語音芯片LD3320 芯片是一款基于非特定人語音識別技術的聲控芯片, 可以實現語音識別及MP3 播放功能。為了能使芯片正常工作,共有42 個引腳需要配置,而單獨使用AT89S52 單片機無法直接完成對該芯片的配置。
2014-12-18 10:54:41 3070
3070 
為進一步提高模擬訓練的訓練效果,利用智能語音芯片設計開發了某模擬訓練器的示教與回放系統。該系統綜合運用語音識別、聲強檢測、語音合成、數據記錄等手段,完成對操作過程的實時記錄與回放,取得了良好的訓練
2014-03-28 10:40:192260 非特定人語音識別技術研究的最終目的是讓計算機等設備能夠“聽懂”人類語音,提取出語音中所包含的特定信息,成為人機通信和交互最便捷的手段。
2014-10-21 10:08:221559 
本漢語語音識別系統是一個非特定人的、孤立音語音識別系統。其中孤立音至少包括漢語的400多個調音節(不考慮聲調)以及一些常用的詞組。##測度估計技術可以采用動態時間彎折DTW、隱馬爾可夫模型HMM
2014-12-16 13:44:373123 
隨著高新技術在軍事領域的廣泛運用,武器裝備逐步向高、精、尖方向發展。傳統的軍事訓練由于訓練時間長、訓練費用高、訓練空間窄,常常不能達到預期的訓練效果,已不能滿足現代軍事訓練的需要。為解決上述問題,模擬訓練應運而生。
2015-07-27 11:13:072357 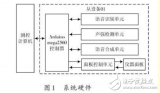
本系統采用的主控MCU為Atmel公司的ATMEGA128,語音識別功能則采用ICRoute公司的單芯片LD3320。LD3320內部集成優化過的語音識別算法,無需外部FLASH,RAM資源,可以很好地完成非特定人的語音識別任務。
2020-02-17 15:07:442366 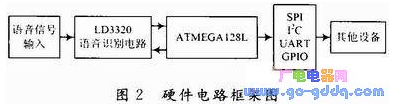
特定人語音識別的方法有哪些?特定人語音識別技術在汽車控制上的應用是什么?
2021-05-14 06:34:04
,設置寄存器傳入LD332X / LD3320 芯片,就可以完成語音識別功能。直接將芯片設計加入系統中即可以增加非特定人語音識別功能。# #
目前已有的語音識別芯片,一般基于特定人語音識別技術
2009-12-16 12:00:28
各位大神,我想完成用SPCE061A來實現非特定人的語音識別技術,并能夠使得發出的命令能在LCD上顯示,不知有沒有能夠指導一下的,大概的框架和模塊,拜托各位了。。。
2015-01-06 22:47:31
語音識別系統在智能家庭系統中的應用是什么?
2021-05-31 06:54:34
本帖最后由 linchenfeng 于 2014-8-10 21:33 編輯
非特定人聲識別單元,初步測試已經完成,可以識別和合成語音。但是對于噪聲干擾和識別的距離以及準確性還需要進一步優化
2014-08-07 13:31:03
2 非特定人語音識別2 語音支持 35 種語言, 如中文、英語、日語等2 BC009 支持二種連接方式:一、25MM 間距端子線連接二、直接將模塊焊接到主板上 2.應用范圍智能家電:智能語音燈具語音播報
2018-10-26 14:49:00
FPGA和Nios_軟核的語音識別系統的研究引言語音識別的過程是一個模式匹配的過程 在這個過程中,首先根據說話人的語音特點建立語音模型,對輸入的語音信號進行分析,并提取所需的語音特征,在此基礎上建立
2012-08-11 11:47:15
`產品特征:1、單芯片語音識別解決方案(非特定人識別)2、ISD9160自帶145kflash,可以做20條左右指令,另外可以外加SPI-FLASH擴展指令數量。3、采用***先進語音識別算法
