 電子發燒友App
電子發燒友App


1. 引言
前文介紹了Arm公司近幾年在移動處理器市場推出的Cortex-A系列處理器。Cortex-A系列處理器每年迭代,性能和能效不斷提升,是一款非常成功的產品。但是,Arm并不滿足于Cortex-A系列每年的架構小幅度升級,又推出了X計劃,也就是Cortex-X產品線。Cortex-X系列處理器采用了激進的架構設計,大幅度提升移動處理器的性能(俗稱超級大核),本文將重點介紹Arm的Cortex-X系列產品。
2. X計劃起源
Cortex-X計劃起源可以追溯到2016年,當時Arm推出了一個新的客戶Licence叫做“Build on Cortex”,允許用戶請Arm基于Cortex核心做一些定制優化,如可以增加或者減少Cache數量等,客戶如高通公司一直是該計劃的使用方,用于開發和迭代每年的Kyro系列處理器。到了2020年,Arm公司正式宣布推出Cortex-X這一全新的高性能處理器設計計劃。Cortex-X計劃的目標是為高端移動平臺、云服務場景、邊緣計算和高性能計算設備提供更快、更強大的處理器核心。
Cortex-X系列定制處理器計劃,相比2016年的定制方案要更加深入,Cortex-X系列處理器的目標是給用戶提供足夠強大性能的核心,在此計劃下芯片廠商可以早期參與Arm的Cortex處理器架構設計,并基于 Cortex-X 核心進行定制優化,以適應自己的產品需求。但是從產品的表現看,由于Arm每年都在迭代Cortex-X系列處理器(2023,第四年,預計會更新Cortex-X4),迭代速度和周期都非常快,芯片廠商并沒有針對X系列處理器特殊定制微架構,而是通過搭配不同尺寸的緩存,設計出面向不同價位段的產品。
Cortex-X系列的出現,和市場競爭日益激烈,芯片廠商有較強需求相關。市場上,蘋果公司堅持自己研發A系列處理器, 蘋果的A系列處理器是專為iPhone和iPad設備設計的自研處理器,基于Arm指令集,蘋果自己設計并優化了微架構。從2010年推出的A4處理器開始推出第一款量產產品,當前蘋果A系列處理器已發展到A16(2022年)。A系列處理器一直采用較為激進的微架構設計,通過強大的計算能力領先行業。最新A16還是保持Armv8指令集,沒有升級到Armv9指令集,最后我們會簡單對比下Cortex-X系列和蘋果的A系列處理器的差異。
