 電子發燒友App
電子發燒友App


永遠使用SSL
毫無例外,永遠都要使用SSL。你的應用不知道要被誰,以及什么情況訪問。有些是安全的,有些不是。使用SSL可以減少鑒權的成本:你只需要一個簡單的令牌(token)就可以鑒權了,而不是每次讓用戶對每次請求簽名。
值得注意的是:不要讓非SSL的url訪問重定向到SSL的url。
文檔
文檔和API本身一樣重要。文檔應該容易找到,并且公開(把它們藏到pdf里面或者存到需要登錄的地方都不太好)。文檔應該有展示請求和輸出的例子:或者以點擊鏈接的方式或者通過curl的方式(請見openstack的文檔)。如果有更新(特別是公開的API),應該及時更新文檔。文檔中應該有關于何時棄用某個API的時間表以及詳情。使用郵件列表或者博客記錄是好方法。
版本化
在API上加入版本信息可以有效的防止用戶訪問已經更新了的API,同時也能讓不同主要版本之間平穩過渡。關于是否將版本信息放入url還是放入請求頭有過爭論:API version should be included in the URL or in a header. 學術界說它應該放到header里面去,但是如果放到url里面我們就可以跨版本的訪問資源了。。(參考openstack)。
strip使用的方法就很好:它的url里面有主版本信息,同時請求頭倆面有子版本信息。這樣在子版本變化過程中url的穩定的。變化有時是不可避免的,關鍵是如何管理變化。完整的文檔和合理的時間表都會使得API使用者使用的更加輕松。
結果過濾,排序,搜索:
url最好越簡短越好,和結果過濾,排序,搜索相關的功能都應該通過參數實現(并且也很容易實現)。
過濾:為所有提供過濾功能的接口提供統一的參數。例如:你想限制get /tickets 的返回結果:只返回那些open狀態的ticket–get /tickektsstate=open這里的state就是過濾參數。
排序:和過濾一樣,一個好的排序參數應該能夠描述排序規則,而不業務相關。復雜的排序規則應該通過組合實現:
GET /ticketssort=-priority- Retrieves a list of tickets in descending order of priority
GET /ticketssort=-priority,created_at- Retrieves a list of tickets in descending order of priority. Within a specific priority, older tickets are ordered first
這里第二條查詢中,排序規則有多個rule以逗號間隔組合而成。
搜索:有些時候簡單的排序是不夠的。我們可以使用搜索技術(ElasticSearch和Lucene)來實現(依舊可以作為url的參數)。
GET /ticketsq=return&state=open&sort=-priority,created_at- Retrieve the highest priority open tickets mentioning the word ‘return’
對于經常使用的搜索查詢,我們可以為他們設立別名,這樣會讓API更加優雅。例如:
get /ticketsq=recently_closed -》 get /tickets/recently_closed.
限制API返回值的域
有時候API使用者不需要所有的結果,在進行橫向限制的時候(例如值返回API結果的前十項)還應該可以進行縱向限制。并且這個功能能有效的提高網絡帶寬使用率和速度。可以使用fields查詢參數來限制返回的域例如:
GET /ticketsfields=id,subject,customer_name,updated_at&state=open&sort=-updated_at
更新和創建操作應該返回資源
PUT、POST、PATCH 操作在對資源進行操作的時候常常有一些副作用:例如created_at,updated_at 時間戳。為了防止用戶多次的API調用(為了進行此次的更新操作),我們應該會返回更新的資源(updated representation.)例如:在POST操作以后,返回201 created 狀態碼,并且包含一個指向新資源的url作為返回頭
是否需要 “HATEOAS“
網上關于是否允許用戶創建新的url有很大的異議(注意不是創建資源產生的url)。為此REST制定了HATEOAS來描述了和endpoint進行交互的時候,行為應該在資源的metadata返回值里面進行定義。
(譯注:作者這里認為HATEOAS還不算成熟,我也不怎么理解這段就算了,讀者感興趣可以自己去原文查看)
只提供json作為返回格式
現在開始比較一下XML和json了。XML即冗長,難以閱讀,又不適合各種編程語言解析。當然XML有擴展性的優勢,但是如果你只是將它來對內部資源串行化,那么他的擴展優勢也發揮不出來。很多應用(youtube,twitter,box)都已經開始拋棄XML了,我也不想多費口舌。給了google上的趨勢圖吧:
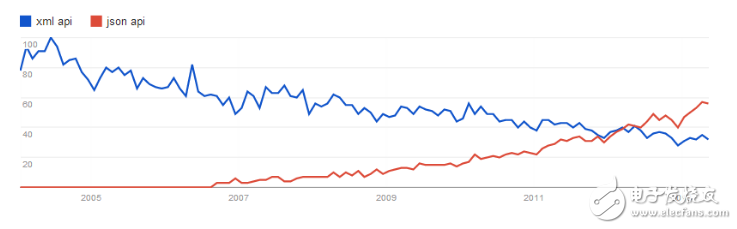
當然如果的你使用用戶里面企業用戶居多,那么可能需要支持XML。如果是這樣的話你還有另外一個問題:你的http請求中的media類型是應該和accept 頭同步還是和url?為了方便(browser explorability),應該是在url中(用戶只要自己拼url就好了)。如果這樣的話最好的方法是使用.xml或者.json的后綴。
命名方式?