2017-04-08 15:08:51
LD3320語音識別模塊+MP3-TF-16P模塊實現語音交互功能利用LD3320語音識別模塊可以實現非特定人聲語音控制單片機io口動作,而加入MP3-TF-16P語音播放模塊,可以讓語音識別富有
2022-02-15 06:35:24
LD3320是非特定人(不用針對指定人)語音識別芯片,即語音聲控芯片。最多可以識別50條預先內置的指令。工作模式:LD3320(LDV7)語音模塊可以工作在以下三種模式:普通模式:直接說話,模塊直接
2022-02-18 06:32:52
一、概述1.芯片介紹LD3320 是一顆基于非特定人語音識(SI-ASR:Speaker-Independent Automatic Speech Recognition)技術的語音識/聲控芯片
2021-07-26 06:54:04
為了提高廣大單片機愛好者學習單片機的興趣,凌陽科技大學計劃教育推廣中心推出了應用SPCE061A作為主控制器,外加電機驅動電路制作的語音識別機器人。該機器人采用特定人語音識別對機器人進行控制,可以
2011-03-08 17:09:02
這是說話人語音識別的相關資料,大神們來看看啊,順便幫小弟做一個用電腦麥克風識別說話人的程序,謝啦
2012-05-31 15:17:36
使用的是STC單片機,LD3320LD3320 是一顆基于非特定人語音識別(SI-ASR:Speaker-IndependentAutomatic Speech Recognition)技術的語音識別/聲控芯片。提供了真正的單芯片語音識別解決方案。
2016-06-29 10:44:29
的項目,當初開始研究LD3320芯片,無意中發現了ISD9160。ISD9160在BOM上可以直接驅動,特別適合語音控制方案。另外額外的還有語音識別的功能,我要做的是非特定人語音識別智能家具設計。如圖
2016-12-23 09:19:55
應用。通過軟件支持,ISD9160可以實現特定人和非特定人語音識別。其中非特定人語音識別支持九種語音,方便客戶開發國際化的產品。客戶在開發的時候,使用Nuvoton提供的ASR Tool工具,只需
2020-08-13 12:16:03
集成電路技術和微機械加工制造技術的進步,微型智能射頻卡得到了發展,在低功耗IC技術方面的突破,為發展小型、低功耗主動射頻卡創造了條件。 本文以新型射頻芯片nRF905為例,設計了一個工作在微波頻段的主動式射頻識別系統,給出了系統中關鍵的通信模塊設計方案。
2019-07-26 07:21:50
開發并測試了安裝在汽車內、使用簡單離散字的特定發音人語音識別系統。
2019-11-04 07:23:41
非特定語音識別有雜音干擾,如何用外圍電路解決這個問題?
2018-01-31 10:08:46
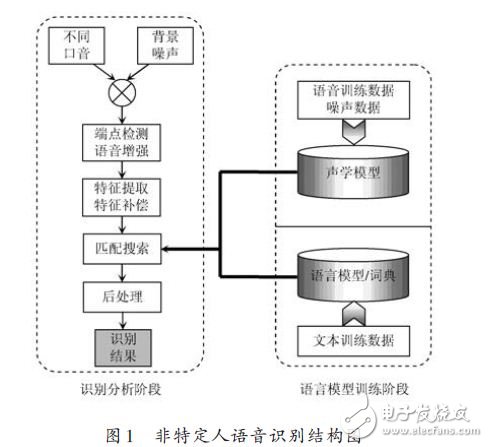
非特定人的語音識別任務。1 整體方案設計1.1 語音識別原理在計算機系統中,語音信號本身的不確定性、動態性和連續性是語音識別的難點。主流的語音識別技術是基于統計模式識別的基本理論,原理如圖1所示
2014-03-17 13:31:40
識別系統設計的可行性,并給出了設計方案。通過多次測試結果表明,本系統具有電路運行穩定,語音識別率高,成本低等優點。同時借助于LD3320的MP3播放功能,該系統具有一定的交互性和娛樂性。移植性方面,系統
2021-01-13 15:54:14
基于DSP的漢字語音識別系統如何實現
2021-03-12 06:33:15
基于HMM的語音識別系統是怎么訓練的?有哪些步驟?