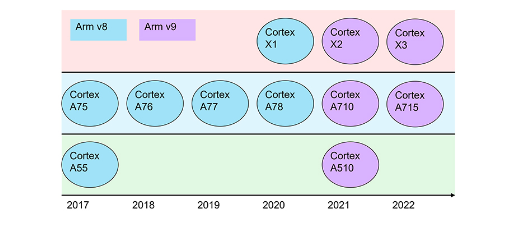
2017年至2022年的Arm系列處理器
?
3. Cortex-X1:第一代Cortex-X處理器
2020年5月,Arm發布了基于Armv8.2架構的最后一款處理器Cortex-A78,同時還發布了一顆性能更強大的Cortex-X1處理器。Cortex-X1 處理器比之前的 Cortex-A77 提升了 30% 的性能,由于采用大緩存的設計架構,還提升了 23% 的芯片能效。簡單總結下,X1提供了更強的性能,整體更優秀的能效,但是極限功耗高于Cortex-A78。

Cortex-X1性能強大,能效有明顯改善,但是由于增大了緩存和處理單元,使得芯片的整體面積增大不少,廠商往往出于成本考慮,一般在處理器中只會放置一顆Cortex-X系列處理器來提升單線程的峰值性能。從Cortex-X1出現后,市場上的旗艦處理器架構發生了變化,逐步從4+4架構,演變成有一個超級大核心的1+3+4架構。
下圖是一個典型示意圖,在5nm工藝下如果僅升級到A78,性能提升20%,面積可以減少15%;在5nm工藝下升級到1個X1+3個A78,L3增大,峰值性能可以提升30%,但是面積要增加15%,一來一回差異30%芯片面積,這樣看來,旗艦芯片要漲價也情有可原了。

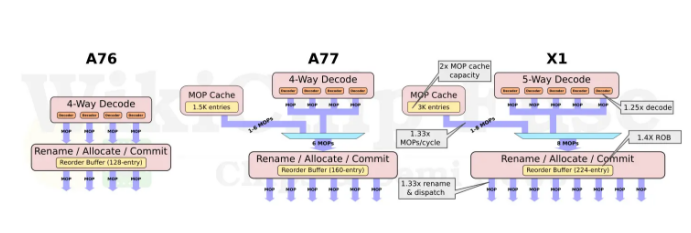
我們看一下Cortex-X1的微架構細節,相比A78,Cortex-X1具體有以下提升:
1、BPU分枝預測單元的L0 BTB從64提升到96,增加50%;
2、前端Decode從4路提升到5路;
3、MOP通路從6路提升到8路;
4、MOP Cache從1.5K提升到3K,增大一倍;
5、ROB緩沖從160(推測)提升到224(參考,AMD的Zen2處理器的ROB是224);
6、L1L2L3都較大,分別是64KB起、256KB起、最多8MB;
7、執行單元整數和存儲部分變化不大,浮點單元相比A78提供了2倍的NEON單元,可以同時提供4個128bit運算能力;
