 電子發燒友App
電子發燒友App


索引創建和搜索過程
1.創建索引
舉例子:
文檔一:solr是基于Lucene開發的企業級搜索引擎技術
文檔二:Solr是一個獨立的企業級搜索應用服務器,Solr是一個高性能,基于Lucene的全文搜索服務器
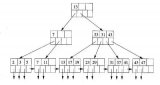
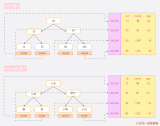
首先經過分詞器分詞,solr會為分詞后的結果(詞典)創建索引,然后將索引和文檔id列表對應起來,如下圖所示:
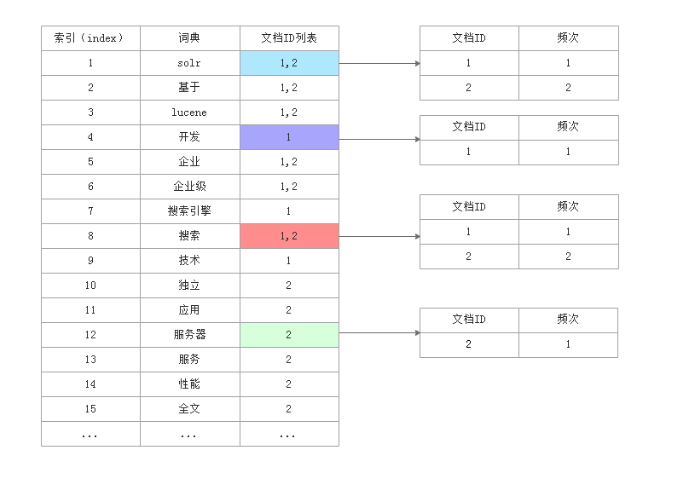
比如:solr在文檔1和文檔2中都有出現,所以對應的文檔ID列表中既包含文檔1的ID也包含文檔2的ID,文檔ID列表對應到具體的文檔,并體現該詞典在該文檔中出現的頻次,頻次越多說明權重越大,權重越大搜索的結果就會排在前面。
solr內部會對分詞的結果做如下處理:
1.去除停詞和標點符號,例如英文的this,that等, 中文的“的”,“一”等沒有特殊含義的詞
2.會將所有的大寫英文字母轉換成小寫,方便統一創建索引和搜索索引
3.將復數形式轉為單數形式,比如students轉為student,也是方便統一創建索引和搜索索引
2.索引搜索過程
知道了創建索引的過程,那么根據索引進行搜索就變得簡單了。
1.用戶輸入搜索條件
2.對搜索條件進行分詞處理
3.根據分詞的結果查找索引
4.根據索引找到文檔ID列表
5.根據文檔ID列表找到具體的文檔,根據出現的頻次等計算權重,最后將文檔列表按照權重排序返回
使用SolrJ管理索引庫
使用SolrJ可以實現索引庫的增刪改查操作。
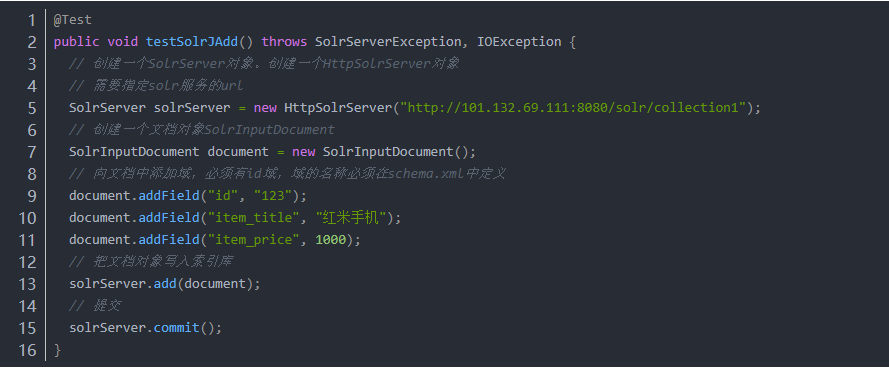
3.1 添加文檔
第一步:把solrJ的jar包添加到工程中。
第二步:創建一個SolrServer,使用HttpSolrServer創建對象。
第三步:創建一個文檔對象SolrInputDocument對象。
第四步:向文檔中添加域。必須有id域,域的名稱必須在schema.xml中定義。
第五步:把文檔添加到索引庫中。
第六步:提交。
3.2 刪除文檔
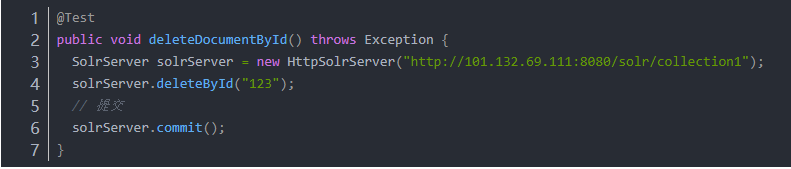
3.2.1 根據id刪除
第一步:創建一個SolrServer對象。
第二步:調用SolrServer對象的根據id刪除的方法。
第三步:提交。
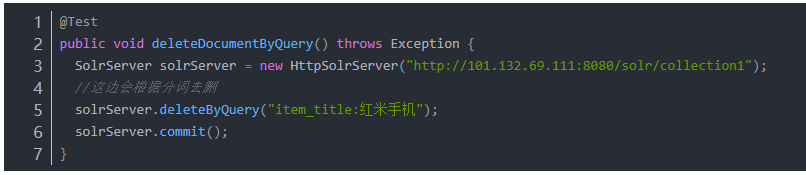
3.2.2 根據查詢刪除
3.3 查詢索引庫
第一步:創建一個SolrServer對象
第二步:創建一個SolrQuery對象。
3 向SolrQuery中添加查詢條件、過濾條件。。。
第四步:執行查詢。得到一個Response對象。
5 取查詢結果。
第六步:遍歷結果并打印。
3.3.1 簡單查詢
3.3.2 帶高亮顯示
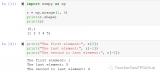
@Test
public void searchDocumet() throws Exception {
// 創建一個SolrServer對象
SolrServer solrServer = new HttpSolrServer(“http://101.132.69.111:8080/solr/collection1”);
// 創建一個SolrQuery對象
SolrQuery query = new SolrQuery();
// 設置查詢條件、過濾條件、分頁條件、排序條件、高亮
// query.set(“q”, “*:*”);
query.setQuery(“手機”);
// 分頁條件
query.setStart(0);
query.setRows(30);
// 設置默認搜索域
query.set(“df”, “item_keywords”);
// 設置高亮
query.setHighlight(true);
// 高亮顯示的域
query.addHighlightField(“item_title”);
