 電子發(fā)燒友App
電子發(fā)燒友App


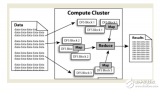
Hadoop 由許多元素構(gòu)成。其最底部是 Hadoop Distributed File System(HDFS),它存儲(chǔ) Hadoop 集群中所有存儲(chǔ)節(jié)點(diǎn)上的文件。HDFS(對(duì)于本文)的上一層是MapReduce 引擎,該引擎由 JobTrackers 和 TaskTrackers 組成。通過(guò)對(duì)Hadoop分布式計(jì)算平臺(tái)最核心的分布式文件系統(tǒng)HDFS、MapReduce處理過(guò)程,以及數(shù)據(jù)倉(cāng)庫(kù)工具Hive和分布式數(shù)據(jù)庫(kù)Hbase的介紹,基本涵蓋了Hadoop分布式平臺(tái)的所有技術(shù)核心。
Hadoop 設(shè)計(jì)之初的目標(biāo)就定位于高可靠性、高可拓展性、高容錯(cuò)性和高效性,正是這些設(shè)計(jì)上與生俱來(lái)的優(yōu)點(diǎn),才使得Hadoop 一出現(xiàn)就受到眾多大公司的青睞,同時(shí)也引起了研究界的普遍關(guān)注。到目前為止,Hadoop 技術(shù)在互聯(lián)網(wǎng)領(lǐng)域已經(jīng)得到了廣泛的運(yùn)用,例如,Yahoo 使用4 000 個(gè)節(jié)點(diǎn)的Hadoop集群來(lái)支持廣告系統(tǒng)和Web 搜索的研究;Facebook 使用1 000 個(gè)節(jié)點(diǎn)的集群運(yùn)行Hadoop,存儲(chǔ)日志數(shù)據(jù),支持其上的數(shù)據(jù)分析和機(jī)器學(xué)習(xí);
百度用Hadoop處理每周200TB 的數(shù)據(jù),從而進(jìn)行搜索日志分析和網(wǎng)頁(yè)數(shù)據(jù)挖掘工作;中國(guó)移動(dòng)研究院基于Hadoop 開發(fā)了“大云”(Big Cloud)系統(tǒng),不但用于相關(guān)數(shù)據(jù)分析,還對(duì)外提供服務(wù);淘寶的Hadoop 系統(tǒng)用于存儲(chǔ)并處理電子商務(wù)交易的相關(guān)數(shù)據(jù)。國(guó)內(nèi)的高校和科研院所基于Hadoop 在數(shù)據(jù)存儲(chǔ)、資源管理、作業(yè)調(diào)度、性能優(yōu)化、系統(tǒng)高可用性和安全性方面進(jìn)行研究,相關(guān)研究成果多以開源形式貢獻(xiàn)給Hadoop 社區(qū)。
除了上述大型企業(yè)將Hadoop 技術(shù)運(yùn)用在自身的服務(wù)中外,一些提供Hadoop 解決方案的商業(yè)型公司也紛紛跟進(jìn),利用自身技術(shù)對(duì)Hadoop 進(jìn)行優(yōu)化、改進(jìn)、二次開發(fā)等,然后以公司自有產(chǎn)品形式對(duì)外提供Hadoop 的商業(yè)服務(wù)。比較知名的有創(chuàng)辦于2008 年的Cloudera 公司,它是一家專業(yè)從事基于ApacheHadoop 的數(shù)據(jù)管理軟件銷售和服務(wù)的公司,它希望充當(dāng)大數(shù)據(jù)領(lǐng)域中類似RedHat 在Linux 世界中的角色。
