 電子發(fā)燒友App
電子發(fā)燒友App


Ice Lake是Intel下一代平臺(tái)的架構(gòu)代號(hào),隨著臺(tái)北電腦展上的演示,它終于揭下來神秘的面紗。而前不久Intel內(nèi)部的第二季度財(cái)報(bào)會(huì)議上,CEO已經(jīng)宣布Ice Lake處理器已經(jīng)正式向OEM廠商出貨,戴爾方面也迅速行動(dòng),延期了一個(gè)月多的、采用新Ice Lake處理器的XPS 13 7390也迅速上架接受預(yù)定并將于近日發(fā)貨。這意味著Intel的第一代量產(chǎn)級(jí)10nm產(chǎn)品(不算Cannon Lake唯一的那款10nm i3)終于要在市場(chǎng)上亮相了,在此之際,小編編譯、整理了目前有關(guān)于Ice Lake架構(gòu)的相關(guān)解析文章,探尋其背后的改進(jìn)之處。
繼上一次Intel更新他們的桌面級(jí)處理器的架構(gòu)已經(jīng)過去了將近5年的時(shí)間了,不得不說,Skylake是一代非常成功的架構(gòu),也可能是從P6以來Intel使用時(shí)間最長(zhǎng)的一代處理器架構(gòu),支撐Intel走到現(xiàn)在還在主流和服務(wù)器市場(chǎng)上面占據(jù)著上風(fēng)。
首先我們要理清一點(diǎn),Ice Lake是整個(gè)處理器架構(gòu)的代號(hào),而現(xiàn)在的Intel處理器架構(gòu)中包括了內(nèi)核、GPU、以及Uncore部分的其他IO單元,所以本文并不只是針對(duì)CPU的內(nèi)核微架構(gòu)進(jìn)行解析,而是對(duì)于整個(gè)體系結(jié)構(gòu)。
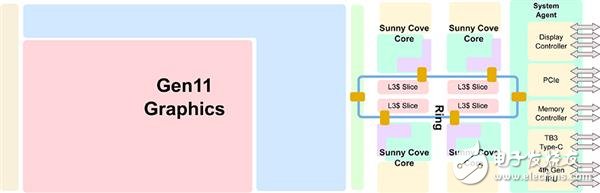
Ice Lake處理器結(jié)構(gòu)圖Sunny Cove內(nèi)核微架構(gòu):IPC平均提升18%

Sunny Cove內(nèi)核結(jié)構(gòu)圖前端緩沖區(qū):加大加大加大
x86處理器的內(nèi)核主要可以簡(jiǎn)單地分成兩個(gè)部分,前端部分與后端執(zhí)行部分,前端部分主要完成“取指譯碼”的工作,后端主要為指令的具體執(zhí)行單元,前后端之間有緩沖區(qū),用于存放解譯融合完畢的微指令。Intel很早就在內(nèi)核中引入了“微指令融合”的技術(shù)來提高效率,融合過的微指令會(huì)進(jìn)入緩沖區(qū)然后被分配給后端執(zhí)行部分進(jìn)行具體的執(zhí)行。Intel目前認(rèn)為,如今程序更多的瓶頸位于訪存和前端指令分派上,Sunny Cove的前端部分改進(jìn)就體現(xiàn)了這一理念,所以這次緩沖區(qū)就被擴(kuò)大了不少。
緩沖區(qū)部分對(duì)比架構(gòu)HaswellSkylakeIce Lake亂序重排緩沖區(qū)192224352訪存Load隊(duì)列大小7272128訪存Store隊(duì)列大小425672超 能 網(wǎng) 制 作
可以看到Intel這次把亂序重排緩沖區(qū)(ReOrder Buffer,主要是用于亂序執(zhí)行后將執(zhí)行的微指令根據(jù)原本順序提交的指令緩沖區(qū))大小做到了可以容納352條微指令,直接提升了128條/57%之多,而Haswell到Skylake才僅僅提升了32條。同樣在訪存上面也進(jìn)行了不小的提升,Load(加載)隊(duì)列增加了56,Store(存儲(chǔ))隊(duì)列增加了16,比Haswell到Skylake的改變都明顯要多。
緩存對(duì)比架構(gòu)HaswellSkylakeIce Lake單核心一級(jí)數(shù)據(jù)緩存大小32KB32KB48KB單核心一級(jí)指令緩存大小32KB32KB32KB單核心二級(jí)緩存大小256KB256KB512KB微指令緩存1.5K μOPS1.5K μOPS2.25K μOPS超 能 網(wǎng) 制 作
再來看緩存部分,新的內(nèi)核終于增加了萬(wàn)年沒變動(dòng)過的一級(jí)數(shù)據(jù)緩存,從32KB到48KB,雖然只增加了12KB,但是要知道,32KB的一級(jí)指令緩存+32KB的一級(jí)數(shù)據(jù)緩存的設(shè)計(jì),從Core系列的第一代架構(gòu)——Core微架構(gòu)上面就開始使用了,一直沿用到現(xiàn)在,同時(shí)一級(jí)數(shù)據(jù)緩存的帶寬也增加了。而每個(gè)內(nèi)核附帶的二級(jí)緩存直接提升一倍,達(dá)到512KB的大小,這也是從Nehalem架構(gòu)把二級(jí)緩存內(nèi)置進(jìn)每個(gè)核心、單獨(dú)設(shè)立共享L3緩存以來在內(nèi)核緩存上發(fā)生的最大幅度變動(dòng)了。