2021-12-23 06:16:50
基于LabVIEW的語音識別系統
2020-03-07 16:41:15
請大家幫幫忙,基于LabVIEW的語音識別系統,要求先錄幾個人的聲音做樣板,然后再讓其中一個人說話,能辨別出是誰說的
2013-05-16 11:16:15
語音識別是機器通過識別和理解過程把人類的語音信號轉變為相應文本或命令的技術,其根本目的是研究出一種具有聽覺功能的機器。本設計研究孤立詞語音識別系統及其在STM32嵌入式平臺上的實現。識別流程是:預
2021-08-06 08:32:00
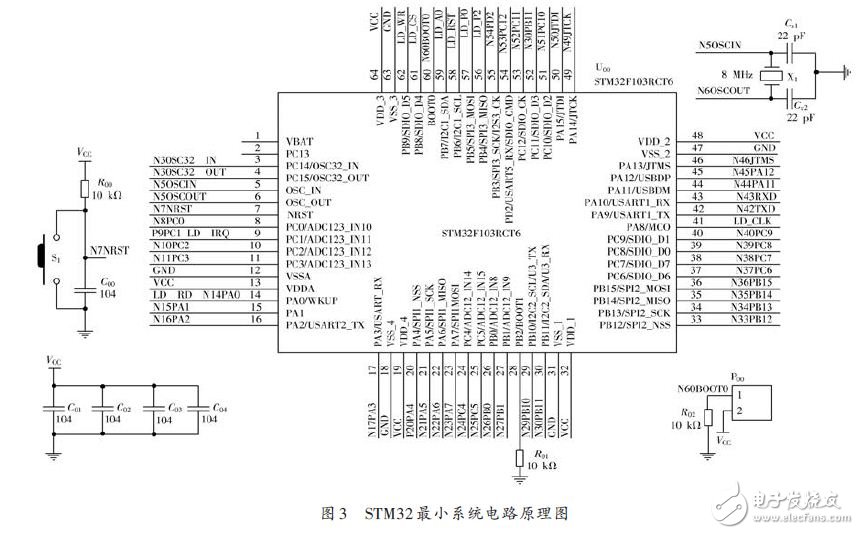
設計的臺燈采用的主控芯片是性能較高的STM32F103C8T6單片機芯片,采用中斷方式對臺燈進行按鍵控制,并通過基于LD332O語音識別模塊,利用非特定人語音識別技術對臺燈的工作狀態進行語音控制,同時實現了...
2022-01-19 06:04:27
特定人語音識別的方法有哪些?特定人語音識別系統是由哪些部分組成的?如何去實現一種特定人語音識別系統?
2021-05-19 06:44:14
現在社會發展的這么快,什么高科技都涌現出來,什么智能機器人啦,智能手機等,有很多在這里就不一一列舉了,在這里我們要說的就是語音識別系統了,現在嵌入式產品如此的多,就像一些智能空調啦,我們可以對著他說
2021-12-20 07:52:03
嵌入式語音識別系統是什么?嵌入式語音識別系統在生活中的應用有哪些呢?
2021-12-23 08:27:03
導讀:微軟今天宣布,其會話語音識別系統的誤率達到了5.1%,是目前為止最低的。
[img][/img]
這一數據超過了微軟人工智能和研究團隊去年5.9%的誤差率,并將其準確性與專業的人
2017-08-23 09:18:35
隨著計算機技術和信息技術的迅速發展,語音口令識別已經成為了人機交互的一個重要方式之一。語音口令識別系統將根據人發出的聲音、音節或短語給出響應,如通過語音口令控制一些執行機構、控制家用電器的運行或做出
2019-09-03 08:27:23
(GMM+HMM+NGRAM)概述)。一段時間后老板就布置了具體任務:在我們公司自己的ARM芯片上基于kaldi搭建一個在線語音識別系統,三個人花三個月左右的時間完成。由于我們都是語音識別領域的小白,要求...
2021-07-29 08:59:19
怎樣去搭建一個基于kaldi的嵌入式語音識別系統呢?
2021-12-23 09:30:05
怎樣去搭建一個基于kaldi的嵌入式在線語音識別系統?分為哪幾個階段呢?
2021-10-28 08:37:01
設備說明:本設備使用具有兩個usart串口的stc12c5a60s2作為MCU主控,SNR3512作為語音識別模塊,JQC80作為語音模塊,esp8266作為聯網模塊。本設備可以實現非特定人聲的語音
2021-12-06 08:16:18
語音與“家電溝通”,控制其開啟和關斷。基本思路:作品融合單片機技術、基于非特定人的語音識別技術、無線信息發傳輸技術為一體。首先采集人的語音命令,通過語音識別技術識別出命令,由單片機將命令處理成對家用電器...
