 電子發燒友App
電子發燒友App


一、概述
在前面的"CPU 優化技術"系列文章中我們對NEON做了系統的介紹和說明,包括SIMD和NEON概念,NEON自動向量化以及NEON intrinsic指令集等。但是只掌握這些還不足以編寫一個性能完善的NEON程序,在實際的NEON優化工作中我們會遇到如何將標量處理轉換為向量處理,如何更高效的處理圖像的邊界區域等問題。接下來我們會針這些問題進行介紹和說明,讓大家可以在實際工作中使用NEON來優化程序的性能。
本文我們會介紹代碼如何進行向量化,如何處理向量化的剩余部分,如何處理圖像的邊界區域,最后會給出一個完整的NEON程序實例。
二、概述向量化編程
2.1.?向量化
向量化就是使用SIMD指令同時對多個數據進行處理,達到提升程序性能的目的。
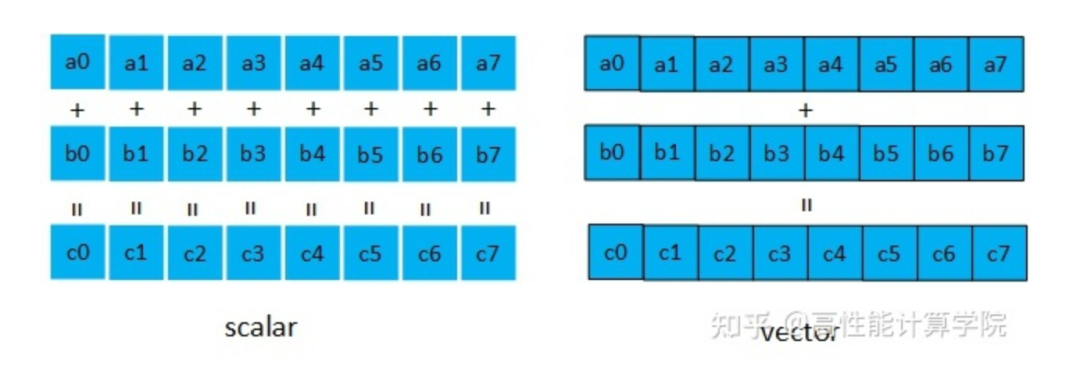
我們以數據加法為例,標量和向量處理的對比圖如下。對于無符號16位類型的加法運算,普通的標量加法需要進行8次的計算量,使用向量加法指令一次就可以完成。
相比于標量編程,向量化編程對于初學者來說有一定的難度:
編程方式的變化:一次處理的不再是單個數據而是多個數據,同時還要專門處理向量化的剩余數據。
向量數據類型的選擇:要根據實際的情況選擇最合適的向量寄存器。
選擇合適的指令:需要非常熟悉NEON指令集,使用最適合的指令獲得最好的性能。
2.2 實例講解
這是一個UV通道下采樣代碼,輸入是u8類型的數據,通過鄰近的4個像素求平均,輸出u8類型的數據,達到1/4下采樣的目的。我們假定每行數據長度是16的整數倍。算法的示意圖和參考代碼如下所示。

C代碼實現:
void DownscaleUv(uint8_t *src, uint8_t *dst, int32_t src_stride, int32_t dst_width, int32_t dst_height, int32_t dst_stride)
{
for (int32_t j = 0; j < dst_height; j++)
{
uint8_t *src_ptr0 = src + src_stride * j * 2;
uint8_t *src_ptr1 = src_ptr0 + src_stride;
uint8_t *dst_ptr = dst + dst_stride * j;
for (int32_t i = 0; i < dst_width; i += 2)
{
// U通道
dst_ptr[i] = (src_ptr0[i * 2] + src_ptr0[i * 2 + 2] +
src_ptr1[i * 2] + src_ptr1[i * 2 + 2]) / 4;
// V通道
dst_ptr[i + 1] = (src_ptr0[i * 2 + 1] + src_ptr0[i * 2 + 3] +
src_ptr1[i * 2 + 1] + src_ptr1[i * 2 + 3]) / 4;
}
}
}
2.2.1 內層循環向量化
內層循環是代碼執行次數最多的部分,因此是向量化的重點。我們的輸入和輸出都是u8類型,NEON寄存器128bit,所以我們每次處理16個數據。
// 每次有16個數據輸出
for (i = 0; i < dst_width; i += 16)
{
//數據處理部分......
