 電子發(fā)燒友App
電子發(fā)燒友App


1 TMS320C6000的硬件設(shè)計和指令系統(tǒng)
TMS320C6000系列DSP(數(shù)字信號處理器)是TI公司最新推出的一種并行處理的數(shù)字信號處理器。它是基于TI的VLIW技術(shù)的,其中,TMS320C62xx是定點處理器,TMS320C67xx是浮點處理器。本文主要討論TMS320C6201。該處理器的工作頻率最高可以采用50MHz,經(jīng)內(nèi)部4倍頻后升至200MHz,每個時鐘周期最多可以并行執(zhí)行8條指令,從而可以實現(xiàn)1600MIPS的定點運算能力,而且完成1024定點FFT的時間只需70μs。
1.1 TMS320C6000的硬件結(jié)構(gòu)
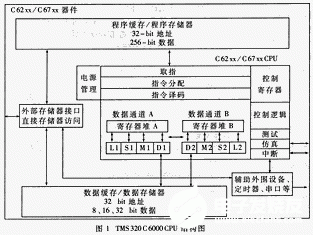
TMS320C6000的CPU有兩個數(shù)據(jù)通道A和B,每個通道有16個32位字長的寄存器(A0~A15,B0~B15),四個功能單元(L,S,M,D),每個功能單元負責完成一定的算術(shù)或者邏輯運行。A、B兩通道的寄存器并不是完全共享,只能通過TM320C6000提供的兩個交換通道1X、2X,才能實現(xiàn)處理單元從不同通道的寄存器堆那里獲取32位字長的操作數(shù)。
TMS320C6000的地址線為32位,存儲器尋址空間是4G。C6201片內(nèi)集成有1Mbit SRAM——512Kbit的程序存儲器(根據(jù)需要可全部配置成Cache)和512Kbit的數(shù)據(jù)存儲器。通過片內(nèi)的程序存儲空間控制器,CPU一次可以取出256bit,即一次最多可以取出8條32位指令。
C6201有32位的外部存儲接口EMIF為CPU訪問外圍設(shè)備提供了無縫接口。外圍設(shè)備可以是同步動態(tài)存儲器(SDRAM)、同步突發(fā)靜態(tài)存儲器(SBSRAM)、靜態(tài)存儲器(SRAM)、只讀存儲器(ROM),也可以是FIFO寄存器。
為了便于進行多信道數(shù)字信號處理,TMS320C6000配備了多信道帶緩沖能力的串口McBSP。McBSP的功能非常強大,除具有一般DSP串口功能之外,還可以支持T1/E1、ST-BUS、IOM2、SPI、IIS等不同標準。McBSP最多支持128個信道;支持多種數(shù)據(jù)格式(8/12/16/20/24/32bit)的傳輸;可自動進行u律、A律壓擴。其工作速率可達到1/2時鐘速率。
TMS32C6000提供的16位主機接口(HPI)使得主機設(shè)備可以直接訪問DPS的存儲空間。通過內(nèi)部或外部存儲空間,主機和DSP可以交換信息。主機也可以利用HPI直接訪問映射進存儲空間的外圍設(shè)備。
DSP器件一般都帶有DMA控制器,可以在CPU操作的后臺進行數(shù)據(jù)傳輸。TMS320C6201的DMA控制器有4個獨立的可編程通道,可以同時進行四個不同的DMA操作,每個通道的優(yōu)先級可以通過編程設(shè)定。每個通道可以根據(jù)需要傳輸8/16/32bit的數(shù)據(jù),并且DMA控制器可以訪問全部32位的地址空間。此外,還有一個輔助通道允許DMA控制器響應(yīng)主機通過HPI口發(fā)來的請求。
1.2 指令系統(tǒng)
C62xx和C67xx共享同一個指令集。C67xx可以使用所有的C62xx指令,但因為C67xx是浮點芯片,怕以C67xx的指令集中有一些指令只能用于浮點運算。TMS320C6201CPU的設(shè)計采用了類似于RISC的結(jié)構(gòu),指令集簡單、運算速度快。8個功能單元負責不同功能的運算,指令和功能單元之間存在一個映射關(guān)系。其中,L單元有23條指令,M單元有20條指令,S單元29有條指令,D單元有26條指令。
TMS320C6201的大部分指令都可在單周期內(nèi)完成,都可以直接對8/16/32bit數(shù)據(jù)進行操作。同時,TMS320C6201指令集針對數(shù)字信號處理算法提供了一引起特殊指令:為復(fù)雜計算提供的40bit的特殊操作的加法運算;有效的溢出處理和歸一化處理;簡潔的位操作功能等。TMS320C6201中最多可以有8條指令同時并行執(zhí)行;所有指令均可條件執(zhí)行。以上所有特點提高了指令的執(zhí)行效率、減小了代碼長度、大大減少了因跳轉(zhuǎn)引起的開銷、提高了編碼效率。
