 電子發(fā)燒友App
電子發(fā)燒友App


摘 要 本文綜述了人臉識別理論的研究現(xiàn)狀,根據(jù)人臉自動識別技術(shù)發(fā)展的時間進行了分類,分析和比較各種識別方法優(yōu)缺點,討論了其中的關(guān)鍵技術(shù)及發(fā)展前景。
關(guān)鍵詞 人臉識別;特征提取
1 人臉識別技術(shù)概述
近年來,隨著計算機技術(shù)的迅速發(fā)展,人臉自動識別技術(shù)得到廣泛研究與開發(fā),人臉識別成為近30年里模式識別和圖像處理中最熱門的研究主題之一。人臉識別的目的是從人臉圖像中抽取人的個性化特征,并以此來識別人的身份。一個簡單的自動人臉識別系統(tǒng),包括以下4個方面的內(nèi)容:
(1)人臉檢測(Detection):即從各種不同的場景中檢測出人臉的存在并確定其位置。
(2)人臉的規(guī)范化(Normalization):校正人臉在尺度、光照和旋轉(zhuǎn)等方面的變化。
(3)人臉表征(Face Representation):采取某種方式表示檢測出人臉和數(shù)據(jù)庫中的已知人臉。
(4)人臉識別(Recognition):將待識別的人臉與數(shù)據(jù)庫中的已知人臉比較,得出相關(guān)信息。
2 人臉識別算法的框架
人臉識別算法描述屬于典型的模式識別問題,主要有在線匹配和離線學(xué)習(xí)兩個過程組成,如圖1所示。

圖1 一般人臉識別算法框架
在人臉識別中,特征的分類能力、算法復(fù)雜度和可實現(xiàn)性是確定特征提取法需要考慮的因素。所提取特征對最終分類結(jié)果有著決定性的影響。分類器所能實現(xiàn)的分辨率上限就是各類特征間最大可區(qū)分度。因此,人臉識別的實現(xiàn)需要綜合考慮特征選擇、特征提取和分類器設(shè)計。
3 人臉識別的發(fā)展歷史及分類
人臉識別的研究已經(jīng)有相當(dāng)長的歷史,它的發(fā)展大致可以分為四個階段:
第一階段:人類最早的研究工作至少可追朔到二十世紀(jì)五十年代在心理學(xué)方面的研究和六十年代在工程學(xué)方面的研究。
J. S. Bruner于1954年寫下了關(guān)于心理學(xué)的The perception of people,Bledsoe在1964年就工程學(xué)寫了Facial Recognition Project Report,國外有許多學(xué)校在研究人臉識別技術(shù)[1],其中有從感知和心理學(xué)角度探索人類識別人臉機理的,如美國Texas at Dallas大學(xué)的Abdi和Tool小組[2、3],由Stirling大學(xué)的Bruce教授和Glasgow大學(xué)的Burton教授合作領(lǐng)導(dǎo)的小組等[3];也有從視覺機理角度進行研究的,如英國的Graw小組[4、5]和荷蘭Groningen大學(xué)的Petkov小組[6]等。
第二階段:關(guān)于人臉的機器識別研究開始于二十世紀(jì)七十年代。
Allen 和Parke 為代表,主要研究人臉識別所需要的面部特征。研究者用計算機實現(xiàn)了較高質(zhì)量的人臉灰度圖模型。這一階段工作的特點是識別過程全部依賴于操作人員,不是一種可以完成自動識別的系統(tǒng)。
第三階段:人機交互式識別階段。
Harmon 和Lesk 用幾何特征參數(shù)來表示人臉正面圖像。他們采用多維特征矢量表示人臉面部特征,并設(shè)計了基于這一特征表示法的識別系統(tǒng)。Kaya和Kobayashi 則采用了統(tǒng)計識別方法,用歐氏距離來表征人臉特征。但這類方法需要利用操作員的某些先驗知識,仍然擺脫不了人的干預(yù)。
第四階段:20世紀(jì)90年代以來,隨著高性能計算機的出現(xiàn),人臉識別方法有了重大突破,才進入了真正的機器自動識別階段。在用靜態(tài)圖像或視頻圖像做人臉識別的領(lǐng)域中,國際上形成了以下幾類主要的人臉識別方法:
