NVIDIA 推出的CUDA(計算統(tǒng)一設(shè)備架構(gòu))是基于GPU 進行通用計算的開發(fā)平臺,非常適合大規(guī)模的并行數(shù)據(jù)計算。在GPU 流處理器架構(gòu)下用CUDA 技術(shù)實現(xiàn)編碼并行化,并針對流處理器架構(gòu)特點進行
2018-01-18 07:30:00 5394
5394 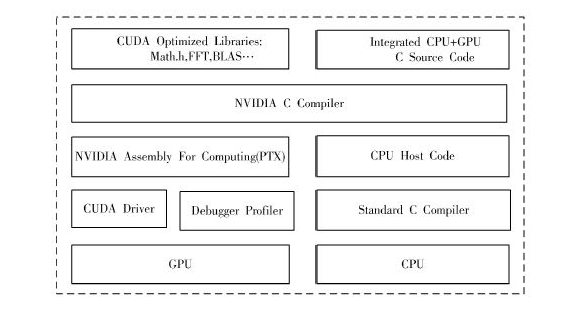
具有許多小 CUDA 內(nèi)核的應(yīng)用程序通常可以使用 CUDA 圖進行加速,即使內(nèi)核啟動模式在整個應(yīng)用程序中發(fā)生變化。鑒于這種動態(tài)環(huán)境,最佳方法取決于應(yīng)用程序的具體情況。希望您能發(fā)現(xiàn)本文中描述的兩個示例易于理解和實現(xiàn)。
2022-04-01 16:39:153370 
這篇文章描述了兩種不同的加速矩陣乘法的方法。第一種方法使用 Numba 編譯器來減少 Python 代碼中與循環(huán)相關(guān)的開銷。第二種方法使用 CUDA 并行化矩陣乘法。速度比較證明了 CUDA 在加速矩陣乘法方面的有效性。
2022-04-24 17:04:514949 
的梯度上,所有這些都在一個操作中完成,可以避免多次訪問global memory提升算子的帶寬。下面解析一下這個優(yōu)化的調(diào)度邏輯和cuda實現(xiàn)。 https://github.com/BBuf
2023-08-24 11:15:25643 OpenCV4支持通過GPU實現(xiàn)CUDA加速執(zhí)行,實現(xiàn)對OpenCV圖像處理程序的加速運行,當前支持加速的模塊包括如下。
2023-12-05 09:56:35364 
是否有關(guān)于GRID vGPU的CUDA / OpenCL支持的更新信息?以上來自于谷歌翻譯以下為原文Is there any updated information about CUDA/OpenCL support for GRID vGPU ?
2018-09-07 16:42:47
CUDA教程之1:Linux系統(tǒng)下CUDA安裝教程
2020-06-02 16:53:31
Nvidia CUDA 2.0編程教程
2019-03-05 07:30:00
/m60-can-it-be-used-for-deep-learning-/我遇到了類似的問題,但它是關(guān)于M10的。我用GRID M10-8Q創(chuàng)建了一個虛擬機,我想在進行深度學(xué)習時使用cuda加速計算。但是,我在這里找不到特斯拉M10
2018-09-26 15:30:23
GPU 加速的 L0 范數(shù)圖像平滑(L0 Smooth)【CUDA】
2020-07-08 12:10:13
我們有一個使用Grid K2機器的系統(tǒng)。我試圖在一個vm的側(cè)面設(shè)置cuda。當我使用驅(qū)動程序下載頁面時,它指向NVIDIA-Linux-x86_64-367.57版本的驅(qū)動程序似乎工作(它們安裝
2018-10-10 17:02:15
調(diào)節(jié)輸出電能的形式,從而驅(qū)動電機,進而驅(qū)動車輛。這就是IGBT作為核心部件的工作原理。IGBT 功率模塊是逆變器的核心功率器件。逆變器用于驅(qū)動電機,為汽車運行提供動力。當電驅(qū)動系統(tǒng)工作時,逆變器從電池組
2022-05-10 09:54:36
1.安裝toolkit(1)cd /home/CUDA_train/software/cuda4.1(2)./cudatoolkit_4.1.28_linux_64_rhel6.x.run
2019-07-24 06:11:31
NVIDIA CUDA參考文件
2019-03-05 08:00:00
``運算卡 價格表 更新日期2014.9型號參數(shù) 價格質(zhì)保備注備貨情況Nvidia Tesla C2050CUDA核心頻率:1.15 GHz CUDA核心數(shù)量:448雙精度浮點性能(峰值):515
2014-09-09 11:38:06
