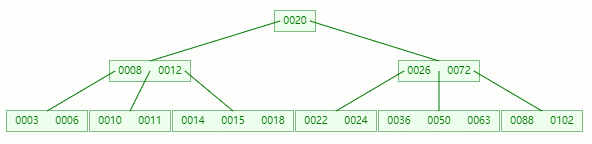
在 [36, 50, 63] 節點移除 50 后,依然符合?B-tree?對節點內關鍵字的要求:
┌m/2┐?-?1?≤?關鍵字個數?≤?m?-?1 ┌5/2┐?-?1?≤?3?-?1?≤?5?-?1 2?≤?2?≤?4?
?
?
刪除完成
情況二:刪除葉子節點的元素后合并+旋轉
刪除目標:11
查找元素 11 位置
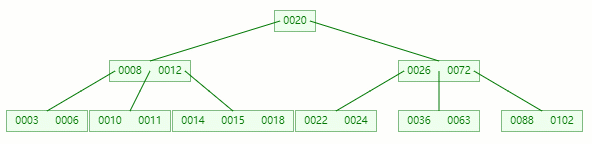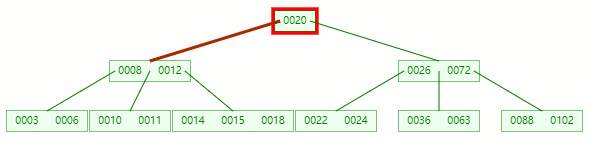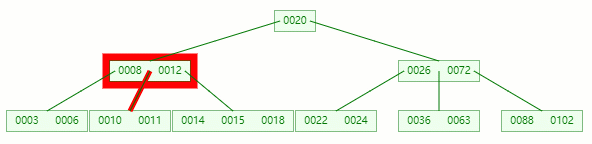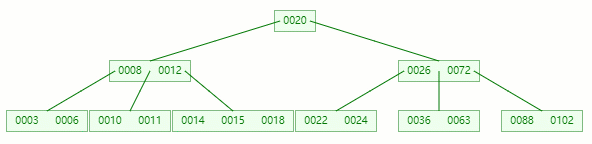
在 [10, 11] 節點移除 11 后,違背?B-tree?對節點內關鍵字的要求:
?
?
┌m/2┐?-?1?≤?關鍵字個數?≤?m?-?1 ┌5/2┐?-?1?≤?2?-?1?≤?5?-?1 2?≤?1?≤?4?
?
?
在它只剩1個關鍵字后,需要向兄弟節點借元素,這時候右兄弟有多的,它說:我愿意把14借給你
但不可能讓11和14放一起,因為?14 > 12?,這時候就要進行旋轉~
首先,將父節點的元素 12 移到該節點,然后 12 就讓位給14
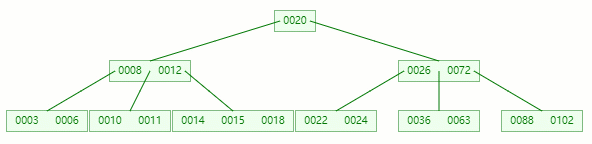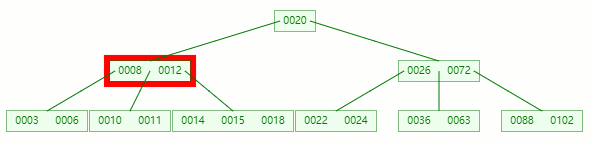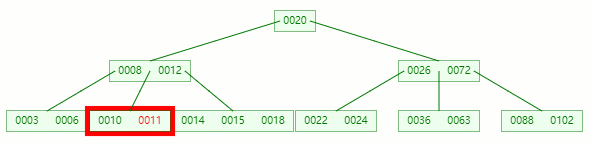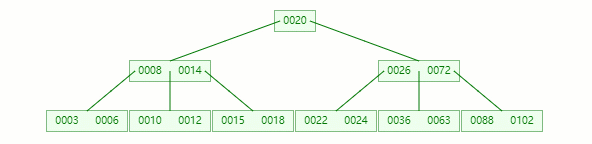