Skylake與Sunny Cove內(nèi)核架構(gòu)對(duì)比圖,左Skylake,右Sunny Cove
前端部分的改進(jìn)較小,主要是改進(jìn)了預(yù)取器與分支預(yù)測(cè)器的性能,增加了微指令緩存的大小使得其能夠滿足每周期5(6)指令的發(fā)射。
后端:更寬

上Skylake,下Icelake,注意看Port
后端也有不小的改變,Sunny Cove的執(zhí)行端口相比Skylake多了兩個(gè),達(dá)到了10個(gè)之多。并且端口的用途更為精細(xì)化,有專門用于讀取和存儲(chǔ)地址的端口,并且專用于存取數(shù)據(jù)的端口數(shù)量均為兩個(gè)。

然后在執(zhí)行單元中,Sunny Cove新增了支持AVX-512指令的單元,其實(shí)這類單元在Skylake-Server上便已經(jīng)加入,同時(shí)引入的還有Cannon Lake上面加入的iDIV這個(gè)硬件整數(shù)除法器,同時(shí)還加入了新的MulHi單元,專用于乘法指令的處理。
AVX-512計(jì)算單元的引入使得Sunny Cove內(nèi)核一次可以處理1條512-bit的指令或者2個(gè)256-bit的指令。
內(nèi)核互聯(lián)方面,桌面級(jí)Ice Lake仍將采用Ringbus也就是環(huán)形總線的設(shè)計(jì),而服務(wù)器端將延續(xù)Skylake-Server的Mesh總線設(shè)計(jì)。
指令集與AI加速
指令集隨著新單元的加入也同時(shí)進(jìn)行了擴(kuò)充,在加密解密、AI加速、通用計(jì)算、特定計(jì)算等方面都新加入了不少指令,尤其是AVX-512指令集。
對(duì)于近幾年大熱門的人工智能,Intel一方面在Uncore部分加入了自家的“高斯網(wǎng)絡(luò)加速器(Gaussian Network Accelerator)”這樣類似于手機(jī)SoC上面常見的AI硬件加速電路,還通過引入AVX512VNNI指令集,使用AVX-512單元來進(jìn)行AI相關(guān)的加速計(jì)算,Intel將這種加速稱為“DL(Deep Learning) Boost”。這是一種很聰明的取巧辦法,專用計(jì)算單元的引入可以保證一定的加速性能,而新指令集的加入同時(shí)也可以更加充分地利用上新的CPU特性。
加密解密指令集上面的改動(dòng)諸如AES的吞吐量加大、加入新的針對(duì)SHA算法的一系列指令等,總之在編譯器進(jìn)行適當(dāng)優(yōu)化的前提下,Ice Lake的加密解密性能是比Skylake強(qiáng)不少的。
小結(jié)
簡(jiǎn)單歸納一下Sunny Cove微架構(gòu)的改進(jìn)點(diǎn):
改進(jìn)了預(yù)取器與分支預(yù)測(cè)器的性能
一級(jí)數(shù)據(jù)緩存增大50%
一級(jí)緩存存儲(chǔ)帶寬增大100%
二級(jí)緩存增大100%
微指令緩存增大50%
每周期能夠加進(jìn)亂序重排緩沖區(qū)的微指令多了25%
亂序重排緩沖區(qū)大了57%
后端執(zhí)行端口多了25%
支持AVX-512等新指令集
綜合以上的改進(jìn),Sunny Cove相對(duì)于Skylake在IPC上面取得了平均18%的進(jìn)步,而對(duì)于Broadwell或者說Haswell,則是有47%的進(jìn)步幅度,在針對(duì)AVX-512進(jìn)行優(yōu)化過的測(cè)試中,最高可以比上代移動(dòng)低壓處理器快2~2.5倍。在摩爾定律前進(jìn)緩慢的今天,這個(gè)數(shù)字已經(jīng)非常高了。
題外話,其實(shí)很多改進(jìn)在Cannon Lake上面就已經(jīng)有了,比如AVX-512、相關(guān)的指令集變動(dòng)和緩存帶寬增加等,還有些改動(dòng)是從Skylake-Server架構(gòu)上面下放而來的,比如AI加速的指令集其實(shí)已經(jīng)在服務(wù)器端處理器上出現(xiàn)了。但因?yàn)镃annon Lake實(shí)際被Intel放棄,所以繼承了Cannon Lake改進(jìn)點(diǎn)的Sunny Cove內(nèi)核架構(gòu)才能在相比較Skylake時(shí)得到平均18%的IPC進(jìn)步,如果一切正常,Intel的10nm沒有延期,Ice Lake應(yīng)該是Cannon Lake的下一代,對(duì)比起來就沒那么大的進(jìn)步幅度了。
第11代圖形架構(gòu)
Ice Lake的核顯首次達(dá)到了1TFlops的計(jì)算性能,還增加了不少的功能特性,可謂改進(jìn)頗多。Intel用了“the most powerful version”來形容這代核顯的性能,怎么做到的呢?

