 電子發燒友App
電子發燒友App


在雄心勃勃的將 CPU 和 GPU 集成到芯片中的計劃突然逆轉后,英特爾終于提供了有關其超級計算芯片路線圖的大規模更改的具體細節。
該芯片制造商分享了即將推出的名為 Falcon Shores 的芯片的更多細節,該芯片最初被定為 XPU(統一的 CPU 和 GPU)。Falcon Shores 現在是一款純 GPU 產品,并針對科學和 AI 計算進行了重新配置。
?
“我之前推動并強調將 CPU 和 GPU 集成到 XPU 中還為時過早。原因是,我們覺得我們所處的市場比我們一年前想象的要活躍得多,”英特爾公司副總裁兼超級計算事業部總經理 Jeff McVeigh 在新聞發布會上說。
新的 Falcon Shores 芯片是面向高性能計算和 AI 的下一代獨立 GPU。它包括來自 Gaudi 系列的 AI 處理器(在 Falcon Shores 發布時將是第 3 版),還包括標準以太網交換、HBM3 內存和大規模 IO。
“這提供了跨供應商的靈活性,可以將 Falcon Shores GPU 與其他 CPU 以及 CPU 與 GPU 的結合起來,同時仍然提供非常通用的基于 GPU 的編程接口,并在 CPU 和 GPU 之間共享 CXL,以提高生產力和性能對于這些代碼,”McVeigh 說。
Falcon Shores GPU 是代號為 Ponte Vecchio 的 Max 系列 GPU 的繼任者,現在將于 2025 年推出。英特爾在 3 月份廢棄了代號為 Rialto Bridge 的超級計算機 GPU,該 GPU 是 Ponte Vecchio 的指定后續產品。
McVeigh 說,計算環境還不成熟,無法實施 XPU 戰略,并補充說,圍繞生成式人工智能和大型語言模型的創新——其中大部分來自商業領域——引發了英特爾關于如何構建下一代超級計算芯片的思維轉變。
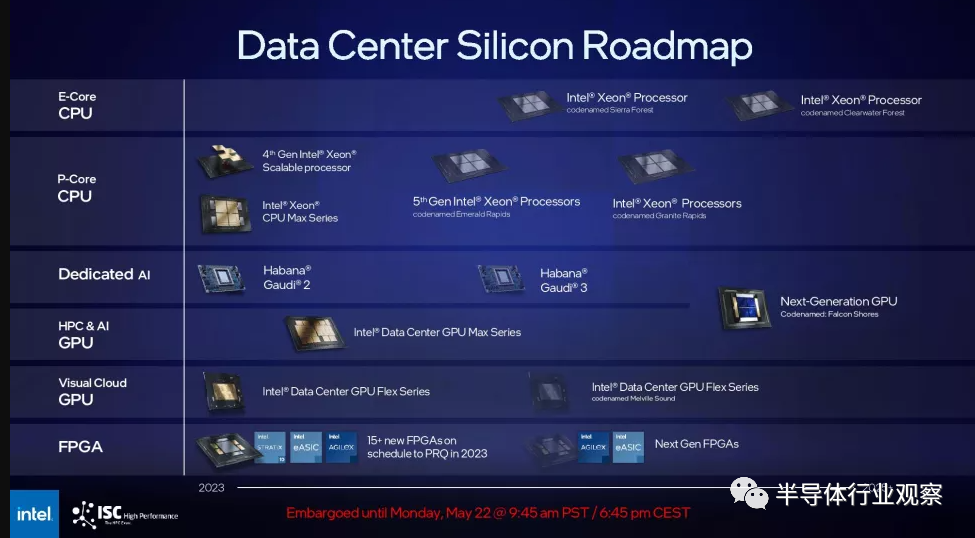
與此同時,英特爾還發布了新的 HPC 和 AI 路線圖,其中沒有顯示 Gaudi3 處理器的繼任者——相反,Gaudi 和 GPU 與 Falcon Shores GPU 合并,因為它繼承了英特爾首屈一指的 HPC 和 AI 芯片。英特爾告訴我們,它“計劃整合 Habana 和 AXG 產品 [GPU] 路線圖”,但整合的細節很少。
Gaudi 計算架構與標準 GPU 有很大不同,因此其計算架構似乎無法完全集成到 GPU 中。因此,英特爾可以將Gaudi設計的較小部分(例如其網絡接口或其他 IP 塊)整合到其 GPU 中。回顧一下,英特爾為 Habana Labs 支付了 20 億美元,并取消了其 3.5 億美元收購 Nervana 的產品,以專注于 Gaudi 芯片。

