 電子發燒友App
電子發燒友App


Solr簡介
Solr是一個獨立的企業級搜索應用服務器,它對外提供類似于Web-service的API接口。用戶可以通過http請求,向搜索引擎服務器提交一定格式的XML文件,生成索引;也可以通過Http Get操作提出查找請求,并得到XML格式的返回結果。
要想知道solr的實現原理,首先得了解什么是全文檢索,solr的索引創建過程和索引搜索過程。
全文檢索
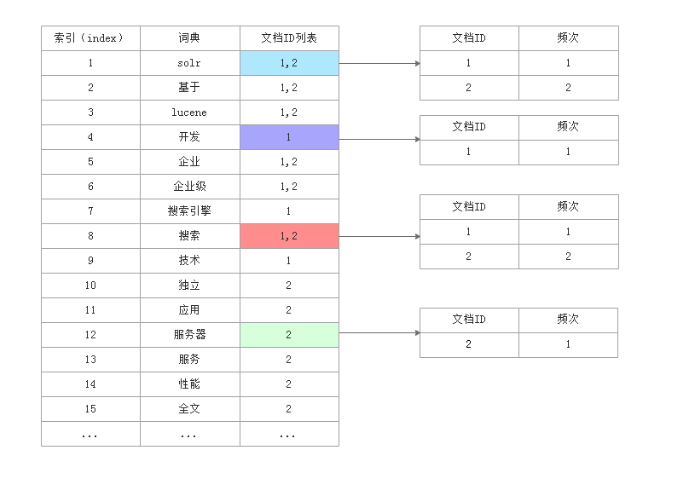
首先舉個例子:比如現在有5個文檔,我現在想從5個文檔中查找出包含“solr工作原理”的文檔,此時有兩種做法:
1.順序掃描法:對5個文檔依次查找,包含目標字段的文檔就記錄下來,最后查找的結果可能是在2,3文檔中,這種查找方式叫做順序掃描法。
順序掃描法在文檔數量較少的情況下,查找速度還是很快的,但是當文檔數量很多時,查找速度就差強人意了。
2.全文檢索:對文檔內容進行分詞,對分詞后的結果創建索引,然后通過對索引進行搜索的方式叫做全文檢索。
全文檢索就相當于根據偏旁部首或者拼音去查找字典,在文檔很多的情況,這種查找速度肯定比你一個一個文檔查找要快。
solr中的cache的實現原理
搭建過solr的人肯定對solrconf.xml不陌生,在《query》《/query》中有多個cache,比如filterCache、queryResultCache,documentCache。這個博客就是介紹這三個cache的意思、配置以及他們的使用。
我們直接看代碼,對于這三個cache的使用是在solrIndexSearcher中,他有下面的屬性
private final boolean cachingEnabled;//這個indexSearcher是否使用緩存
private final SolrCache《Query,DocSet》 filterCache;對應于filterCache
private final SolrCache《QueryResultKey,DocList》 queryResultCache;//對應于queryResultCache
private final SolrCache《Integer,Document》 documentCache;//對應于documentCache
private final SolrCache《String,UnInvertedField》 fieldValueCache;//這個稍后再說
在SolrIndexSearcher的構造方法中可以發現對上面的幾個cache的賦值:
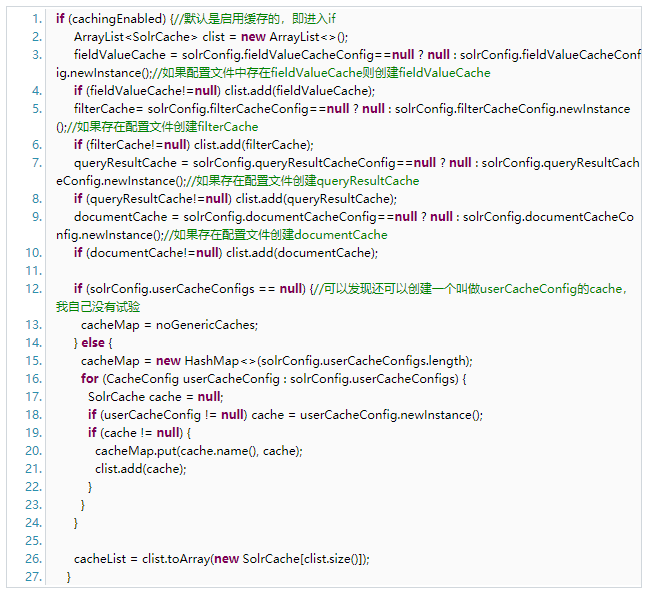
通過上面的代碼可以發現,如果在solrconf.xml中配置了對應的cache,就會在solrIndexSearcher中創建對應的cache。
solrconf.xml中cache的實現原理:
我們以《filterCache class=“solr.FastLRUCache” size=“512” initialSize=“512” autowarmCount=“0”/》這個為例:創建這個cache的實現類是FastLRUCache,他的實現原理就是封裝了concurrentHashMap,最大可以存放512個緩存的key,初始大小為512個,autoWarmCount這個稍后再說。在solr中默認有兩個cache,一個是剛才說的FastLRUCache,還有一個是LRUCache,他的實現原理是LinkedHashMap+同步,很明顯這個的性能要比前一個要差一些,所以可以將LRUCache都換為FastLRuCache。不過這兩個cahce都是基于lru算法的,貌似也不適合我們的需求,最好是lfu的,所以可以通過改變這些配置,使用一個基于lfu算法的cache,當然這個不是這篇博客的內容。我們先看一下這個FastLRUCache的實現:
1、初始化cache的方法:

在FastLruCache中還有一些put,get,clear這些顯而易見的方法(對生成的ConcurrentLRUCache對象操作),另外還有一個warm方法比較重要,我專門在一篇博客中寫他的作用。
接下來我們進入到ConcurrentLRUCache類中,看看他的實現。
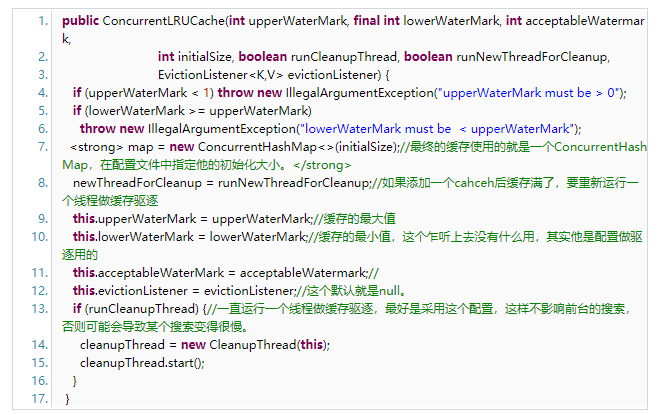
再看一下他的添加方法:

看到這里就明白了solr自帶的緩存的實現原理了。(markAndSweep方法我沒有完全看懂,不過不影響我們的理解)
在緩存中還有一個重要的方法是獲得這個緩存的使用情況: public NamedList getStatistics() 方法,返回一個類似于map的結構,我們看看FastLRUCache的代碼:
public NamedList getStatistics() {
NamedList《Serializable》 lst = new SimpleOrderedMap《》();
if (cache == null) return lst;
ConcurrentLRUCache.Stats stats = cache.getStats();//這里的stats就是用來記錄緩存使用的情況的,比如大小,添加次數,訪問次數、查詢未命中次數,驅逐次數。
long lookups = stats.getCumulativeLookups();//這個是查詢總的次數,包括命中的次數+未命中的次數
long hits = stats.getCumulativeHits();//查詢的有效命中次數
long inserts = stats.getCumulativePuts();//添加緩存的次數
long evictions = stats.getCumulativeEvictions();//累計的驅逐次數
long size = stats.getCurrentSize();//大小
long clookups = 0;
long chits = 0;
long cinserts = 0;
long cevictions = 0;
// NOTE: It is safe to iterate on a CopyOnWriteArrayList
for (ConcurrentLRUCache.Stats statistiscs : statsList) {//這個是對于多個SolrIndexSearcher之間的統計,不過現在我做測試發現并沒有開啟,也就是統計的還是一個SolrIndexSearcher生存期間的緩存使用情況,
clookups += statistiscs.getCumulativeLookups();
chits += statistiscs.getCumulativeHits();
cinserts += statistiscs.getCumulativePuts();
cevictions += statistiscs.getCumulativeEvictions();
}
lst.add(“lookups”, lookups);//返回的結果包括這些:
lst.add(“hits”, hits);
lst.add(“hitratio”, calcHitRatio(lookups, hits));
lst.add(“inserts”, inserts);
lst.add(“evictions”, evictions);
lst.add(“size”, size);
lst.add(“warmupTime”, warmupTime);
lst.add(“cumulative_lookups”, clookups);
lst.add(“cumulative_hits”, chits);
lst.add(“cumulative_hitratio”, calcHitRatio(clookups, chits));
lst.add(“cumulative_inserts”, cinserts);
lst.add(“cumulative_evictions”, cevictions);
if (showItems != 0) {//showItem的意思是將多少個緩存的key展示出來,展示最近搜索的,
Map items = cache.getLatestAccessedItems( showItems == -1 ? Integer.MAX_VALUE : showItems );
for (Map.Entry e : (Set 《Map.Entry》)items.entrySet()) {
Object k = e.getKey();
Object v = e.getValue();
String ks = “item_” + k;
String vs = v.toString();
lst.add(ks,vs);
}
}
return lst;
}










 工商網監
工商網監
評論