 電子發燒友App
電子發燒友App


過去幾年,采用多線程或多內核CPU的微處理器架構有了長足的發展。現在它們已經成為臺式電腦的標準配置,并且在高端嵌入式市場的CPU中也已非常普及。這種發展是想要獲得更高性能的處理器設計師推動的結果。但硅片技術已經達到性能極限。滿足不斷提高的處理能力需求的解決方案,高度依賴于像在基于微處理器的系統級芯片(SoC)中復制內核處理器這樣的架構化解決方案。
戈登。摩爾在1965年提出的摩爾定律指出,隨著晶體管尺寸的縮小,每平方英寸硅片面積上可以集成的晶體管數量每兩年會翻一番。當然,這個“定律”并不是一種物理規律,而是根據60年代和70年代對技術的觀察經驗得出的一個猜想。但它從第一次被提出到現在都非常準確——并且至少在下一個十年中有望延續其正確性。
摩爾定律一直能保持正確性的原因是,縮小芯片上元件尺寸的能力使得設計師能夠不斷提高處理器、存儲器等器件中的晶體管密度。由于晶體管越來越小,設計師可以在處理器中增加更多的功能單元,并在相同面積上實現更加復雜的架構。
由于這種更高的密度,像分支預測或亂序執行等技術在現代處理器中已經很普及,雖然它們非常耗用資源。這些技術提高了每周期執行指令數(IPC),即提高了指令吞吐量,這是影響處理器總體性能的兩大基本根源之一。更小的晶體管尺寸還可以支持更高的時鐘速率。當晶體管的柵極長度縮短1/k時,電路延時也可以減少同樣的量。隨著電路延時的減少,晶體管開關時間也相應縮短,因此時鐘速率可以提高k倍。處理器工作在更高頻率可以提供更高的性能,但需要付出一定的代價。
然而,現在設計遇到了一些實際的限制。隨著晶體管尺寸的進一步縮小,晶體管密度和芯片頻率的提高顯得非常有限,而影響越來越大。其中更高的功耗和更大的傳輸延時是最令人擔心的兩大因素,也是影響進一步發展的主要障礙。
芯片功耗
芯片功耗和相關的散熱問題正在成為硬件設計師面臨的一個巨大障礙。隨著晶體管數量的不斷增加,當前處理器在很小的面積上就需要相當大的能量。這意味著需要散發很高的功率密度。問題不僅在于晶體管的數量,高的工作頻率對功耗也有很大的影響,下面還會討論到。
為了對過去幾十年中這些參數的演變有一個印象,圖1顯示了在20年時間內Intel的x86架構中晶體管數量和工作頻率的增加情況,最早的數據來自80386架構——第一個32位x86處理器。
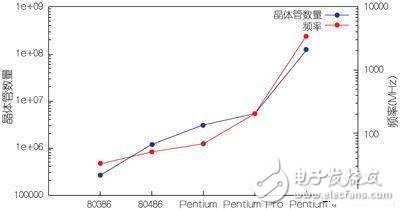
圖1:X86架構中的晶體管數量和頻率演變。
注意,上述兩個參數都是用對數刻度標示的,這也表明了它們進步幅度之大。在功耗方面,圖2顯示了這些處理器的典型功耗演變情況,這次采用的是線性刻度。
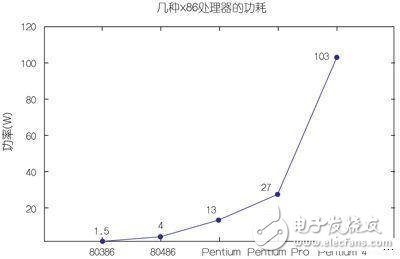
圖2:不同代X86處理器的功耗演變。
晶體管數量在持續增加,一些最新的Intel Core i7處理器中的晶體管數量已經超過22億個。功耗也在緩慢增加,高的可達130W,當然這取決于具體型號。然而,這些新處理器的時鐘頻率卻不再增加,保持在3.5GHz左右。
時鐘頻率停滯不前的原因之一是目前的集成電路已經達到功率密度的物理極限,產生的熱量已經達到芯片封裝能夠散發的極限,因此硬件設計師必須限制頻率的提高。Intel的確從未為功效而犧牲性能,但如今的物理限制使得他們只能在功耗上面做文章。
一些公式可以更好地展示頻率和晶體管數量是如何影響芯片功耗的。一些簡單的數學關系可以讓我們清楚地看出為什么這些參數在當前設計中是如此重要。
下列公式顯示了芯片功耗與工作頻率和其它系數的關系。
這是用于當前集成電路的主流半導體技術——CMOS技術的功耗表達式。公式的第一部分(加數)是芯片的動態功耗(也就是晶體管開關時由容性負載充放電引起的功耗),代表芯片執行的有用工作。A是活躍系數,代表每個時鐘周期中進行開關的晶體管比例(因為每個時鐘周期中并不是所有晶體管都必須開關);C是晶體管的容性負載;V是電壓;f是頻率。