}
2.2.2 數據類型的選擇
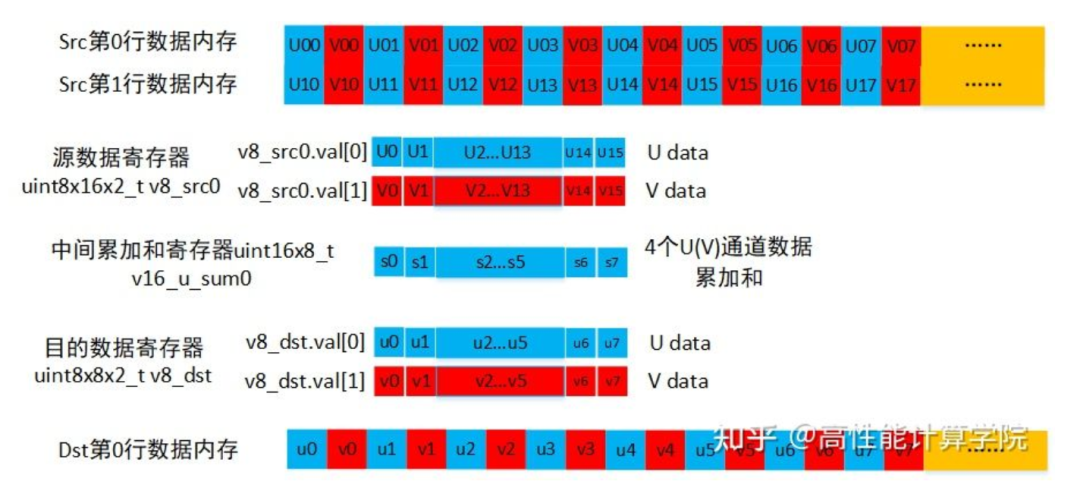
2.2.3 指令的選擇
輸入數據加載:UV通道的數據是交織的,使用vld2指令可以實現解交織。
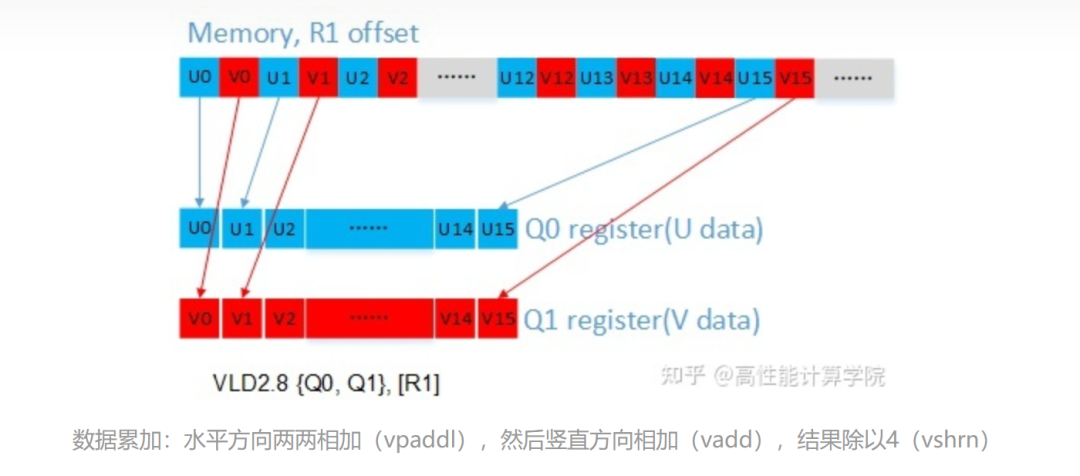
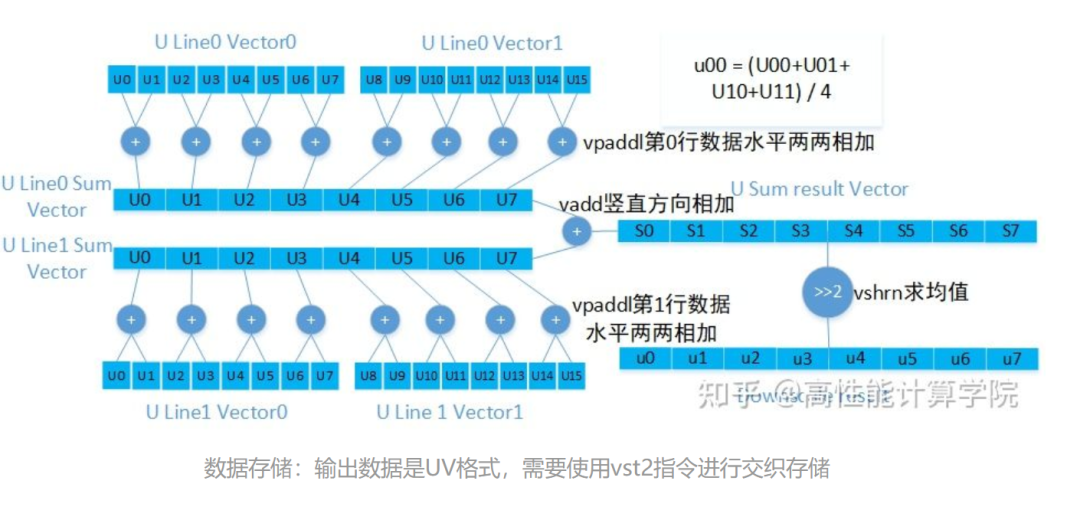
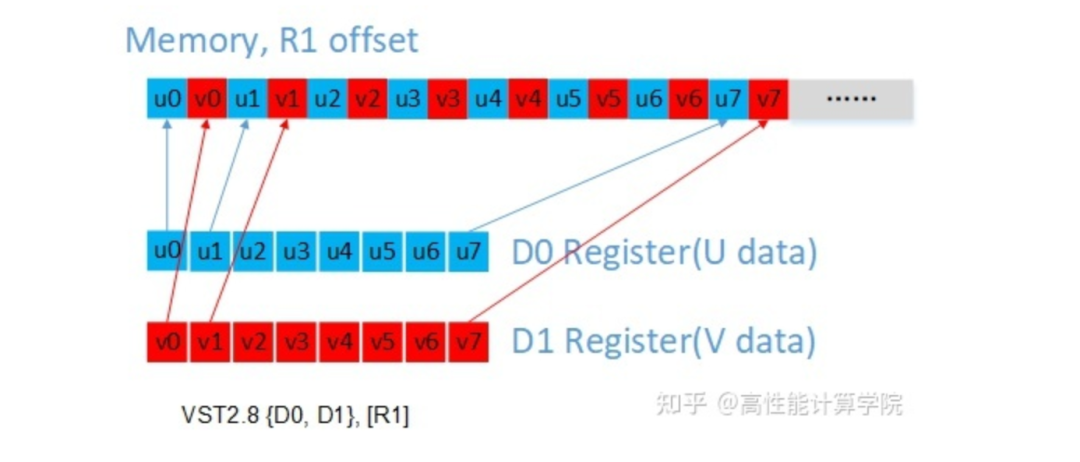
2.2.4 代碼實現
//使用intrinsic需要包含的頭文件 #includevoid DownscaleUvNeon(uint8_t *src, uint8_t *dst, int32_t src_width, int32_t src_stride, int32_t dst_width, int32_t dst_height, int32_t dst_stride) { //load偶數行的源數據,2組每組16個u8類型數據 uint8x16x2_t v8_src0; //load奇數行的源數據,需要兩個Q寄存器 uint8x16x2_t v8_src1; //目的數據變量,需要一個Q寄存器 uint8x8x2_t v8_dst; //目前只處理16整數倍部分的結果 int32_t dst_width_align = dst_width & (-16); //向量化剩余的部分需要單獨處理 int32_t remain = dst_width & 15; int32_t i = 0; //外層高度循環,逐行處理 for (int32_t j = 0; j < dst_height; j++) { //偶數行源數據指針 uint8_t *src_ptr0 = src + src_stride * j * 2; //奇數行源數據指針 uint8_t *src_ptr1 = src_ptr0 + src_stride; //目的數據指針 uint8_t *dst_ptr = dst + dst_stride * j; //內層循環,一次16個u8結果輸出 for (i = 0; i < dst_width_align; i += 16) { //提取數據,進行UV分離 v8_src0 = vld2q_u8(src_ptr0); src_ptr0 += 32; v8_src1 = vld2q_u8(src_ptr1); src_ptr1 += 32; //水平兩個數據相加 uint16x8_t v16_u_sum0 = vpaddlq_u8(v8_src0.val[0]); uint16x8_t v16_v_sum0 = vpaddlq_u8(v8_src0.val[1]); uint16x8_t v16_u_sum1 = vpaddlq_u8(v8_src1.val[0]); uint16x8_t v16_v_sum1 = vpaddlq_u8(v8_src1.val[1]); //上下兩個數據相加,之后求均值 v8_dst.val[0] = vshrn_n_u16(vaddq_u16(v16_u_sum0, v16_u_sum1), 2); v8_dst.val[1] = vshrn_n_u16(vaddq_u16(v16_v_sum0, v16_v_sum1), 2); //UV通道結果交織存儲 vst2_u8(dst_ptr, v8_dst); dst_ptr += 16; } //process leftovers...... } }
2.3 向量化剩余部分(leftovers)處理
接著上面的實例,內層循環每次計算16個結果,當輸出圖像寬度不是16整數倍的時候,我們需要考慮結尾如何高效的編寫。“NEON Programmer's Guide”中給出了幾種推薦寫法,下面逐一介紹一下。
2.3.1 Extend arrays with padding
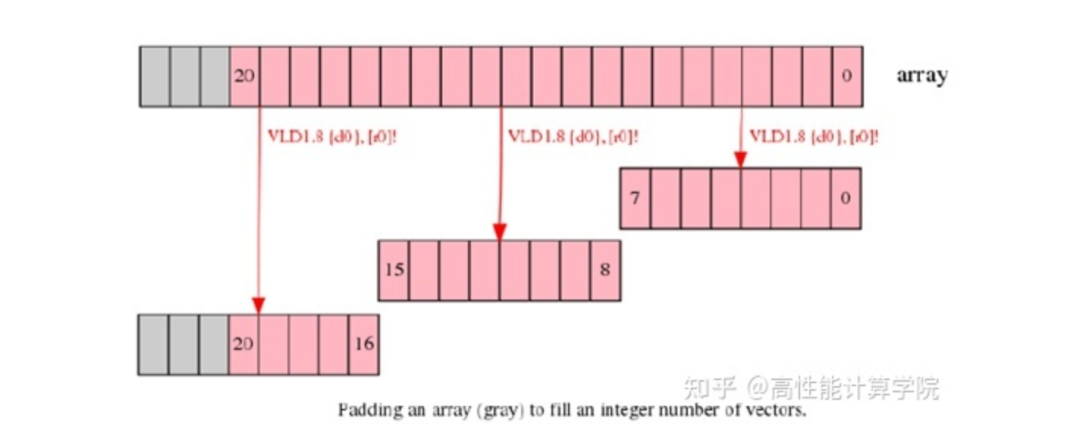
這個方法比較好理解,每行數據長度不是向量長度整數倍我們可以提前將數據補齊到需要的長度,這樣處理時候就方便了。這個方法的使用是要分情況的。
