 電子發(fā)燒友App
電子發(fā)燒友App


Solr的工作原理以及全文檢索實(shí)現(xiàn)原理
Solr 是一個(gè)企業(yè)級(jí)開源搜索引擎平臺(tái), Solr用Java編寫,起源自Apache的Lucene項(xiàng)目。主要功能包括全文本搜索,高亮命中,分面搜索,實(shí)時(shí)索引,動(dòng)態(tài)集群,數(shù)據(jù)庫集成,NoSQL功能以及富文本(比如Word,PDF)處理。Solr提供了分布式搜索和索引復(fù)制功能,具備高度可擴(kuò)展性和容錯(cuò)功能。Solr是當(dāng)今最流行的企業(yè)級(jí)索引引擎。 Solr用Java編寫,運(yùn)行在獨(dú)立的全文搜索服務(wù)器上。Solr使用Lucene Java索引庫作為全文索引和搜索的核心,并且提供了類REST的HTTP/XML 和 JSON API,絕大多數(shù)流行的編程語言都可以使用。Solr具有強(qiáng)大的外部配置設(shè)置,無需任何Java代碼就可以定制何種類型的應(yīng)用。Solr使用了插件式層次機(jī)構(gòu),支持更加高級(jí)的定制化。
工作原理
solr是基于Lucence開發(fā)的企業(yè)級(jí)搜索引擎技術(shù),而lucence的原理是倒排索引。那么什么是倒排索引呢?接下來我們就介紹一下lucence倒排索引原理。
假設(shè)有兩篇文章1和2:
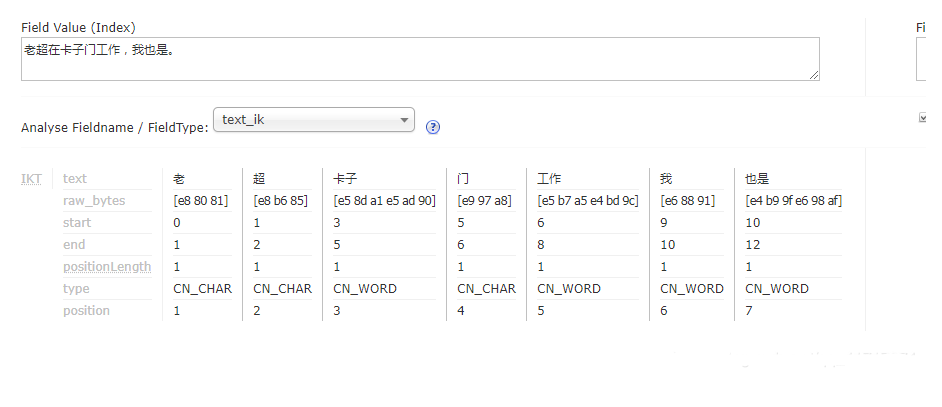
文章1的內(nèi)容為:老超在卡子門工作,我也是。
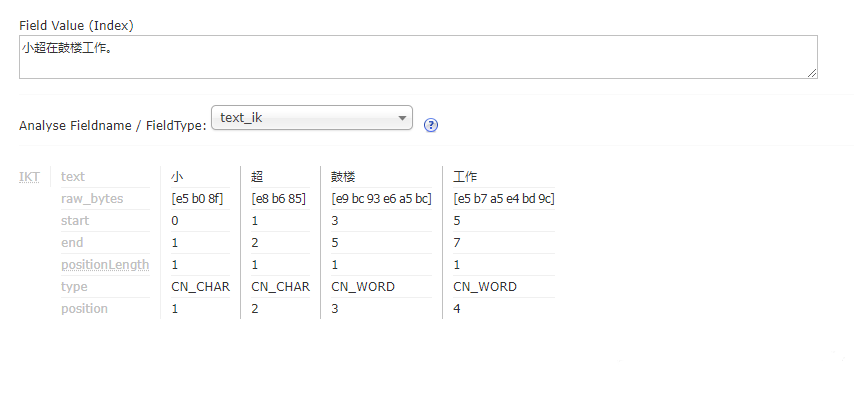
文章2的內(nèi)容為:小超在鼓樓工作。
由于lucence是基于關(guān)鍵詞索引查詢的,那我們首先要取得這兩篇文章的關(guān)鍵詞。如果我們把文章看成一個(gè)字符串,我們需要取得字符串中的所有單詞,即分詞。分詞時(shí),忽略”在“、”的“之類的沒有意義的介詞,以及標(biāo)點(diǎn)符號(hào)可以過濾。
我們使用Ik Analyzer實(shí)現(xiàn)中文分詞,分詞之后結(jié)果為:
文章1:
文章2:
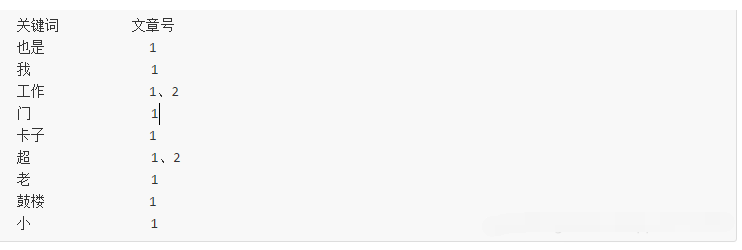
接下來,有了關(guān)鍵詞后,我們就可以建立倒排索引了。上面的對(duì)應(yīng)關(guān)系是:“文章號(hào)”對(duì)“文章中所有關(guān)鍵詞”。倒排索引把這個(gè)關(guān)系倒過來,變成: “關(guān)鍵詞”對(duì)“擁有該關(guān)鍵詞的所有文章號(hào)”。