是蛇形命令(下劃線和小寫)還是駝峰命名?如果使用json那么最好的應該是遵守JAVASCRIPT的命名方法-也就是說駱駝命名法。如果你正在使用多種語言寫一個庫,那么最好按照那些語言所推薦的,java,c#使用駱駝,python,ruby使用snake。
個人意見:我總覺得蛇形命令更好使一些,當然這沒有什么理論的依據。有人說蛇形命名讀起來更快,能達到20%,也不知道真假http://ieeexplore.ieee.org/xpl/articleDetails.jsptp=&arnumber=5521745
默認使用pretty print格式,使用gzip
只是使用空格的返回結果從瀏覽器上看總是覺得很惡心(一大坨有沒有?~)。當然你可以提供url上的參數來控制使用“pretty print”,但是默認開啟這個選項還是更加友好。格外的傳輸上的損失不會太大。相反你如果忘了使用gzip那么傳輸效率將會大大減少,損失大大增加。想象一個用戶正在debug那么默認的輸出就是可讀的-而不用將結果拷貝到其他什么軟件中在格式化-是想起來就很爽的事,不是么?
下面是一個例子:
$ curl https://API.github.com/users/veesahni 》 with-whitespace.txt
$ ruby -r json -e ‘puts JSON JSON.parse(STDIN.read)’ 《 with-whitespace.txt 》 without-whitespace.txt
$ gzip -c with-whitespace.txt 》 with-whitespace.txt.gz
$ gzip -c without-whitespace.txt 》 without-whitespace.txt.gz
輸出如下:
without-whitespace.txt- 1252 bytes
with-whitespace.txt- 1369 bytes
without-whitespace.txt.gz- 496 bytes
with-whitespace.txt.gz- 509 bytes
在上面的例子中,多余的空格使得結果大小多出了8.5%(沒有使用gzip),相反只多出了2.6%。據說:twitter使用gzip之后它的streaming API傳輸減少了80%(link:https://dev.twitter.com/blog/announcing-gzip-compression-streaming-APIs)。
只在需要的時候使用“envelope”
很多API象下面這樣返回結果:
{
“data” : {
“id” : 123,
“name” : “John”
}
}
理由很簡單:這樣做可以很容易擴展返回結果,你可以加入一些分頁信息,一些數據的元信息等-這對于那些不容易訪問到返回頭的API使用者來說確實有用,但是隨著“標準”的發展(cors和http://tools.ietf.org/html/rfc5988#page-6都開始被加入到標準中了),我個人推薦不要那么做。
何時使用envelope?
有兩種情況是應該使用envelope的。如果API使用者確實無法訪問返回頭,或者API需要支持交叉域請求(通過jsonp)。
jsonp請求在請求的url中包含了一個callback函數參數。如果給出了這個參數,那么API應該返回200,并且把真正的狀態碼放到返回值里面(包裝在信封里),例如:
callback_function({
status_code: 200,
next_page: “https://。.”,
response: {
... actual JSON response body 。..
}
})
同樣為了支持無法方法返回頭的API使用者,可以允許envelope=true這樣的參數。
在post,put,patch上使用json作為輸入
如果你認同我上面說的,那么你應該決定使用json作為所有的API輸出格式,那么我們接下來考慮考慮API的輸入數據格式。
很多的API使用url編碼格式:就像是url查詢參數的格式一樣:單純的鍵值對。這種方法簡單有效,但是也有自己的問題:它沒有數據類型的概念。這使得程序不得不根據字符串解析出布爾和整數,而且還沒有層次結構–雖然有一些關于層次結構信息的約定存在可是和本身就支持層次結構的json比較一下還是不很好用。
當然如果API本身就很簡單,那么使用url格式的輸入沒什么問題。但對于復雜的API你應該使用json。或者干脆統一使用json。
注意使用json傳輸的時候,要求請求頭里面加入:Content-Type:application/json.,否則拋出415異常(unsupported media type)。
分頁
分頁數據可以放到“信封”里面,但隨著標準的改進,現在我推薦將分頁信息放到link header里面:http://tools.ietf.org/html/rfc5988#page-6。
使用link header的API應該返回一系列組合好了的url而不是讓用戶自己再去拼。這點在基于游標的分頁中尤為重要。例如下面,來自github的文檔
Link: 《https://api.github.com/user/repos?page=3&per_page=100》; rel=“next”,
《https://api.github.com/user/repos?page=50&per_page=100》; rel=“last”
自動加載相關的資源
很多時候,自動加載相關資源非常有用,可以很大的提高效率。但是這卻和RESTful的原則相背。為了如此,我們可以在url中添加參數:embed(或者expend)。embed可以是一個逗號分隔的串,例如:
GET /ticket/12embed=customer.name,assigned_user
對應的API返回值如下:
{
“id” : 12,
“subject” : “I have a question!”,
“summary” : “Hi, 。..。”,
“customer” : {
“name” : “Bob”
},
assigned_user: {
“id” : 42,
“name” : “Jim”,
}
}
值得提醒的是,這個功能有時候會很復雜,并且可能導致N+1 SELECT 問題。
重寫HTTP方法
有的客戶端只能發出簡單的GET 和POST請求。為了照顧他們,我們可以重寫HTTP請求。這里沒有什么標準,但是一個普遍的方式是接受X-HTTP-Method-Override請求頭。
速度限制
為了避免請求泛濫,給API設置速度限制很重要。為此 RFC 6585 引入了HTTP狀態碼429(too many requests)。加入速度設置之后,應該提示用戶,至于如何提示標準上沒有說明,不過流行的方法是使用HTTP的返回頭。
下面是幾個必須的返回頭(依照twitter的命名規則):
X-Rate-Limit-Limit :當前時間段允許的并發請求數
X-Rate-Limit-Remaining:當前時間段保留的請求數。
X-Rate-Limit-Reset:當前時間段剩余秒數
為什么使用當前時間段剩余秒數而不是時間戳?