8、存儲單元通路雖然沒有變化,但是其LoadStore的緩沖數量增加了33%。
下面用一張表格列舉了一些微架構的核心變化:
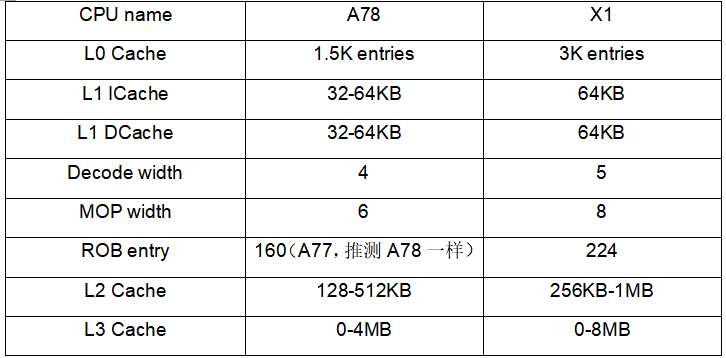
第一代的Cortex-X1還是使用的Armv8.2的指令集,并沒有升級到Armv9,似乎Arm覺得要在2021年同時發布Armv9和全新的Cortex-A、Cortex-X系列壓力有點大,所以提前將Cortex-X1的發布放在了2020年。
可惜,Cortex-X1的命運可謂生不逢時,2020年采用Cortex-X1的典型旗艦處理器有三星的Exynos 2100和高通的Snapdragon 888,這兩款處理器都搭載了三星的5nm工藝(5LPE),這一次三星工藝翻車了,架構的提升得不到工藝的補償,導致這兩款處理器的性能和功耗的表現都不是很好。目前(2023年)市面上還活躍著不少采用A78處理器架構的芯片,如MTK的天璣8100、8200等處理器,但是已經鮮少看到搭載Cortex-X1處理器的芯片了。
4. Cortex-X2:第二代Cortex-X處理器
2021年5月,Arm的Cortex-X2系列處理器如期而至。這一次,Cortex-X2正式升級到了Armv9新架構,搭載了SVE2指令集,并且只支持運行64bit軟件。還記得A710的產品代號叫做Matterhorn么?這一代Arm為了更好的記憶產品代號,將Cortex-X2處理器的產品代號命名為Matterhorn-ELP,后續Cortex-X系列應該也是基于同期Cortex-A系列的產品代號,增加ELP后綴,ELP的全稱是Enhanced Lead Partner的意思。
第一代的Cortex-X1由于搭配工藝的原因導致整體不佳的表現并沒有掩埋Cortex-X系列微架構的成功,Arm計劃將Cortex-X系列發揚光大,后續我們看到的也是每年一更新的快速迭代節奏。如此快速的更新節奏,芯片廠商也很難深度定制,后續各大廠商發布的幾款采用Cortex-X系列處理器的產品,還是采用了Arm的公版架構,基于產品的價位段,在Cache容量上做一些差異化的配置。