文章1、文章2經(jīng)過倒排后變成:
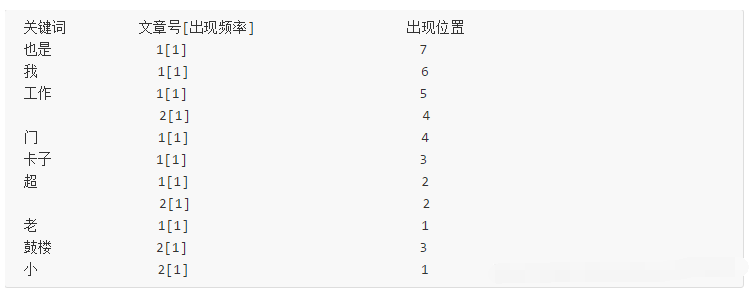
通常僅知道關(guān)鍵詞在哪些文章中出現(xiàn)還不夠,我們還需要知道關(guān)鍵詞在文章中出現(xiàn)次數(shù)和出現(xiàn)的位置,通常有兩種位置:
a.字符位置,即記錄該詞是文章中第幾個(gè)字符(優(yōu)點(diǎn)是關(guān)鍵詞亮顯時(shí)定位快);
b.關(guān)鍵詞位置,即記錄該詞是文章中第幾個(gè)關(guān)鍵詞(優(yōu)點(diǎn)是節(jié)約索引空間、詞組(phase)查詢快),lucene中記錄的就是這種位置。
加上出現(xiàn)頻率和出現(xiàn)位置信息后,我們的索引結(jié)構(gòu)變?yōu)椋?/p>
實(shí)現(xiàn)時(shí),lucene將上面三列分別作為詞典文件(Term Dictionary)、頻率文件(frequencies)、位置文件 (positions)保存。其中詞典文件不僅保存有每個(gè)關(guān)鍵詞,還保留了指向頻率文件和位置文件的指針,通過指針可以找到該關(guān)鍵字的頻率信息和位置信息。
全文檢索實(shí)現(xiàn)原理
solr是一個(gè)獨(dú)立的企業(yè)級(jí)搜索應(yīng)用服務(wù)器,它對(duì)外t提供類似于web-service的api接口。用戶可以通過http請求,向搜索引擎服務(wù)器提交一定格式的xml文件,生成索引。;
也可以通過http get操作提出查詢的請求,得到xml/json格式的返回結(jié)果
Lucene是一個(gè)高效的,基于Java的全文檢索庫。
所以在了解Lucene之前要費(fèi)一番工夫了解一下全文檢索。
那么什么叫做全文檢索呢?這要從我們生活中的數(shù)據(jù)說起。
我們生活中的數(shù)據(jù)總體分為兩種:結(jié)構(gòu)化數(shù)據(jù)和非結(jié)構(gòu)化數(shù)據(jù)。
結(jié)構(gòu)化數(shù)據(jù):指具有固定格式或有限長度的數(shù)據(jù),如數(shù)據(jù)庫,元數(shù)據(jù)等。
非結(jié)構(gòu)化數(shù)據(jù):指不定長或無固定格式的數(shù)據(jù),如郵件,word文檔等。