這整個過程就是刪除葉子節點元素后的合并、旋轉操作
下面再來道菜
接著刪除 10
在 [10, 12] 節點移除 10 后,違背?B-tree?對節點內關鍵字的要求
在它只剩1個關鍵字后,需要向兄弟節點借元素,這時候沒有兄弟有多的該怎么辦呢
首先,將父節點的元素 8 移到該節點,這時候 3、6、8、12 都小于14,就先把它們放一起
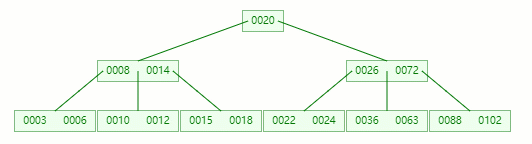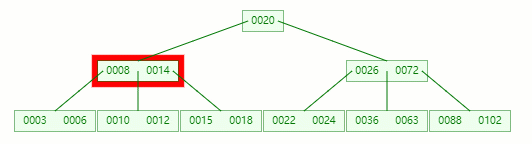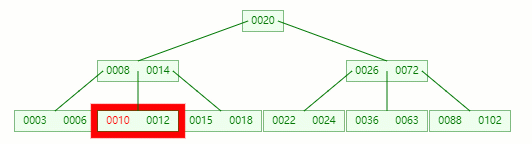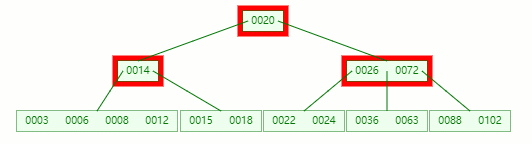
結果又發現父節點只剩個14了,它又違背了?B-tree?對節點內關鍵字的要求,接著造!!!
首先,還是將父節點的元素 20 移到該節點,這時候根節點都直接沒了,直接合并 14、20、26、72 關鍵字
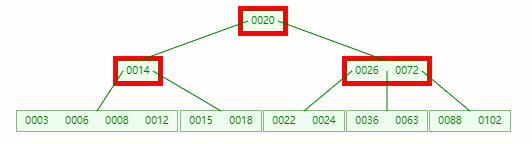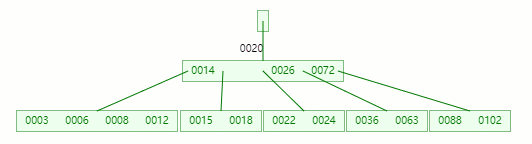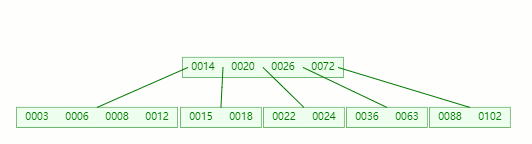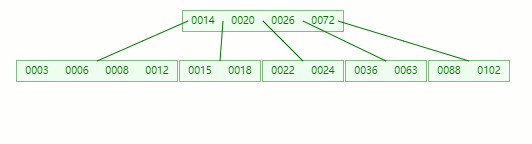
在這整個過程包括刪除葉子節點和非葉子節點的合并、旋轉操作
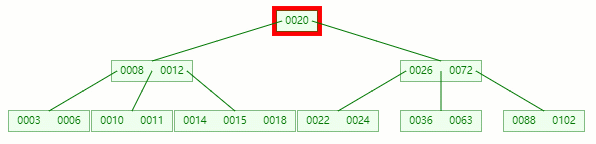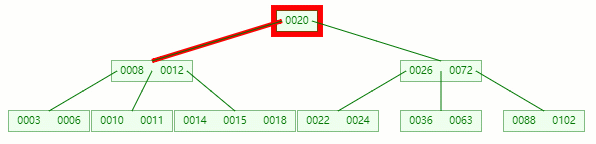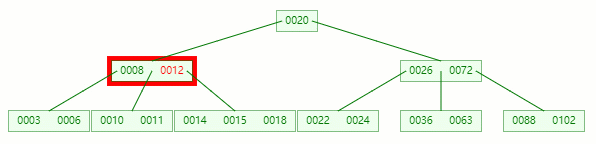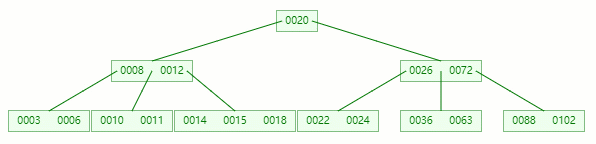