你好我有一個裸機Windows 2002 RC 2 x64bit服務(wù)器,帶有物理NVIDIA Grid SERIES K2卡(不是vGPU vGRID)。這張卡與CUDA兼容嗎?我使用的軟件沒有將其
2018-09-10 17:18:51
``運算卡 價格表 更新日期2014.9型號參數(shù) 價格質(zhì)保備注備貨情況Nvidia Tesla C2050CUDA核心頻率:1.15 GHz CUDA核心數(shù)量:448雙精度浮點性能(峰值):515
2014-10-10 14:56:27
```Nvidia Tesla C2050 CUDA核心頻率:1.15 GHz CUDA核心數(shù)量:448雙精度浮點性能(峰值):515 Gflops單精度浮點性能(峰值):1.03 Tflops專用
2014-08-21 11:18:27
``提供個人超級計算機解決方案 高性能GPU運算服務(wù)器解決方案/集群解決方案 Nvidia Tesla C2050 CUDA核心頻率:1.15 GHz CUDA核心數(shù)量:448 雙精度浮點性能
2014-08-03 18:09:13
``運算卡 價格表 更新日期2014.9型號參數(shù) 價格質(zhì)保備注備貨情況Nvidia Tesla C2050CUDA核心頻率:1.15 GHz CUDA核心數(shù)量:448雙精度浮點性能(峰值):515
2014-09-09 11:31:44
``提供個人超級計算機解決方案 高性能GPU運算服務(wù)器解決方案/集群解決方案 Nvidia Tesla C2050 CUDA核心頻率:1.15 GHz CUDA核心數(shù)量:448 雙精度浮點性能
2014-08-26 16:36:28
`運算卡 價格表 更新日期2014.9型號參數(shù) 價格質(zhì)保備注備貨情況Nvidia Tesla C2050CUDA核心頻率:1.15 GHz CUDA核心數(shù)量:448雙精度浮點性能(峰值):515
2014-09-15 16:15:00
`運算卡 價格表 更新日期2014.9型號參數(shù) 價格質(zhì)保備注備貨情況Nvidia Tesla C2050CUDA核心頻率:1.15 GHz CUDA核心數(shù)量:448雙精度浮點性能(峰值):515
2014-09-11 12:48:26
``Nvidia Tesla C2050 "CUDA核心頻率:1.15 GHz CUDA核心數(shù)量:448 雙精度浮點性能(峰值):515 Gflops 單精度浮點性能(峰值
2014-09-02 21:17:41
Py之TFCudaCudnn:Win10下安裝深度學(xué)習框架Tensorflow+Cuda+Cudnn最簡單最快捷最詳細攻略
2018-12-20 10:35:16
STM32F103C8T6核心板 ARM 32位 Cortex-M3 CPU 22.62X53.34MM
2023-06-13 18:18:05
原裝正品ARM 核心板 STM32F103C8T6開發(fā)板 最小系統(tǒng)板 STM32
2023-06-13 16:25:30
ZYNQ核心板 DEVB_45X60MM 5V
2023-03-28 13:06:25
安裝即可,之后就能用nvidia-smi命令了
5、安裝CUDA庫
進入 https://developer.nvidia.com/cuda-downloads,依次選擇 CUDA 類型然后
2019-07-09 07:45:08
什么是CUDA?
2021-09-28 07:37:20
在大家開始深度學(xué)習時,幾乎所有的入門教程都會提到CUDA這個詞。那么什么是CUDA?她和我們進行深度學(xué)習的環(huán)境部署等有什么關(guān)系?通過查閱資料,我整理了這份簡潔版CUDA入門文檔,希望能幫助大家用最快
2021-07-26 06:28:15
工作。對于Premiere Pro的使用,我們需要CUDA強制渲染GPU而不是使用CPU來渲染視頻。是否支持使用NVIDIA GRID K2卡?以上來自于谷歌翻譯以下為原文We have
2018-09-10 17:18:49
北極星STM32核心板 DEVB_52X42MM 5V
2023-03-28 13:06:24
單片機應(yīng)用的核心技術(shù)是什么?單片機神奇的工作原理是什么?匯編語言很難學(xué)怎么辦?