如果需要自己申請內存,復制來擴展邊界,這并不是一種高效的方法。
如果外部數據先要經過其他的處理(例如rgb2yuv),我們可以考慮將前一級的輸出保存成需要的長度,這樣后面的uv下采樣就可以得到擴展的內存了。
2.3.2 Overlap data elements
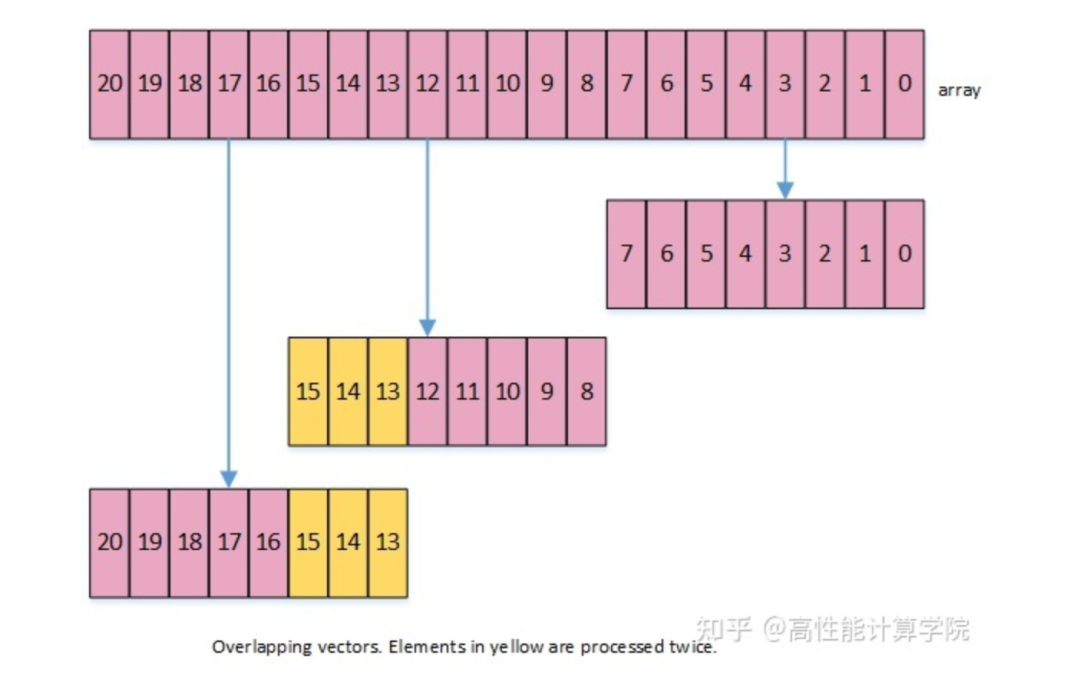
這種做法是在處理尾部數據的時候,從后往前提取一個向量的數據進行計算,這樣會出現一部分數據重復計算。接著2.2.4節的示例,這種方法的實現代碼如下:
#includevoid DownscaleUvNeon(uint8_t *src, uint8_t *dst, int32_t src_width, int32_t src_stride, int32_t dst_width, int32_t dst_height, int32_t dst_stride) { uint8x16x2_t v8_src0; uint8x16x2_t v8_src1; uint8x8x2_t v8_dst; int32_t dst_width_align = dst_width & (-16); int32_t remain = dst_width & 15; int32_t i = 0; for (int32_t j = 0; j < dst_height; j++) { uint8_t *src_ptr0 = src + src_stride * j * 2; uint8_t *src_ptr1 = src_ptr0 + src_stride; uint8_t *dst_ptr = dst + dst_stride * j; for (i = 0; i < dst_width_align; i += 16) { v8_src0 = vld2q_u8(src_ptr0); src_ptr0 += 32; v8_src1 = vld2q_u8(src_ptr1); src_ptr1 += 32; uint16x8_t v16_u_sum0 = vpaddlq_u8(v8_src0.val[0]); uint16x8_t v16_v_sum0 = vpaddlq_u8(v8_src0.val[1]); uint16x8_t v16_u_sum1 = vpaddlq_u8(v8_src1.val[0]); uint16x8_t v16_v_sum1 = vpaddlq_u8(v8_src1.val[1]); v8_dst.val[0] = vshrn_n_u16(vaddq_u16(v16_u_sum0, v16_u_sum1), 2); v8_dst.val[1] = vshrn_n_u16(vaddq_u16(v16_v_sum0, v16_v_sum1), 2); vst2_u8(dst_ptr, v8_dst); dst_ptr += 16; } //process leftover if (remain > 0) { //從后往前回退一次向量計算需要的數據長度,有部分數據是之前處理過的 src_ptr0 = src + src_stride * (j * 2) + src_width - 32; src_ptr1 = src_ptr0 + src_stride; dst_ptr = dst + dst_stride * j + dst_width - 16; v8_src0 = vld2q_u8(src_ptr0); v8_src1 = vld2q_u8(src_ptr1); uint16x8_t v16_u_sum0 = vpaddlq_u8(v8_src0.val[0]); uint16x8_t v16_v_sum0 = vpaddlq_u8(v8_src0.val[1]); uint16x8_t v16_u_sum1 = vpaddlq_u8(v8_src1.val[0]); uint16x8_t v16_v_sum1 = vpaddlq_u8(v8_src1.val[1]); v8_dst.val[0] = vshrn_n_u16(vaddq_u16(v16_u_sum0, v16_u_sum1), 2); v8_dst.val[1] = vshrn_n_u16(vaddq_u16(v16_v_sum0, v16_v_sum1), 2); vst2_u8(dst_ptr, v8_dst); } } }