情況三:刪除非葉子節點的元素后合并+旋轉
刪除目標:12
查找元素 12 位置
移除 12 后,違背?B-tree?對節點內關鍵字的要求
對于非葉子節點元素的刪除,我們需要用后繼元素覆蓋要被刪除的元素,然后在后繼元素所在的葉子中刪除該后繼元素。
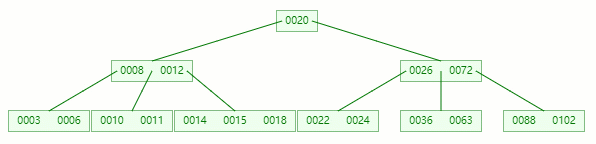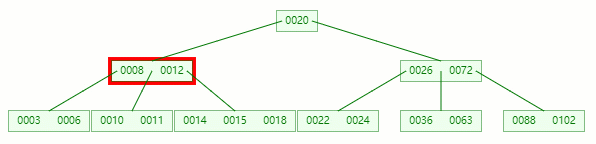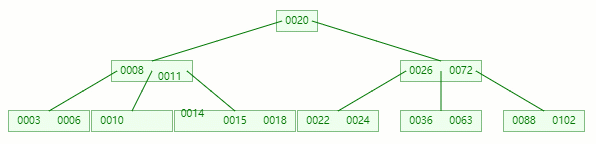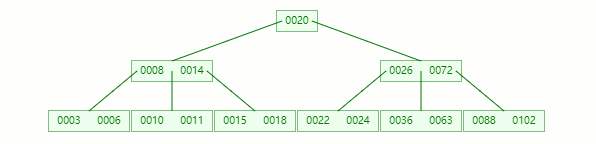
小總結
“
B-tree 主要用于文件系統以及部分數據庫索引,例如:MongoDB。
從查找效率考慮一般要求 B-tree 的階數 m ≥ 3
B-tree 上算法的執行時間主要由讀、寫磁盤的次數來決定,故一次I/O操作應讀寫盡可能多的信息。
因此 B-tree 的節點規模一般以一個磁盤頁為單位。一個結點包含的關鍵字及其孩子個數取決于磁盤頁的大小。
”
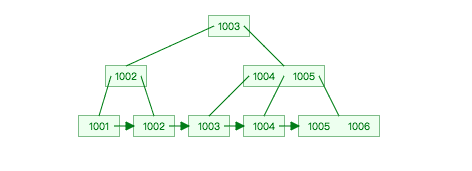
B+tree
上面這些例子相信大家對?B-tree?已經有一定了解了,而?MySQL?底層用的索引數據結構正是在?B-tree?上面做了一些改造,變成了?B+tree。
B+tree?和?B-tree?區別:
所有的子節點,一定會出現在葉子節點上
相鄰的葉子節點之間,會用一個雙向鏈表連接起來(關鍵)
非葉子節點只存儲索引,不存儲數據,就為放更多索引