從上圖中可見,Arm對于兩個系列的策略有所不同,Cortex-A系列主打均衡能效并小幅度改善性能 ,Cortex-X2相比Cortex-X1在性能上有更明顯的提升,進一步拉開了A系列和X系列的性能差距,由此可見Cortex-X系列的目標是推進Arm核心架構的算力提升和突破。
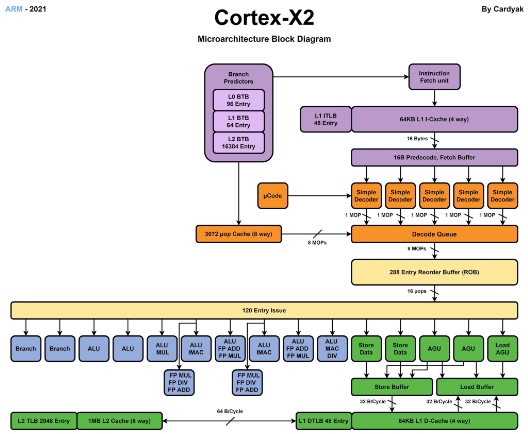
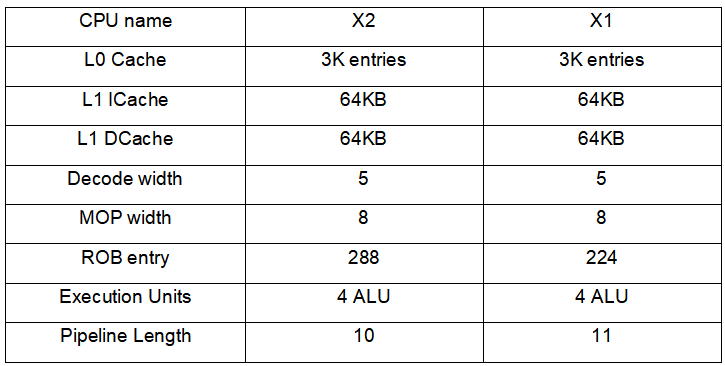
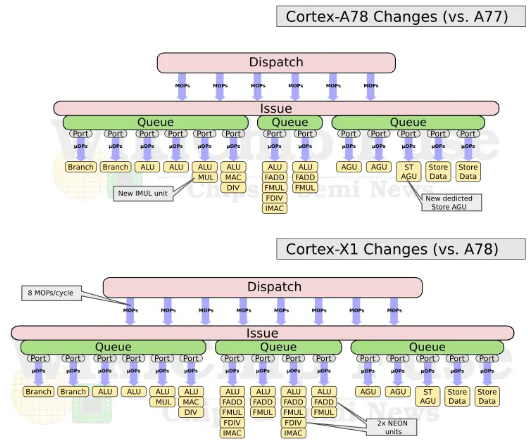
從互聯網上可以找到Cortex-X2的微架構框圖,我們可以此對比Cortex-X2和Cortex-X1的微架構差異,并分析影響性能提升的因素。Cortex-X2相比Cortex-X1,在微架構上有以下變化:
1、將分支預測和Fetch解耦,提升并行度;
2、指令流水線從11級減少到10級,dispatch從2個時鐘周期減少到1個時鐘周期;
3、ROB緩沖從224提升到288,提升了30%;
4、支持SVE2 SIMD指令集;
5、ML能力支持Bfloat16;
6、取消了Aarch32支持;
7、LoadStore結構體緩沖提升33%;
8、d-TLB從40提升到48,提升了20%;
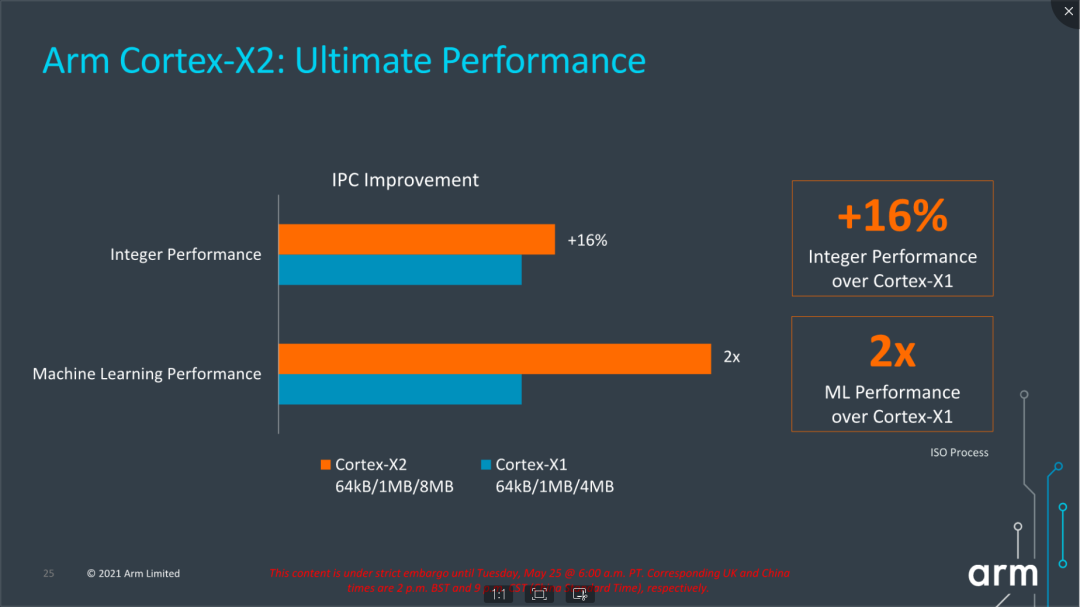
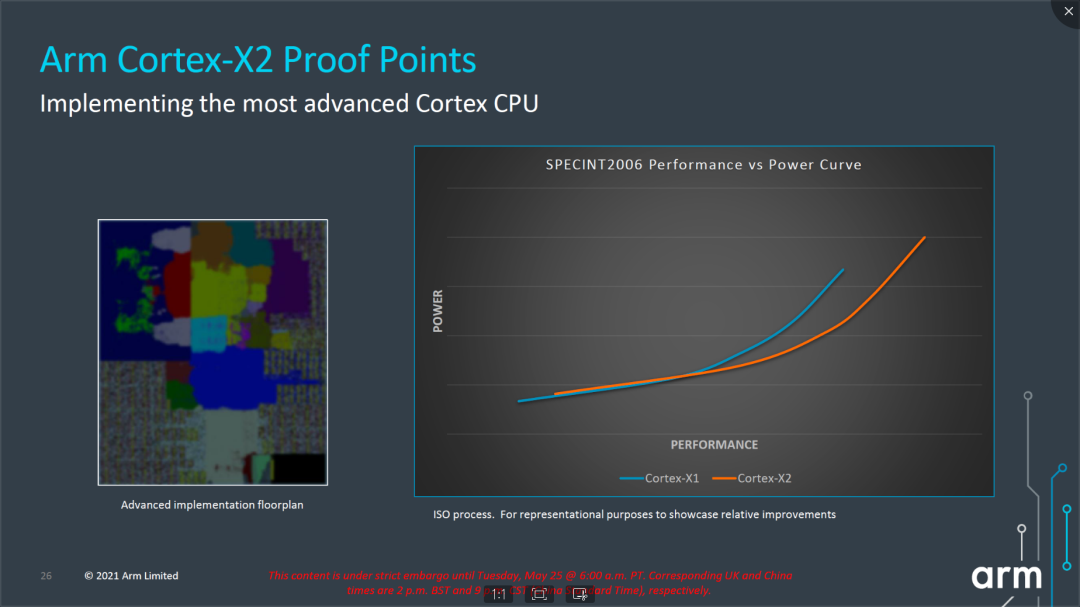
再來看看具體性能數據,Arm宣稱Cortex-X2相比Cortex-X1在整數性能上提升了16%,在ML能力上提升了2倍。回顧一下A710,Arm宣稱的數據是相比A78提升了10%的整數性能。從能效曲線上看,Cortex-X2的最大性能和功耗都有增加,能效在低頻率區間和Cortex-X1差異不大,在中高頻率區間相比Cortex-X1有改善。由于極限功耗持續增加,對于散熱能力和發熱策略改善提出了更大的訴求和壓力。
2021年,第一代搭載了Cortex-X2的處理器高通8Gen1,由于采用了三星4nm LPX工藝,性能功耗的表現不是很理想,后續高通將工藝切換到臺積電4nm工藝,在2022年推出了同樣設計的8+Gen1處理器,宣稱CPU功耗降低了30%,這才發揮出了Cortex-X2的實力,目前有多部熱門手機搭載,當前也是Cortex-X系列產品中賣的最好一代。