1)基于幾何特征的人臉識別方法
基于幾何特征的方法是早期的人臉識別方法之一[7]。常采用的幾何特征有人臉的五官如眼睛、鼻子、嘴巴等的局部形狀特征。臉型特征以及五官在臉上分布的幾何特征。提取特征時往往要用到人臉結(jié)構(gòu)的一些先驗知識。識別所采用的幾何特征是以人臉器官的形狀和幾何關(guān)系為基礎(chǔ)的特征矢量,本質(zhì)上是特征矢量之間的匹配,其分量通常包括人臉指定兩點間的歐式距離、曲率、角度等。
基于幾何特征的識別方法比較簡單、容易理解,但沒有形成統(tǒng)一的特征提取標(biāo)準(zhǔn);從圖像中抽取穩(wěn)定的特征較困難,特別是特征受到遮擋時; 對較大的表情變化或姿態(tài)變化的魯棒性較差。
2)基于相關(guān)匹配的方法
基于相關(guān)匹配的方法包括模板匹配法和等強度線方法。
①模板匹配法:Poggio和Brunelli[10]專門比較了基于幾何特征的人臉識別方法和基于模板匹配的人臉識別方法,并得出結(jié)論:基于幾何特征的人臉識別方法具有識別速度快和內(nèi)存要求小的優(yōu)點,但在識別率上模板匹配要優(yōu)于基于幾何特征的識別方法。
②等強度線法:等強度線利用灰度圖像的多級灰度值的等強度線作為特征進行兩幅人臉圖像的匹配識別。等強度曲線反映了人臉的凸凹信息。這些等強度線法必須在背景與頭發(fā)均為黑色,表面光照均勻的前提下才能求出符合人臉真實形狀的等強度線。
3)基于子空間方法
常用的線性子空間方法有:本征子空間、區(qū)別子空間、獨立分量子空間等。此外,還有局部特征分析法、因子分析法等。這些方法也分別被擴展到混合線性子空間和非線性子空間。
Turk等[11]采用本征臉(Eigenfaces)方法實現(xiàn)人臉識別。由于每個本征矢量的圖像形式類似于人臉,所以稱本征臉。對原始圖像和重構(gòu)圖像的差分圖像再次進行K-L變換,得到二階本征空間,又稱二階本征臉[12]。Pentland等[13]提出對于眼、鼻和嘴等特征分別建立一個本征子空間,并聯(lián)合本征臉子空間的方法獲得了好的識別結(jié)果。Shan等[14]采用特定人的本征空間法獲得了好于本征臉方法的識別結(jié)果。Albert等[15]提出了TPCA(Topological PCA)方法,識別率有所提高。Penev等[16]提出的局部特征分析(LFA Local Feature Analysis)法的識別效果好于本征臉方法。當(dāng)每個人有多個樣本圖像時,本征空間法沒有考慮樣本類別間的信息,因此,基于線性區(qū)別分析(LDA Linear Discriminant Analysis ),Belhumeur等[17]提出了Fisherfaces方法,獲得了較好的識別結(jié)果。Bartlett等[18]采用獨立分量分析(ICA,Independent Component Analysis)的方法識別人臉,獲得了比PCA方法更好的識別效果。
4)基于統(tǒng)計的識別方法
該類方法包括有:KL算法、奇異值分解(SVD)、隱馬爾可夫(HMM)法。
①KL變換:將人臉圖像按行(列)展開所形成的一個高維向量看作是一種隨機向量,因此采用K-L變換獲得其正交K-L基底,對應(yīng)其中較大特征值基底具有與人臉相似的形狀。國外,在用靜態(tài)圖像或視頻圖像做人臉識別的領(lǐng)域中,比較有影響的有MIT的Media實驗室的Pentland小組,他們主要是用基于KL變換的本征空間的特征提取法,名為“本征臉(Eigenface)[19]。
②隱馬爾可夫模型:劍橋大學(xué)的Samaria和Fallside[20]對多個樣本圖像的空間序列訓(xùn)練出一個HMM模型,它的參數(shù)就是特征值;基于人臉從上到下、從左到右的結(jié)構(gòu)特征;Samatia等[21]首先將1-D HMM和2-D Pseudo HMM用于人臉識別。Kohir等[22]采用低頻DCT系數(shù)作為觀察矢量獲得了好的識別效果,如圖2(a)所示。Eickeler等[23]采用2-D Pseudo HMM識別DCT壓縮的JPEG圖像中的人臉圖像;Nefian等采用嵌入式HMM識別人臉[24],如圖2(b)所示。后來集成coupled HMM和HMM通過對超狀態(tài)和各嵌入狀態(tài)采用不同的模型構(gòu)成混合系統(tǒng)結(jié)構(gòu)[25]。