該公司基于Apache Hadoop 發(fā)行了相應(yīng)的商業(yè)版本Cloudera Enterprise,它還提供Hadoop 相關(guān)的支持、咨詢、培訓(xùn)等服務(wù)。在2009 年,Cloudera 聘請(qǐng)了Doug Cutting(Hadoop 的創(chuàng)始人)擔(dān)任公司的首席架構(gòu)師,從而更加加強(qiáng)了Cloudera 公司在Hadoop 生態(tài)系統(tǒng)中的影響和地位。最近,Oracle 也表示已經(jīng)將Cloudera 的Hadoop 發(fā)行版和Cloudera Manager 整合到Oracle Big Data Appliance 中。同樣,Intel 也基于Hadoop 發(fā)行了自己的版本IDH。從這些可以看出,越來(lái)越多的企業(yè)將Hadoop 技術(shù)作為進(jìn)入大數(shù)據(jù)領(lǐng)域的必備技術(shù)。
需要說(shuō)明的是,Hadoop 技術(shù)雖然已經(jīng)被廣泛應(yīng)用,但是該技術(shù)無(wú)論在功能上還是在穩(wěn)定性等方面還有待進(jìn)一步完善,所以還在不斷開發(fā)和不斷升級(jí)維護(hù)的過(guò)程中,新的功能也在不斷地被添加和引入,讀者可以關(guān)注Apache Hadoop的官方網(wǎng)站了解最新的信息。得益于如此多廠商和開源社區(qū)的大力支持,相信在不久的將來(lái),Hadoop 也會(huì)像當(dāng)年的Linux 一樣被廣泛應(yīng)用于越來(lái)越多的領(lǐng)域,從而風(fēng)靡全球。
Hadoop技術(shù)原理總結(jié)
1、Hadoop運(yùn)行原理
Hadoop是一個(gè)開源的可運(yùn)行于大規(guī)模集群上的分布式并行編程框架,其最核心的設(shè)計(jì)包括:MapReduce和HDFS。基于 Hadoop,你可以輕松地編寫可處理海量數(shù)據(jù)的分布式并行程序,并將其運(yùn)行于由成百上千個(gè)結(jié)點(diǎn)組成的大規(guī)模計(jì)算機(jī)集群上。
基于MapReduce計(jì)算模型編寫分布式并行程序相對(duì)簡(jiǎn)單,程序員的主要工作就是設(shè)計(jì)實(shí)現(xiàn)Map和Reduce類,其它的并行編程中的種種復(fù)雜問(wèn)題,如分布式存儲(chǔ),工作調(diào)度,負(fù)載平衡,容錯(cuò)處理,網(wǎng)絡(luò)通信等,均由 MapReduce框架和HDFS文件系統(tǒng)負(fù)責(zé)處理,程序員完全不用操心。換句話說(shuō)程序員只需要關(guān)心自己的業(yè)務(wù)邏輯即可,不必關(guān)心底層的通信機(jī)制等問(wèn)題,即可編寫出復(fù)雜高效的并行程序。如果說(shuō)分布式并行編程的難度足以讓普通程序員望而生畏的話,開源的 Hadoop的出現(xiàn)極大的降低了它的門檻。
2、Mapreduce原理
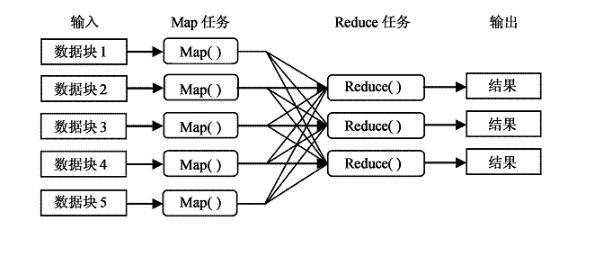
簡(jiǎn)單的說(shuō):MapReduce框架的核心步驟主要分兩部分:Map和Reduce。當(dāng)你向MapReduce框架提交一個(gè)計(jì)算作業(yè)時(shí),它會(huì)首先把計(jì)算作業(yè)拆分成若干個(gè)Map任務(wù),然后分配到不同的節(jié)點(diǎn)上去執(zhí)行,每一個(gè)Map任務(wù)處理輸入數(shù)據(jù)中的一部分,當(dāng)Map任務(wù)完成后,它會(huì)生成一些中間文件,這些中間文件將會(huì)作為Reduce任務(wù)的輸入數(shù)據(jù)。Reduce對(duì)數(shù)據(jù)做進(jìn)一步處理之后,輸出最終結(jié)果。