5. Cortex-X3:第三代Cortex-X處理器
2022年6月,市場上還在關注升級新工藝的Cortex-X2系列處理器產品時,Arm發布了當年的新品Cortex-X3,Cortex-X3的代號是Makalu-ELP,和同期Coretex-A715的代號Makalu保持一致。2021年的Cortex-X2肩負著升級Armv9指令集的任務,在微架構上的修改上相比第一代并不是很多。新一代的Cortex-X3在微架構上的升級和變化要更多一些,后續我們會詳細分析。性能上,Arm宣稱Cortex-X3在性能相比上一代IPC提升11%,綜合性能有22%的提升(包含工藝的提升)。

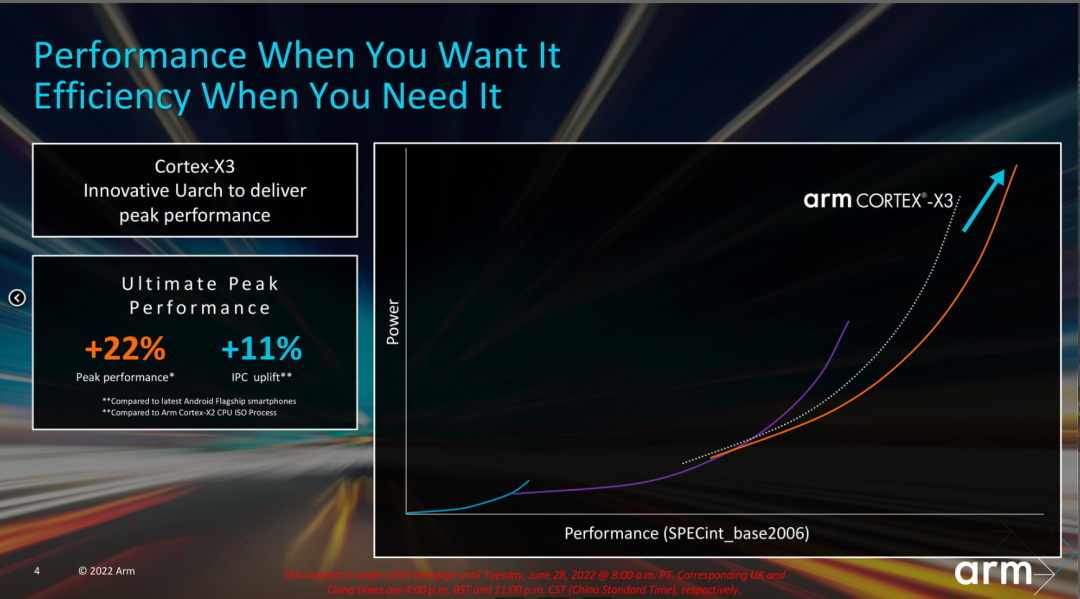
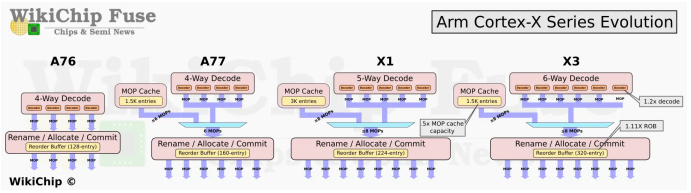
從Cortex-X2開始,X系列處理器就不再支持32bit應用,這一代Arm繼續針對64bit進行微架構的優化,通過剔除和優化一些陳舊的32bit兼容設計,進一步提升64bit應用程序的執行效率。
下面我們具體看一下Cortex-X3微架構相比上一代的變化:
1、MOP Cache尺寸變化。隨著半導體工藝的持續演進,接下來的3nm新工藝將繼續縮小半導體器件的尺寸,但是,在半導體中SRAM的尺寸并沒有隨器件尺寸縮小而同步縮小。如何減少SRAM的占用,是對先進工藝設計提出的一個考驗。在Cortex-X3的前端設計中,Arm將L0的MOP Cacha的SRAM從上一代的3K減少到1.5K,推測也是為了減少未來在先進工藝中SRAM的占比。同時,Arm提出通過優化Cache的填充算法,來做到盡量不影響性能。記得MOP Cache在A77引入時就有討論過,1.5K的容量就可以達到85%的命中率,增加容量帶來的邊際效益也增加,所以增大Cache帶來的效果提升會越來越小,所以這次Arm將Cortex-X3的MOP Cache降低到1.5K(同期的A715則是取消了MOP Cache)。
2、Fetch-decode通路從5路提升到6路,Fetch能力提升了20%;
3、在ROB重排序緩沖區上,上一代Cortex-X2是228個,Cortex-X3繼續提升11%,達到了320 entries;