基于HMM的人臉識別方法具有以下優(yōu)點:第一,能夠允許人臉有表情變化,較大的頭部轉(zhuǎn)動;第二,擴容性好。即增加新樣本不需要對所有的樣本進行訓(xùn)練;第三,較高的識別率。

(a) (b)
圖2 (a) 人臉圖像的1-D HMM (b) 嵌入式隱馬爾科夫模型
5)基于神經(jīng)網(wǎng)絡(luò)的方法
Gutta等[26]提出了混合神經(jīng)網(wǎng)絡(luò)、Lawrence等[27]通過一個多級的SOM實現(xiàn)樣本的聚類,將卷積神經(jīng)網(wǎng)絡(luò)CNN用于人臉識別、Lin等[28]采用基于概率決策的神經(jīng)網(wǎng)絡(luò)方法、Demers等[29]提出采用主元神經(jīng)網(wǎng)絡(luò)方法提取人臉圖像特征,用自相關(guān)神經(jīng)網(wǎng)絡(luò)進一步壓縮特征,最后采用一個MLP來實現(xiàn)人臉識別。Er等[30]采用PCA進行維數(shù)壓縮,再用LDA抽取特征,然后基于RBF進行人臉識別。Haddadnia等[31]基于PZMI特征,并采用混合學(xué)習(xí)算法的RBF神經(jīng)網(wǎng)絡(luò)進行人臉識別。神經(jīng)網(wǎng)絡(luò)的優(yōu)勢是通過學(xué)習(xí)的過程獲得對這些規(guī)律和規(guī)則的隱性表達,它的適應(yīng)性較強。
6)彈性圖匹配方法
Lades等提出采用動態(tài)鏈接結(jié)構(gòu)(DLA,Dynamic Link Architecture)[32]的方法識別人臉。它將人臉用格狀的稀疏圖如圖3所示。
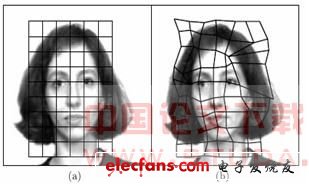
圖3 人臉識別的彈性匹配方法
圖3中的節(jié)點用圖像位置的Gabor小波分解得到的特征向量標(biāo)記,圖的邊用連接節(jié)點的距離向量標(biāo)記。Wiskott等人使用彈性圖匹配方法,準(zhǔn)確率達到97.3%。Wiskott等[33]將人臉特征上的一些點作為基準(zhǔn)點,構(gòu)成彈性圖。采用每個基準(zhǔn)點存儲一串具有代表性的特征矢量,減少了系統(tǒng)的存儲量。Wurtz等[34]只使用人臉I(yè)CI部的特征,進一步消除了結(jié)構(gòu)中的冗余信息和背景信息,并使用一個多層的分級結(jié)構(gòu)。Grudin等[35]也采用分級結(jié)構(gòu)的彈性圖,通過去除了一些冗余節(jié)點,形成稀疏的人臉描述結(jié)構(gòu)。另一種方法是,Nastar等[36]提出將人臉圖像I(x,y)表示為可變形的3D網(wǎng)格表(x,y,I(x,y)),將人臉匹配問題轉(zhuǎn)換為曲面匹配問題,利用有限分析的方法進行曲面變形,根據(jù)兩幅圖像之間變形匹配的程度識別人臉。
7)幾種混合方法的有效性
(1)K-L投影和奇異值分解(SVD)相融合的分類判別方法。
K-L變換的核心過程是計算特征值和特征向量。而圖像的奇異值具有良好的穩(wěn)定性,當(dāng)圖像有小的擾動時,奇異值的變化不大。奇異值表示了圖像的代數(shù)特征,在某種程度上,SVD特征同時擁有代數(shù)與幾何兩方面的不變性。利用K-L投影后的主分量特征向量與SVD特征向量對人臉進行識別,提高識別的準(zhǔn)確性[37]。
(2)HMM和奇異值分解相融合的分類判別方法。