然而,如上所示,Falcon Shores 的原始計劃確實包括通過將不同數量的 CPU 或 GPU 塊放入四塊設計中來調整 CPU/GPU 的能力,從而允許它配置最佳混合各種工作量。此外,從設計上講,處于前沿的超級計算機是針對手頭任務的高度專業化設計,針對架構的軟件調整只是運行超級計算機業務的常規部分。這些因素意味著 CPU/GPU 比率并不是英特爾從設計中移除 CPU 內核的唯一原因。
生成式 AI 和 LLM 將在科學計算中得到廣泛采用,CPU 和 GPU 的解耦將為具有不同工作負載的客戶提供更多選擇。
“當您身處工作負載瞬息萬變的動態市場時,您真的不想強迫自己走固定 CPU 與 GPU 的道路。你不想修復供應商甚至所使用的架構……x86,Arm。” McVeigh說。
CPU 和 GPU 的集成可以降低成本并節省電力,但它會將客戶鎖定在供應商和配置上。但這將隨著新的 Falcon Shores 的出現而改變,McVeigh表示,他補充說:“我們只是覺得要對今天的市場進行清算,現在還不是整合的時候。”
雖然在不久的將來不會將 CPU 和 GPU 合并用于超級計算,但英特爾并沒有放棄這個想法。
“我們會在合適的時間,”McVeigh說,并補充道,“當天氣合適的時候,我們會這樣做。我們只是覺得這不適合下一代。”
獨立的 GPU 還將為供應商提供更大的靈活性,讓他們可以使用具有 x86 以外的不同 CPU 的 GPU 構建系統。英特爾已達成協議,可能會在其工廠生產基于 Arm 的芯片。
服務器設計也有望隨著 CXL(Compute Express Link)互連而改變,這鼓勵組件解耦,因此 GPU、AI 芯片和其他加速器可以輕松訪問大型存儲和內存池。
“問題是,這通常落在我們的 OEM 合作伙伴的肩上,他們希望如何將我們的 GPU 與其他供應商的 CPU 集成,但我們為實現這一目標敞開大門,并利用 PCI Express 等標準接口,和 CXL 等等,使我們能夠非常有效地做到這一點,”McVeigh說。
但英特爾面臨來自 AMD 的 Instinct MI300 的挑戰,該產品預計將于今年晚些時候發貨,并將為勞倫斯利弗莫爾國家實驗室的 2 exaflops(峰值)超級計算機 El Capitan 提供動力。Nvidia 目前在商業生成人工智能市場占據主導地位,該公司的 H100 GPU 在谷歌、Facebook 和微軟運營的數據中心運行。
英特爾將利用 Falcon Shores 的 GPU 編程模型,類似于 Nvidia 采用的 CUDA 編程框架。英特爾的 OneAPI 工具包有一系列編譯器、庫和編程工具,可以在 Falcon Shores GPU、Gaudi AI 處理器和英特爾將放入超級計算芯片的其他加速器上執行。
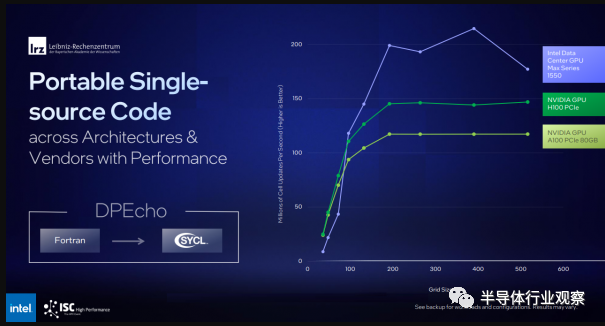