2021-11-02 06:17:40
如果沒有其他用戶共享K520,您是否可以抓取兩個GPU進行CUDA計算作業(yè)?我們的應(yīng)用程序使用GPU進行顯示和計算。當我們在AWS K520實例上運行時,CUDA只能看到K520上的一個GPU。我們
2018-09-26 15:23:49
[cuda] Linux系統(tǒng)多版本cuda環(huán)境下的cuda-90安裝
2019-06-19 17:04:45
企業(yè)培訓(xùn)公司面向單位員工培訓(xùn),長期招CUDA兼職老師,一般三天左右的短周期培訓(xùn),周末為主,有2人左右的小輔導(dǎo),也有30人左右的培訓(xùn)大班,待遇優(yōu),北京,上海,成都,廣州,深圳等,如您想掙點外塊,積累
2017-09-22 10:31:38
和Horizo??n 7.1。我能夠在C ++中編譯示例CUDA代碼(Windows 10. Visual Studio 2015),但在運行時,我得到了一個
2018-09-11 16:33:56
解決Ubuntu下的includedarkneth1414 fatal error cuda_runtimeh No such file or directory#incl
2018-12-24 11:46:26
請推薦一個能開發(fā)OPenCL 或CuDA以學(xué)習GPGPU的嵌入式板子,真的很急!謝謝
2015-09-04 21:29:44
全面介紹使用CUDA進行通用計算所需
要的語法、硬件架構(gòu)、程序優(yōu)化技巧等知識,是進行GPU通用計算程序開發(fā)的入門教材和參考書。
本書共分5章。第1章
2010-08-16 16:21:32 0
0 •GPGPU及CUDA介紹
•CUDA編程模型
•多線程及存儲器硬件
2010-11-12 16:12:100 The CUDA Toolkit targets a class of applications whose control part runs as a process on a general
2010-11-12 16:20:010 Portland Group宣布PGI CUDA C和C++編譯器已正式出貨,針對基于產(chǎn)業(yè)標準的通用64位和32位x86架構(gòu)的處理器系統(tǒng)。
2011-06-30 08:54:09968 本文來自于Toradex長期合作伙伴Antmicro公司,在本文中他們會著重介紹基于核心SoC來自NVIDIA 強大的Tegra K1的Toradex Apalis TK1 計算機模塊,來實現(xiàn)CUDA和視覺處理相關(guān)應(yīng)用。