MapReduce是Hadoop的核心技術(shù)之一,為分布式計(jì)算的程序設(shè)計(jì)提供了良好的編程接口,并且屏蔽了底層通信原理,使得程序員只需關(guān)心業(yè)務(wù)邏輯本事,就可輕易的編寫出基于集群的分布式并行程序。從它名字上來(lái)看,大致可以看出個(gè)兩個(gè)動(dòng)詞Map和Reduce,“Map(展開)”就是將一個(gè)任務(wù)分解成為多個(gè)子任務(wù)并行的執(zhí)行,“Reduce”就是將分解后多任務(wù)處理的結(jié)果匯總起來(lái),得出最后的分析結(jié)果并輸出。
適合用 MapReduce來(lái)處理的數(shù)據(jù)集(或任務(wù))有一個(gè)基本要求:待處理的數(shù)據(jù)集可以分解成許多小的數(shù)據(jù)集,而且每一個(gè)小數(shù)據(jù)集都可以完全并行地進(jìn)行處理。
Map-Reduce的處理過(guò)程主要涉及以下四個(gè)部分:
?Client進(jìn)程:用于提交Map-reduce任務(wù)job;
?JobTracker進(jìn)程:其為一個(gè)Java進(jìn)程,其main class為JobTracker;
?TaskTracker進(jìn)程:其為一個(gè)Java進(jìn)程,其main class為TaskTracker;
?HDFS:Hadoop分布式文件系統(tǒng),用于在各個(gè)進(jìn)程間共享Job相關(guān)的文件;
其中JobTracker進(jìn)程作為主控,用于調(diào)度和管理其它的TaskTracker進(jìn)程, JobTracker可以運(yùn)行于集群中任一臺(tái)計(jì)算機(jī)上,通常情況下配置JobTracker進(jìn)程運(yùn)行在NameNode節(jié)點(diǎn)之上。TaskTracker負(fù)責(zé)執(zhí)行JobTracker進(jìn)程分配給的任務(wù),其必須運(yùn)行于 DataNode 上,即DataNode 既是數(shù)據(jù)存儲(chǔ)結(jié)點(diǎn),也是計(jì)算結(jié)點(diǎn)。 JobTracker將Map任務(wù)和Reduce任務(wù)分發(fā)給空閑的TaskTracker,讓這些任務(wù)并行運(yùn)行,并負(fù)責(zé)監(jiān)控任務(wù)的運(yùn)行情況。如果某一個(gè) TaskTracker出故障了,JobTracker會(huì)將其負(fù)責(zé)的任務(wù)轉(zhuǎn)交給另一個(gè)空閑的 TaskTracker重新運(yùn)行。
本地計(jì)算-原理
數(shù)據(jù)存儲(chǔ)在哪一臺(tái)計(jì)算機(jī)上,就由這臺(tái)計(jì)算機(jī)進(jìn)行這部分?jǐn)?shù)據(jù)的計(jì)算,這樣可以減少數(shù)據(jù)在網(wǎng)絡(luò)上的傳輸,降低對(duì)網(wǎng)絡(luò)帶寬的需求。在Hadoop這樣的基于集群的分布式并行系統(tǒng)中,計(jì)算結(jié)點(diǎn)可以很方便地?cái)U(kuò)充,而因它所能夠提供的計(jì)算能力近乎是無(wú)限的,但是由是數(shù)據(jù)需要在不同的計(jì)算機(jī)之間流動(dòng),故網(wǎng)絡(luò)帶寬變成了瓶頸,是非常寶貴的,“本地計(jì)算”是最有效的一種節(jié)約網(wǎng)絡(luò)帶寬的手段,業(yè)界把這形容為“移動(dòng)計(jì)算比移動(dòng)數(shù)據(jù)更經(jīng)濟(jì)”。
