 電子發燒友App
電子發燒友App


眾所周知,匯編語言具有更高的性能優勢,而用C語言編碼則能更容易和快速地實現。DSP處理器功能的不斷增強以及編譯器優化技術的提高,使得傳統的用匯編語言編寫DSP應用程序的做法逐漸被淘汰。現在的DSP應用程序幾乎都是由C代碼和匯編代碼混合組成的。在那些對性能起決定性作用的關鍵功能中,DSP工程師將繼續使用高度優化的匯編代碼,同時轉用C語言編寫那些不太關鍵的功能,這將有利于代碼維護和移植。而C和匯編代碼的這種結合要求DSP工程師具備專門的工具和方法。
正確混合C代碼和匯編代碼
問題是在哪里劃分C代碼和匯編代碼的界限。這取決于跟蹤器(profiler)所能提供的性能分析結果。然而在使用跟蹤器之前,DSP工程師需要為應用程序定義清晰的目標,這些目標一般包括循環數、代碼規模和數據量。目標一旦確定后,應該先全部用C語言編寫和創建應用程序,然后才使用跟蹤器來分析性能。
在某些特定情況下,主要是控制應用中,C語言級的編碼就足夠了。但在大多數情況下,初始編寫的C語言應用程序是不能滿足一個或更多目標要求的。這通常意味著多少需要一些匯編代碼。在求助于匯編編程之前,強烈建議保存原始的C代碼。這樣不僅方便調試,而且當條件成熟(比如采用更強大的平臺),還可以返回到這些C語言的實現。
匯編部分代碼應盡可能少。為此,工程師需要認真分析跟蹤器提供的性能結果,并確定應用程序中的關鍵函數。關鍵函數是指占用大部分執行時間,而必須用匯編語言重寫才能滿足性能目標的那些函數。重寫其中的幾個關鍵函數后,需要重新進行性能分析。如果仍達不到目標要求,那就應該確定其它關鍵函數,再進行重寫。圖1顯示了利用專用硬件機制獲得高度優化的匯編代碼。

圖1:用C語言創建的循環緩沖器代碼(左)以及由CEVA-teakLite-III創建的等效匯編代碼(右)。
對編譯器的考慮事項
在編寫需要與C代碼結合的匯編代碼時,匯編編程人員必須了解編譯器的約定和假設。匯編編程人員還必須了解編譯器的寄存器使用約定。通常,寄存器使用約定將硬件寄存器分成被調用方保存(或調用方使用)和被調用方使用(或調用方保存)寄存器。圖2給出了從CEVA-X1641 DSP內核FFT實現中摘取的匯編代碼例子。左邊第二行的add指令符合CEVA-X1641編譯器傳遞r0地址寄存器中指針參數的調用約定。右邊的pushd指令用于備份后面函數會用到的被調用方保存寄存器。

圖2:從CEVA-X1641 DSP內核的FFT實現中摘取的一段匯編代碼。
除了調用約定和寄存器使用約定外,一些編譯器在人工編寫的匯編代碼方面可能還會有一些額外的假設。這些假設通常是專門針對某個編譯器的,因此編譯器提供商會提供完善的資料和說明。
用于C和匯編連接的常用C語言擴展
用于嵌入式平臺的大多數編譯器,特別是用于DSP編程的編譯器,都具有豐富的C語言和匯編語言連接功能。其中絕大部分功能不屬于標準C語言,因此被稱為C語言擴展。下面列出的是其中有益于DSP編程的一些功能。
內聯匯編(inline assembly):該功能可以幫助編程人員將匯編指令插入C代碼。
硬件寄存器綁定C變量:該功能經常與匯編指令內聯功能結合在一起,幫助內聯匯編代碼訪問C語言級的變量(見圖3)。

圖3:結合內聯匯編和硬件寄存器綁定功能的代碼示例。
存儲區屬性:該功能允許編程人員將上述變量和函數分配到獨特的用戶定義存儲區,可以讓編程人員將C語言級單元分配到實際的存儲器位置,這對DSP應用來說非常關鍵。
用戶定義的調用約定:在某些情況下,匯編函數可以通過用戶定義的調用約定取得更好的優化效果。編譯器內部函數(Compiler intrinsics):是指能夠使用專門的宏或函數調用觸發的內建編譯器功能總稱。沒有內部函數支持的編譯器必須調用用戶定義的函數,這樣做可能會令用戶定義函數可能會在一個環路里產生函數調用和返回(見圖4),從而產生巨大的開銷。