2017-09-18 16:51:434 根據(jù)2ICMA相關(guān)器的算法特點,在對比基于CPU并行的MPI集群、MPI+CUDA異構(gòu)并行集群和Hadoop+ CUDA異構(gòu)并行集群的架構(gòu)特點的基礎(chǔ)上,提出了一種基于Hadoop+ CUDA平臺實現(xiàn)
2017-12-06 10:12:260 Nvidia今天公布了CUDA并行計算開發(fā)平臺的更新規(guī)劃說明,其中特別提到,CUDA 10.2(包括工具包和驅(qū)動)將是最后一個支持蘋果macOS系統(tǒng)開發(fā)、運行CUDA程序的版本,未來CUDA將與蘋果平臺無關(guān)。
2019-11-26 15:48:563050 NVIDIA在CUDA 6中引入了統(tǒng)一內(nèi)存模型 ( Unified Memory ),這是CUDA歷史上最重要的編程模型改進之一。在當今典型的PC或群集節(jié)點中,CPU和GPU的內(nèi)存在物理上是獨立
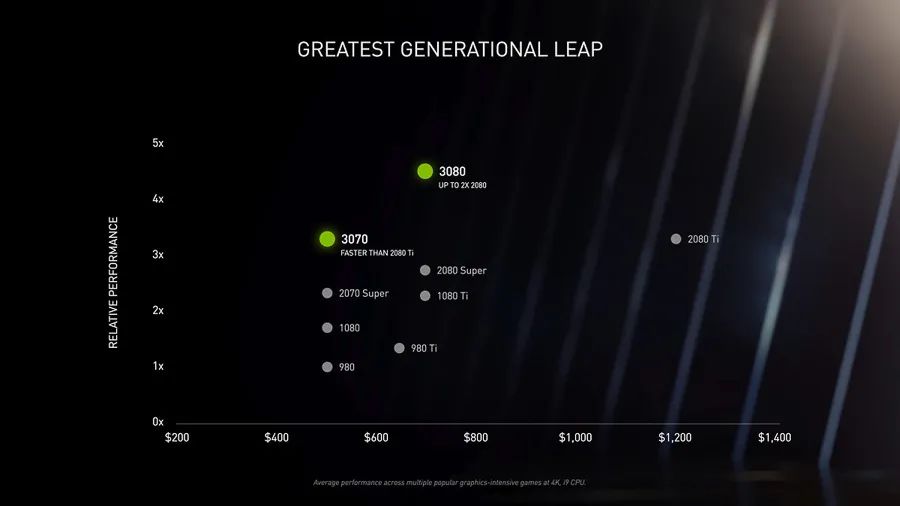
2020-07-02 14:08:232384 搭載了 9984 個 CUDA 內(nèi)核,比 RTX 3080 多 1280 個,顯存配置也將從 RTX 3080 的 320bit 升級至 384 bit,這也意味其顯存容量可能為 12 GB。在此之前
2020-10-27 17:08:412393 與 RTX 3090 相同的 CUDA 核心數(shù),即 10496 個核心,配備了 20GB GDDR6X 顯存,功耗與 RTX 3080 相同,不支持 NVLINK。 IT之家了解到,AMD 現(xiàn)已發(fā)布
2020-11-04 16:06:192707 將配備 GA102-250-KD-A1 GPU,擁有 10496 個 CUDA 核心,具有 320 bit 位寬的 20GB GDDR6X 顯存。 RTX 3080 Ti 的 TGP 估計為 320W
2020-11-11 16:23:151379 最近,RTX3060 Ti顯卡開始登場,這款被叫作甜品的產(chǎn)品,具有4864個CUDA 核心,比RTX 3070少1024個核心,后者是5888個。其顯存為8GB GDDR6 256 bit 14 Gbps,單卡價格在3000元左右,綜合性價比極高。
