 電子發(fā)燒友App
電子發(fā)燒友App


前言
? ? ? 本文主要介紹 Cassandra 中數(shù)據(jù)的存儲格式,包括在內(nèi)存中的數(shù)據(jù)和磁盤中數(shù)據(jù)。Cassandra 的寫的性能表現(xiàn)非常好,為什么寫的性能這么好?和它的數(shù)據(jù)結(jié)構(gòu)有沒有關(guān)系,以及和它的寫的機制又有多大的關(guān)系。同時也將分析哪些因素會影響讀的性能 Cassandra 又做了哪些改進。
Cassandra 的數(shù)據(jù)存儲結(jié)構(gòu)主要分為三種:
1、CommitLog:主要記錄下客戶端提交過來的數(shù)據(jù)以及操作。這個數(shù)據(jù)將被持久化到磁盤中,以便數(shù)據(jù)沒有被持久化到磁盤時可以用來恢復(fù)。
2、Memtable:用戶寫的數(shù)據(jù)在內(nèi)存中的形式,它的對象結(jié)構(gòu)在后面詳細(xì)介紹。其實還有另外一種形式是 BinaryMemtable 這個格式目前 Cassandra 并沒有使用,這里不再介紹了。
3、SSTable:數(shù)據(jù)被持久化到磁盤,這又分為 Data、Index 和 Filter 三種數(shù)據(jù)格式。
CommitLog 數(shù)據(jù)格式
CommitLog 的數(shù)據(jù)只有一種,那就是按照一定格式組成 byte 組數(shù),寫到 IO 緩沖區(qū)中定時的被刷到磁盤中持久化,在上一篇的配置文件詳解中已經(jīng)有說到 CommitLog 的持久化方式有兩種,一個是 Periodic 一個是 Batch,它們的數(shù)據(jù)格式都是一樣的,只是前者是異步的,后者是同步的,數(shù)據(jù)被刷到磁盤的頻繁度不一樣。關(guān)于 CommitLog 的相關(guān)的類結(jié)構(gòu)圖如下:
圖 1. CommitLog 的相關(guān)的類結(jié)構(gòu)圖
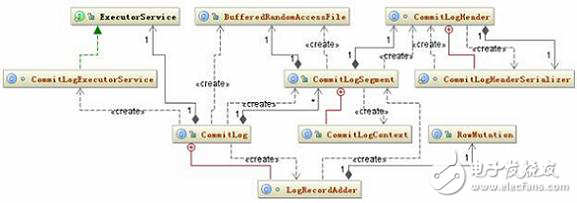
它持久化的策略也很簡單,就是首先將用戶提交的數(shù)據(jù)所在的對象 RowMutation 序列化成 byte 數(shù)組,然后把這個對象和 byte 數(shù)組傳給 LogRecordAdder 對象,由 LogRecordAdder 對象調(diào)用 CommitLogSegment 的 write 方法去完成寫操作,這個 write 方法的代碼如下:
清單 1. CommitLogSegment. write
public CommitLogSegment.CommitLogContext write(RowMutation rowMutation,
Object serializedRow){
long currentPosition = -1L;
...
Checksum checkum = new CRC32();
if (serializedRow instanceof DataOutputBuffer){
DataOutputBuffer buffer = (DataOutputBuffer) serializedRow;
logWriter.writeLong(buffer.getLength());
logWriter.write(buffer.getData(), 0, buffer.getLength());
checkum.update(buffer.getData(), 0, buffer.getLength());
}
else{
assert serializedRow instanceof byte[];
byte[] bytes = (byte[]) serializedRow;
logWriter.writeLong(bytes.length);
logWriter.write(bytes);
checkum.update(bytes, 0, bytes.length);
}
logWriter.writeLong(checkum.getValue());
...
}
這個代碼的主要作用就是如果當(dāng)前這個根據(jù) columnFamily 的 id 還沒有被序列化過,將會根據(jù)這個 id 生成一個 CommitLogHeader 對象,記錄下在當(dāng)前的 CommitLog 文件中的位置,并將這個 header 序列化,覆蓋以前的 header。這個 header 中可能包含多個沒有被序列化到磁盤中的 RowMutation 對應(yīng)的 columnFamily 的 id。如果已經(jīng)存在,直接把 RowMutation 對象的序列化結(jié)果寫到 CommitLog 的文件緩存區(qū)中后面再加一個 CRC32 校驗碼。Byte 數(shù)組的格式如下:
圖 2. CommitLog 文件數(shù)組結(jié)構(gòu)

上圖中每個不同的 columnFamily 的 id 都包含在 header 中,這樣做的目的是更容易的判斷那些數(shù)據(jù)沒有被序列化。
CommitLog 的作用是為恢復(fù)沒有被寫到磁盤中的數(shù)據(jù),那如何根據(jù) CommitLog 文件中存儲的數(shù)據(jù)恢復(fù)呢?這段代碼在 recover 方法中:
清單 2. CommitLog.recover
public static void recover(File[] clogs) throws IOException{
...