流水線操作是DSP實現(xiàn)高速度、高效率的關(guān)鍵技術(shù)之一。TMS320C6000只有在流水線充分發(fā)揮作用的情況下,才能達到1600MIPS的速度。C6000的流水線分為三個階段:取指、解碼、執(zhí)行、總共11級。和以前的C3x、C54x相比,有非常大的優(yōu)勢,主要表現(xiàn)在:簡化了流水線的控制以消除流水線互鎖;增加流水線的深度以消除傳統(tǒng)流水線結(jié)構(gòu)在取指、數(shù)據(jù)訪問和乘法操作上的瓶頸。其中取指、數(shù)據(jù)訪問分為多個階段,使得C6000可以高速地訪問存儲空是。
2 優(yōu)化編程的幾個方法
使用TMS320C6000進行程序設(shè)計時,首先的感覺是匯編指令集太小了。C6000在設(shè)計時采用了一種類RISC機的結(jié)構(gòu),運算速率特別快,但是指令集卻非常簡單。象DSP算法中常用的乘加指令、循環(huán)操作指令等,在C54x和C3x中兩條指令就可以完成的功能,而在C6000中卻需要一個循環(huán)體,所以它的程序設(shè)計一般比較復(fù)雜。要想充分發(fā)揮C6000的運算能力,必須從它的硬件結(jié)構(gòu)出去,最大限度地利用八個功能單元,使用軟件流水線,盡量讓程序無沖突的并行執(zhí)行。
并行處理的長處在于,在處理彼此之間沒有承接關(guān)系的運算時,在CPU資源允許的情況下可以并行完成。但對于前后有承接關(guān)系或者判斷、跳轉(zhuǎn)頻繁的情況,就無法發(fā)揮并行的優(yōu)勢。一般循環(huán)體都滿足并行處理的條件,并且循環(huán)體往往是程序中耗時最長的地方。因此進行C6000應(yīng)用開發(fā)時應(yīng)將優(yōu)化重點放在循環(huán)體上。為了降低開發(fā)難度,C6000提供了很多在高級語言(如ANSI C)一級對程序進行優(yōu)化的方法。在應(yīng)用滿足實時性處理要求時,應(yīng)盡量采有這種方法。但是這種方法的效率比較低,C語言優(yōu)化最好的例子是點乘,這種循環(huán)使用C語言進行優(yōu)化可以百分之百地的利用CPU資源,程序的并行性達到最好。但是我們在做20點的點乘時發(fā)現(xiàn)它耗時是匯編語言程序的3倍。所以如果系統(tǒng)的實時性要求比較高,就不能使用這種優(yōu)化方法了。
這時可以考慮使用線性匯編語言進行開發(fā)。線性匯編語言是TMS320C6000中獨有的一種編程語言,介于高級語言和低級語言之間。因為在用手寫匯編語言進行應(yīng)用開發(fā)時,開發(fā)者除了要精通C6000的指令系統(tǒng)之外,還必須為指令分配功能單元、考慮指令的延這和功能單元之間的配合以及合理分配使用32個寄存器,才能寫出高效的并行指令,發(fā)揮C6000的威力。上面任何一個方面出現(xiàn)問題,都會嚴重影響算法的效率。
線性匯編語言的指令系統(tǒng)和匯編語言的指令系統(tǒng)完全相同,但是它有自己的匯編優(yōu)化器指令系統(tǒng),用于和匯編性匯編語言時不需要考慮指令的延時、寄存器的使用和功能單元的分配,完全可以按照高級語言的方式進行編寫。當然由于它不是高級語言,有許多編程的限制。例如,在優(yōu)化循環(huán)體時,不能使用跳轉(zhuǎn)到循環(huán)體之外的跳轉(zhuǎn)指令;另外計數(shù)順只能使用減計數(shù),如果使用加計數(shù),優(yōu)化器將不能工作等等。但總的說來,它的代碼效率遠遠高于高級語言,而且開發(fā)難度和開發(fā)周期比匯編語言要小得多。
在實際開發(fā)過程中需要具體情況具體分析,選擇一種高效、快捷的開發(fā)方法。以下結(jié)合應(yīng)用開發(fā)中的幾個模塊來簡述我們使用的優(yōu)化方法。
2.1 使用匯編語言進行
使用匯編語言進行并行編程難度比較大。但在有些情況下,程序中數(shù)據(jù)有非常強的承接關(guān)系,并且該程序體邏輯關(guān)系清楚,使用的寄存器不超過32個,這時直接使用匯編語言實現(xiàn),效率會更高。另外,有些使用C語言比較難實現(xiàn)的運算函數(shù),在C6000的匯編指令集中可能有專用DSP指令,這時就可以直接使用匯編語言實現(xiàn)。
使用匯編語言進行編程時特別需要注意的是C6000指令的延遲情況,有些指令并不是立刻就能得到結(jié)果。C6000指令集中有延遲的指令如表1所示。

例1 32位歸一化函數(shù)morm_1()
short morm_1(long L_var1)
{short var_out;
if (L_var1= = 0L){
var_out = (short)0;
}
else {
if (L_var1= = (logn)0xffffffffL{