2020-12-04 15:33:345220 1、CUDA的簡介 2、GPU架構(gòu)和CUDA介紹3、CUDA架構(gòu)4、開發(fā)環(huán)境說明和配置5、開始第一個Hello CUDA程序????5.1、VS2017創(chuàng)建NVIDIA CUDA項目...
2020-12-14 23:40:27659 蔚來 ET7 搭載四顆英偉達 Orin 芯片:8096CUDA 核心,cuda,芯片,英偉達,nvidia,蔚來,顯卡
2021-02-20 14:33:374664 NVIDIA CUDA鼎鼎大名,不過,從一開始,該技術(shù)就為N卡獨享。
2021-03-01 09:43:345044 盡管已經(jīng)有一些工具能讓CUDA為OpenCL環(huán)境所用,但即便先進如HIPCL也還是一款半自動化工具,需要開發(fā)者手動干預(yù)。
2021-03-01 10:36:366407 最近因為工作需要,學(xué)習了一波CUDA。這里簡單記錄一下PyTorch自定義CUDA算子的方法,寫了一個非常簡單的example,再介紹一下正確的PyTorch中CUDA運行時間分析方法。
2021-03-30 15:58:583772 
我希望這篇文章向您展示了 CMake 如何自然地支持構(gòu)建 CUDA 應(yīng)用程序。如果您是 CMake 的現(xiàn)有用戶,請試用 CMake 3 . 9 并利用改進的 CUDA 支持。如果您不是 CMake 的現(xiàn)有用戶,請試用 CMake 3 . 9 ,親身體驗一下它對于構(gòu)建使用 CUDA 的跨平臺項目有多好。
2022-04-01 17:42:273806 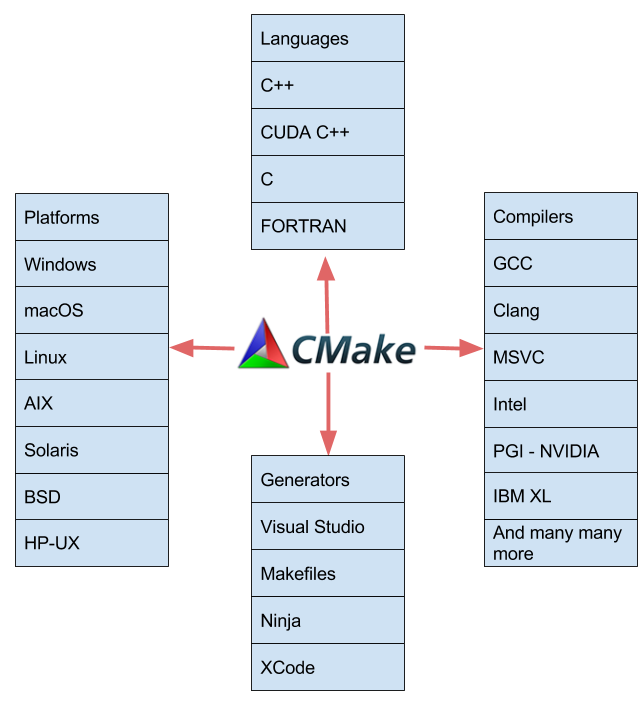
通常,實時物理模擬代碼是用低級 CUDA C ++編寫的,以獲得最佳性能。在這篇文章中,我們將介紹 NVIDIA Warp ,這是一個新的 Python 框架,可以輕松地用 Python 編寫
2022-04-02 16:15:292260 NVIDIA 發(fā)布的 CUDA 開發(fā)環(huán)境 CUDA 11.6 的最新版本。本版本的重點是增強 CUDA 應(yīng)用程序的編程模型和性能。 CUDA 繼續(xù)推動 GPU 加速度的邊界,并為 HPC 、可視化、 AI 、 ML 和 DL 和數(shù)據(jù)科學(xué)中的新應(yīng)用奠定基礎(chǔ)。