公式中的第2個加數是由于短時間短路電流(ISC)引起的少量動態功耗,這個電流是在有限的上升或下降時間t內從晶體管電壓源流到地的電流。最后一個加數是靜態功耗,即由于漏電流(Ileak)引起的功耗,這也是唯一在加電,但不活動的電路中存在的功耗。這種功耗適用于整個電路,與晶體管狀態無關,因此該項中沒有活躍系數。
從公式的第一項可以看出為何功耗只是呈線性增加,而頻率呈對數增加,這是因為電壓是二次方的關系。
工程師能夠將這個電壓從5V減小到1V以下,從而幫助他們控制住功耗同時不降低性能。遺憾的是,許多因素是相互影響的,工程師必須不斷進行折衷。例如,想象一下我們想要通過降低最初設置在2V的電源電壓來減小芯片的動態功耗(只考慮公式中的第一項)。如果我們能夠將電源電壓降低到1.7V,雖然電壓只下降了15%,但功耗可以顯著下降28%.然而,降低電源電壓對電路的最大頻率和晶體管的閾值電壓(晶體管的導通電壓)有副作用。
在我們這個例子中,如果閾值電壓為0.5V,電路工作頻率為4GHz,那么為了保持相同的工作頻率,必須將閾值電壓降低到大約0.32V.然而,這樣做也許是不可行的,因為閾值電壓依賴于一些技術參數,當超出一定的范圍時,不改變半導體制造工藝是不可能繼續減小的。如果不改變閾值電壓,最大頻率將降低到3GHz,降幅為25%.
另一方面,即使你能夠降低電源電壓和閾值電壓并且不影響性能,但漏電流與閾值電壓呈指數依賴關系:
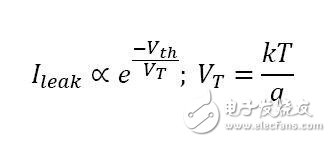
電壓VT是熱電壓,取決于絕對溫度T.k是玻爾茲曼常數,q是電子上的電荷量。在常溫時熱電壓值大約為30mV.當相比于熱電壓有較大的閾值電壓時,漏電流效應可以忽略,但當閾值電壓較小——大約在100mV左右時,漏電流效應就變得突出了。
另外,不僅熱電壓與溫度有關,閾值電壓通常也隨溫度變化而變化,這兩種變化將疊加在一起共同影響漏電流。漏電流增加意味著靜態功耗的增加,因此對于低電壓值而言,電壓降低技術存在一定的實用性限制。
圖3顯示了兩個不同溫度下的這些效應。T=300K的第一條曲線顯示了與閾值電壓的指數關系。T=330K的第二條曲線是考慮了閾值電壓隨溫度變化因素下的估計數據。這樣,橫坐標仍然代表標稱閾值電壓,但晶體管的實際閾值電壓因溫度效應而偏向更低的值,因此對漏電流有較大的影響。
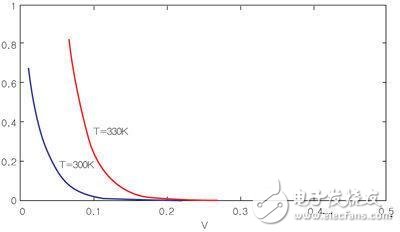
圖3:閾值電壓和溫度對漏電流的影響。
漏電流還與絕緣柵厚度有關。當采用非常薄的柵極電介質時,電子可以穿過絕緣層形成隧道效應,進而形成隧道電流,導致高功耗。鑒于使用32nm及以下工藝時的實際柵極長度,這種效應在當前半導體技術工藝中是非常重要的。
當然,處理器內核并不是芯片中唯一耗能的器件。比如內存也消耗相當大的能量,現代處理器專門開辟了大塊裸片區域來集成多級緩存。
工程師通常會應用多種設計技術來減少內存的漏電流或活動系數(功耗公式中的A系數),進而達到降低功耗的目的。
例如,緩存等級的層次化組織不僅可以改善數據訪問時間,而且有助于降低消耗的功率,因為更小更近的緩存所需能量比更大更遠的緩存要少。這種結構化解決方案在降低功耗的同時能保持性能不變。與這種想法類似,另外一個常用的解決方案是將內存組織成庫的形式來提高效率。這種情況下可以只激活正在訪問的庫,從而節省能量。
然而,追求更高性能并不總是正確的做事方式。有時以一定的吞吐量代價來降低功耗就足夠了。有些處理器專門用于特定的應用,它們總是做相同類型的運算,比如DSP.音頻處理、數字濾波器或數據壓縮算法是這些器件的典型應用,評估這些應用的指標是一次操作需要多少能量、這些處理器做這些運算需要花多長時間。
