 電子發燒友App
電子發燒友App


常用數據庫sql語句寫法整理
--創建一個用戶表
create table users (id int(10),pwd char(20),name varchar(10));
char表示占20個長度的空間 varchar根據實際長度決定空間大小
--復制表
create table users_copy as select * from users;
--增加數據到表中
方式1:insert into users values(1,‘1234’,‘d1’);
方式2:insert into users (id,name)values(2,‘d2’);
--查詢數據
最簡單的 select * from users;
條件查詢 select * from users where id=1 ;
select * from users where id=1 and name=‘d1’ ;(and表示且的意思)
select * from users where id=1 or id=2 ;(or表示或的意思)
select * from users where id in(1,3,4);(or的條件多了,用in)
select * from users where id》=2;(可以有大小條件)
select count(*) from users;(查詢有多少條數)
select * from employ where name like ‘%duan%’;(模糊查詢)
select * from employ where name like ‘duan%’;(模糊查詢,表示以duan開頭---結尾反之)
select distinct name from users;(除去重復記錄)
select * from employ order by id;(由小到大)
select * from employ order by id desc;(反之順序排列)
查詢的時候可以計算
select name,salary salary*12 from employ;(員工的年薪)
select name,salary+bonus from employ;(員工的月薪)
分組查詢
select job, count(*)from emp_ning group by job;
過濾分組結果:having短語
select deptno, count(*)from emp_ning group by deptno having count(*) 》= 5;
子查詢(即用某一查詢語句代替語句中要寫的數據)
select name from emp_ning where salary 》 (select salary
from emp_ning where id = 1002);
--子查詢的結果集是多行多列(結果如果返回多行,使用in, 》all, 》any, 《all, 《any)
select name, salary, deptno from emp_ning
where (deptno, salary) in(select deptno, max(salary)from emp_ning group by deptno);
--子查詢的結果如果返回一行( 使用單行比較運算符(=, 》, 《, 《=, 》=) )
select name, deptno, salary from emp_ning
where (deptno, salary) =(select deptno, max(salary)from emp_ning where deptno = 10
group by deptno);
關聯查詢
等值連接:(自連接為特殊情況)
內連接:
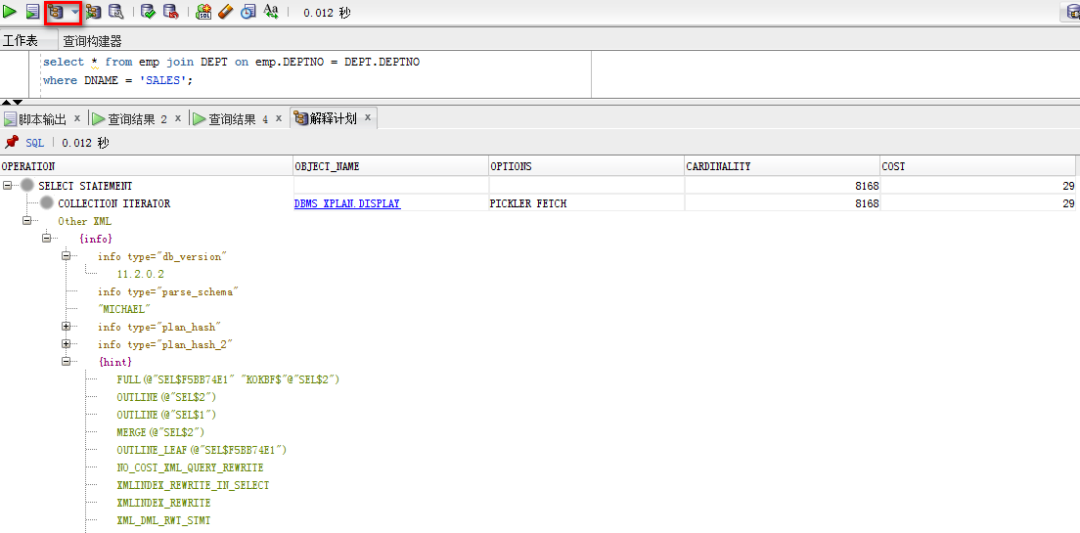
select emp.name,dept.dname from emp join dept on emp.deptno =dept.deptno;
外連接:(若為left 表示左邊的為驅動表(會全部顯示) 右邊的為匹配表 反之。。。。)
外連接的結果集 = 內連接的結果集 + 驅動表中在匹配表中找不到匹配記錄的 數據和空值的組合
select e.name, d.dname from emp_ning e left outer join dept_ning d on e.deptno = d.deptno;(emp的全部)
select e.name, d.dname from emp_ning e lright outer join dept_ning d on e.deptno = d.deptno;(dept的全部)
非等值連接:
select e.name,s.salary from emp e join salary s on e.sa
lary between s.lowsal and s.highsal;
查詢的總格式:
select 表1.列1, 表1.列2, 表2.列1,表2.列2,。。。。[組函數][單行函數]
from 表1
[left|right|full outer join 表2
on 表1.列1 = 表2.列2
where 條件1 and 條件2[子查詢] or 條件3
group by 列
having 組函數的條件[子查詢]
order by 列]
--更新數據的語句
update users set pwd=‘1234’ where id=2;
--刪除某行
delete from t_user where user_id = 1;
--刪除表結構 drop table users;
SQL語句中的函數( mysql為例子)
select *,round(salary*2.12222222,4) from employ;(round函數,省略到小數點后4位的全部信息)
select now();(查詢當前時間)
組函數 count / max / min / sum / avg
oracle數據庫中的分頁
select * from (select user_id,psort_id,user_name,user_age,insert_time,rownum as num from tb_user )t where num between ? and ?