相比?B-tree?來說,進行范圍查找時只需要查找兩個節點,進行遍歷就行。而?B-tree?需要獲取所有節點,相比之下?B+tree?效率更高。
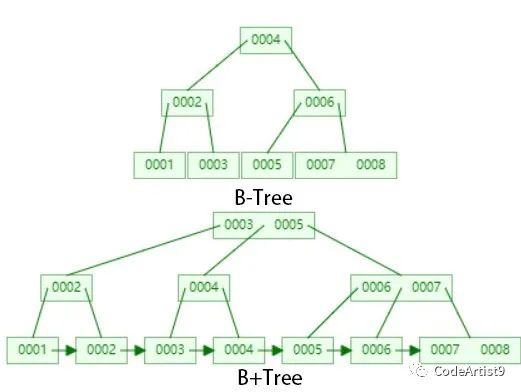
這里其實這個數據結構可視化網頁畫的?B+tree?還是不夠清晰,只是畫了個大概,下面我們就來看看它底層實際具體的數據結構
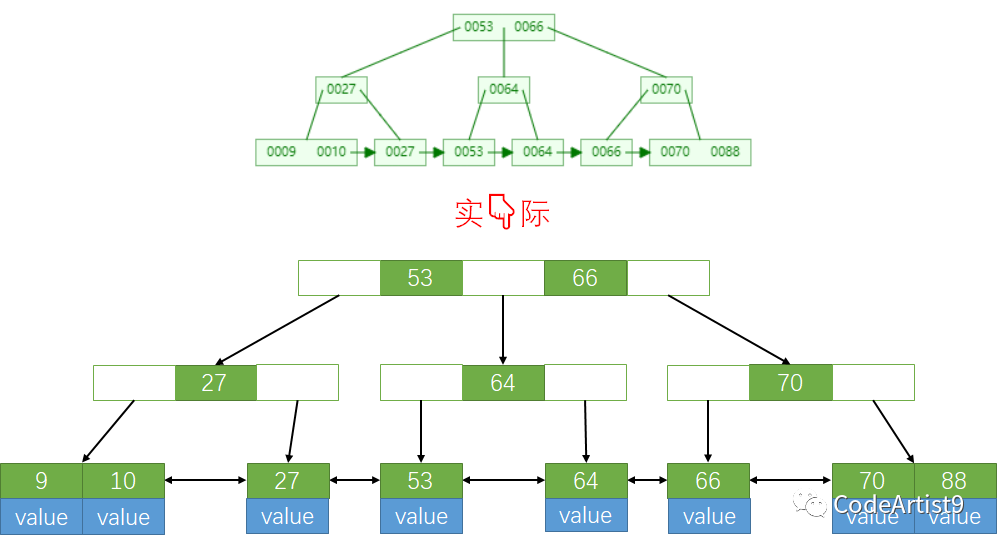
每個節點都被稱作一個磁盤頁
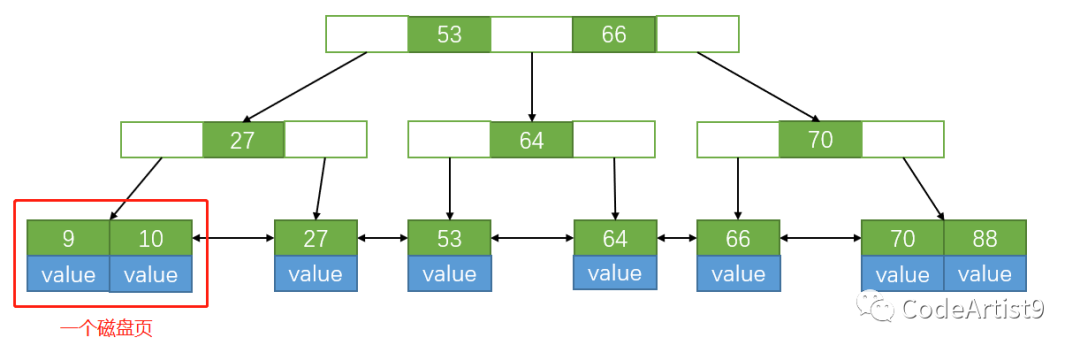
B+tree 的葉子節點包含所有索引數據,在非葉子節點會存儲不存儲數據,只存儲索引,從而來組成一棵 B+tree。
查找
B+tree?最大的優勢就在查找上,主要是范圍查詢更加明顯。
“
B-tree 節點中的每個關鍵字都有數據,而 B+tree 中間節點沒有數據,只有索引;這就意味著相同大小的磁盤頁可以放更多的節點元素,也就是在相同的數據量下,I/O 操作更少
在范圍查詢上,B-tree 需要先找到指定范圍內的下限,再找到上限,有了這兩個過程后再取出它們之間的元素。
B+tree 因為葉子節點通過雙向鏈表進行連接,找到指定范圍內的下限后,直接通過鏈表順序遍歷就行,這樣就方便很多了。
”
在查詢單個關鍵字上,和?B-tree?差不多:先把通過磁盤 I/O 找到節點,再把節點加載到內存中進行內部關鍵字比對,然后通過大小關系再決定接下來走哪個分支。
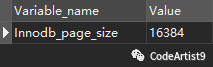