圖4:ETSI的mult_r(乘法和取整)基本操作的C代碼實現(左)和對應的由CEVA-TeakLite-III編譯器生成的匯編代碼(右)。
匯編內部函數:是將匯編代碼內聯進C代碼的一種先進方法,下文將有詳細介紹。
把匯編指令當作C語句一樣來編寫
內聯匯編功能具有顯著的缺點。它會破壞各種編譯器優化操作,因為編譯器不了解內聯代碼的內容,會使用最壞假設;以及它可能迫使編程人員處理底層問題,如寄存器分配和指令調度。
匯編內部函數可以幫助編程人員實現內聯匯編代碼,并且不存在這些缺點。從編程人員的角度看,匯編內部函數就像是C語言宏或函數。它們接收C語言變量,返回C語言輸出結果,同時表現為單個匯編指令。由于涉及該功能的所有代碼都在C語言等級,因此編程人員不必擔心寄存器分配、指令調度和其它底層問題。匯編內部函數不僅不會妨礙編譯器優化操作,還會參與優化過程,就像它們是編譯器正常產生的匯編指令一樣。這些特征使得匯編內部函數的功能非常強大。
利用匯編內部函數,編程人員可以從編譯器不可能產生的獨特匯編指令中受益。例如,CEVA-X1641的bitrev(位反向)指令就是為FFT等算法定制的。由于編譯器不太可能把一個程序看作一個FFT并使用bitrev指令,因此編程人員可以完全把bitrev匯編內部功能嵌入到C代碼中。結合對應用的透徹了解,編程人員還可以使用C應用程序的性能決定段里的精確序列匯編內部函數,從而能夠確保編譯器生成的代碼效率就像手工編寫的一樣高。
圖5是CEVA-X1641編譯器與匯編內部函數一起使用的例子。匯編內部函數還受益于由CEVA-X1641編譯器處理的問題所決定的機器,如寄存器分配、指令調度和硬件單元分配。

圖5:CEVA-X1641編譯器支持的匯編內部函數的使用。
調試混合代碼的應用程序
匯編代碼的調試需要對延遲和存儲器對齊限制等架構和機器級問題有深入的了解。只是簡單地把C代碼和匯編代碼放在一起會使事情更麻煩,因為編程人員現在還必須調試C代碼和匯編代碼之間的連接。
調試混合代碼應用程序的第一步就是分隔問題。假設保持匯編代碼的C語言實現不變以及C語言實現方案工作正常,那么將匯編函數轉換成C語言實現并重新測試應用程序就相對比較容易。為了迅速檢測出問題,編程人員可以在每一步把受懷疑函數的一半轉換為相應的C語言實現方案。
一旦有問題的匯編函數被確定,它就應該同時作為獨立的匯編問題和C與匯編的連接問題加以分析。調試獨立的匯編問題對匯編編程人員來說十分簡單明了,但C與匯編的連接問題就有點麻煩。在考慮匯編函數本身時,C與匯編的連接問題是不可見的,這與獨立的匯編問題有所不同。為了找出這些問題,編程人員必須檢查編譯器的約定,比如調用約定和寄存器使用約定。
編程人員還必須檢查編譯器假設,比如匯編指令的行蹤。為了節省調試時間,編程人員應該在第一次實現匯編函數時驗證是否遵循所有的編譯器約定和假設。
本文討論的技術和方法已被CEVA公司用于各種各樣的應用,包括視頻編解碼器、音頻編解碼器、聲音合成器和設備驅動器。而本文所述的功能在這些應用中都可以顯著提高性能。H.264視頻編碼器是一個很好的研究案例。它在處理能力及其它資源方面要求非常嚴格,尤其是相比語音編解碼器等其它類型的編解碼器而言。
CEVA公司的CEVA-X16xx高端DSP內核系列及其MM2000多媒體平臺可以為這種編碼器提供所需的處理能力。先用高級跟蹤技術確定這種編碼器的關鍵函數,然后逐步對之進行優化。首先,利用匯編內部函數在C語言級對這些函數進行全面優化。然后,在匯編語言級對編譯器提供的匯編代碼作進一步優化。
圖6展示了通過對這種編碼器的關鍵函數進行全面優化所獲得的性能提高。只有最后一個優化階段涉及到純匯編編程,所有其它階段都基于帶有匯編內部函數的C代碼。這些匯編內部函數主要用于SIMD操作,如avg_acW_acX_acZ_4b。這條指令對8個輸入字節取平均,產生4字節結果。這種SIMD操作對執行大量字節級計算的視頻編解碼器非常有用。
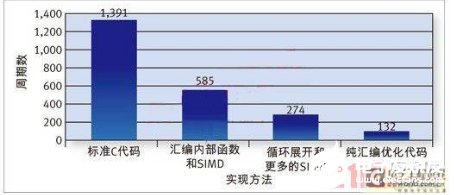
圖6:對H.264編碼器的關鍵函數進行優化以提升性能。AMR-NB(自適應多速率-窄帶)是廣泛用于無線通信應用的語音編解碼器。通常都是采用純匯編來實現聲音合成器,但C語言實現與CEVA-X1620編譯器利用本文討論的各種功能可以獲得與匯編實現媲美的結果。圖7顯示了整個AMR-NB應用經過全面優化而取得的以MCPS(每秒百萬周期)計的性能提高幅度。只有最后的優化階段涉及到了純匯編編程,所有其它階段都基于帶有ETSI內部函數和匯編內部函數等的C代碼。
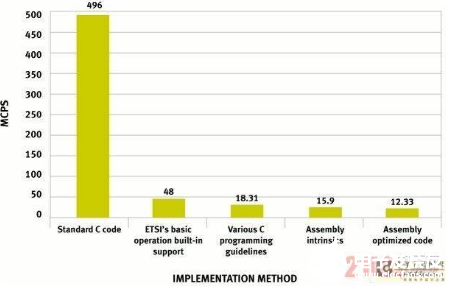
圖7:通過各種優化方法取得的ARM-NB性能改進。
總之,H.264編碼器和AMR-NB例子清楚地表明了匯編實現方案的性能優勢,但也表明純匯編實現并非首選的優化方法。利用高質量軟件開發工具提供的C與匯編功能,DSP編程人員無需純匯編語言也能使整個應用程序達到令人滿意的性能。










 工商網監
工商網監
評論