借助10nm工藝,暴力堆疊規(guī)模
Intel的10nm工藝在晶體管密度上的提升幅度是真的很大,14nm時(shí)代最多配備24組EU的核顯,在Ice Lake上面直接就翻了2.67倍,最大可以達(dá)到64組EU,并且頻率也不低,最高可以跑到1100MHz,比以前只低了50MHz,此時(shí)核顯整體的FP32計(jì)算量已經(jīng)達(dá)到了1.15TFlops。鑒于此,相比于八代酷睿處理器上搭載的第9代核顯,Intel官方宣稱可以提供平均約1.8倍的幀率。

你一定想問第10代去哪里了對(duì)不對(duì),其實(shí)還是在夭折了的Cannon Lake上面,而且唯一一顆的核顯還是被屏蔽了的。
目前在移動(dòng)低壓版Ice Lake處理器上面,Intel一共提供了G1、G4和G7三種配置的核顯,分別有32/48/64組EU,低端的G1命名仍為“UHD”,而G4和G7都以“Iris Plus”的品牌出現(xiàn)。
除了通過制程進(jìn)步來堆疊EU數(shù)量之外,內(nèi)部架構(gòu)的優(yōu)化也同樣重要。
內(nèi)部架構(gòu)優(yōu)化

與第九代核顯的對(duì)比表格如圖,出處:周末雜談,Icelake CPU的助手,Gen11核顯簡(jiǎn)介
首先通過增加單個(gè)Slice中含有的子Slice來擴(kuò)大規(guī)模,使得每周期的計(jì)算次數(shù)增加。
其次是在緩存系統(tǒng)上做文章,擴(kuò)大了三級(jí)緩存的容量,Intel方面公布的是EU的三級(jí)緩存有3MB,并且還有0.5MB的本地共享內(nèi)存。另外還有通過處理器的內(nèi)存控制器升級(jí),能夠用上更高的內(nèi)存帶寬。
新接口版本和加強(qiáng)的硬件編碼電路
上個(gè)月讓小編最難受的一件事情就是買了一臺(tái)1440p,144Hz刷新率的顯示器,用HDMI連接筆記本的時(shí)候,在1440p下面最高只能輸出60Hz,究其原因,就是老的第9代核顯支持的HDMI版本只能到1.4,最高只能提供4K@30Hz的輸出,1080p下面最大是120Hz,而小編的筆記本并沒有提供USB-C或者DP輸出。
而Ice Lake終于解決了這個(gè)痛點(diǎn),支持了HDMI 2.0b和DP 1.4 HBR3,這兩個(gè)就不用多說了吧,反正就是最高分辨率和幀數(shù)提升順便還能支持一下HDR。
另外,在視頻硬件編碼部分,也就是Intel QuickSync特性使用的獨(dú)立硬件電路上,新核顯也有比較大的改進(jìn),現(xiàn)在支持兩條HEVC 10-bit同時(shí)進(jìn)行編碼,在YUV444的情況下最高支持兩條4K60幀視頻流,或者一條YUV422的8K30幀視頻流。
可變速率著色(VRS)
VRS全稱Variable Rate Shading,是一種新的允許GPU根據(jù)畫面區(qū)域的重要性調(diào)整著色精度的技術(shù),具體效果我們之前的新聞?dòng)薪榻B過,可以看一下:來對(duì)比一下VRS可變速率著色技術(shù)帶來的性能提升吧 3DMark將添加該技術(shù)基準(zhǔn)測(cè)試一文中的圖片對(duì)比。