2021-09-15 06:50:56
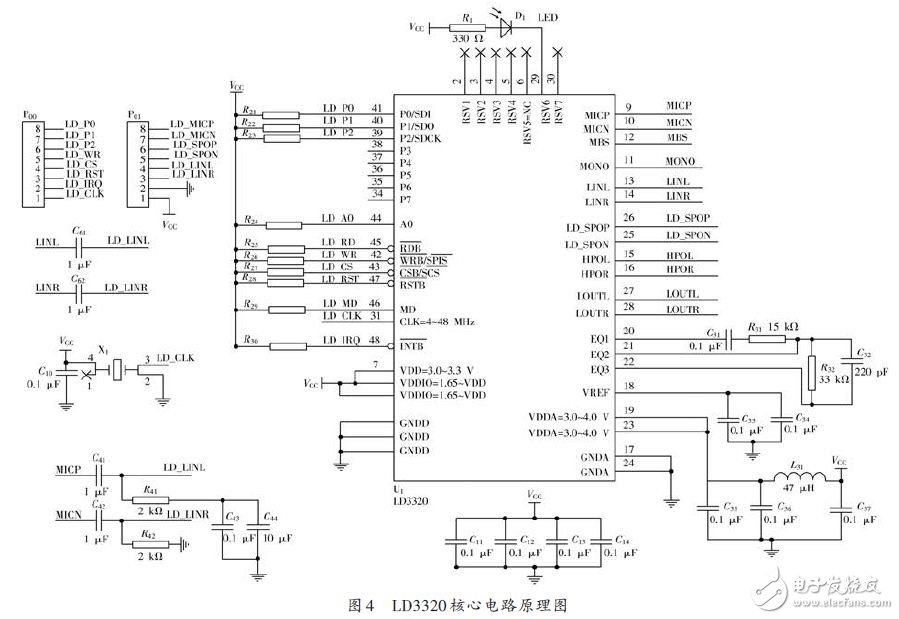
該設計運用三星公司的S3C2440,結合ICRoute公司的高性能語音識別芯片LD3320,進行了語音識別系統的硬件和軟件設計。在嵌入式Linux操作系統下,運用多進程機制完成了對語音識別芯片
2021-11-04 09:03:09
語音識別是什么?怎樣去設計并制作出基于STM32的孤立詞語音識別系統呢?
2021-11-08 07:04:19
求matlab特定人語音識別的程序,或者思路也行
2012-03-31 15:03:58
音樂語音識別系統的硬件電路該如何去設計?音樂語音識別系統的軟件該如何去實現?
2021-12-23 08:50:56
一種基于FPGA技術的多按鍵狀態識別系統的設計方案
2021-05-06 08:44:59
SVM多類分類方法是什么?嵌入式系統開發環境怎么搭建?基于SVM的0MAP5912非特定人嵌入式語音識別系統的實現方法
2021-06-01 06:47:44
本系統是基于數字通信原理、利用集成單芯片窄帶超高頻收發器構建的無線識別系統。闡述了該無線射頻識別系統基本工作原理和硬件設計思路,并給出了 程序設計方案的流程圖。從低功耗、高效識別和實用角度設計適用于
2019-08-14 06:49:06
完成語音識別功能。直接將芯片設計加入系統中即可以增加非特定人語音識別功能。
#
目前已有的語音識別芯片,一般基于特定人語音識別技術,芯片在出廠后無法修改識別的條目只能識別出廠前預制的識別內容
2009-12-16 11:59:08
: 1、識別率高達95%,無需聯網,只需一顆芯片即可搞定, 2、非特定人聲的語音識別,即只要是說同樣的指令,誰說都可以,不論男女老少都可以識別。3、識別的指令只需滿足3-8個字,具體是什么詞,由客戶自定義
2018-06-13 10:50:02
誰能告訴我 ,設計一個語音電子鎖,要能夠用特定人的聲音開鎖,用什么語音識別芯片可以做到呢?