當(dāng)然有的地方還會(huì)提到第三種,半結(jié)構(gòu)化數(shù)據(jù),如XML,HTML等,當(dāng)根據(jù)需要可按結(jié)構(gòu)化數(shù)據(jù)來處理,也可抽取出純文本按非結(jié)構(gòu)化數(shù)據(jù)來處理。
非結(jié)構(gòu)化數(shù)據(jù)又一種叫法叫全文數(shù)據(jù)。
按照數(shù)據(jù)的分類,搜索也分為兩種:
對(duì)結(jié)構(gòu)化數(shù)據(jù)的搜索:如對(duì)數(shù)據(jù)庫的搜索,用SQL語句。再如對(duì)元數(shù)據(jù)的搜索,如利用windows搜索對(duì)文件名,類型,修改時(shí)間進(jìn)行搜索等。
對(duì)非結(jié)構(gòu)化數(shù)據(jù)的搜索:如利用windows的搜索也可以搜索文件內(nèi)容,Linux下的grep命令,再如用Google和百度可以搜索大量內(nèi)容數(shù)據(jù)。
對(duì)非結(jié)構(gòu)化數(shù)據(jù)也即對(duì)全文數(shù)據(jù)的搜索主要有兩種方法:
一種是順序掃描法(Serial Scanning):所謂順序掃描,比如要找內(nèi)容包含某一個(gè)字符串的文件,就是一個(gè)文檔一個(gè)文檔的看,對(duì)于每一個(gè)文檔,從頭看到尾,如果此文檔包含此字符串,則此文檔為我們要找的文件,接著看下一個(gè)文件,直到掃描完所有的文件。如利用windows的搜索也可以搜索文件內(nèi)容,只是相當(dāng)?shù)穆H绻阌幸粋€(gè)80G硬盤,如果想在上面找到一個(gè)內(nèi)容包含某字符串的文件,不花他幾個(gè)小時(shí),怕是做不到。Linux下的grep命令也是這一種方式。大家可能覺得這種方法比較原始,但對(duì)于小數(shù)據(jù)量的文件,這種方法還是最直接,最方便的。但是對(duì)于大量的文件,這種方法就很慢了。
有人可能會(huì)說,對(duì)非結(jié)構(gòu)化數(shù)據(jù)順序掃描很慢,對(duì)結(jié)構(gòu)化數(shù)據(jù)的搜索卻相對(duì)較快(由于結(jié)構(gòu)化數(shù)據(jù)有一定的結(jié)構(gòu)可以采取一定的搜索算法加快速度),那么把我們的非結(jié)構(gòu)化數(shù)據(jù)想辦法弄得有一定結(jié)構(gòu)不就行了嗎?