VRS可以在不重要的畫面上面節(jié)約一定的GPU資源,使這部分GPU資源參與更加重要的部分畫面的渲染中,從而提高了整體的幀數(shù),目前NVIDIA已經(jīng)在Turing核心中加入了相關(guān)的支持。而Intel也沒有落后,在第11代核顯中提供了這項(xiàng)特性,并且他們宣布將與Epic合作,將這項(xiàng)特性加入到虛幻引擎中去,目前文明六已經(jīng)支持了該技術(shù),并且根據(jù)Intel的數(shù)據(jù),幀數(shù)最大提高了30%。
小結(jié)
GPU部分的改進(jìn)主要還是規(guī)模增加了很多,架構(gòu)上屬于小改動(dòng),主要改進(jìn)了緩存系統(tǒng),不過第11代核顯的進(jìn)步還是比較明顯的。

可能以后在1080p低畫質(zhì)下面核顯也不再是雞肋了,能夠30幀打打游戲了。
Uncore部分
Uncore部分指的是處理器上除了內(nèi)核和GPU的其他部分,在頂上的結(jié)構(gòu)示意圖中就是System Agent的那部分,自從Intel在Nehalem把內(nèi)存控制器和PCI-E控制器移入CPU內(nèi)部之后就沒有什么大的變化,但是這次Intel在上面加入了個(gè)新東西,還升級(jí)了不少老部件。
Thunderblot 3
原來阻擋人們使用Thunderblot(以下簡(jiǎn)稱TB)設(shè)備的一大原因就是這個(gè)接口的使用成本略高,當(dāng)TB3開始以USB Type-C接口的形式出現(xiàn)之后,使用率確實(shí)高上去不少,但是還有其他的攔路虎,其中一個(gè)就是TB需要主板搭載額外的芯片來使用,這個(gè)控制芯片并不便宜。終于在Ice Lake上面,Intel把TB控制器整合到了處理器里面,并且再也不會(huì)占據(jù)掉處理器提供的PCI-E總線數(shù)量或者是與PCH一起擠原本就已經(jīng)擁擠不堪的DMI 3.0總線,而是在環(huán)形總線上面擁有了自己的位置。

而且Intel大方的一下子就提供了4個(gè)之多的TB3接口,每個(gè)都是PCI-E 3.0 x4的滿規(guī)格,也就是說,Ice Lake處理器其實(shí)一共擁有32條PCI-E 3.0通道,不過其中一半都是以TB3形式提供的,當(dāng)然這些接口是支持USB模式的,當(dāng)運(yùn)行于USB 2.0狀態(tài)時(shí),會(huì)繞回到PCH上進(jìn)行通信。

當(dāng)然也不是所有的廠商都會(huì)給足四個(gè)TB3接口,具體怎么配置還是得看OEM廠商,畢竟其他的配套芯片諸如USB PD所需要的獨(dú)立IC都是會(huì)增加成本的,而TB接口還需要額外的Retimer芯片,不過Intel已經(jīng)減半了所需的Retimer,兩條TB3只需要1個(gè)Retimer就可以了。