2012-11-15 20:46:01
詳細介紹了一種非特定人的數碼語音識別算法:連續距離密度分段概率模型,同時給出了基于ADSP2181 DSP芯片的語音識別模塊的實現方案。
2009-04-22 15:30:00 30
30 詳細介紹了一種非特定人的數碼語音識別算法:連續距離密度分段概率模型,同時給出了基于ADSP2171DSP芯片的語音識別模塊的實現方案.
2009-04-27 16:33:2344 系統采用凌陽SPCE061A 單片機作為語音識別系統的主控芯片。通過硬件電路設計和軟件代碼部分成功的設計并實現了一種具有語音識別功能、語音提示(語音合成)及語音回放(語音編
2009-05-26 10:54:0845 語音識別技術是近年來十分活躍的研究領域,語音識別系統的實用化研究是語音識別研究的一個主要方向。近年來,消費類電子產品對低成本、高穩健性的語音識別功能的需求快速
2009-08-22 08:25:18115 語音識別技術是語音處理領域的一個關鍵技術。在研究了語音識別技術原理的基礎上,本文提出了一種基于ARM 處理器的孤立詞語音識別系統的設計方案,包括系統硬件設計、軟件
2009-09-03 10:52:4977 本文介紹了一種基于TMS320C6711 DSP的非特定人、孤立詞語音識別系統。本文首先介紹了語音識別技術的基本原理,然后對不同的識別算法在多種嵌入式系統平臺上進行性能分析和比較
2010-07-27 17:49:1324 隨著語音識別和語音合成技術的不斷更新與發展,將語音識別技術應用于嵌入式產品中已得到廣泛應用。SVM(支持向量機)作為統汁概率模型已經被證明是一種很好的識別模型。
2010-08-19 09:50:141089 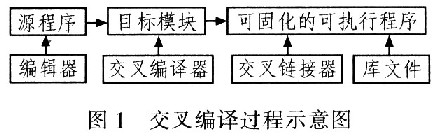
提出了一種特定人群 指紋驗證 系統的A S IC 實現方案。實現了指紋數據量少(針對特定人群)、采集環境相對固定的指紋驗證系統脫機工作。簡要介紹了該系統采用的指紋驗證算法, 重點介
2011-06-24 11:15:1037 語音控制的基礎就是語音識別技術,可以是特定人或者非特定人的。非特定人的應用更為廣泛,對于用戶而言不用訓練,因此也更加方便。語音識別可以分為孤立詞識別,連接詞識別,
2011-07-22 10:08:4812043 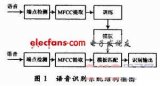
詳細介紹了一種非特定人的數碼語音識別算法:連續距離密度分段概率模型(CDD-SPM),同時給出了基于ADSP2181 DSP芯片的語音識別模塊的實現方案。
2011-10-12 15:59:32120 設計了一個嵌入式語音識別系統,該系統硬件平臺以ADSP-BF531為核心,采用離散隱馬爾可夫模型(DHMM)檢測和識別算法完成了對非特定人的孤立詞語音識別。試驗結果表明,該系統對非特定