2022-04-02 16:43:343996 NVIDIA 宣布 CUDA 開發(fā)環(huán)境的最新版本 CUDA 11 . 5 。 CUDA 11 . 5 專注于增強您的 CUDA 應(yīng)用程序的編程模型和性能。 CUDA 繼續(xù)推動 GPU 加速的邊界,并為 HPC 、可視化、 AI 、 ML 和 DL 中的新應(yīng)用打下基礎(chǔ),和數(shù)據(jù)科學(xué)。
2022-04-02 16:48:472603 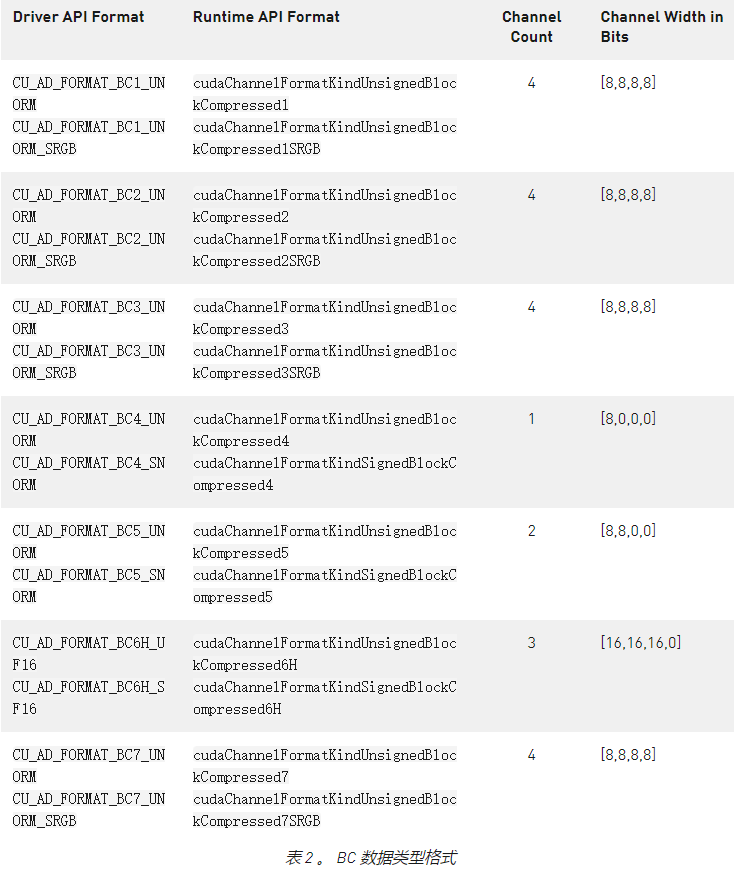
CUDA 11 . 5 C ++編譯器解決了不斷增長的客戶請求。具體來說,如何減少 CUDA 應(yīng)用程序構(gòu)建時間。除了消除未使用的內(nèi)核外, NVRTC 和 PTX 并發(fā)編譯有助于解決這個關(guān)鍵問題 CUDA C ++應(yīng)用程序開發(fā)的關(guān)注點。
2022-04-06 11:59:231889 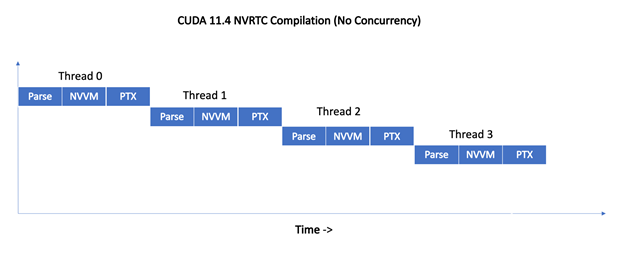
在 NVIDIA CUDA 11.5 中, NVCC 離線編譯器在主機編譯器支持的平臺上為有符號和無符號__int128數(shù)據(jù)類型添加了預(yù)覽支持。
2022-04-11 09:16:191214 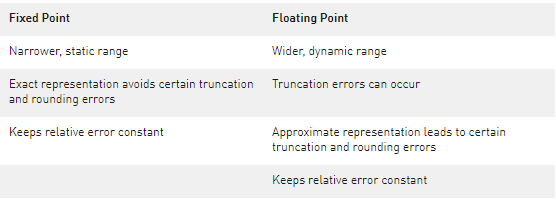
在不指定流的情況下執(zhí)行異步 CUDA 命令時,運行時使用默認流。在 CUDA 7 之前,默認流是一個特殊流,它隱式地與設(shè)備上的所有其他流同步。
2022-04-11 09:26:25767 
這篇文章是對 CUDA 的一個超級簡單的介紹,這是一個流行的并行計算平臺和 NVIDIA 的編程模型。我在 2013 年給 CUDA 寫了一篇前一篇 “簡單介紹” ,這幾年來非常流行。但是 CUDA 編程變得越來越簡單, GPUs 也變得更快了,所以是時候更新(甚至更容易)介紹了。
2022-04-11 09:46:261098 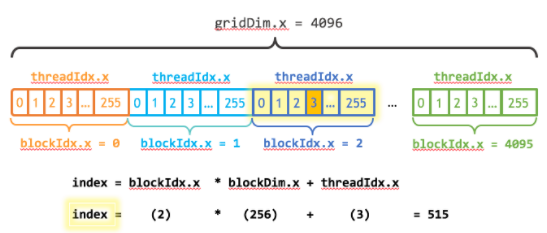
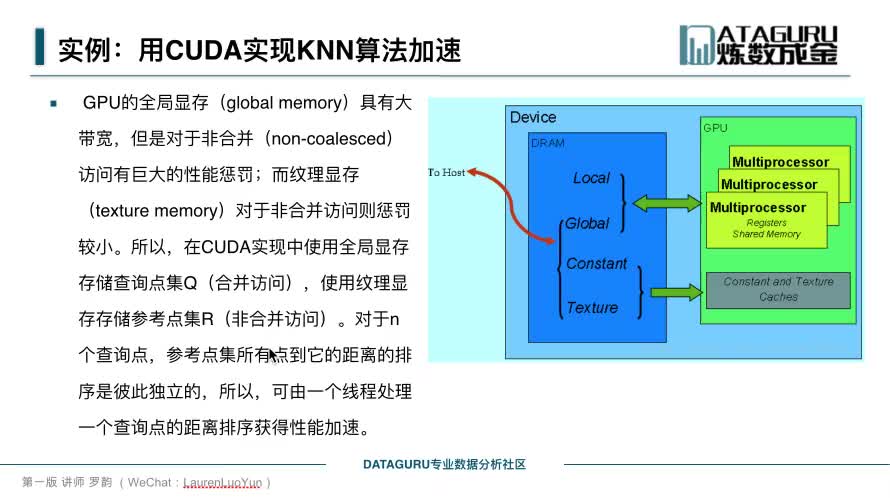
共享內(nèi)存是編寫優(yōu)化良好的 CUDA 代碼的一個強大功能。共享內(nèi)存的訪問比全局內(nèi)存訪問快得多,因為它位于芯片上。
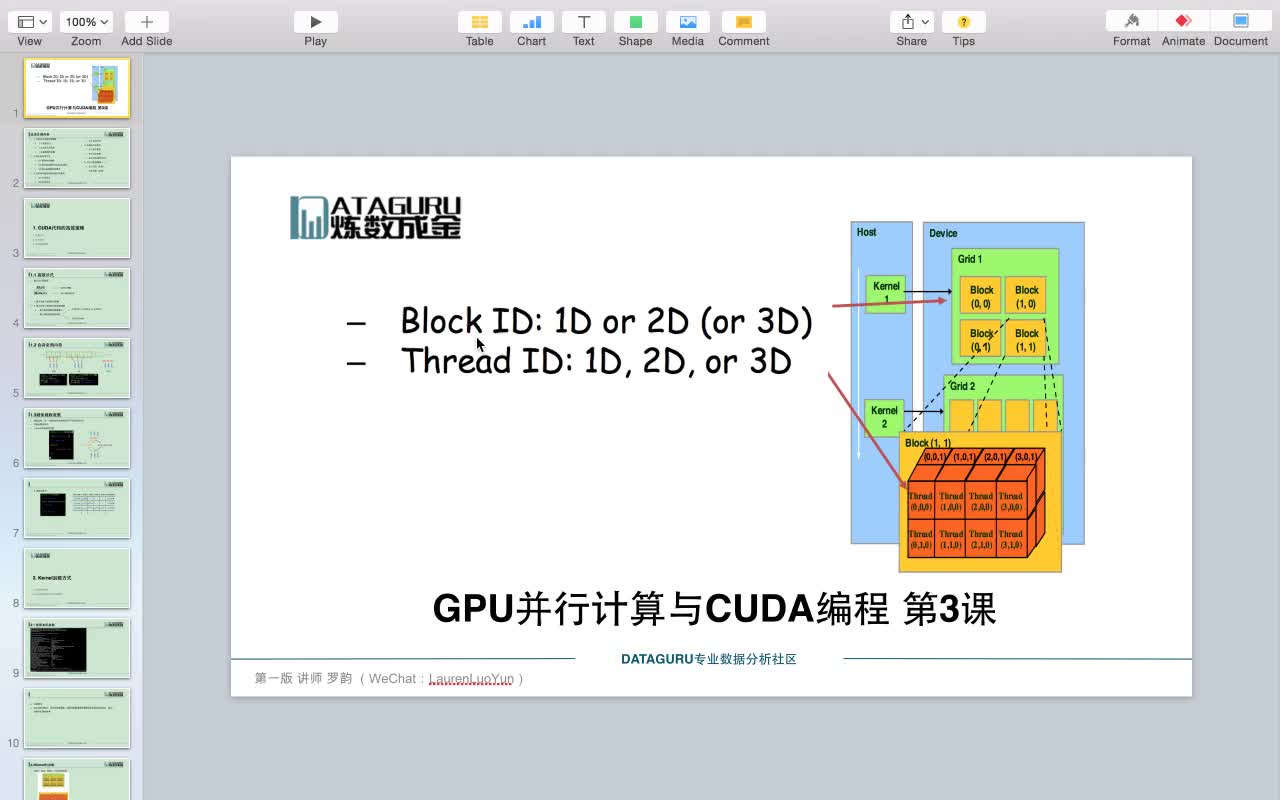