不過將TB控制器集成到CPU內(nèi)部也使得整個(gè)System Agent的IO部分更為復(fù)雜了,上面是一張?jiān)敿?xì)的原理圖,一個(gè)Type-CIO路由(圖上名為CIO Router)擁有兩條PCI-E 3.0 x4與CPU相連,而CPU內(nèi)部的顯示控制引擎(圖上的Display Engine)也要與這個(gè)Type-CIO路由相連,以控制Type-C接口所處的狀態(tài),并決定發(fā)送的信號(hào)。同時(shí)還有USB的xHCI也要跟Type-CIO連接,還要管理整個(gè)的內(nèi)存統(tǒng)一性……
復(fù)雜的結(jié)構(gòu)所導(dǎo)致的就是整體的延遲會(huì)增加,Intel將原因歸結(jié)在電源控制上面,原本分離式的芯片很容易管理電源狀態(tài),但是整合進(jìn)來之后每一個(gè)部分都有自己的電源狀態(tài)需要管理,需要更為精細(xì)化的電源管理系統(tǒng),而這就增加了總體的延遲。不過更為精細(xì)化的電源管理還是有好處的,那就是可以提高能耗效率,Intel方面稱滿載的一個(gè)TB3接口的芯片外加鏈路層將使用300mW的功率,四個(gè)加起來也只有1.2W。
值得一提的是,Intel已經(jīng)做好了對(duì)于USB4的兼容,不過考慮到目前USB4仍處于草案階段,不排除未來的修改使得兼容失效。不過目前只是針對(duì)Ice Lake的移動(dòng)版本進(jìn)行架構(gòu)分析,當(dāng)然也不排除Intel在桌面級(jí)的Ice Lake上面同樣保留內(nèi)部TB控制器。
題外話,TB3據(jù)說在Cannon Lake上面也是有的,但是夭折了。
內(nèi)存控制器
現(xiàn)在內(nèi)存控制器原生支持DDR4 3200/LPDDR4X 3733內(nèi)存,原來Skylake上面的內(nèi)存控制器頂多只能支持到DDR4 2666,還是八代的Coffee Lake以后的事情了。而隨著DDR4內(nèi)存的發(fā)展,默頻上3000的內(nèi)存條也開始出現(xiàn)了,內(nèi)存控制器直接支持到DDR4 3200是一件不錯(cuò)的事情。而且隨著處理器內(nèi)核數(shù)量的增加,內(nèi)存帶寬也逐漸要開始成為處理器性能的一個(gè)瓶頸所在了,在我們的測(cè)試中,內(nèi)存帶寬對(duì)于游戲性能的影響還是比較明顯的。
此前Intel的移動(dòng)低壓平臺(tái)只能使用LPDDR3作為內(nèi)存,而支持LPDDR4/X的一個(gè)好處就是可以在更低的功耗下面帶來更強(qiáng)的性能,尤其是對(duì)于此次圖形性能有比較大提升的Ice Lake來說,有著非常大的實(shí)際意義,因?yàn)閮?nèi)存帶寬直接影響到GPU的實(shí)際表現(xiàn)。
GNA