這種想法很天然,卻構(gòu)成了全文檢索的基本思路,也即將非結(jié)構(gòu)化數(shù)據(jù)中的一部分信息提取出來,重新組織,使其變得有一定結(jié)構(gòu),然后對(duì)此有一定結(jié)構(gòu)的數(shù)據(jù)進(jìn)行搜索,從而達(dá)到搜索相對(duì)較快的目的。
這部分從非結(jié)構(gòu)化數(shù)據(jù)中提取出的然后重新組織的信息,我們稱之索引。
這種說法比較抽象,舉幾個(gè)例子就很容易明白,比如字典,字典的拼音表和部首檢字表就相當(dāng)于字典的索引,對(duì)每一個(gè)字的解釋是非結(jié)構(gòu)化的,如果字典沒有音節(jié)表和部首檢字表,在茫茫辭海中找一個(gè)字只能順序掃描。然而字的某些信息可以提取出來進(jìn)行結(jié)構(gòu)化處理,比如讀音,就比較結(jié)構(gòu)化,分聲母和韻母,分別只有幾種可以一一列舉,于是將讀音拿出來按一定的順序排列,每一項(xiàng)讀音都指向此字的詳細(xì)解釋的頁數(shù)。我們搜索時(shí)按結(jié)構(gòu)化的拼音搜到讀音,然后按其指向的頁數(shù),便可找到我們的非結(jié)構(gòu)化數(shù)據(jù)——也即對(duì)字的解釋。
這種先建立索引,在對(duì)索引進(jìn)行搜索的過程就叫做全文檢索。
全文檢索大體分為2個(gè)過程,索引創(chuàng)建和搜索索引
1.索引創(chuàng)建:將現(xiàn)實(shí)世界中的所有結(jié)構(gòu)化和非結(jié)構(gòu)化數(shù)據(jù)提取信息,創(chuàng)建索引的過程
2.索引索引:就是得到用戶查詢的請求,搜索創(chuàng)建的索引,然后返回結(jié)果的過程
于是全文檢索就存在3個(gè)重要的問題:
1. 索引里面究竟存了什么東西?
2.如何創(chuàng)建索引?
3.如何對(duì)索引進(jìn)行搜索?
下面我們順序?qū)γ總€(gè)個(gè)問題進(jìn)行研究。
二、索引里面究竟存些什么
索引里面究竟需要存些什么呢?
首先我們來看為什么順序掃描的速度慢:
其實(shí)是由于我們想要搜索的信息和非結(jié)構(gòu)化數(shù)據(jù)中所存儲(chǔ)的信息不一致造成的。
非結(jié)構(gòu)化數(shù)據(jù)中所存儲(chǔ)的信息是每個(gè)文件包含哪些字符串,也即已知文件,欲求字符串相對(duì)容易,也即是從文件到字符串的映射。而我們想搜索的信息是哪些文件包含此字符串,也即已知字符串,欲求文件,也即從字符串到文件的映射。兩者恰恰相反。于是如果索引總能夠保存從字符串到文件的映射,則會(huì)大大提高搜索速度。
由于從字符串到文件的映射是文件到字符串映射的反向過程,于是保存這種信息的索引稱為反向索引。
反向索引的所保存的信息一般如下:
假設(shè)我的文檔集合里面有100篇文檔,為了方便表示,我們?yōu)槲臋n編號(hào)從1到100,得到下面的結(jié)構(gòu)
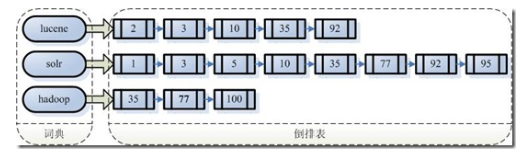
左邊保存的是一系列字符串,稱為詞典。
每個(gè)字符串都指向包含此字符串的文檔(Document)鏈表,此文檔鏈表稱為倒排表(Posting List)。
有了索引,便使保存的信息和要搜索的信息一致,可以大大加快搜索的速度。
比如說,我們要尋找既包含字符串“l(fā)ucene”又包含字符串“solr”的文檔,我們只需要以下幾步:
1. 取出包含字符串“l(fā)ucene”的文檔鏈表。
2. 取出包含字符串“solr”的文檔鏈表。
3. 通過合并鏈表,找出既包含“l(fā)ucene”又包含“solr”的文件。

看到這個(gè)地方,有人可能會(huì)說,全文檢索的確加快了搜索的速度,但是多了索引的過程,兩者加起來不一定比順序掃描快多少。的確,加上索引的過程,全文檢索不一定比順序掃描快,尤其是在數(shù)據(jù)量小的時(shí)候更是如此。而對(duì)一個(gè)很大量的數(shù)據(jù)創(chuàng)建索引也是一個(gè)很慢的過程。
然而兩者還是有區(qū)別的,順序掃描是每次都要掃描,而創(chuàng)建索引的過程僅僅需要一次,以后便是一勞永逸的了,每次搜索,創(chuàng)建索引的過程不必經(jīng)過,僅僅搜索創(chuàng)建好的索引就可以了。
這也是全文搜索相對(duì)于順序掃描的優(yōu)勢之一:一次索引,多次使用。
三、如何創(chuàng)建索引
全文檢索的索引創(chuàng)建過程一般有以下幾步:
第一步:一些要索引的原文檔(Document)。
為了方便說明索引創(chuàng)建過程,這里特意用兩個(gè)文件為例:
文件一:Students should be allowed to go out with their friends, but not allowed to drink beer.