3、HDFS存儲(chǔ)的機(jī)制
Hadoop的分布式文件系統(tǒng) HDFS是建立在Linux文件系統(tǒng)之上的一個(gè)虛擬分布式文件系統(tǒng),它由一個(gè)管理節(jié)點(diǎn) ( NameNode )和N個(gè)數(shù)據(jù)節(jié)點(diǎn) ( DataNode )組成,每個(gè)節(jié)點(diǎn)均是一臺(tái)普通的計(jì)算機(jī)。在使用上同我們熟悉的單機(jī)上的文件系統(tǒng)非常類似,一樣可以建目錄,創(chuàng)建,復(fù)制,刪除文件,查看文件內(nèi)容等。但其底層實(shí)現(xiàn)上是把文件切割成 Block(塊),然后這些 Block分散地存儲(chǔ)于不同的 DataNode 上,每個(gè) Block還可以復(fù)制數(shù)份存儲(chǔ)于不同的 DataNode上,達(dá)到容錯(cuò)容災(zāi)之目的。NameNode則是整個(gè) HDFS的核心,它通過(guò)維護(hù)一些數(shù)據(jù)結(jié)構(gòu),記錄了每一個(gè)文件被切割成了多少個(gè) Block,這些 Block可以從哪些 DataNode中獲得,各個(gè) DataNode的狀態(tài)等重要信息。
HDFS的數(shù)據(jù)塊
每個(gè)磁盤都有默認(rèn)的數(shù)據(jù)塊大小,這是磁盤進(jìn)行讀寫的基本單位。構(gòu)建于單個(gè)磁盤之上的文件系統(tǒng)通過(guò)磁盤塊來(lái)管理該文件系統(tǒng)中的塊。該文件系統(tǒng)中的塊一般為磁盤塊的整數(shù)倍。磁盤塊一般為512字節(jié).HDFS也有塊的概念,默認(rèn)為64MB(一個(gè)map處理的數(shù)據(jù)大小).HDFS上的文件也被劃分為塊大小的多個(gè)分塊,與其他文件系統(tǒng)不同的是,HDFS中小于一個(gè)塊大小的文件不會(huì)占據(jù)整個(gè)塊的空間。
任務(wù)粒度——數(shù)據(jù)切片(Splits)
把原始大數(shù)據(jù)集切割成小數(shù)據(jù)集時(shí),通常讓小數(shù)據(jù)集小于或等于 HDFS中一個(gè) Block的大小(缺省是 64M),這樣能夠保證一個(gè)小數(shù)據(jù)集位于一臺(tái)計(jì)算機(jī)上,便于本地計(jì)算。有 M個(gè)小數(shù)據(jù)集待處理,就啟動(dòng) M個(gè) Map任務(wù),注意這 M個(gè) Map任務(wù)分布于 N臺(tái)計(jì)算機(jī)上并行運(yùn)行,Reduce任務(wù)的數(shù)量 R則可由用戶指定。
HDFS用塊存儲(chǔ)帶來(lái)的第一個(gè)明顯的好處一個(gè)文件的大小可以大于網(wǎng)絡(luò)中任意一個(gè)磁盤的容量,數(shù)據(jù)塊可以利用磁盤中任意一個(gè)磁盤進(jìn)行存儲(chǔ)。第二個(gè)簡(jiǎn)化了系統(tǒng)的設(shè)計(jì),將控制單元設(shè)置為塊,可簡(jiǎn)化存儲(chǔ)管理,計(jì)算單個(gè)磁盤能存儲(chǔ)多少塊就相對(duì)容易。同時(shí)也消除了對(duì)元數(shù)據(jù)的顧慮,如權(quán)限信息,可以由其他系統(tǒng)單獨(dú)管理。
4、舉一個(gè)簡(jiǎn)單的例子說(shuō)明MapReduce的運(yùn)行機(jī)制