?表示他們從第幾位到第幾位(非下標)
mysql中的分頁
select * from d_book limit 0,5;
表示從下標為0的開始,每頁五條
在mysql中 setnames utf8 可以解決查看數據庫時亂碼問題
下面是創建一個sqlserver數據庫的代碼模板,加上一個創建表的模板。開發的時候可以拷貝過去直接改動一下就可以用了。
USE [master]
GO
IF EXISTS(SELECT 1 FROM sysdatabases WHERE NAME=N‘HkTemp’)
BEGIN
DROP DATABASE HkTemp --如果數據庫存在先刪掉數據庫
END
GO
CREATE DATABASE HkTemp
ON
PRIMARY --創建主數據庫文件
(
NAME=‘HkTemp’,
FILENAME=‘E:\Databases\HkTemp.dbf’,
SIZE=5MB,
MaxSize=20MB,
FileGrowth=1MB
)
LOG ON --創建日志文件
(
NAME=‘HkTempLog’,
FileName=‘E:\Databases\HkTemp.ldf’,
Size=2MB,
MaxSize=20MB,
FileGrowth=1MB
)
GO
--添加表
IF NOT EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N‘Hksj_User’) AND type in (N‘U’))
BEGIN
CREATE TABLE Hksj_User
(
Id INT IDENTITY(1,1) NOT NULL,
SName NVARCHAR(20) NOT NULL,
SNickName NVARCHAR(20),
SPassWord NVARCHAR(30) NOT NULL,
SCreator NVARCHAR(20),
SEmail NVARCHAR(50),
SPhone NVARCHAR(50),
SIdentifyId NVARCHAR(30),
DLastTimeLogOn DATETIME
PRIMARY KEY CLUSTERED
(
Id ASC
)WITH (IGNORE_DUP_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]
END
GO
--添加注釋
EXEC sys.sp_addextendedproperty @name=N‘MS_Description’, @value=N‘登錄名’ , @level0type=N‘SCHEMA’,@level0name=N‘dbo’, @level1type=N‘TABLE’,@level1name=N‘Hksj_User’, @level2type=N‘COLUMN’,@level2name=N‘SName’
GO
EXEC sys.sp_addextendedproperty @name=N‘MS_Description’, @value=N‘郵箱’ , @level0type=N‘SCHEMA’,@level0name=N‘dbo’, @level1type=N‘TABLE’,@level1name=N‘Hksj_User’, @level2type=N‘COLUMN’,@level2name=N‘SEmail’
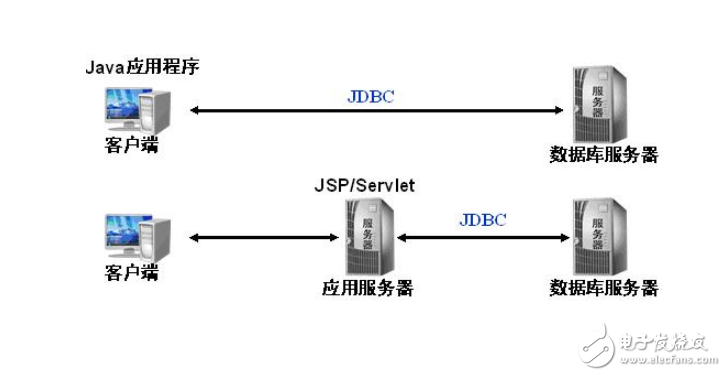
寫myeclipse鏈接sql數據庫的類的代碼例子
可以用jdbc來連接數據庫,完整代碼如下:
package com.jdbc.test;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class JDBCTest {
public static void main(String[] args) throws Exception {
//1.加載驅動
//Class.forName(“com.microsoft.sqlserver.jdbc.SQLServerDriver”);
//Class.forName(“com.mysql.jdbc.Driver”);
Class.forName(“oracle.jdbc.driver.OracleDriver”);
//2.創建數據庫連接對象
//Connection conn = DriverManager.getConnection(“jdbc:sqlserver://localhost:1433;databaseName=db”,“sa”,“sqlpass”);
//Connection conn = DriverManager.getConnection(“jdbc:mysql://localhost:3306/db?useUnicode=true&characterEncoding=UTF-8”,“root”,“123456”);
Connection conn = DriverManager.getConnection(“jdbc:oracle:thin:@localhost:1521:orcl”,“scott”,“Oracle123”);
//3.創建數據庫命令執行對象。
Statement stmt = conn.createStatement();
// PreparedStatement ps = conn.prepareStatement(“select * from t_user”);
//4.執行數據庫命令
ResultSet rs = stmt.executeQuery(“select * from t_user”);
// ResultSet rs = ps.executeQuery();
//5.處理執行結果
while (rs.next()) {
int id = rs.getInt(“id”);
String username = rs.getString(“username”);
String password = rs.getString(“password”);
System.out.println(id + “\t” + username + “\t” + password);}
//6.釋放數據庫資源
if (rs != null) {
rs.close();
}
// if (ps != null) {
// ps.close();
// }
if (stmt != null) {
stmt.close();
}
if (conn != null) {
conn.close();
}
}
}









 工商網監
工商網監
評論