以上這種方法我們平時用的比較多,不僅可以處理剩余元素,而且可以保持向量處理的高效性。
2.3.3 Process leftovers as single elements
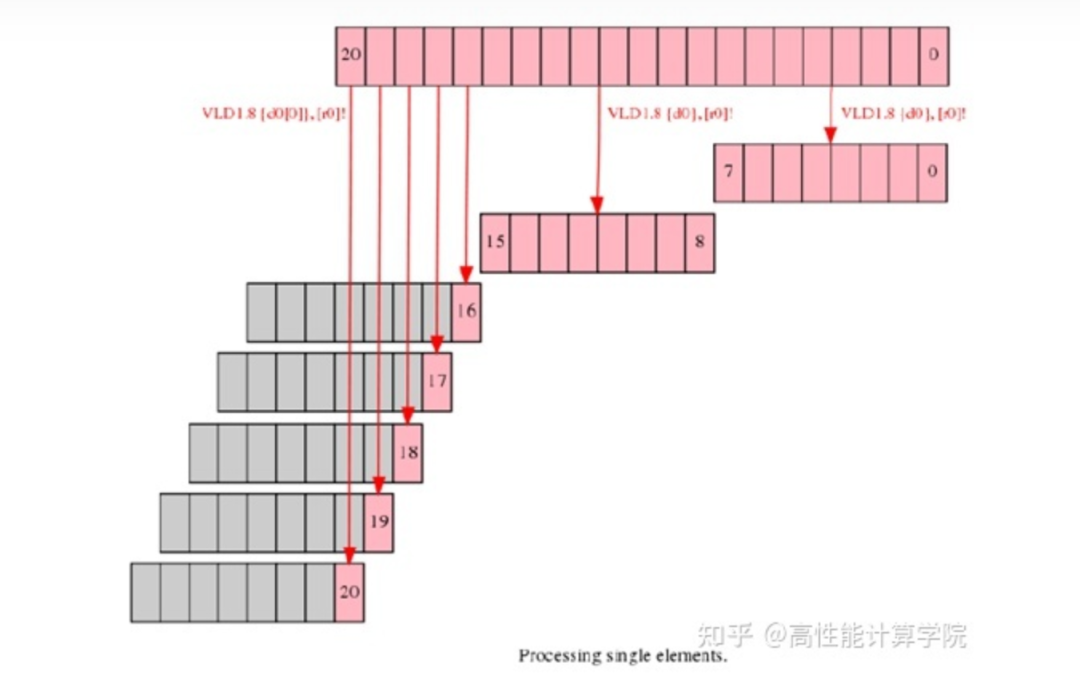
這種做法利用NEON向量可以只加載/存儲一個元素的功能,雖然使用向量指令,但是每個結果獨立計算和存儲。這是一種很不推薦的方法。每次的向量計算只使用一個元素,浪費了計算資源(NEON指令相比于標量指令的執行周期要長,各指令執行時間可以參考文獻[2])。
2.3.4 標量處理剩余部分
剩余部分直接采用標量來處理,這種是最簡單的方法,也是最常用的方法,每行的剩余元素可以簡單的用標量處理,因為絕大部分都是向量計算,剩余元素所占比例非常小,因此使用標量不會對性能產生太明顯的影響。
void DownscaleUvNeonScalar(uint8_t *src, uint8_t *dst, int32_t src_width, int32_t src_stride, int32_t dst_width, int32_t dst_height, int32_t dst_stride)
{
uint8x16x2_t v8_src0;
uint8x16x2_t v8_src1;
uint8x8x2_t v8_dst;
int32_t dst_width_align = dst_width & (-16);
int32_t remain = dst_width & 15;
int32_t i = 0;
for (int32_t j = 0; j < dst_height; j++)
{
uint8_t *src_ptr0 = src + src_stride * j * 2;
uint8_t *src_ptr1 = src_ptr0 + src_stride;
uint8_t *dst_ptr = dst + dst_stride * j;
for (i = 0; i < dst_width_align; i += 16) // 16 items output at one time
{
v8_src0 = vld2q_u8(src_ptr0);
src_ptr0 += 32;
v8_src1 = vld2q_u8(src_ptr1);
src_ptr1 += 32;
uint16x8_t v16_u_sum0 = vpaddlq_u8(v8_src0.val[0]);
uint16x8_t v16_v_sum0 = vpaddlq_u8(v8_src0.val[1]);
uint16x8_t v16_u_sum1 = vpaddlq_u8(v8_src1.val[0]);
uint16x8_t v16_v_sum1 = vpaddlq_u8(v8_src1.val[1]);
v8_dst.val[0] = vshrn_n_u16(vaddq_u16(v16_u_sum0, v16_u_sum1), 2);
v8_dst.val[1] = vshrn_n_u16(vaddq_u16(v16_v_sum0, v16_v_sum1), 2);
vst2_u8(dst_ptr, v8_dst);
dst_ptr += 16;
}
//process leftover
src_ptr0 = src + src_stride * j * 2;
src_ptr1 = src_ptr0 + src_stride;
dst_ptr = dst + dst_stride * j;
for (int32_t i = dst_width_align; i < dst_width; i += 2)
{