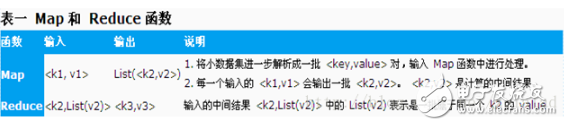
以計(jì)算一個(gè)文本文件中每個(gè)單詞出現(xiàn)的次數(shù)的程序?yàn)槔秌1,v1》可以是 《行在文件中的偏移位置,文件中的一行》,經(jīng) Map函數(shù)映射之后,形成一批中間結(jié)果 《單詞,出現(xiàn)次數(shù)》,而 Reduce函數(shù)則可以對(duì)中間結(jié)果進(jìn)行處理,將相同單詞的出現(xiàn)次數(shù)進(jìn)行累加,得到每個(gè)單詞的總的出現(xiàn)次數(shù)。
5.MapReduce的核心過(guò)程----Shuffle[‘??fl]和Sort
shuffle是mapreduce的心臟,了解了這個(gè)過(guò)程,有助于編寫效率更高的mapreduce程序和hadoop調(diào)優(yōu)。
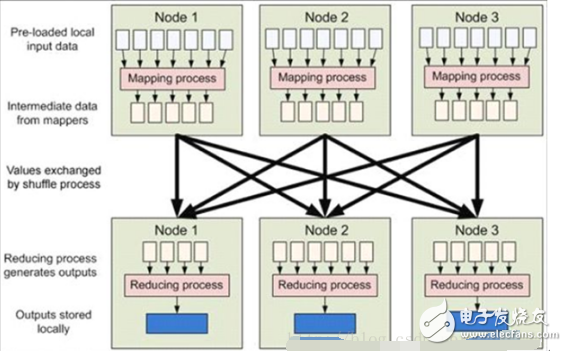
Shuffle是指從Map產(chǎn)生輸出開始,包括系統(tǒng)執(zhí)行排序以及傳送Map輸出到Reducer作為輸入的過(guò)程。如下圖所示:
首先從Map端開始分析,當(dāng)Map開始產(chǎn)生輸出的時(shí)候,他并不是簡(jiǎn)單的把數(shù)據(jù)寫到磁盤,因?yàn)轭l繁的操作會(huì)導(dǎo)致性能嚴(yán)重下降,他的處理更加復(fù)雜,數(shù)據(jù)首先是寫到內(nèi)存中的一個(gè)緩沖區(qū),并作一些預(yù)排序,以提升效率,如圖:
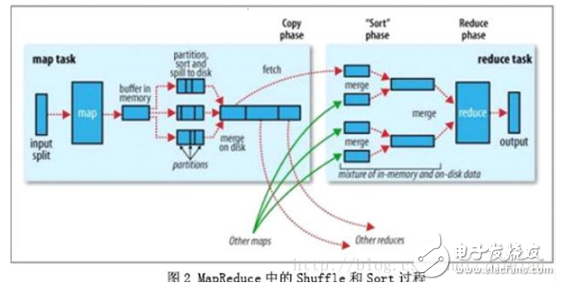
每個(gè)Map任務(wù)都有一個(gè)用來(lái)寫入“輸出數(shù)據(jù)”的“循環(huán)內(nèi)存緩沖區(qū)”,這個(gè)緩沖區(qū)默認(rèn)大小是100M(可以通過(guò)io.sort.mb屬性來(lái)設(shè)置具體的大小),當(dāng)緩沖區(qū)中的數(shù)據(jù)量達(dá)到一個(gè)特定的閥值(io.sort.mb * io.sort.spill.percent,其中io.sort.spill.percent默認(rèn)是0.80)時(shí),系統(tǒng)將會(huì)啟動(dòng)一個(gè)后臺(tái)線程把緩沖區(qū)中的內(nèi)容spill到磁盤。在spill過(guò)程中,Map的輸出將會(huì)繼續(xù)寫入到緩沖區(qū),但如果緩沖區(qū)已經(jīng)滿了,Map就會(huì)被阻塞直到spill完成。spill線程在把緩沖區(qū)的數(shù)據(jù)寫到磁盤前,會(huì)對(duì)他進(jìn)行一個(gè)二次排序,首先根據(jù)數(shù)據(jù)所屬的partition排序,然后每個(gè)partition中再按Key排序。輸出包括一個(gè)索引文件和數(shù)據(jù)文件,如果設(shè)定了Combiner,將在排序輸出的基礎(chǔ)上進(jìn)行。Combiner就是一個(gè)Mini Reducer,它在執(zhí)行Map任務(wù)的節(jié)點(diǎn)本身運(yùn)行,先對(duì)Map的輸出作一次簡(jiǎn)單的Reduce,使得Map的輸出更緊湊,更少的數(shù)據(jù)會(huì)被寫入磁盤和傳送到Reducer。Spill文件保存在由mapred.local.dir指定的目錄中,Map任務(wù)結(jié)束后刪除。
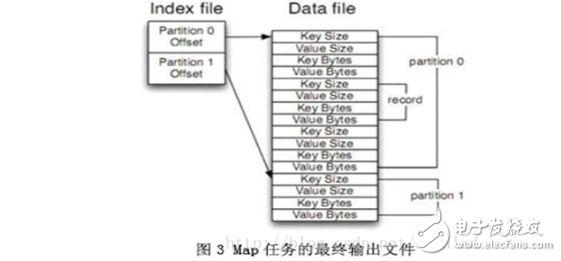