query.setHighlightSimplePre(“《div》”);
query.setHighlightSimplePost(“《/div》”);
// 執行查詢,得到一個Response對象
QueryResponse response = solrServer.query(query);
// 取查詢結果
SolrDocumentList solrDocumentList = response.getResults();
// 取查詢結果總記錄數
System.out.println(“查詢結果總記錄數:” + solrDocumentList.getNumFound());
for (SolrDocument solrDocument : solrDocumentList) {
System.out.println(solrDocument.get(“id”));
// 取高亮顯示
Map《String, Map《String, List《String》》》 highlighting = response.getHighlighting();
List《String》 list = highlighting.get(solrDocument.get(“id”)).get(“item_title”);
String itemTitle = “”;
if (list != null && list.size() 》 0) {
itemTitle = list.get(0);
} else {
itemTitle = (String) solrDocument.get(“item_title”);
}
System.out.println(itemTitle);
System.out.println(solrDocument.get(“item_sell_point”));
System.out.println(solrDocument.get(“item_price”));
System.out.println(solrDocument.get(“item_image”));
System.out.println(solrDocument.get(“item_category_name”));
System.out.println(“=============================================”);
}
}
4. Solr服務器中的后臺數據處理
這個其實是通過圖形界面操作,只需手動填寫查詢條件,不需要進行代碼處理。但是實際項目開發中,還是需要進行代碼編寫的。
6
4.1 solr的基礎語法
q 查詢的關鍵字,此參數最為重要,例如,q=id:1,默認為q=*:*,
fq (filter query)過慮查詢,提供一個可選的篩選器查詢。
返回在q查詢符合結果中同時符合的fq條件的查詢結果
sort 排序方式,例如id desc 表示按照 “id” 降序
start 返回結果的第幾條記錄開始,一般分頁用,默認0開始
rows 指定返回結果最多有多少條記錄,默認值為 10,配合start實現分頁
fl 指定返回哪些字段,用逗號或空格分隔,注意:字段區分大小寫,例如,fl= id,title,sort
df 默認的查詢字段,一般默認指定
wt (writer type)指定輸出格式,有 xml, json, php等
indent 返回的結果是否縮進,默認關閉
hl 高亮
hl.fl 設定高亮顯示的字段
hl.requireFieldMatch 如果置為true,除非用hl.fl指定了該字段,查詢結果才會被高亮。它的默認值是false。
hl.usePhraseHighlighter 如果一個查詢中含有短語(引號框起來的)那么會保證一定要完全匹配短語的才會被高亮。
hl.highlightMultiTerm如果使用通配符和模糊搜索,那么會確保與通配符匹配的term會高亮。默認為false,同時hl.usePhraseHighlighter要為true。
hl.fragsize 返回的最大字符數。默認是100.如果為0,那么該字段不會被fragmented且整個字段的值會被返回。















 工商網監
工商網監
評論