2022-04-11 10:03:456774 CUDA 編程模型是一個異構(gòu)模型,其中使用了 CPU 和 GPU 。在 CUDA 中, host 指的是 CPU 及其存儲器, device 是指 GPU 及其存儲器。在主機上運行的代碼可以管理主機和設(shè)備上的內(nèi)存,還可以啟動在設(shè)備上執(zhí)行的函數(shù) kernels 。這些內(nèi)核由許多 GPU 線程并行執(zhí)行。
2022-04-11 10:13:121192 在 CUDA 編程模型中,線程是進行計算或內(nèi)存操作的最低抽象級別。 從基于 NVIDIA Ampere GPU 架構(gòu)的設(shè)備開始,CUDA 編程模型通過異步編程模型為內(nèi)存操作提供加速。 異步編程模型定義了與 CUDA 線程相關(guān)的異步操作的行為。
2022-04-20 17:16:032410 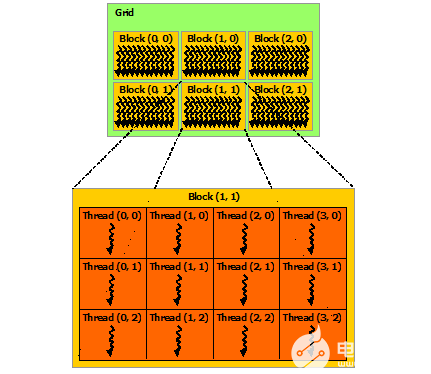
本文檔描述了支持動態(tài)并行的 CUDA 的擴展功能,包括為利用這些功能而對 CUDA 編程模型進行必要的修改和添加,以及利用此附加功能的指南和最佳實踐。
2022-04-28 09:31:12941 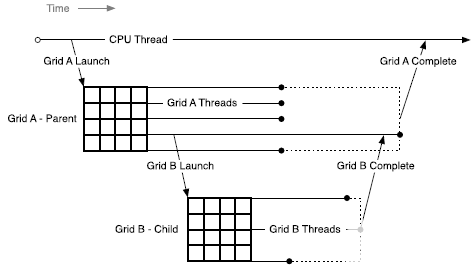
NVIDIA GPUs 以 SIMT (單指令,多線程)方式執(zhí)行稱為 warps 的線程組。許多 CUDA 程序通過利用 warp 執(zhí)行來獲得高性能。在這個博客中,我們將展示如何使用 CUDA 9 中引入的原語,使您的 warp 級編程安全有效。
2022-04-28 16:09:052323 
在 CUDA 上下文中,內(nèi)核作為 PTX 或二進制對象由主機代碼顯式加載,如模塊中所述。 因此,用 C++ 編寫的內(nèi)核必須單獨編譯成 PTX 或二進制對象。 內(nèi)核使用 API 入口點啟動,如內(nèi)核執(zhí)行中所述。
2022-05-07 15:07:081297 
NVIDIA CUDA 工具包提供了開發(fā)環(huán)境,可供開發(fā)、優(yōu)化和部署經(jīng) GPU 加速的高性能應(yīng)用。
2022-06-10 12:03:422964 OpenCV4.x中關(guān)于CUDA加速的內(nèi)容主要有兩個部分,第一部分是之前OpenCV支持的圖像處理與對象檢測傳統(tǒng)算法的CUDA加速;第二部分是OpenCV4.2版本之后開始支持的針對深度學(xué)習卷積神經(jīng)網(wǎng)絡(luò)模型的CUDA加速。