每當(dāng)內(nèi)存中的數(shù)據(jù)達(dá)到spill閥值的時(shí)候,都會(huì)產(chǎn)生一個(gè)新的spill文件,所以在Map任務(wù)寫完他的最后一個(gè)輸出記錄的時(shí)候,可能會(huì)有多個(gè)spill文件,在Map任務(wù)完成前,所有的spill文件將會(huì)被歸并排序?yàn)橐粋€(gè)索引文件和數(shù)據(jù)文件。如圖3所示。這是一個(gè)多路歸并過(guò)程,最大歸并路數(shù)由io.sort.factor控制(默認(rèn)是10)。如果設(shè)定了Combiner,并且spill文件的數(shù)量至少是3(由min.num.spills.for.combine屬性控制),那么Combiner將在輸出文件被寫入磁盤前運(yùn)行以壓縮數(shù)據(jù)。
對(duì)寫入到磁盤的數(shù)據(jù)進(jìn)行壓縮(這種壓縮同Combiner的壓縮不一樣)通常是一個(gè)很好的方法,因?yàn)檫@樣做使得數(shù)據(jù)寫入磁盤的速度更快,節(jié)省磁盤空間,并減少需要傳送到Reducer的數(shù)據(jù)量。默認(rèn)輸出是不被壓縮的,但可以很簡(jiǎn)單的設(shè)置mapred.compress.map.output為true啟用該功能。壓縮所使用的庫(kù)由mapred.map.output.compression.codec來(lái)設(shè)定。
當(dāng)spill 文件歸并完畢后,Map 將刪除所有的臨時(shí)spill文件,并告知TaskTracker任務(wù)已完成。Reducers通過(guò)HTTP來(lái)獲取對(duì)應(yīng)的數(shù)據(jù)。用來(lái)傳輸partitions數(shù)據(jù)的工作線程個(gè)數(shù)由tasktracker.http.threads控制,這個(gè)設(shè)定是針對(duì)每一個(gè)TaskTracker的,并不是單個(gè)Map,默認(rèn)值為40,在運(yùn)行大作業(yè)的大集群上可以增大以提升數(shù)據(jù)傳輸速率。
現(xiàn)在讓我們轉(zhuǎn)到Shuffle的Reduce部分。Map的輸出文件放置在運(yùn)行Map任務(wù)的TaskTracker的本地磁盤上(注意:Map輸出總是寫到本地磁盤,但是Reduce輸出不是,一般是寫到HDFS),它是運(yùn)行Reduce任務(wù)的TaskTracker所需要的輸入數(shù)據(jù)。Reduce任務(wù)的輸入數(shù)據(jù)分布在集群內(nèi)的多個(gè)Map任務(wù)的輸出中,Map任務(wù)可能會(huì)在不同的時(shí)間內(nèi)完成,只要有其中一個(gè)Map任務(wù)完成,Reduce任務(wù)就開始拷貝他的輸出。這個(gè)階段稱為拷貝階段,Reduce任務(wù)擁有多個(gè)拷貝線程,可以并行的獲取Map輸出。可以通過(guò)設(shè)定mapred.reduce.parallel.copies來(lái)改變線程數(shù)。