dst_ptr[i] = (src_ptr0[i * 2] + src_ptr0[i * 2 + 2] +
src_ptr1[i * 2] + src_ptr1[i * 2 + 2]) / 4;
dst_ptr[i + 1] = (src_ptr0[i * 2 + 1] + src_ptr0[i * 2 + 3] +
src_ptr1[i * 2 + 1] + src_ptr1[i * 2 + 3]) / 4;
}
}
}
三、邊界處理方法
在許多圖像處理算法中,經常會遇到需要處理邊界的情況。例如灰度圖的3x3高斯濾波,為了計算邊界附近點的輸出,需要在原圖的上下左右各填充1個像素的padding。
一種通用的處理方法是申請一塊添加了邊界大小的內存空間,將邊界填充為需要的數據,并且將原有數據復制到新申請的內存空間中,完成擴邊操作(openCV采用的就是這種做法)。這樣新的數據塊中就有了邊界數據,后面的數據處理就很方便了。
但是通用方法不一定是最優的方法,內存申請和填充會增加大量的額外時間,對提升算法性能很不利。我們可以充分利用NEON指令在幾乎不增加時間空間開銷的前提下完成一些特殊的邊界處理。
3.1 常量填充
常量填充就是在有效數據塊的上下左右添加常量邊界值,完成數據的擴充。例如3x3高斯濾波計算需要在上下左右添加1個常量邊界值進行計算。
上下邊界的填充比較簡單,我們只需要使用vdup指令填充一個向量v8_pre_row_data。
左右邊界填充也需要用到dup來的向量v8_const_pad,使用vext來組建新的向量,示意圖及參考代碼如下。
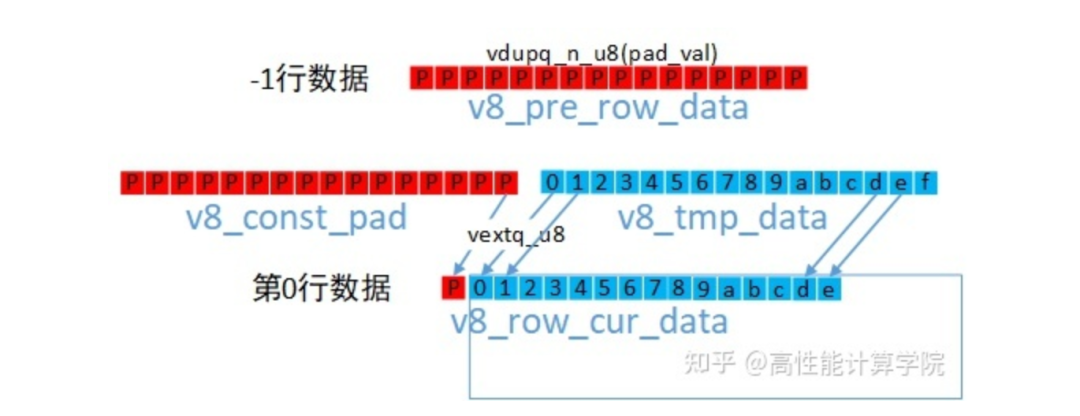
//dup指令生成pading向量 uint8x16_t v8_const_pad = vdupq_n_u8(pad_val); //-1行數據 v8_pre_row_data = v8_const_pad; //讀取第0行數據 uint8x16_t v8_tmp_data = vld1q_u8(pt_row0); //第0行帶有左padding的數據 uint8x16_t v8_row_cur_data = vextq_u8(v8_const_pad, v8_tmp_data, 15); //讀取第1行數據 v8_tmp_data = vld1q_u8(pt_row1); //第1行帶有左padding的數據 uint8x16_t v8_next_row_data = vextq_u8(v8_const_pad, v8_tmp_data, 15);
3.2 復制填充
復制填充就是復制最邊緣的像素作為邊界。我們同樣以3x3高斯濾波計算為例。
上下邊界的方法一樣,我們可以使用vld加載第0行或者最后一行的數據即可。
左右邊界的方法一樣,對于左邊界,我們可以使用VLD1_DUP指令提取邊界數據,然后使用vext來組建新的向量,參考代碼如下。
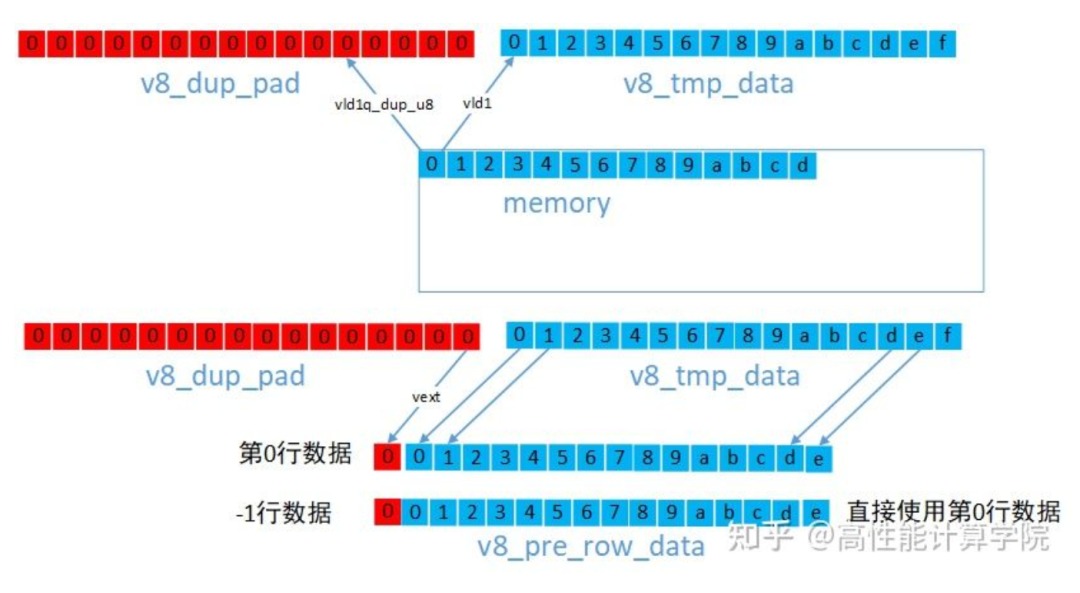
//提取0行padding數據 uint8x16_t v8_dup_pad = vld1q_dup_u8(pt_row0); //提取第0行數據 uint8x16_t v8_tmp_data = vld1q_u8(pt_row0); //第0行帶有左padding的數據 uint8x16_t v8_row_cur_data = vextq_u8(v8_dup_pad, v8_tmp_data, 15); //-1行直接使用第0行 uint8x16_t v8_pre_row_data = v8_row_cur_data; //取1行padding數據 v8_dup_pad = vld1q_dup_u8(pt_row1); v8_tmp_data = vld1q_u8(pt_row1); //第1行帶有左padding的數據 uint8x16_t v8_next_row_data = vextq_u8(v8_dup_pad, v8_tmp_data, 15);
3.3 反射填充