2012-07-12 14:02:320 本文首次提出了一種以專用語音處理芯片UniSpeech-SDA80D51為核心組成的非特定人車載音響語音控制系統的設計方案,并實現了系統樣機的研制。
2012-10-23 10:04:402900 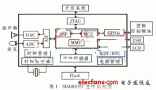
本文介紹了一種基于ARM的光學指紋識別系統的設計方案。##系統軟件設計部分針對畸變糾正采用了四點轉正算法。
2014-02-24 10:38:192020 基于STM32的語音識別系統的設計與實現
2015-11-09 18:03:0046 基于ARM的紙幣號碼識別系統,有需要的下來看看
2016-08-29 15:31:415 基于語音特征聚類的HMM語音識別系統研究_姚敏鋒
2017-03-15 08:00:002 該設計運用三星公司的S3C2440,結合ICRoute公司的高性能語音識別芯片LD3320,進行了語音識別系統的硬件和軟件設計。在嵌入式Linux操作系統下,運用多進程機制完成了對語音識別芯片
2017-10-15 10:53:426 本文介紹了一種基于ARM的光學指紋識別系統的設計方案。本方案采用ARM處理器作為控制核心,構建指紋識別算法的嵌入式系統的設計方法及過程。該系統采用光學指紋傳感器(內建格科微電子有限公司的光學
2017-10-16 16:22:275 的模式識別系統,包括指紋圖像獲取、處理、特征提取和比對等模塊。)設計方案,同時對該指紋識別系統的硬件架構進行了說明。該方案具有結構簡單、可擴展性和移植性強等諸多優點。 圖 1 所示是本嵌入式指紋識別系統的硬件框圖。從圖 1 中可以看到, 本系統主要
2017-10-17 16:19:1510 針對復雜狀況下傳統表情識別方法存在的問題,提出一種新的非特定人表情識別方法。該算法首先提取每張表情圖像的HOG特征和Haar小波特征,然后將兩種不同的特征串行融合得到整幅圖像的特征,最后通過SVM
2017-11-22 17:22:250 語音控制在智能家居的應用為人民生活帶來極大便利,但常規的非特定人語音控制會產生語音的誤觸發。本文在非特定語音識別的基礎上,通過改進相應算法設計了一種特定人語音識別家居控制系統。系統采用MFCC算法
2017-11-27 14:10:584 隨著計算機技術和信息技術的迅速發展,語音口令識別已經成為了人機交互的一個重要方式之一。語音口令識別系統將根據人發出的聲音、音節或短語給出響應,如通過語音口令控制一些執行機構、控制家用電器的運行或做出
2019-04-23 15:52:53863 
LD3320是一顆基于非特定人語音識別(SI-ASR:Speaker-Independent??Automatic?Speech?Recognition)技術的語音識別/聲控芯片。提供了真正的單芯片語音識別解決方案。?
