 電子發燒友App
電子發燒友App


?一、hadoop是什么?
(1)Hadoop是一個開發和運行處理大規模數據的軟件平臺,可編寫和運行分布式應用處理大規模數據,是Appach的一個用java語言實現開源軟件框架,實現在大量計算機組成的集群中對海量數據進行分布式計算(或專為離線和大規模數據分析而設計的)并不適合那種對幾個記錄隨機讀寫的在線事務處理模式。
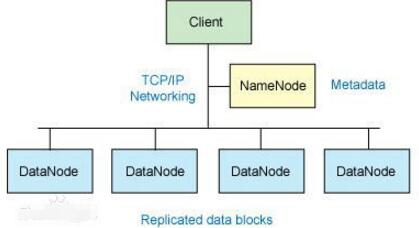
Hadoop=HDFS(文件系統,數據存儲技術相關)+ Mapreduce(數據處理),Hadoop的數據來源可以是任何形式,在處理半結構化和非結構化數據上與關系型數據庫相比有更好的性能,具有更靈活的處理能力,不管任何數據形式最終會轉化為key/value,key/value是基本數據單元。用函數式變成Mapreduce代替SQL,SQL是查詢語句,而Mapreduce則是使用腳本和代碼,而對于適用于關系型數據庫,習慣SQL的Hadoop有開源工具hive代替。
(2)Hadoop就是一個分布式計算的解決方案。
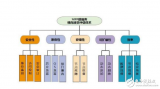
Hadoop框架中最核心設計就是:HDFS和MapReduce.HDFS提供了海量數據的存儲,MapReduce提供了對數據的計算。
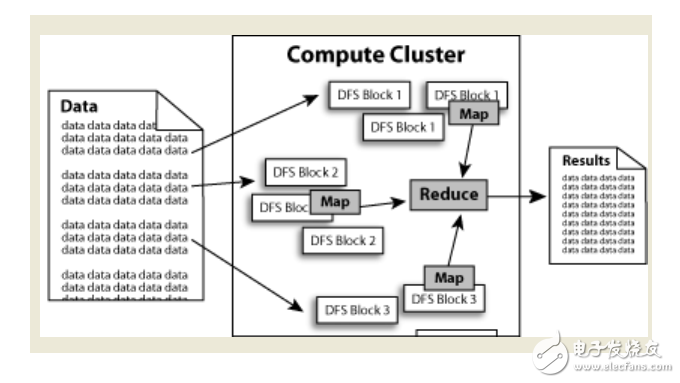
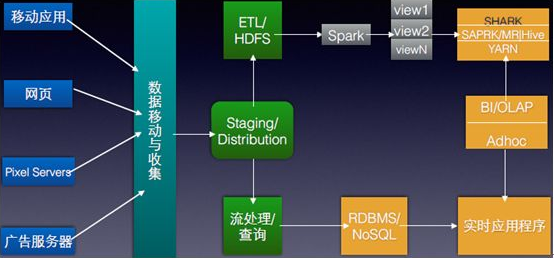
數據在Hadoop中處理的流程可以簡單的按照下圖來理解:數據通過Haddop的集群處理后得到結果。
?
優點
Hadoop是一個能夠對大量數據進行分布式處理的軟件框架。 Hadoop 以一種可靠、高效、可伸縮的方式進行數據處理。
Hadoop 是可靠的,因為它假設計算元素和存儲會失敗,因此它維護多個工作數據副本,確保能夠針對失敗的節點重新分布處理。
Hadoop 是高效的,因為它以并行的方式工作,通過并行處理加快處理速度。
Hadoop 還是可伸縮的,能夠處理 PB 級數據。
此外,Hadoop 依賴于社區服務,因此它的成本比較低,任何人都可以使用。
Hadoop是一個能夠讓用戶輕松架構和使用的分布式計算平臺。用戶可以輕松地在Hadoop上開發和運行處理海量數據的應用程序。它主要有以下幾個優點:
高可靠性。Hadoop按位存儲和處理數據的能力值得人們信賴。
高擴展性。Hadoop是在可用的計算機集簇間分配數據并完成計算任務的,這些集簇可以方便地擴展到數以千計的節點中。.
高效性。Hadoop能夠在節點之間動態地移動數據,并保證各個節點的動態平衡,因此處理速度非常快。
高容錯性。Hadoop能夠自動保存數據的多個副本,并且能夠自動將失敗的任務重新分配。
低成本。與一體機、商用數據倉庫以及QlikView、Yonghong Z-Suite等數據集市相比,hadoop是開源的,項目的軟件成本因此會大大降低。
Hadoop帶有用Java語言編寫的框架,因此運行在 Linux 生產平臺上是非常理想的。Hadoop 上的應用程序也可以使用其他語言編寫,比如 C++。
?