但是差別就在于?B+tree?的高度更加可控一些。MySQL?默認給一個磁盤頁數據分配的大小是?16KB,也就是 16 × 1024 = 16384 字節
官網說明:https://dev.mysql.com/doc/refman/5.7/en/innodb-physical-structure.html
證明:直接在數據庫中通過?SQL?語句?show GLOBAL STATUS LIKE 'INNODB_page_size'進行驗證
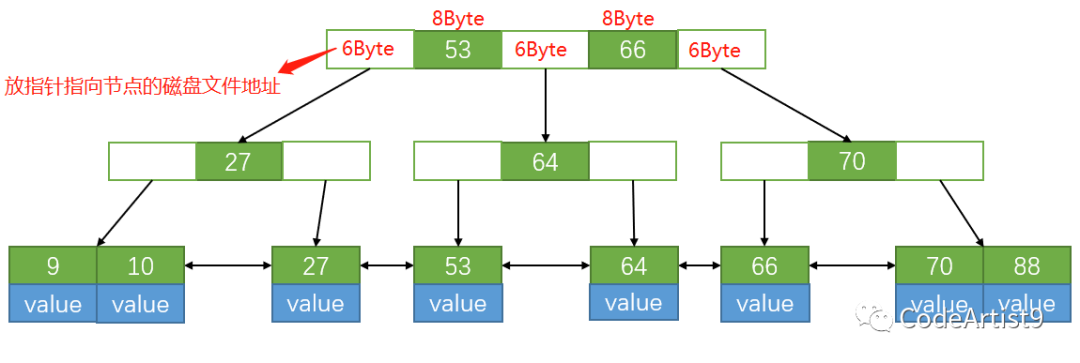
當我們的葉子節點全部撐滿之后,可以來算一算它樹的高度。
我們拿阿里的《Java 開發手冊》嵩山版中對表主鍵的要求進行舉例

bigint?大概占?8Byte,索引旁邊放指向下一節點的磁盤文件地址那塊是6Byte,是?MySQL?底層寫死了的。
通過計算:16384 Byte / (8+6) Byte ≈ 1170,也就是說一個節點設置?16KB?大小的話可以放 1170個索引。
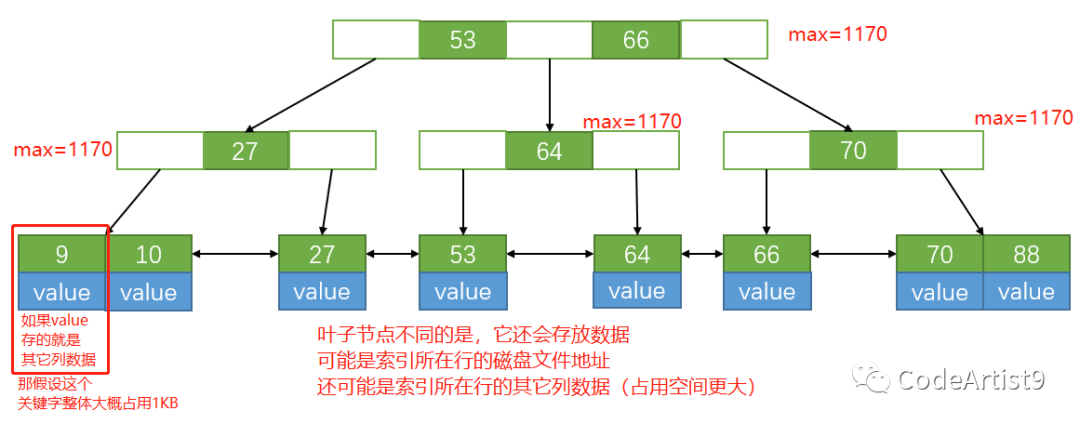
葉子節點一個關鍵字占用1KB時,那一個節點就可以放16個元素,當整棵樹葉子節點全部都被撐滿時,通過計算?1170 × 1170 × 16 = 21902400
最后結果為2千多萬,樹的高度才為3,也就是我們要的高度可控。這也就是為什么?MySQL?的表有上千萬數據的情況下,查詢效率依然快的原因。
插入
插入還是挺簡單的:當節點內元素數量大于 (m-1) 時,按中間元素分裂成左右兩部分,中間元素分裂到父節點當做索引存儲,本身中間元素也還會分裂右邊這一部分的。
下面以5階(m)舉
操作流程