采用奇異值分解方法進行特征提取,一般是把一幅圖像(長為H)看成一個N×M的矩陣,求取其奇異值作為人臉識別的特征。在這里我們采用采樣窗對同一幅圖片進行重疊采樣(如圖4),對采樣所得到的矩陣分別求其對應(yīng)的前k個最大的奇異值,分別對每一組奇異值進行矢量標(biāo)準(zhǔn)化和矢量重新排序,把這些處理后的奇異值按采樣順序組成一組向量,這組向量是惟一的[38]。

圖4 采樣窗采樣
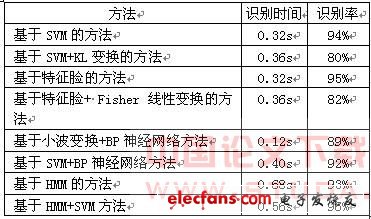
綜合上述論文中的實驗數(shù)據(jù)表明[39],如表1:
表1 人臉識別算法比較
8)基于三維模型的方法
該類方法一般先在圖像上檢測出與通用模型頂點對應(yīng)的特征點,然后根據(jù)特征點調(diào)節(jié)通用模型,最后通過紋理映射得到特定人臉的3D模型。Tibbalds[40]基于結(jié)構(gòu)光源和立體視覺理論,通過攝像機獲取立體圖像,根據(jù)圖像特征點之間匹配構(gòu)造人臉的三維表面,如圖5所示。

圖5 三維人臉表面模型 圖6 合成的不同姿態(tài)和光照條件下二維人臉表面模型
Zhao[41]提出了一個新的SSFS(Symetric Shape- from-Shading)理論來處理像人臉這類對稱對象的識別問題,基于SSFS理論和一個一般的三維人臉模型來解決光照變化問題,通過基于SFS的視圖合成技術(shù)解決人臉姿態(tài)問題,針對不同姿態(tài)和光照條件合成的三維人臉模型如圖6所示。
三維圖像有三種建模方法:基于圖像特征的方法[42、43]、基于幾何[44]、基于模型可變參數(shù)的方法[45]。其中,基于模型可變參數(shù)的方法與基于圖像特征的方法的最大區(qū)別在于:后者在人臉姿態(tài)每變化一次后,需要重新搜索特征點的坐標(biāo),而前者只需調(diào)整3D 變形模型的參數(shù)。三維重建的系統(tǒng)框圖,如圖7所示。
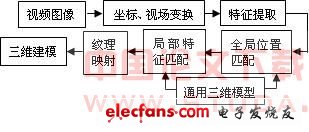
圖7 三維建模的系統(tǒng)框圖
三維人臉建模、待識別人臉的姿態(tài)估計和識別匹配算法的選取是實現(xiàn)三維人臉識別的關(guān)鍵技術(shù)。隨著采用三維圖像識別人臉技術(shù)的發(fā)展,利用直線的三維圖像信息進行人臉識別已經(jīng)成為人們研究的重心。
4 總結(jié)與展望
人臉自動識別技術(shù)已取得了巨大的成就,隨著科技的發(fā)展,在實際應(yīng)用中仍然面臨困難,不僅要達到準(zhǔn)確、快速的檢測并分割出人臉部分,而且要有效的變化補償、特征描述、準(zhǔn)確的分類的效果,還需要注重和提高以下幾個方面:
(1) 人臉的局部和整體信息的相互結(jié)合能有效地描述人臉的特征,基于混合模型的方法值得進一步深入研究,以便能準(zhǔn)確描述復(fù)雜的人臉模式分布。
(2) 多特征融合和多分類器融合的方法也是改善識別性能的一個手段。
(3) 由于人臉為非剛體性,人臉之間的相似性以及各種變化因素的影響,準(zhǔn)確的人臉識別仍較困難。為了滿足自動人臉識別技術(shù)具有實時要求,在必要時需要研究人臉與指紋、虹膜、語音等識別技術(shù)的融合方法。
(4) 3D形變模型可以處理多種變化因素,具有很好的發(fā)展前景。已有研究也表明,對各種變化因素采用模擬或補償?shù)姆椒ň哂休^好的效果。三維人臉識別算法的選取還處于探索階段,需要在原有傳統(tǒng)識別算法的基礎(chǔ)上改進和創(chuàng)新。
(5) 表面紋理識別算法是一種最新的算法[52],有待于我們繼續(xù)學(xué)習(xí)和研究出更好的方法。
總之,人臉識別是極富挑戰(zhàn)性的課題僅僅采用一種現(xiàn)有方法難以取得良好的識別效果,如何與其它技術(shù)相結(jié)合,如何提高識別率和識別速度、減少計算量、提高魯棒性,如何采用嵌入式及硬件實現(xiàn),如何實用化都是將來值得研究的。















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論