常見的有反射(dcba"abcdefgh"hgfed)和101反射(edcb"abcdefgh"gfed),處理的方式幾乎一樣,我們以稍復雜的101反射介紹,同樣選擇3x3高斯濾波計算舉例。
上下邊界的方法一樣,我們需要根據反射類型,將padding行的數據向量賦值為相應行的數據向量即可。左右邊界的方法一樣,對于左邊界,我們可以使用VLD1指令提取邊界數據,然后使用vrev來翻轉向量內部元素最后使用vext來組建新的向量。
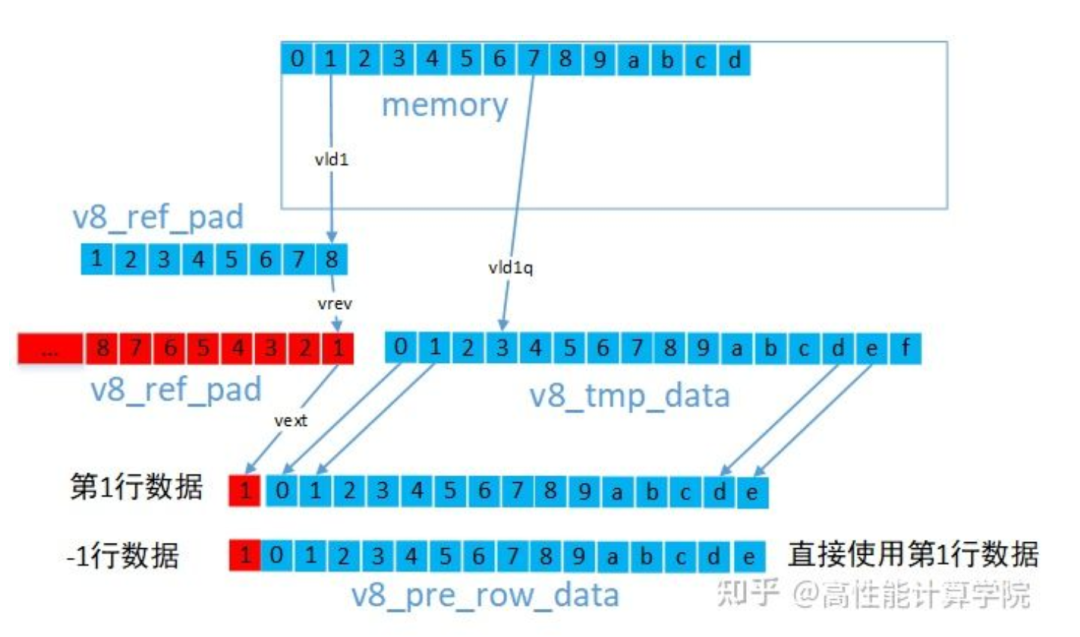
參考代碼:
uint8x8_t v8_ref_pad = vld1_u8(pt_row0 + 1); uint8x8_t v8_ref_pad1; uint8x8_t v8_tmp_data = vld1q_u8(pt_row0); //翻轉數據,用于生成101反射padding v8_ref_pad1 = vrev64_u8(v8_ref_pad); //第0行帶有左padding的數據 uint8x8_t v8_cur_row_data = vextq_u8(vcombine_u8(v8_ref_pad, v8_ref_pad1), v8_tmp_data, 15); v8_ref_pad = vld1_u8(pt_row1 + 1); v8_tmp_data = vld1q_u8(pt_row1); v8_ref_pad1 = vrev64_u8(v8_ref_pad); //第1行帶有左padding的數據 uint8x8_t v8_next_row_data = vextq_u8(vcombine_u8(v8_ref_pad, v8_ref_pad1), v8_tmp_data, 15); //-1行數據 uint8x8_t v8_pre_row_data = v8_next_row_data;
四、優化實例
4.1 說明
我們使用核參數為{{1,2,1},{2,4,2},{1,2,1}}對灰度圖(size:4095x2161)做高斯濾波,邊界填充類型為BORDER_REFLECT101。
4.2 過程分析
整體流程:
Gaussian3x3Sigma0NeonU8C1是主函數
Gaussian3x3RowCalcu是行處理函數,完成一行的處理
第一次處理上邊邊界,然后是中間處理,最后是下邊界處理
int32_t Gaussian3x3Sigma0NeonU8C1(const uint8_t *src, uint8_t *dst, int32_t height, int32_t width, int32_t istride, int32_t ostride)
{
if ((NULL == src) || (NULL == dst))
{
printf("input param invalid!
");
return -1;
}
//BORDER_REFLECT101 top padding
const uint8_t *p_src0 = src + istride;
const uint8_t *p_src1 = src;
const uint8_t *p_src2 = src + istride;
uint8_t *p_dst = dst;
//計算第0行輸出
Gaussian3x3RowCalcu(p_src0, p_src1, p_src2, p_dst, width);
//中間行的處理
for (int32_t row = 1; row < height - 1; row++)
{
p_src0 = src + (row - 1) * istride;
p_src1 = src + (row - 0) * istride;
p_src2 = src + (row + 1) * istride;
p_dst = dst + row * ostride;
Gaussian3x3RowCalcu(p_src0, p_src1, p_src2, p_dst, width);
}
//計算最后一行輸出
p_src0 = src + (height - 2) * istride;