final CommitLogHeader clHeader = CommitLogHeader.readCommitLogHeader(reader);
int lowPos = CommitLogHeader.getLowestPosition(clHeader);
if (lowPos == 0) break;
reader.seek(lowPos);
while (!reader.isEOF()){
try{
bytes = new byte[(int) reader.readLong()];
reader.readFully(bytes);
claimedCRC32 = reader.readLong();
}
...
ByteArrayInputStream bufIn = new ByteArrayInputStream(bytes);
Checksum checksum = new CRC32();
checksum.update(bytes, 0, bytes.length);
if (claimedCRC32 != checksum.getValue()){continue;}
final RowMutation rm =
RowMutation.serializer().deserialize(new DataInputStream(bufIn));
}
...
}
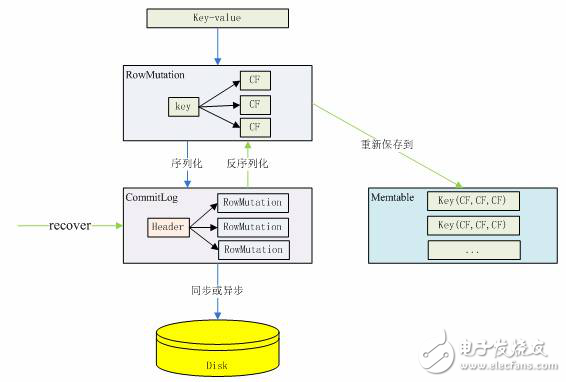
這段代碼的思路是:反序列化 CommitLog 文件的 header 為 CommitLogHeader 對象,尋找 header 對象中沒有被回寫的最小 RowMutation 位置,然后根據(jù)這個位置取出這個 RowMutation 對象的序列化數(shù)據(jù),然后反序列化為 RowMutation 對象,然后取出 RowMutation 對象中的數(shù)據(jù)重新保存到 Memtable 中,而不是直接寫到磁盤中。CommitLog 的操作過程可以用下圖來清楚的表示:
圖 3. CommitLog 數(shù)據(jù)格式的變化過程
Memtable 內(nèi)存中數(shù)據(jù)結(jié)構(gòu)
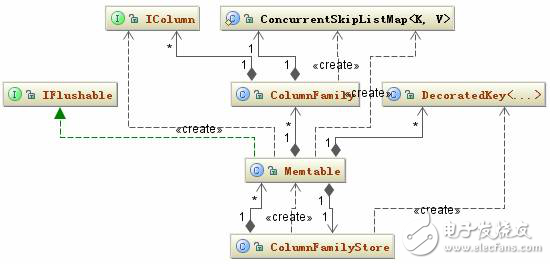
Memtable 內(nèi)存中數(shù)據(jù)結(jié)構(gòu)比較簡單,一個 ColumnFamily 對應(yīng)一個唯一的 Memtable 對象,所以 Memtable 主要就是維護一個 ConcurrentSkipListMap《decoratedkey, columnfamily=“” style=“box-sizing: border-box;”》 類型的數(shù)據(jù)結(jié)構(gòu),當(dāng)一個新的 RowMutation 對象加進來時,Memtable 只要看看這個結(jié)構(gòu)是否 《decoratedkey, columnfamily=“” style=“box-sizing: border-box;”》集合已經(jīng)存在,沒有的話就加進來,有的話取出這個 Key 對應(yīng)的 ColumnFamily,再把它們的 Column 合并。Memtable 相關(guān)的類結(jié)構(gòu)圖如下:
圖 4. Memtable 相關(guān)的類結(jié)構(gòu)圖
Memtable 中的數(shù)據(jù)會根據(jù)配置文件中的相應(yīng)配置參數(shù)刷到本地磁盤中。這些參數(shù)在上一篇中已經(jīng)做了詳細(xì)說明。
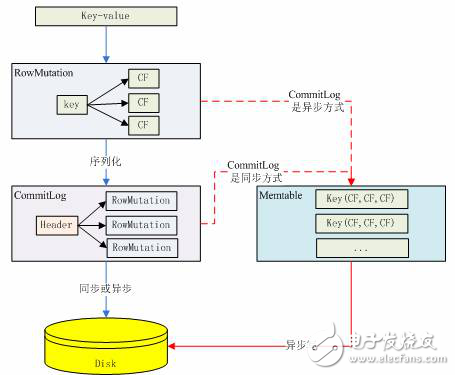
前面已經(jīng)多處提到了 Cassandra 的寫的性能很好,好的原因就是因為 Cassandra 寫到數(shù)據(jù)首先被寫到 Memtable 中,而 Memtable 是內(nèi)存中的數(shù)據(jù)結(jié)構(gòu),所以 Cassandra 的寫是寫內(nèi)存的,下圖基本上描述了一個 key/value 數(shù)據(jù)是怎么樣寫到 Cassandra 中的 Memtable 數(shù)據(jù)結(jié)構(gòu)中的。
圖 5. 數(shù)據(jù)被寫到 Memtable
SSTable 數(shù)據(jù)格式
每添加一條數(shù)據(jù)到 Memtable 中,程序都會檢查一下這個 Memtable 是否已經(jīng)滿足被寫到磁盤的條件,如果條件滿足這個 Memtable 就會寫到磁盤中。先看一下這個過程涉及到的類。相關(guān)類圖如圖 6 所示:
圖 6. SSTable 持久化類結(jié)構(gòu)圖
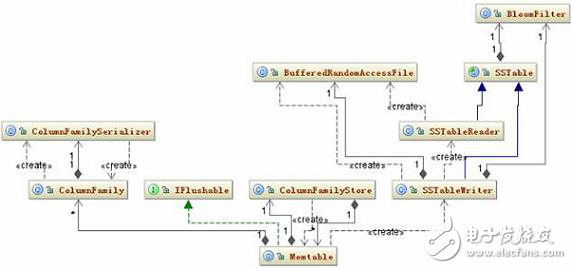
Memtable 的條件滿足后,它會創(chuàng)建一個 SSTableWriter 對象,然后取出 Memtable 中所有的 《decoratedkey, columnfamily=“” style=“box-sizing: border-box;”》集合,將 ColumnFamily 對象的序列化結(jié)構(gòu)寫到 DataOutputBuffer 中。接下去 SSTableWriter 根據(jù) DecoratedKey 和 DataOutputBuffer 分別寫到 Date、Index 和 Filter 三個文件中。
Data 文件格式如下:
圖 7. SSTable 的 Data 文件結(jié)構(gòu)

Data 文件就是按照上述 byte 數(shù)組來組織文件的,數(shù)據(jù)被寫到 Data 文件中是接著就會往 Index 文件中寫,Index 中到底寫什么數(shù)據(jù)呢?
其實 Index 文件就是記錄下所有 Key 和這個 Key 對應(yīng)在 Data 文件中的啟示地址,如圖 8 所示:
圖 8. Index 文件結(jié)構(gòu)

?