hadoop大數據處理的意義
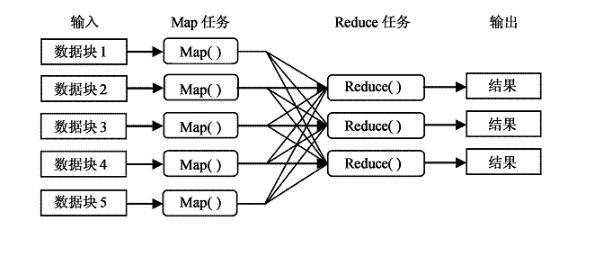
Hadoop得以在大數據處理應用中廣泛應用得益于其自身在數據提取、變形和加載(ETL)方面上的天然優勢。Hadoop的分布式架構,將大數據處理引擎盡可能的靠近存儲,對例如像ETL這樣的批處理操作相對合適,因為類似這樣操作的批處理結果可以直接走向存儲。Hadoop的MapReduce功能實現了將單個任務打碎,并將碎片任務(Map)發送到多個節點上,之后再以單個數據集的形式加載(Reduce)到數據倉庫。
hadoop能做什么?
hadoop擅長日志分析,facebook就用Hive來進行日志分析,2009年時facebook就有非編程人員的30%的人使用HiveQL進行數據分析;淘寶搜索中的 自定義篩選也使用的Hive;利用Pig還可以做高級的數據處理,包括Twitter、LinkedIn 上用于發現您可能認識的人,可以實現類似Amazon.com的協同過濾的推薦效果。淘寶的商品推薦也是!在Yahoo!的40%的Hadoop作業是用pig運行的,包括垃圾郵件的識別和過濾,還有用戶特征建模。(2012年8月25新更新,天貓的推薦系統是hive,少量嘗試mahout!)
下面舉例說明:
設想一下這樣的應用場景。 我有一個100M 的數據庫備份的sql 文件。我現在想在不導入到數據庫的情況下直接用grep操作通過正則過濾出我想要的內容。例如:某個表中 含有相同關鍵字的記錄那么有幾種方式,一種是直接用linux的命令 grep 還有一種就是通過編程來讀取文件,然后對每行數據進行正則匹配得到結果好了 現在是100M 的數據庫備份。上述兩種方法都可以輕松應對。
那么如果是1G , 1T 甚至 1PB 的數據呢 ,上面2種方法還能行得通嗎? 答案是不能。畢竟單臺服務器的性能總有其上限。那么對于這種 超大數據文件怎么得到我們想要的結果呢?
有種方法 就是分布式計算, 分布式計算的核心就在于 利用分布式算法 把運行在單臺機器上的程序擴展到多臺機器上并行運行。從而使數據處理能力成倍增加。但是這種分布式計算一般對編程人員要求很高,而且對服務器也有要求。導致了成本變得非常高。
Haddop 就是為了解決這個問題誕生的.Haddop 可以很輕易的把 很多linux的廉價pc 組成 分布式結點,然后編程人員也不需要知道分布式算法之類,只需要根據mapreduce的規則定義好接口方法,剩下的就交給Haddop. 它會自動把相關的計算分布到各個結點上去,然后得出結果。
例如上述的例子 : Hadoop 要做的事 首先把 1PB的數據文件導入到 HDFS中, 然后編程人員定義好 map和reduce, 也就是把文件的行定義為key,每行的內容定義為value , 然后進行正則匹配,匹配成功則把結果 通過reduce聚合起來返回.Hadoop 就會把這個程序分布到N 個結點去并行的操作。
那么原本可能需要計算好幾天,在有了足夠多的結點之后就可以把時間縮小到幾小時之內。
這也就是所謂的 大數據 云計算了。如果還是不懂的話再舉個簡單的例子
比如 1億個 1 相加 得出計算結果, 我們很輕易知道結果是 1億。但是計算機不知道。那么單臺計算機處理的方式做一個一億次的循環每次結果+1
那么分布式的處理方式則變成 我用 1萬臺 計算機,每個計算機只需要計算 1萬個 1 相加 然后再有一臺計算機把 1萬臺計算機得到的結果再相加從而得到最后的結果。
理論上講, 計算速度就提高了 1萬倍。 當然上面可能是一個不恰當的例子。但所謂分布式,大數據,云計算 大抵也就是這么回事了。
?
hadoop是什么語言開發的
(1)Hadoop的創始人是Doug Cutting, 同時也是著名的基于Java的檢索引擎庫Apache Lucene的創始人。Hadoop本來是用于著名的開源搜索引擎Apache Nutch,而Nutch本身是基于Lucene的,而且也是Lucene的一個子項目。因此Hadoop基于Java就很理所當然了。
(2)用其他語言開發的Hadoop應用大多數是使用Hadoop-Streaming來和框架對接的。 因為Streaming會fork一個java進程來讀寫Python/Perl/C++的stdin/stdout,開銷會大一些。較大的任務、長期運行的任務,推薦使用Java。
?


















 工商網監
工商網監
評論