p_src1 = src + (height - 1) * istride;
p_src2 = src + (height - 2) * istride;
p_dst = dst + (height - 1) * ostride;
Gaussian3x3RowCalcu(p_src0, p_src1, p_src2, p_dst, width);
return 0;
}
Gaussian3x3RowCalcu實現
內聯函數,完成一行的處理,基于高斯行列分離計算,先計算行累加,然后計算列累加。
左邊界處理:
static inline int32_t Gaussian3x3RowCalcu(const uint8_t *src0, const uint8_t *src1, const uint8_t *src2, uint8_t *dst, int32_t width) { if ((NULL == src0) || (NULL == src1) || (NULL == src2) || (NULL == dst)) { printf("input param invalid! "); return -1; } int32_t col = 0; uint16x8_t vqn0, vqn1, vs_1, vs, vs1; uint8x8_t v_lnp; int32_t width_t = (width - 9) & (-8); uint8x8_t v_ld00 = vld1_u8(src0); uint8x8_t v_ld01 = vld1_u8(src0 + 8); uint8x8_t v_ld10 = vld1_u8(src1); uint8x8_t v_ld11 = vld1_u8(src1 + 8); uint8x8_t v_ld20 = vld1_u8(src2); uint8x8_t v_ld21 = vld1_u8(src2 + 8); //豎直方向3行的累加和 vqn0 = vaddl_u8(v_ld00, v_ld20); vqn0 = vaddq_u16(vqn0, vshll_n_u8(v_ld10, 1)); vqn1 = vaddl_u8(v_ld01, v_ld21); vqn1 = vaddq_u16(vqn1, vshll_n_u8(v_ld11, 1)); //生成padding數據 vs_1 = vextq_u16(vextq_u16(vqn0, vqn0, 2), vqn0, 7); vs1 = vextq_u16(vqn0, vqn1, 1); //水平方向累加和 vs = vaddq_u16(vaddq_u16(vqn0, vqn0), vaddq_u16(vs_1, vs1)); v_lnp = vqrshrn_n_u16(vs, 4); vst1_u8(dst, v_lnp); vs_1 = vextq_u16(vqn0, vqn1, 7); // for循環...... }
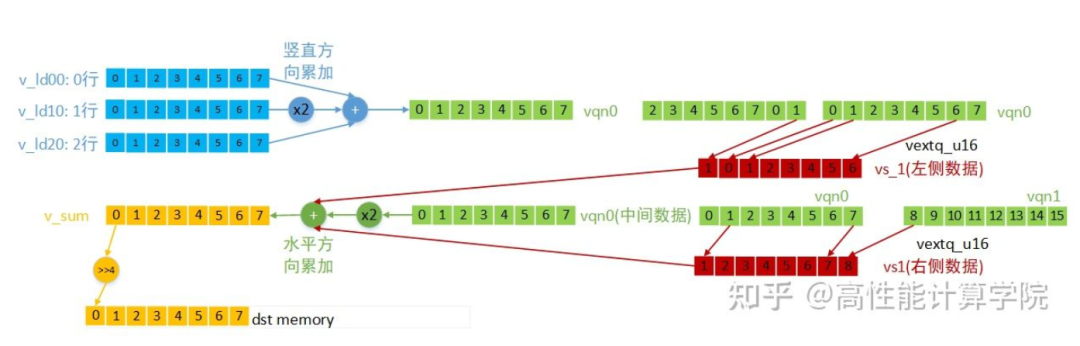
中間部分處理
第二部分for循環是計算中間部分數據的結果,先做豎直方向的累加,再做水平方向的累加,每次計算8個輸出結果。各向量的數據含義及計算方法(for循環第一次計算)見下圖。
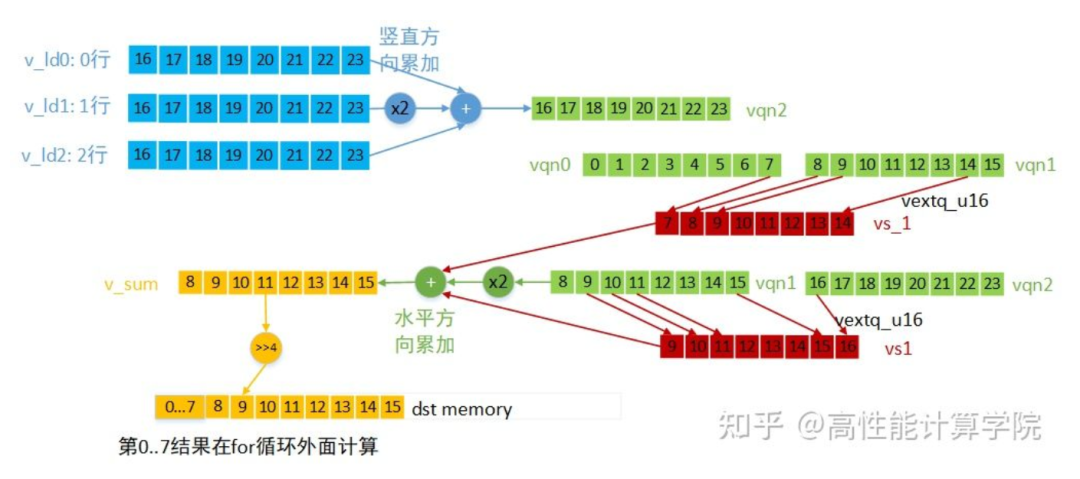
最后一次的向量計算單獨處理,為了防止提取下一組數據時越界。
static inline int32_t Gaussian3x3RowCalcu(const uint8_t *src0, const uint8_t *src1, const uint8_t *src2, uint8_t *dst, int32_t width)
{
// 計算前8個輸出......
for (col = 8; col < width_t; col += 8)
{
// 3行的輸入數據
uint8x8_t v_ld0 = vld1_u8(src0 + col + 8);
uint8x8_t v_ld1 = vld1_u8(src1 + col + 8);