Index 文件實際上就是 Key 的一個索引文件,目前只對 Key 做索引,對 super column 和 column 都沒有建索引,所以要匹配 column 相對來說要比 Key 更慢。
Index 文件寫完后接著寫 Filter 文件,F(xiàn)ilter 文件存的內(nèi)容就是 BloomFilter 對象的序列化結(jié)果。它的文件結(jié)構(gòu)如圖 9 所示:
圖 9. Filter 文件結(jié)構(gòu)

BloomFilter 對象實際上對應(yīng)一個 Hash 算法,這個算法能夠快速的判斷給定的某個 Key 在不在當(dāng)前這個 SSTable 中,而且每個 SSTable 對應(yīng)的 BloomFilter 對象都在內(nèi)存中,F(xiàn)ilter 文件指示 BloomFilter 持久化的一個副本。三個文件對應(yīng)的數(shù)據(jù)格式可以用下圖來清楚的表示:
圖 10. SSTable 數(shù)據(jù)格式轉(zhuǎn)化
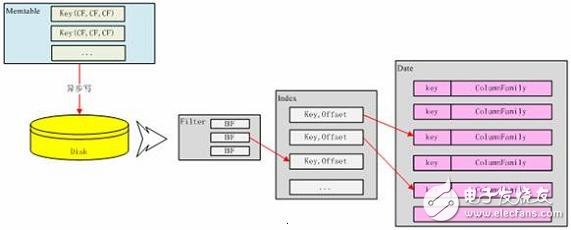
這個三個文件寫完后,還要做的一件事件就是更新前面提到的 CommitLog 文件,告訴 CommitLog 的 header 所存的當(dāng)前 ColumnFamily 的沒有寫到磁盤的最小位置。
在 Memtable 往磁盤中寫的過程中,這個 Memtable 被放到 memtablesPendingFlush 容器中,以保證在讀時候它里面存的數(shù)據(jù)能被正確讀到,這個在后面數(shù)據(jù)讀取時還會介紹。
數(shù)據(jù)的寫入
數(shù)據(jù)要寫到 Cassandra 中有兩個步驟:
1.找到應(yīng)該保存這個數(shù)據(jù)的節(jié)點
2.往這個節(jié)點寫數(shù)據(jù)。客戶端寫一條數(shù)據(jù)必須指定 Keyspace、ColumnFamily、Key、Column Name 和 Value,還可以指定 Timestamp,以及數(shù)據(jù)的安全等級。
數(shù)據(jù)寫入涉及的主要相關(guān)類如下圖所示:
圖 11. Insert 相關(guān)類圖
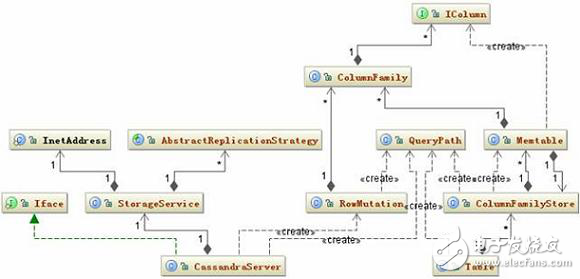
大慨的寫入邏輯是這樣的:
CassandraServer 接收到要寫入的數(shù)據(jù)時,首先創(chuàng)建一個 RowMutation 對象,再創(chuàng)建一個 QueryPath 對象,這個對象中保存了 ColumnFamily、Column Name 或者 Super Column Name。接著把用戶提交的所有數(shù)據(jù)保存在 RowMutation 對象的 Map《string, columnfamily=“” style=“box-sizing: border-box;”》 結(jié)構(gòu)中。接下去就是根據(jù)提交的 Key 計算集群中那個節(jié)點應(yīng)該保存這條數(shù)據(jù)。這個計算的規(guī)則是:將 Key 轉(zhuǎn)化成 Token,然后在整個集群的 Token 環(huán)中根據(jù)二分查找算法找到與給定的 Token 最接近的一個節(jié)點。如果用戶指定了數(shù)據(jù)要保存多個備份,那么將會順序在 Token 環(huán)中返回與備份數(shù)相等的節(jié)點。這是一個基本的節(jié)點列表,后面 Cassandra 會判斷這些節(jié)點是否正常工作,如果不正常尋找替換節(jié)點。還有還要檢查是否有節(jié)點正在啟動,這種節(jié)點也是要在考慮的范圍內(nèi),最終會形成一個目標(biāo)節(jié)點列表。最 后把數(shù)據(jù)發(fā)送到這些節(jié)點。
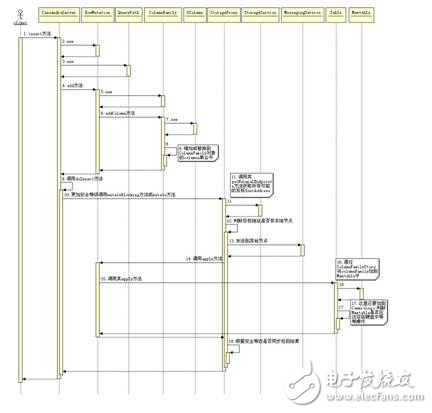
接下去就是將數(shù)據(jù)保存到 Memtable 中和 CommitLog 中,關(guān)于結(jié)果的返回根據(jù)用戶指定的安全等級不同,可以是異步的,也可以是同步的。如果某個節(jié)點返回失敗,將會再次發(fā)送數(shù)據(jù)。下圖是當(dāng) Cassandra 接收到一條數(shù)據(jù)時到將數(shù)據(jù)寫到 Memtable 中的時序圖。
圖 12. Insert 操作的時序圖












 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論