一個處理器如果在執行算法時一開始就比其它處理器花更多的時間但消耗更少的功率,那么最終就具有更高的能效值。衡量這種效率的一個指標是MIPS/W(每秒每瓦百萬指令數)。雖然必須關注指標MIPS,但一般來說具有更高MIPS/W的器件被認為具有更高的效率,這對嵌入式設備特別是電池供電設備來說尤其讓人感興趣。事實上,如今在服務器和數據中心領域人們更樂意使用更高能效的處理器。
漏電流還與絕緣柵厚度有關。當采用非常薄的柵極電介質時,電子可以穿過絕緣層形成隧道效應,進而形成隧道電流,導致高功耗。鑒于使用32nm及以下工藝時的實際柵極長度,這種效應在當前半導體技術工藝中是非常重要的。
當然,處理器內核并不是芯片中唯一耗能的器件。比如內存也消耗相當大的能量,現代處理器專門開辟了大塊裸片區域來集成多級緩存。
工程師通常會應用多種設計技術來減少內存的漏電流或活動系數(功耗公式中的A系數),進而達到降低功耗的目的。
例如,緩存等級的層次化組織不僅可以改善數據訪問時間,而且有助于降低消耗的功率,因為更小更近的緩存所需能量比更大更遠的緩存要少。這種結構化解決方案在降低功耗的同時能保持性能不變。與這種想法類似,另外一個常用的解決方案是將內存組織成庫的形式來提高效率。這種情況下可以只激活正在訪問的庫,從而節省能量。
然而,追求更高性能并不總是正確的做事方式。有時以一定的吞吐量代價來降低功耗就足夠了。有些處理器專門用于特定的應用,它們總是做相同類型的運算,比如DSP。音頻處理、數字濾波器或數據壓縮算法是這些器件的典型應用,評估這些應用的指標是一次操作需要多少能量、這些處理器做這些運算需要花多長時間。
一個處理器如果在執行算法時一開始就比其它處理器花更多的時間但消耗更少的功率,那么最終就具有更高的能效值。衡量這種效率的一個指標是MIPS/W(每秒每瓦百萬指令數)。雖然必須關注指標MIPS,但一般來說具有更高MIPS/W的器件被認為具有更高的效率,這對嵌入式設備特別是電池供電設備來說尤其讓人感興趣。事實上,如今在服務器和數據中心領域人們更樂意使用更高能效的處理器。
芯片的傳輸延時
限制晶體管密度提高和芯片工作頻率增加的另外一個主要因素是走線的傳輸延時。現代處理器中使用的GHz數量級高頻時鐘意味著一個時鐘周期不到一個納秒。這么短的周期時間正在成為影響信號傳播的一個問題。
減小芯片的特征尺寸將造成柵極長度和晶體管電容減小,從而有利于提高時鐘速率,克服容量范圍限制。但芯片上的走線由于更高的電阻和電容而變得越來越慢。走線的寬度和高度變小是走線面積縮小的根本原因,并導致更高的電阻。
由于走線表面積變小,與表面積有關的電容跟著降低,但相鄰走線之間的距離也在縮小,最終形成更高的耦合電容。耦合電容增加的速度大于表面電容減小的速度,因此抵消了表面電容減少效應,并形成了更高總體走線電容的組合效應。
走線傳輸延時直接正比于電阻與電容的乘積:Rw×Cw,因此隨著每一代縮小特征尺寸的新技術的推出,走線延時變得越來越長。隨著時鐘速率的加快和走線傳輸速度的變慢,信號可以傳輸的距離以及一個時鐘周期內可以到達的芯片面積將變小,最終導致通信范圍成為約束條件的新情況。
對于具體的微架構來說,這不會成為大問題,因為電路尺寸將以二次方的比例縮小。但為了充分利用更小的晶體管尺寸并獲得更高的IPC,設計師正在開發更為復雜的微架構,生成更深的流水線,增加更多的執行單元,并使用大的微架構化結構。現在,芯片上更高的通信延時將對尺寸甚至這些結構的布局和最大工作頻率造成實際的限制。
舉個例子,Intel Pentium 4中使用的錯誤預測流水線設計要求的級數是Pentium Ⅲ流水線的兩倍。由于具有更高的時鐘速率和走線延時,流水線必須劃分為更小的段,并且在每級流水線中做更少的工作。但走線延時變得如此之大,以致于Pentium 4流水線中有兩級是額外增加的,用于將信號從一級驅動到下一級,以便有足夠的時間去執行要求的運算,因為有很多的時鐘周期時間用在了信號抵達下一級上。