4、Arm繼續提升Cortex-X3的分支預測能力,L1 BTB從64提升到96,L2 BTB從16384提升到24576。分支預測單元通過解耦合設計,和Fetch形成兩條核心指令通路,大幅提升同步執行效率,一旦發生了分支錯誤,可以快速從BTB緩沖中拿到需要的指令,進行快速切換。通過這些優化,Arm宣稱平均分支預測延遲周期數減少了12.2%,整體執行流程中Stall占比降低了3%;

5、在分支預測模塊上持續優化,Cortex-x3中為indirect branches新增了一個獨立預測單元,并提升了conditional branches的準確率,Arm宣稱平均的分支預測錯誤率可以降低6.1%;

6、流水線的優化,Cortex-X3繼續優化了流水線,從10級優化到9級,主要是優化了MOP Cache的讀取周期;

7、執行單元上,這次Cortex-X3大幅度提升了整型ALU的數量,從4個提升到6個,是一個比較大的變化,整體從2個branch+2個ALU變化為2個branch+4個ALU,主要是提升了整型性能;

8、訪存單元上,因為提升了ALU的數量,相應的整型讀取帶寬也從24提升到了32,并且增加了兩個額外的數據預取模塊。
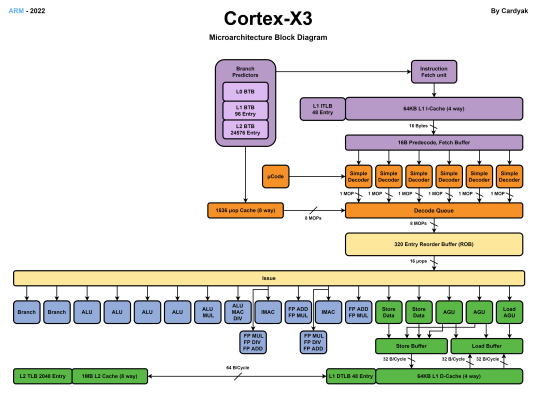
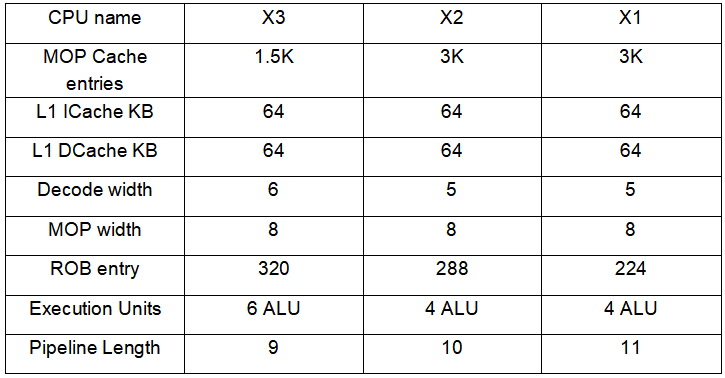
上面是Cortex-X3的微架構框圖,我們把X1至X3放在同一張表中對比:
6、Cortex-X3和蘋果處理器的對比
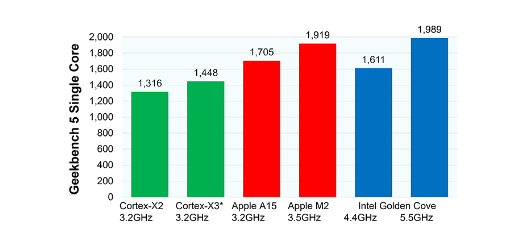
Cortex-X系列處理器通過三代的迭代,不斷升級微架構提升性能,其單核心有明顯提升,已經在拉近蘋果A系列處理器和Intel臺式機處理器的差距。圖中對比了不同處理器的單核心的性能,可以看到Cortex-X3相比Cortex-X2有進一步的提升,距蘋果的A15處理器還有一些差距。目前我還沒有找到蘋果A15處理器的微架構,但是有找到2020年A14處理器大核心(Firestorm)的微架構,下面通過表格做了一個對比。