var_out = (short)31;
}
else {
if (L_var1 0L) {
L_var1 = ~L_var1;
}
for(var_out=(short)0;L_var1(long)0x40000000L;
var_out++){
L_var1 = 1L;
}}}
return(var_out);
}
使用匯編語言進行優(yōu)化;
.global norm_1
_norm1:
B B3
CMPEQ 0,A4,B0
[!B0] NORM A4,A4
NOP 3
消耗時間(時鐘周期):C語言norm_1()為723;匯編語言為11。
2.2 使用線性匯編語言重寫整個函數(shù)
對于某些以循環(huán)體為主的函數(shù)可以使用線性匯編語言重寫整個函數(shù)。使用匯編優(yōu)化器進行優(yōu)化之后,效率是非常高的。
下面例子是算法中計算幀能量的函數(shù),其中包含兩個單循環(huán)體。進行優(yōu)化時,首先要確定循環(huán)的次數(shù)。對于循環(huán)次數(shù)是變量的情況,優(yōu)化器不進行并行優(yōu)化;其次盡量減少數(shù)據(jù)存取次數(shù),例如以32位存取指令對16位數(shù)據(jù)進行存取,可以節(jié)省一增的存取周期。仔細觀察C代碼,會發(fā)現(xiàn)兩次循環(huán)次數(shù)相同。第二個循環(huán)要用到第一個循環(huán)的結(jié)果,因此可以將兩個循環(huán)合并在一起,這樣就避免了在第二個循環(huán)中再從存儲器中取結(jié)果,減少了一半的Load操作。
Long Comp_En(short *Dpnt)
{ int i;
long Rez;
short Temp[60];
for (i=0;i60;i ++) Temp [i] = shr(Dpnt[i],(short) 2);
Rez=(long) 0;
for (i=0; i 60; i ++) Rez=L_mac(Rez,Temp[i],Temp[i]);
return Rez;
}
相應(yīng)的線性匯編程序如下:
.global _Comp_En ;函數(shù)名定義,對c變量前加_
_Comp_En .cproc Dpnt;函數(shù)頭定義,Dpnt是參數(shù)
.reg Rez,Rez1,Rez2,1 ;寄存器定義,不必考慮實際的寄存器分配
.reg t1,t2,x1,c1,m1,m2
zero Rez
zero Rez1
zero Rez2
mv Dpnt,c1
mvk 30,i ;確定循環(huán)次數(shù)。因為用LDW代替LDH,循五環(huán)次數(shù)減少一半。
loop1 .trip 30
ldw *c1++,x1
sh1 x1,16,t1
shr t1,2,t1
shr x1,2,t2 ;將兩個循環(huán)合在一起,又減少了一半的從內(nèi)存取數(shù)據(jù)的時間。
smpyh t1,t1,m1
smpyh t2,t2,m2
sadd Rez1,m1,Rez1
sadd Rez2,m2,Rez2
[i] sub i,1,i ;循環(huán)計數(shù)器從30遞減
[i] b loop1
sadd Rez1,Rez2,Rez
.return Rez
.endproc
消耗時間(時鐘周期):C語言為32971;線性匯編語言為93。
2.3 使用線性匯編改寫復(fù)雜函數(shù)中的循環(huán)體
當函數(shù)的邏輯關(guān)系復(fù)雜,判斷、跳轉(zhuǎn)、函數(shù)調(diào)用情況特別多時,上面方法的效果就會在打折扣。這時可以使用線性匯編將其中的循環(huán)部分改寫成一個函數(shù),以優(yōu)化后的函數(shù)調(diào)用代替環(huán)部分,而不是優(yōu)化整個復(fù)雜函數(shù)。
高速數(shù)字信號處理器件的應(yīng)用范圍越來越廣,特別是在移動通信領(lǐng)域中,軟件無線電、智能天線等新技術(shù)的實都需要強大的實時數(shù)字信號處理的支持。TMS320C6000系列DSP完全可以滿足此類要求。但目前對于并行DSP技術(shù)的軟硬件開發(fā)還處在摸索階段,如何充分利用高速DSP的資源,是這方面的研究重點。本文研究了最新推出的TMS320C6000的優(yōu)化策略,從工程和系統(tǒng)的角度總結(jié)出一套既能滿足實時性又能保證開發(fā)時效性的實用的優(yōu)化編程方法,以供分饗。
責任編輯:gt












 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論