uint8x8_t v_ld2 = vld1_u8(src2 + col + 8);
//豎直方向的累加和
uint16x8_t vqn2 = vaddl_u8(v_ld0, v_ld2);
vqn2 = vaddq_u16(vqn2, vshll_n_u8(v_ld1, 1));
//水平方向累加和
vs1 = vextq_u16(vqn1, vqn2, 1);
uint16x8_t vtmp = vshlq_n_u16(vqn1, 1);
uint16x8_t v_sum = vaddq_u16(vtmp, vaddq_u16(vs1, vs_1));
uint8x8_t v_rst = vqrshrn_n_u16(v_sum, 4);
vst1_u8(dst + col, v_rst);
vs_1 = vextq_u16(vqn1, vqn2, 7);
vqn1 = vqn2;
}
//最后一組向量計算,為了防止越界讀取數據,右側數據只讀取一個
{
uint8x8_t v_ld0 = vld1_lane_u8(src0 + col + 8, v_ld0, 0);
uint8x8_t v_ld1 = vld1_lane_u8(src1 + col + 8, v_ld1, 0);
uint8x8_t v_ld2 = vld1_lane_u8(src2 + col + 8, v_ld2, 0);
uint16x8_t vqn2 = vaddl_u8(v_ld0, v_ld2);
vqn2 = vaddq_u16(vqn2, vshll_n_u8(v_ld1, 1));
vs1 = vextq_u16(vqn1, vqn2, 1);
uint16x8_t vtmp = vshlq_n_u16(vqn1, 1);
uint16x8_t v_sum = vaddq_u16(vtmp, vaddq_u16(vs1, vs_1));
uint8x8_t v_rst = vqrshrn_n_u16(v_sum, 4);
vst1_u8(dst + col, v_rst);
col += 8;
}
//process leftovers...
}
最后剩余的非對齊部分我們使用標量進行計算。
static inline int32_t Gaussian3x3RowCalcu(const uint8_t *src0, const uint8_t *src1, const uint8_t *src2, uint8_t *dst, int32_t width)
{
// 向量計算部分......
for (; col < width; col++)
{
int32_t idx_l = (col == width - 1) ? width - 2 : col - 1;
int32_t idx_r = (col == width - 1) ? width - 2 : col + 1;
int32_t acc = 0;
acc += (src0[idx_l] + src0[idx_r]);
acc += (src0[col] << 1);
acc += (src1[idx_l] + src1[idx_r]) << 1;
acc += (src1[col] << 2);
acc += (src2[idx_l] + src2[idx_r]);
acc += (src2[col] << 1);
uint16_t res = ((acc + (1 << 3)) >> 4) & 0xFFFF;
dst[col] = CAST_U8(res);
}
return 0;
}
4.3 運行結果
下圖是我們在高通驍龍888平臺上的運行結果,可以看到使用NEON優化之后運行時間從15.53ms下降到了3.22ms,性能有了4倍多的提升。感興趣的讀者可以自己運行下結果。

4.4 工程代碼?https://github.com/mobile-algorithm-optimization/guide/tree/main/NeonGaussian
編輯:黃飛










 工商網監
工商網監
評論