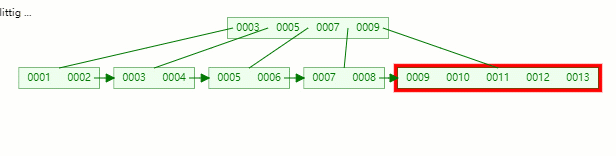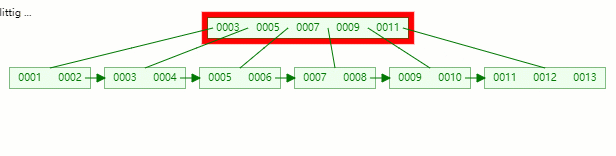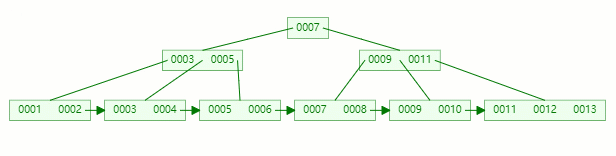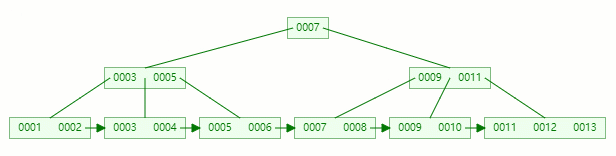
第一次在空樹中插入 1
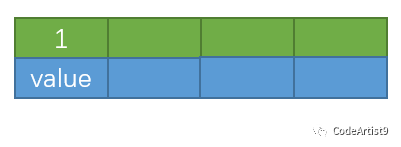
再依次插入 2,3,4
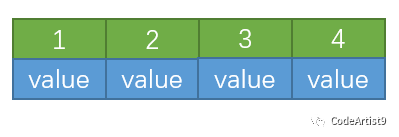
插入 5
當插入關鍵字 5 時,此時節點內元素數量大于 (5-1) ,即超過了4個,這時候就要進行分裂;
以中間元素分裂,中間元素分裂到父節點當做索引存儲,由于葉子節點包含所有索引數據,所以本身它還會分裂至右邊部分。
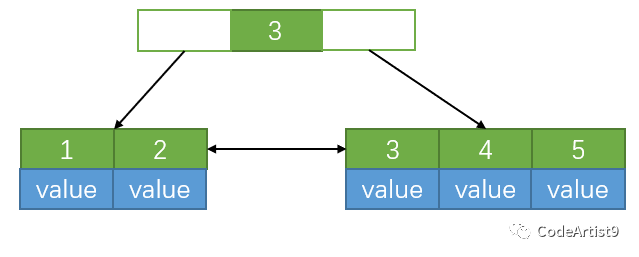
這個過程是在葉子節點上進行分裂操作
下面再來個插入后的非葉子節點分裂操作(大差不差)
在以下的基礎上插入關鍵字:13
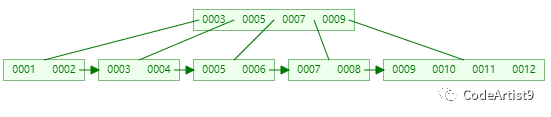
關鍵字13 插入到 [9, 10, 11, 12, 13] 后節點內元素數量超過了4個,準備進行分裂;
以中間元素(11)分裂,中間元素分裂到父節點當做索引存儲,本身它也還會分裂右邊部分。

關鍵字11 被挪到父節點去之后,節點內元素數量超過了4個,又要準備進行分裂
以中間元素(7)分裂,中間元素分裂到父節點當做(冗余)索引存儲。
插入完畢
刪除
在對應節點刪除目標關鍵字后,一樣需要看看節點內剩余關鍵字是否符合:?- 1 ≤ 關鍵字個數 ≤ m - 1