OneAPI 中名為 SYCL 的工具可以編譯超級計算和 AI 應用程序,以在 Intel、Nvidia 和 AMD 的一系列硬件上運行。它還可以通過剝離特定于 CUDA 的代碼來重新編譯為 Nvidia GPU 編寫的應用程序。例如,LRZ 從 Fortran 移植了 DPEcho 天體物理學代碼,并且能夠在 Intel 和 Nvidia GPU 上有效運行(下面的基準測試幻燈片)。
英特爾分享了除 GPU 課程修正之外的其他披露信息。
該芯片制造商為其 Aurora 超級計算機交付了超過 10,624 個采用 HBM 的 Xeon Max 系列芯片計算節點,其中包括 21,248 個 CPU 節點、63,744 個 GPU、10.9PB 的 DDR 內存和 230PB 的存儲空間。
“在全面優化、交付代碼和驗收方面,我們還有很多工作要做。但這是一個至關重要的里程碑,我們……非常高興能夠實現,”McVeigh說。
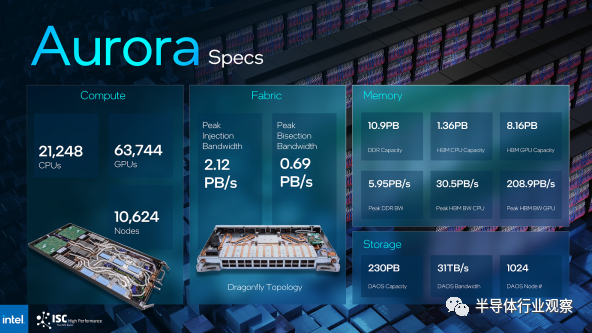
這個里程碑對英特爾來說很重要,因為 Aurora 的部署已經被推遲。這臺有望突破 2 exaflops(峰值)門檻的超級計算機將無法躋身今年 5 月全球最快超級計算機 Top500 榜單。
“我們真正專注于推出整個系統……穩定并運行……獲得真正的工作負載,而不僅僅是運行和運行的基準。我們預計到 11 月,我們將在 Top500 系統中提供強大的產品,”McVeigh 說。
最近在戴爾主辦的網絡研討會上,Rick Stevens(阿貢實驗室)分享說,Frontier 每年將為關鍵的科學工作負載貢獻大約 7800 萬個四 GPU 小時。
包括英特爾、HPE 和阿貢國家實驗室在內的主要 HPC 參與者正在聯手開發一種名為 AuroraGPT 的科學計算大型語言模型,該模型建立在 1 萬億個參數的基礎模型之上,比 ChatGPT 大得多,后者是建立在 GPT-3 基礎模型之上。
生成式人工智能技術將基于可用的科學數據和文本以及代碼庫,并像商業大型語言模型一樣發揮作用。目前尚不清楚該技術是否會是多模態,并生成圖像和視頻。如果它是多模態的,一個例子可能是研究人員提出問題,人工智能提供響應,或者使用人工智能生成科學圖像。
LLM將用于“推動科學發展并利用 Aurora 進行訓練,其推論將成為系統部署方式的關鍵部分,”McVeigh 說。
AuroraGPT 可用于材料、癌癥和氣候科學的研究。基礎模型包括 Megatron 和 DeepSpeed 變壓器。
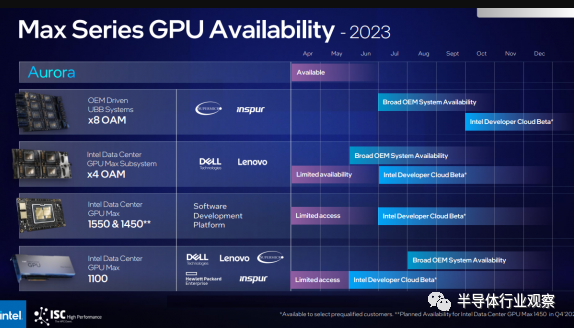
英特爾還宣布將推出一款通用基板 (UBB) 系統,該系統最初采用基于 Supermicro 和 Inspur 的設計,配備八個 Ponte Vecchio Max 系列 GPU(如標題圖片所示)。這些服務器針對 AI 部署,McVeigh 表示支持 8-GPU 配置。該產品于今年早些時候推出,預計將在第三季度推出。
編輯:黃飛













 工商網監
工商網監
評論