文件二:My friend Jerry went to school to see his students but found them drunk which is not allowed.
第二步:將原文檔傳給分次組件(Tokenizer)。
分詞組件(Tokenizer)會(huì)做以下幾件事情(此過程稱為Tokenize):
1. 將文檔分成一個(gè)一個(gè)單獨(dú)的單詞。
2. 去除標(biāo)點(diǎn)符號(hào)。
3. 去除停詞(Stop word)。
所謂停詞(Stop word)就是一種語言中最普通的一些單詞,由于沒有特別的意義,因而大多數(shù)情況下不能成為搜索的關(guān)鍵詞,因而創(chuàng)建索引時(shí),這種詞會(huì)被去掉而減少索引的大小。
英語中挺詞(Stop word)如:“the”,“a”,“this”等。
對(duì)于每一種語言的分詞組件(Tokenizer),都有一個(gè)停詞(stop word)集合。
經(jīng)過分詞(Tokenizer)后得到的結(jié)果稱為詞元(Token)。
在我們的例子中,便得到以下詞元(Token):
“Students”,“allowed”,“go”,“their”,“friends”,“allowed”,“drink”,“beer”,“My”,“friend”,“Jerry”,“went”,“school”,“see”,“his”,“students”,“found”,“them”,“drunk”,“allowed”。
第三步:將得到的詞元(Token)傳給語言處理組件(Linguistic Processor)。
語言處理組件(linguistic processor)主要是對(duì)得到的詞元(Token)做一些同語言相關(guān)的處理。
對(duì)于英語,語言處理組件(Linguistic Processor)一般做以下幾點(diǎn):
1. 變?yōu)樾懀↙owercase)。
2. 將單詞縮減為詞根形式,如“cars”到“car”等。這種操作稱為:stemming。
3. 將單詞轉(zhuǎn)變?yōu)樵~根形式,如“drove”到“drive”等。這種操作稱為:lemmatization
第四步:將得到的詞(Term)傳給索引組件(Indexer)。等等
總而言之
1. 索引過程:
1) 有一系列被索引文件
2) 被索引文件經(jīng)過語法分析和語言處理形成一系列詞(Term)。
3) 經(jīng)過索引創(chuàng)建形成詞典和反向索引表。
4) 通過索引存儲(chǔ)將索引寫入硬盤。
2. 搜索過程:
a) 用戶輸入查詢語句。
b) 對(duì)查詢語句經(jīng)過語法分析和語言分析得到一系列詞(Term)。
c) 通過語法分析得到一個(gè)查詢樹。
d) 通過索引存儲(chǔ)將索引讀入到內(nèi)存。
e) 利用查詢樹搜索索引,從而得到每個(gè)詞(Term)的文檔鏈表,對(duì)文檔鏈表進(jìn)行交,差,并得到結(jié)果文檔。
f) 將搜索到的結(jié)果文檔對(duì)查詢的相關(guān)性進(jìn)行排序。
g) 返回查詢結(jié)果給用戶。













 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論