符合直接刪除就行,不符合就和?B-tree?一樣需要向兄弟節點借元素,不過會比?B-tree?稍簡單一點點
因為葉子節點(雙向鏈表)之間有指針關聯著,可以不需要再找它們的父節點了,直接通過兄弟節點進行移動,然后再更新父節點;
如果兄弟節點內元素沒有多余的關鍵字,那就直接將當前節點和兄弟節點合并,再刪除父節點中的關鍵字。
操作流程
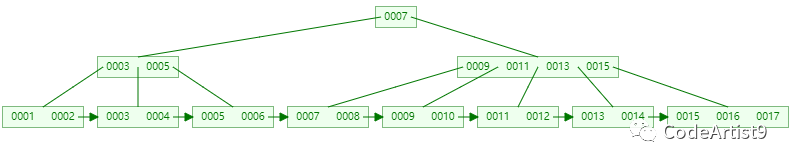
目標刪除元素:14
刪除 14 關鍵字后,它所在的節點只剩 13 一個關鍵字了
?
?
┌m/2┐?-?1?≤?關鍵字個數?≤?m?-?1 ┌5/2┐?-?1?≤?2?-?1?≤?5?-?1 2?≤?1?≤?4?
?
?
準備借元素!
直接通過右兄弟節點(只有它有富余)進行移動,然后再更新父節點的索引

刪除成功后
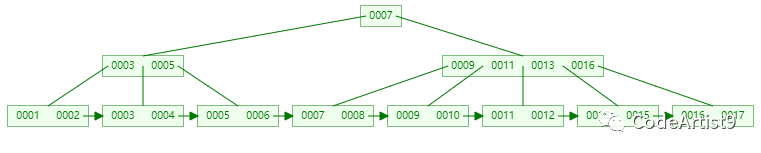
接著刪除元素:16
刪除 16 關鍵字后,它所在的節點只剩 17 一個關鍵字了,又要準備借元素;
這時候兄弟節點都沒有多的,就直接把它和兄弟節點合并,再刪除父節點中的關鍵字
合并關鍵字 [13, 15, 17] ,在刪除父節點中的關鍵字 16

刪除成功后
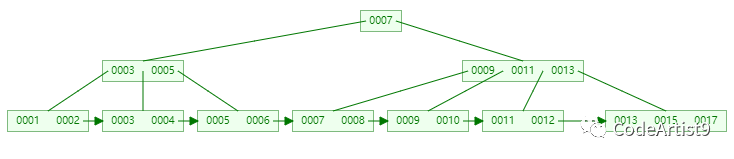
總 結
“
單個節點存儲越多的元素,自然在整個過程中的磁盤I/O交互就越少;
相對 B-tree 來說,所有的查詢最終都會找到葉子節點,這也是 B+tree 性能穩定的一個體現;
所有葉子節點通過雙向鏈表相連,范圍查詢非常方便,這也是 B+tree 最明顯的優勢。
”
編輯:黃飛
?


















 工商網監
工商網監
評論