在ARM公司發布的高級微控制器總線架構(AMBA)規范中,可以看到走線延時如何影響設計的另一個類似例子。在第一版AMBA規范中引入、設計用于互連高性能系統模塊的高級系統總線(ASB)使用了雙向總線和主/從架構。
在第二版AMBA規范中,引入了高級高性能總線(AHB),用于改善對更高性能的支持,并替代ASB。在這個新的總線規范中,獨立于其它功能的雙向總線被替換為復用總線機制。這種修改初看起來似乎增加了不必要的走線和電路復雜性。但在很高性能系統中的走線延時效應使得有必要引入中繼驅動器(與Pentium 4例子中看到的一樣)。這在形成組合式復用總線的單向總線中是可行的,但在雙向總線中很難實現。
面臨的挑戰
我們已經看到有兩個主要的技術性限制在不斷影響摩爾定律和和處理器性能的持續改進。但技術在不斷發展。縮小特征尺寸有助于提高晶體管密度和頻率,而設計師也仍在設法縮小晶體管尺寸,單顆芯片上的晶體管數量有望超過10億個。
業界預測,半導體技術工藝將在2014年達到35nm柵極長度,但實際上從2011年開始就已經有人在用22nm工藝制造產品了。功耗和傳輸延時問題激勵著業界每個人去研究制造晶體管的新材料,而在現代處理器中已經在應用新的組織化和架構化解決方案。高k值氧化柵(k指的是材料的介電常數)正在替代用了幾十年的二氧化硅柵極電介質,它能實現更薄的絕緣層并更好地控制漏電流。
新的低k值電介質的使用使得減小耦合電容以及傳輸延時成為可能。實現單個大型單片內核的傳統微架構正在演變為更簡單的多內核微架構,后者允許占大部分的局部通信,從而避免了大的延時。
最近一些芯片制造商,如Intel公司,發布了三維集成電路。Intel最新的Ivy Bridge系列處理器作為Sandy Bridge系列的后繼產品,采用了新的三柵極(tri-gate)晶體管技術,在提升處理能力的同時可以降低所需的能耗。
使用3D晶體管替代以前的平面結構晶體管后,各級流水線可以彼此垂直堆疊,從而能夠有效地縮短塊與塊之間的距離,消除走線延時效應。據Intel介紹,公司的22nm 3D Tri-Gate晶體管功耗在相同時鐘頻率下不到32nm芯片上的平面晶體管的一半,超過了從一代工藝升級到下一代時通常所取得的效果。
多內核架構的發展非常迅速。例如,Tilera公司已經在單顆芯片上成功開發出首個100內核的處理器。為了達到這種集成度,Tilera將處理器與他們的設計師稱之為“瓦片(tile)”的通信開關組合在一起。通過組合這些瓦片,Tilera公司能夠搭建出一個形成網狀網的硅片。處理器一般通過總線互相連接,但隨著處理器數量的增加,這種總線很快變成了瓶頸。借助Tilera用瓦片平鋪出的網,每個處理器連接一個開關,它們可以像點到點網絡那樣相互通信。除此之外,每個瓦片可以獨立運行一個實時操作系統。或者你也可以將多個瓦片組合在一起,運行像SMP Linux那樣的操作系統。
目前業內正在研究開發令人稱奇的石墨烯晶體管,每個晶體管都是用一片僅一個原子厚度的碳制造的。理論上,這些晶體管支持非常高的工作頻率,可以高達1THz(1000GHz),甚至可以在柔性基板上制造這些晶體管。不過這種技術還面臨許多挑戰,我們可能還要等幾年才能看到這些先進技術實用化。
本文小結
目前業界面臨的問題是如何充分發揮這種巨大的并行處理能力。但嵌入式軟件行業已經在開發強大的工具來幫助構建新的、復雜的許多內核應用世界。
針對共享和分布式存儲架構的OpenMP和MPI建議、以及針對不同種類系統的并行編程制定的開放標準OpenCL(開放計算語言)都非常有前途。利用OpenGL可以為混合有多內核CPU、GPU甚至DSP的系統開發出合適的軟件。但最大的挑戰可能是改變編程人員的想法,使他們學會如何編寫出適合在這些系統運行的高度并行和可靠的軟件。












 工商網監
工商網監
評論