Reduce是怎么知道從哪些TaskTrackers中獲取Map的輸出呢?當(dāng)Map任務(wù)完成之后,會(huì)通知他們的父TaskTracker,告知狀態(tài)更新,然后TaskTracker再轉(zhuǎn)告JobTracker,這些通知信息是通過(guò)心跳通信機(jī)制傳輸?shù)模虼酸槍?duì)以一個(gè)特定的作業(yè),jobtracker知道Map輸出與tasktrackers的映射關(guān)系。Reducer中有一個(gè)線程會(huì)間歇的向JobTracker詢問(wèn)Map輸出的地址,直到把所有的數(shù)據(jù)都取到。在Reducer取走了Map輸出之后,TaskTracker不會(huì)立即刪除這些數(shù)據(jù),因?yàn)镽educer可能會(huì)失敗,他們會(huì)在整個(gè)作業(yè)完成之后,JobTracker告知他們要?jiǎng)h除的時(shí)候才去刪除。
如果Map輸出足夠小,他們會(huì)被拷貝到Reduce TaskTracker的內(nèi)存中(緩沖區(qū)的大小由mapred.job.shuffle.input.buffer.percnet控制),或者達(dá)到了Map輸出的閥值的大小(由mapred.inmem.merge.threshold控制),緩沖區(qū)中的數(shù)據(jù)將會(huì)被歸并然后spill到磁盤。
拷貝來(lái)的數(shù)據(jù)疊加在磁盤上,有一個(gè)后臺(tái)線程會(huì)將它們歸并為更大的排序文件,這樣做節(jié)省了后期歸并的時(shí)間。對(duì)于經(jīng)過(guò)壓縮的Map輸出,系統(tǒng)會(huì)自動(dòng)把它們解壓到內(nèi)存方便對(duì)其執(zhí)行歸并。
當(dāng)所有的Map 輸出都被拷貝后,Reduce 任務(wù)進(jìn)入排序階段(更恰當(dāng)?shù)恼f(shuō)應(yīng)該是歸并階段,因?yàn)榕判蛟贛ap端就已經(jīng)完成),這個(gè)階段會(huì)對(duì)所有的Map輸出進(jìn)行歸并排序,這個(gè)工作會(huì)重復(fù)多次才能完成。
假設(shè)這里有50 個(gè)Map 輸出(可能有保存在內(nèi)存中的),并且歸并因子是10(由io.sort.factor控制,就像Map端的merge一樣),那最終需要5次歸并。每次歸并會(huì)把10個(gè)文件歸并為一個(gè),最終生成5個(gè)中間文件。在這一步之后,系統(tǒng)不再把5個(gè)中間文件歸并成一個(gè),而是排序后直接“喂”給Reduce函數(shù),省去向磁盤寫數(shù)據(jù)這一步。最終歸并的數(shù)據(jù)可以是混合數(shù)據(jù),既有內(nèi)存上的也有磁盤上的。由于歸并的目的是歸并最少的文件數(shù)目,使得在最后一次歸并時(shí)總文件個(gè)數(shù)達(dá)到歸并因子的數(shù)目,所以每次操作所涉及的文件個(gè)數(shù)在實(shí)際中會(huì)更微妙些。譬如,如果有40個(gè)文件,并不是每次都?xì)w并10個(gè)最終得到4個(gè)文件,相反第一次只歸并4個(gè)文件,然后再實(shí)現(xiàn)三次歸并,每次10個(gè),最終得到4個(gè)歸并好的文件和6個(gè)未歸并的文件。要注意,這種做法并沒(méi)有改變歸并的次數(shù),只是最小化寫入磁盤的數(shù)據(jù)優(yōu)化措施,因?yàn)樽詈笠淮螝w并的數(shù)據(jù)總是直接送到Reduce函數(shù)那里。在Reduce階段,Reduce函數(shù)會(huì)作用在排序輸出的每一個(gè)key上。這個(gè)階段的輸出被直接寫到輸出文件系統(tǒng),一般是HDFS。在HDFS中,因?yàn)門askTracker節(jié)點(diǎn)也運(yùn)行著一個(gè)DataNode進(jìn)程,所以第一個(gè)塊備份會(huì)直接寫到本地磁盤。到此,MapReduce的Shuffle和Sort分析完畢。
6、Hadoop中Combiner的作用?