時間戳保存的信息很多,但是也包含了很多不必要的信息,用戶只需要知道還剩幾秒就可以再發請求了這樣也避免了clock skew問題。
有些API使用UNIX格式時間戳,我建議不要那么干。為什么?HTTP 已經規定了使用 RFC 1123 時間格式
鑒權 Authentication
restful API是無狀態的也就是說用戶請求的鑒權和cookie以及session無關,每一次請求都應該包含鑒權證明。
通過使用ssl我們可以不用每次都提供用戶名和密碼:我們可以給用戶返回一個隨機產生的token。這樣可以極大的方便使用瀏覽器訪問API的用戶。這種方法適用于用戶可以首先通過一次用戶名-密碼的驗證并得到token,并且可以拷貝返回的token到以后的請求中。如果不方便,可以使用OAuth 2來進行token的安全傳輸。
支持jsonp的API需要額外的鑒權方法,因為jsonp請求無法發送普通的credential。這種情況下可以在查詢url中添加參數:access_token。注意使用url參數的問題是:目前大部分的網絡服務器都會講query參數保存到服務器日志中,這可能會成為大的安全風險。
注意上面說到的只是三種傳輸token的方法,實際傳輸的token可能是一樣的。
緩存
HTTP提供了自帶的緩存框架。你需要做的是在返回的時候加入一些返回頭信息,在接受輸入的時候加入輸入驗證。基本兩種方法:
ETag:當生成請求的時候,在HTTP頭里面加入ETag,其中包含請求的校驗和和哈希值,這個值和在輸入變化的時候也應該變化。如果輸入的HTTP請求包含IF-NONE-MATCH頭以及一個ETag值,那么API應該返回304 not modified狀態碼,而不是常規的輸出結果。
Last-Modified:和etag一樣,只是多了一個時間戳。返回頭里的Last-Modified:包含了 RFC 1123 時間戳,它和IF-MODIFIED-SINCE一致。HTTP規范里面有三種date格式,服務器應該都能處理。
出錯處理
就像html錯誤頁面能夠顯示錯誤信息一樣,API 也應該能返回可讀的錯誤信息–它應該和一般的資源格式一致。API應該始終返回相應的狀態碼,以反映服務器或者請求的狀態。API的錯誤碼可以分為兩部分,400系列和500系列,400系列表明客戶端錯誤:如錯誤的請求格式等。500系列表示服務器錯誤。API應該至少將所有的400系列的錯誤以json形式返回。如果可能500系列的錯誤也應該如此。json格式的錯誤應該包含以下信息:一個有用的錯誤信息,一個唯一的錯誤碼,以及任何可能的詳細錯誤描述。如下:
{
“code” : 1234,
“message” : “Something bad happened :-(”,
“description” : “More details about the error here”
}
對PUT,POST,PATCH的輸入的校驗也應該返回相應的錯誤信息,例如:
{
“code” : 1024,
“message” : “Validation Failed”,
“errors” : [
{
“code” : 5432,
“field” : “first_name”,
“message” : “First name cannot have fancy characters”
},
{
“code” : 5622,
“field” : “password”,
“message” : “Password cannot be blank”
}
]
}
HTTP 狀態碼
200 ok - 成功返回狀態,對應,GET,PUT,PATCH,DELETE.
201 created - 成功創建。
304 not modified - HTTP緩存有效。
400 bad request - 請求格式錯誤。
401 unauthorized - 未授權。
403 forbidden - 鑒權成功,但是該用戶沒有權限。
404 not found - 請求的資源不存在
405 method not allowed - 該http方法不被允許。
410 gone - 這個url對應的資源現在不可用。
415 unsupported media type - 請求類型錯誤。
422 unprocessable entity - 校驗錯誤時用。
429 too many request - 請求過多。











 工商網監
工商網監
評論