前面在講內(nèi)核的AI加速時(shí)提到了Uncore部分加入了GNA這個(gè)針對(duì)AI的硬件加速單元,目前并不知道太多有關(guān)于它的細(xì)節(jié),就連具體名字都有兩種說法,在Intel官方針對(duì)Windows Machine Learning的介紹網(wǎng)頁(yè)中,它的全名為Gaussian Network Accelerator,而在很多介紹Ice Lake架構(gòu)的文章中,它的名字又成了Gaussian Neural Accelerator。
目前已知的是該單元的功耗非常低,甚至?xí)赟oC其余部分關(guān)閉的情況下繼續(xù)工作,旨在提供穩(wěn)定的AI加速性能,應(yīng)用場(chǎng)景為語(yǔ)音識(shí)別之類。
圖像處理單元
Ice Lake上面的圖像處理單元(Image Process Unit)升級(jí)到了第4代,是的,你大概沒有聽說過Intel的CPU上面還有個(gè)圖像處理單元,但它從Skylake開始就一直存在,不過只有在移動(dòng)雙核型號(hào)上有,屬于DSP(數(shù)字信號(hào)處理器)范疇,為設(shè)備的相機(jī)提供影像處理功能。
Ice Lake上的IPU可以提供4K@30fps的視頻拍攝能力,還有更好的硬件降噪能力,支持更多的相機(jī),還支持將兩個(gè)不同的相機(jī)比如一個(gè)抓IR信息一個(gè)抓RGB信息的兩個(gè)相機(jī)模擬成一個(gè)設(shè)備來看待。
Intel方面稱,他們正在向軟件開放更多的IPU寄存器,以向應(yīng)用提供更好的便利性,并且提供了對(duì)機(jī)器學(xué)習(xí)的支持。另外值得一提的是,Intel將之前PCH上集成的MIPI接口轉(zhuǎn)移到了CPU上,未來可以用于接駁AI加速設(shè)備。
小結(jié)
Uncore部分可謂是發(fā)生了天翻地覆的改變,可以說是Ice Lake相對(duì)于之前Skylake變化最大的地方了,內(nèi)建TB3控制器肯定會(huì)給未來的使用帶來非常大的方便,小編個(gè)人非常喜歡這個(gè)改進(jìn)。而其他的可以歸于常規(guī)性質(zhì)的功能性更新。
PCH改進(jìn)
目前的Ice Lake平臺(tái)上PCH和CPU是封裝在同一塊基板上的,PCH的提升同樣是Ice Lake整個(gè)平臺(tái)的提升。同樣的,Ice Lake CPU通過DMI 3.0 x4總線與PCH相連,提供的帶寬等同于PCI-E 3.0 x4。

重新引入FIVR
FIVR其實(shí)早在Haswell架構(gòu)中就已經(jīng)被引入了,但是從Skylake開始又把它給去掉了,因?yàn)樵诋?dāng)時(shí)FIVR確實(shí)表現(xiàn)不佳,導(dǎo)致了整體功耗和發(fā)熱的增大。不過在Ice Lake上面,它又回歸到了CPU和PCH的內(nèi)部。Intel官方表示這么做可以節(jié)約整個(gè)平臺(tái)的面積,并且簡(jiǎn)化OEM的電源設(shè)計(jì)。新的FIVR有著更高的電源效率,與整個(gè)平臺(tái)的節(jié)能特性息息相關(guān)。看上去Intel也是解決了FIVR身上的一些毛病才放心將它集成進(jìn)CPU和PCH內(nèi)部的。
CNVi 2
其實(shí)Intel在這兩年已經(jīng)在出貨的芯片組里面都加入了CNVi方案的Wi-Fi模塊,這種方案將Wi-Fi網(wǎng)卡的部分電路轉(zhuǎn)移到了芯片組的內(nèi)部,而仍在外面充當(dāng)一個(gè)射頻模塊的Wi-Fi網(wǎng)卡就可以做的非常小了,比如M.2 2230或者以1216規(guī)格直接焊在主板上。PCH內(nèi)部的網(wǎng)卡與在外面的RF模塊通過一條Intel專有的CNVi鏈路進(jìn)行連接。

Ice Lake的PCH上面這條特別的CNVi鏈路升級(jí)到了第二個(gè)版本,即CNVi 2。

當(dāng)然,支持的Wi-Fi標(biāo)準(zhǔn)還是由在外面的Wi-Fi網(wǎng)卡所決定的,方便OEM自定義,Intel此舉是為了打破人們升級(jí)Wi-Fi路上的屏障(你倒是推動(dòng)一下AX路由器降價(jià)啊),目前Intel有兩張支持Wi-Fi 6標(biāo)準(zhǔn)的無(wú)線網(wǎng)卡:AX200/201。
關(guān)于Wi-Fi 6具體的提升之處,可以參考我們之前的文章:超能課堂(188) WiFi 6憑什么可以如此“六”?。
IO
這塊就簡(jiǎn)單羅列一下數(shù)據(jù)。
6個(gè)USB 3.1(5Gbps)/10個(gè)USB 2.0
16條PCI-E 3.0,一般會(huì)有8條用于兩個(gè)NVMe接口
3個(gè)SATA 3.0
eMMC 5.1
Intel沒有提到UFS的支持。
小結(jié)
PCH的變化并不是很大,主要是常規(guī)的功能性提升。
封裝、睿頻與功耗多種功耗目標(biāo)與不同封裝方式
目前Ice Lake-U和Ice Lake-Y是兩種目標(biāo)TDP不同的系列,分別針對(duì)15~28W和7~12W來設(shè)計(jì)的,未來的移動(dòng)標(biāo)壓級(jí)TDP約為45W,而桌面級(jí)目前未知。