2019-06-12 10:31:213021 嵌入式語音識別系統分為封閉域識別和開放域識別,封閉域識別范圍圍繞指定的字/詞語集合,也就是說在開發系統的時候會設定好應識別的字或詞語,對范圍外的詞語語音系統不會識別。
2019-06-12 11:38:092859 對比語音識別技術的兩個發展方向,由于基于不同的運算平臺,因此具有不同的特點。大詞匯量連續語音識別系統一般都是基于PC機平臺,而語音識別專用芯片的中心運算處理器則只是一片低功耗、低價位的智能芯片
2019-10-01 09:21:005253 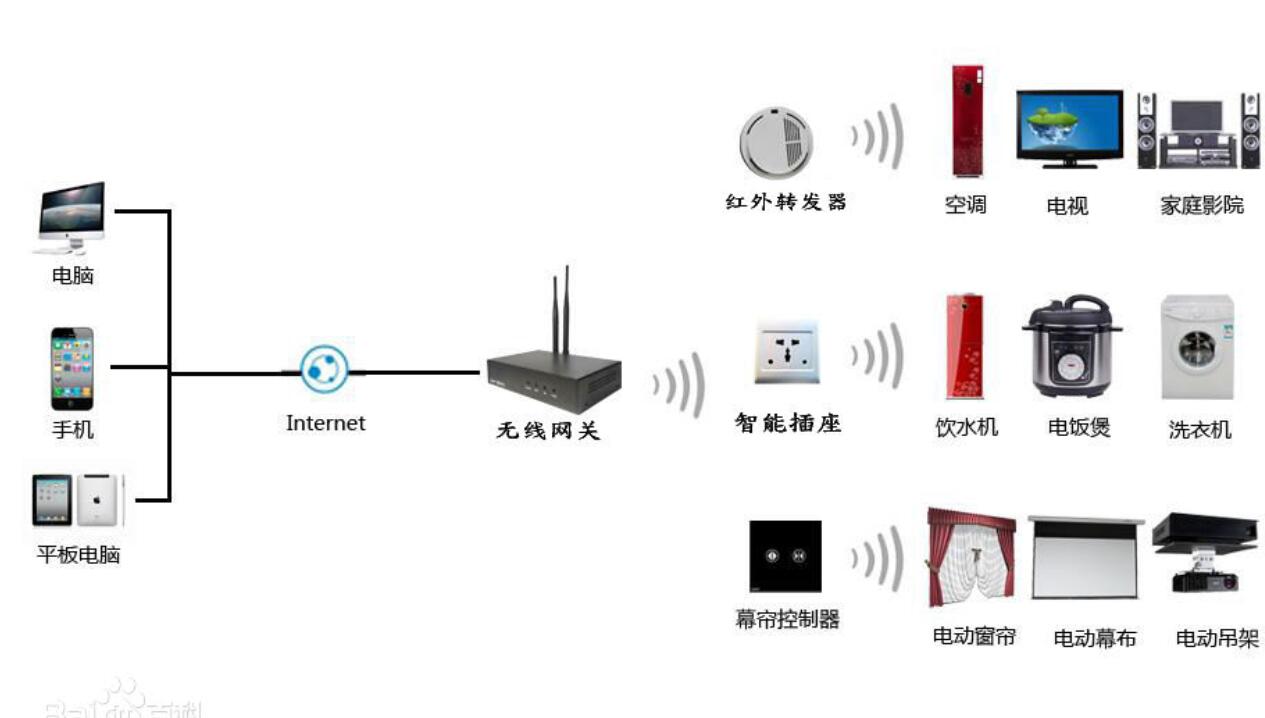
ASR Board 是一款基于Arduino的開源語音識別控制板,該模塊只需要通過上位機軟件發送指令即可設定要識別的關鍵詞,不需要用戶事先訓練和錄音,是一款高效的非特定人語音識別控制模塊。更重要的是,它不僅能夠“識別”語音,而且還能夠播放語音,和用戶進行互動。
2019-11-28 11:36:032765 
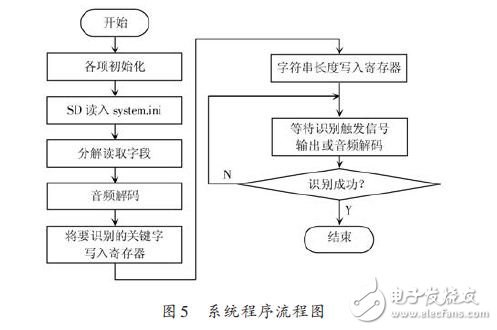
本文首先介紹了語音識別設置的刪除,其次闡述了語音識別系統工作流程,最后介紹了語音識別系統的實現。
2020-04-01 09:47:403749 本文介紹了一種采用ARM處理器作為控制核心的非特定人語音識別系統的設計方案。
2020-04-11 11:17:371180 
斯坦福大學的一項研究顯示,亞馬遜、蘋果、谷歌、IBM和微軟的語音識別系統存在種族差異,對白人和黑人語音的識別率有高有低。
2020-05-18 09:37:31579 深圳唯創知音研發了一款,本地語音識別芯片,是低成本語音交互解決方案,單芯片可定制60條不同的識別命令詞,并且符合藍牙 V5.1 + BR + EDR + BLE 規范,是一款低成本、高可靠性的非特定人聲識別方案;
2022-07-25 17:50:25996 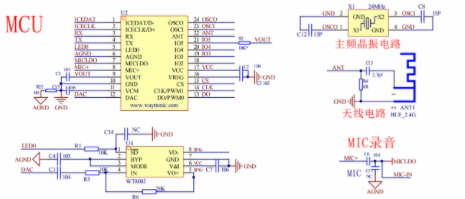
WTK6900H系列語音識別芯片,是深圳唯創知音研發的一款,低成本非特定人聲語音識別芯片,支持語音對話、語音控制兩種方式進行人機交互;3米內語音識別度可達90%以上;
2022-10-26 08:38:521317 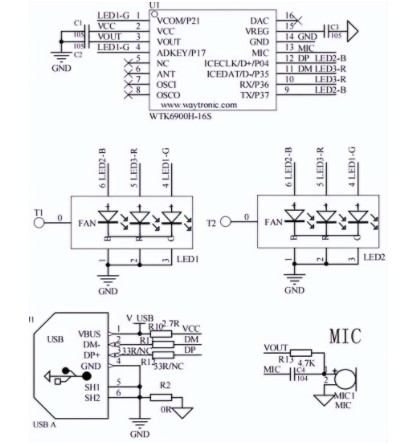
電子發燒友網站提供《基于OMAP5912的嵌入式非特定人連續語音識別系統.pdf》資料免費下載
2023-10-09 15:21:410 電子發燒友網站提供《基于DSP的車載語音識別系統方案設計.pdf》資料免費下載
2023-11-08 09:14:380
 電子發燒友App
電子發燒友App














 工商網監
工商網監
評論