6.1 Partition
把 Map任務(wù)輸出的中間結(jié)果按 key的范圍劃分成 R份( R是預(yù)先定義的 Reduce任務(wù)的個(gè)數(shù)),劃分時(shí)通常使用hash函數(shù)如: hash(key) mod R,這樣可以保證某一段范圍內(nèi)的 key,一定是將會(huì)由一個(gè)Reduce任務(wù)來(lái)處理,這樣可以簡(jiǎn)化 Reduce獲取計(jì)算數(shù)據(jù)的過(guò)程。
6.2 Combine操作
在 partition之前,還可以對(duì)中間結(jié)果先做 combine,即將中間結(jié)果中有相同 key的 《key, value》對(duì)合并成一對(duì)。combine的過(guò)程與Reduce的過(guò)程類似,很多情況下就可以直接使用 Reduce函數(shù),但 combine是作為 Map任務(wù)的一部分,在執(zhí)行完 Map函數(shù)后緊接著執(zhí)行的,而Reduce必須在所有的Map操作完成后才能進(jìn)行。Combine能夠減少中間結(jié)果中 《key, value》對(duì)的數(shù)目,從而減少網(wǎng)絡(luò)流量。
6.3 Reduce任務(wù)從 Map任務(wù)結(jié)點(diǎn)取中間結(jié)果
Map 任務(wù)的中間結(jié)果在做完 Combine和 Partition之后,以文件形式存于本地磁盤。中間結(jié)果文件的位置會(huì)通知主控JobTracker,JobTracker再通知 Reduce任務(wù)到哪一個(gè) DataNode上去取中間結(jié)果。注意所有的 Map任務(wù)產(chǎn)生中間結(jié)果均按其 Key用同一個(gè)Hash函數(shù)劃分成了 R份,R個(gè) Reduce任務(wù)各自負(fù)責(zé)一段 Key區(qū)間。每個(gè) Reduce需要向許多個(gè)原Map任務(wù)結(jié)點(diǎn)以取得落在其負(fù)責(zé)的Key區(qū)間內(nèi)的中間結(jié)果,然后執(zhí)行 Reduce函數(shù),形成一個(gè)最終的結(jié)果文件。
6.4 任務(wù)管道
有R個(gè) Reduce任務(wù),就會(huì)有 R個(gè)最終結(jié)果,很多情況下這 R個(gè)最終結(jié)果并不需要合并成一個(gè)最終結(jié)果。因?yàn)檫@ R個(gè)最終結(jié)果又可以做為另一個(gè)計(jì)算任務(wù)的輸入,開始另一個(gè)并行計(jì)算任務(wù)。
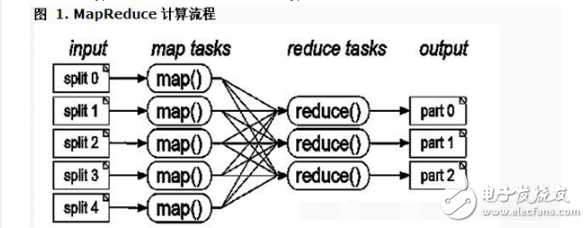
這個(gè) MapReduce的計(jì)算過(guò)程簡(jiǎn)而言之,就是將大數(shù)據(jù)集分解為成百上千的小數(shù)據(jù)集,每個(gè)(或若干個(gè))數(shù)據(jù)集分別由集群中的一個(gè)結(jié)點(diǎn)(一般就是一臺(tái)普通的計(jì)算機(jī))進(jìn)行處理并生成中間結(jié)果,然后這些中間結(jié)果又由大量的結(jié)點(diǎn)進(jìn)行合并,形成最終結(jié)果。
計(jì)算模型的核心是 Map 和 Reduce 兩個(gè)函數(shù),這兩個(gè)函數(shù)由用戶負(fù)責(zé)實(shí)現(xiàn),功能是按一定的映射規(guī)則將輸入的 《key, value》對(duì)轉(zhuǎn)換成另一個(gè)或一批 《key, value》對(duì)輸出。
6.5、總結(jié)
(1)、combiner使用的合適,可以在滿足業(yè)務(wù)的情況下提升job的速度,如果不合適,則將導(dǎo)致輸出的結(jié)果不正確,但是不是所有的場(chǎng)合都適合combiner。根據(jù)自己的業(yè)務(wù)來(lái)使用。hadoop就是map和 reduce的過(guò)程。服務(wù)器上一個(gè)目錄節(jié)點(diǎn)+多個(gè)數(shù)據(jù)節(jié)點(diǎn)。將程序傳送到各個(gè)節(jié)點(diǎn),在數(shù)據(jù)節(jié)點(diǎn)上進(jìn)行計(jì)算
(2)、將數(shù)據(jù)存儲(chǔ)到不同節(jié)點(diǎn),用map方式對(duì)應(yīng)管理,在各個(gè)節(jié)點(diǎn)進(jìn)行計(jì)算,采用reduce進(jìn)行合并結(jié)果集
(3)、就是通過(guò)java程序和目錄節(jié)點(diǎn)配合,將數(shù)據(jù)存放到不同數(shù)據(jù)節(jié)點(diǎn)上
(4)、看上邊的2.注意,分布式注重的是計(jì)算,不是每個(gè)場(chǎng)景都適合
(5)、將文件存放到不同的數(shù)據(jù)節(jié)點(diǎn),然后每個(gè)節(jié)點(diǎn)計(jì)算出前十個(gè)進(jìn)行reduce的計(jì)算。













 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論