此次率先發(fā)布的11款低壓和超低壓也采取了兩種不同的封裝,U系列沒有怎么變,還是老樣子,而超低壓就與往常不一樣了,Intel使用了更加緊湊的封裝方式,同時(shí)底部觸點(diǎn)也相對(duì)更加緊密。

動(dòng)態(tài)調(diào)節(jié) 2.0
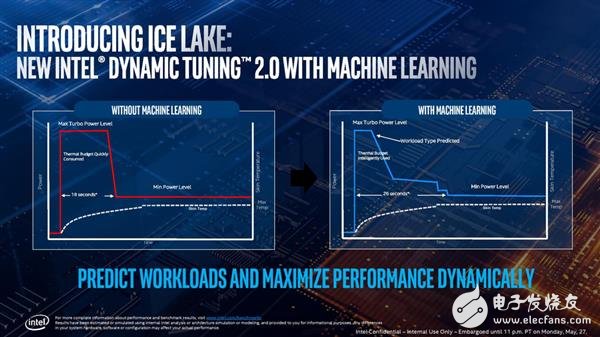
新的動(dòng)態(tài)調(diào)節(jié)2.0技術(shù)變化點(diǎn)看圖就可以了,大致意思就是Ice Lake處理器不會(huì)像之前那樣只能睿頻18秒之后就回到基礎(chǔ)頻率,而是慢慢的降下來,整個(gè)過程比原先長(zhǎng)了8秒。新技術(shù)還使用了機(jī)器學(xué)習(xí)來預(yù)測(cè)CPU將會(huì)吃到哪種類型的負(fù)載,然后智能調(diào)節(jié)功耗預(yù)算來盡可能地延長(zhǎng)睿頻時(shí)間。
總結(jié)
總的來看,Ice Lake是一代變化非常大的架構(gòu),無(wú)論是內(nèi)核還是外面的各種組件。人們都說Intel擠牙膏,但怎么說呢,競(jìng)爭(zhēng)對(duì)手所給的壓力不夠也是Intel擠牙膏的一個(gè)原因,但更多的原因恐怕是來自于這幾年Intel在制程工藝上面遇到的難題,本來在Intel的Tick-Tock戰(zhàn)略中,Cannon Lake是作為Skylake的制程升級(jí)版出現(xiàn)的,然而由于10nm的難產(chǎn),Tick-Tock戰(zhàn)略徹底失效,變成了PAO——制程-架構(gòu)-優(yōu)化戰(zhàn)略之后,計(jì)劃以10nm初代的角色推出,結(jié)果10nm比PAO戰(zhàn)略的計(jì)劃還要晚,但是競(jìng)爭(zhēng)對(duì)手的Zen和Zen+架構(gòu)開始給Intel壓力了,沒辦法,Skylake加兩個(gè)核用14nm++再頂一頂吧。這一頂就是將近兩年過去了,Cannon Lake也被徹底的放棄了,上面的許多優(yōu)化被Ice Lake所繼承了下來。
從整體架構(gòu)來看,Ice Lake在單線程性能上面繼續(xù)沖高,而測(cè)試成績(jī)也都印證了這一點(diǎn):基礎(chǔ)頻率和加速頻率都比前代更低的情況下單線程成績(jī)能夠?qū)⒋蚱剑呀?jīng)很不容易了。多核的話,Ringbus極限應(yīng)該是十核左右,如果不采用Mesh架構(gòu),那么桌面版未來的Intel Ice Lake處理器還是會(huì)不敵AMD的Zen 2/3。
而在擴(kuò)展性上面,Ice Lake還是比較良心的,TB3控制器的加入使得USB和TB設(shè)備不再需要擠占原本就有些不夠的PCI-E 3.0總線,并且還預(yù)留了與USB4的兼容,在未來Ice Lake的優(yōu)化版或者升級(jí)版上我們有望看到正式的USB 4支持。
Ice Lake也會(huì)是未來一段時(shí)間中Intel主力的架構(gòu),只不過等它來到桌面級(jí)還需要一段時(shí)間。Intel目前的產(chǎn)品線也是非常的混亂,有機(jī)會(huì)我們會(huì)單開一篇文章來捋一捋。














 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論