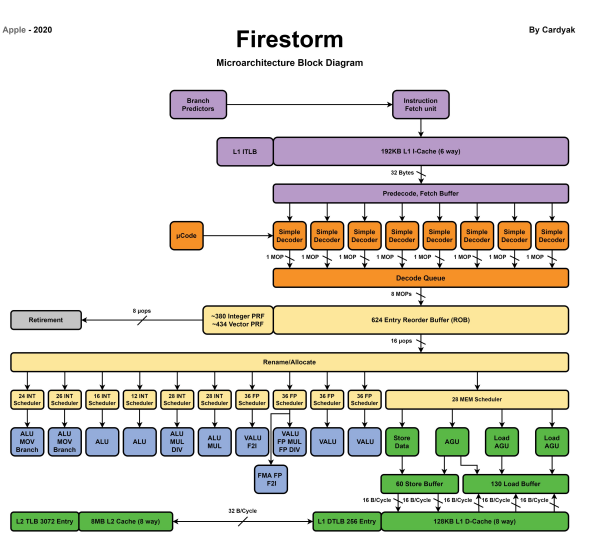
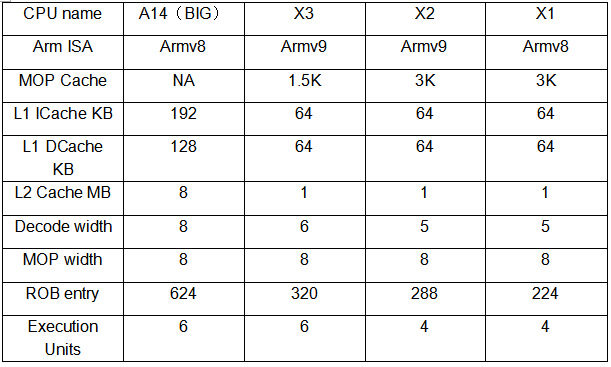
從Cortex-X系列和蘋果A14的對比可以看出,蘋果在設計A系列處理器時對于微架構的調整更加激進,采用了更大的L1、L2緩存,Decoder數量更多,而ROB緩沖的尺寸幾乎是Cortex-X系列的一倍,這也對于指令重排序的效率和算法優化能力提出了更高的要求。
雖然Cortex-X系列每年迭代,相比蘋果的A系列激進的設計,目前還存在一定的差距。但是隨著Cortex-X系列處理器的每年迭代更新,我們也希望看到在微架構能力上打平甚至超過競品的那一天。
由于蘋果在A系列處理器采用大緩存大尺寸設計,在智能手機產品中一般是放置兩顆大核心,采用2+4的架構。采用Cortex-X系列處理器的安卓手機,一般采用八核心的架構,例如最新的高通8Gen2處理器,采用1個Cortex-X3+2個A715+2個A710+3個A510的組合架構,提供了5個大核心的算力,在多核心算力上相比6核心有多2個核心的優勢,一定程度上彌補了多核心的差距。
?
7、總結和對Cortex-X4處理器的期望
距2023年中Arm發布Cortex-X4處理器的時間不遠了,下一代的Cortex-X4處理器的代號叫做Hunter-ELP,期望這一代的“獵人”能給我們帶來更多的驚喜,新的架構改了什么地方,有多少性能提升,我也會第一時間關注和分享。
Arm公司通過三年時間迭代Cortex-X系列處理器,每年的性能上都有兩位數的提升,切實讓消費者使用上了更快更強的處理器和產品,這半年來,采用Cortex-X2和Cortex-X3系列架構的高通8+Gen1、8Gen2、MTK的天璣9200等處理器的市場口碑都很不錯。
此外,高通的8Gen2處理器還第一次打破了傳統4顆大核心的架構,提供了1+4+3的5顆大核心配置組合。期望未來的產品不但可以看到Arm的最新架構,而且可以看到更多有意思的CPU核心架構組合,如果可以在一個處理器中放置多顆Cortex-X核心,相信基于Cortex-X系列的Arm處理器也可以挑戰蘋果 A系列處理器綜合性能。
編輯:黃飛
?













 工商網監
工商網監
評論