2022-09-05 10:03:004415 單精度矩陣乘法(SGEMM)幾乎是每一位學(xué)習 CUDA 的同學(xué)繞不開的案例,這個經(jīng)典的計算密集型案例可以很好地展示 GPU 編程中常用的優(yōu)化技巧。本文將詳細介紹 CUDA SGEMM 的優(yōu)化手段
2022-09-28 09:46:541511 通過這種構(gòu)建CUDA圖的方法,由CUDA內(nèi)核和CUDA內(nèi)存操作形成的圖節(jié)點通過調(diào)用cudaGraphAdd*節(jié)點API添加到圖中,其中*被替換為節(jié)點類型。節(jié)點之間的依賴關(guān)系是用API顯式設(shè)置的。
2022-10-11 09:43:40553 
CUDA(Compute Unified Device Architecture,統(tǒng)一計算架構(gòu))是由英偉達所推出的一種集成技術(shù),是該公司對于GPGPU的正式名稱。通過這個技術(shù),用戶可利用NVIDIA的GPU進行圖像處理之外的運算,CUDA也是首次可以利用GPU作為C-編譯器的開發(fā)環(huán)境。
2022-11-29 09:36:552464 CV-CUDA (Computer Vision – Compute Unified Device Architecture)高性能圖像處理加速庫,近日發(fā)布 Alpha 版本,正式向全球開發(fā)者開源
2022-12-21 20:45:02732 CUDA是NVIDIA的一種用于GPU編程的技術(shù),CUDA核心是GPU上的一組小型計算單元,它們可以同時執(zhí)行大量的計算任務(wù)。
2023-01-08 09:20:141874 CUDA 除了是并行計算架構(gòu)外,還是 CPU 和 GPU 協(xié)調(diào)工作的通用語言。在CUDA 編程模型中,主要有 Host(主機)和 Device(設(shè)備)兩個概念,Host 包含 CPU 和主機內(nèi)存,Device 包含 GPU 和顯存
2023-05-18 09:57:541576 
CUDA 編程模型主要有三個關(guān)鍵抽象:層級的線程組,共享內(nèi)存和柵同步(barrier synchronization)。
2023-05-19 11:32:541017 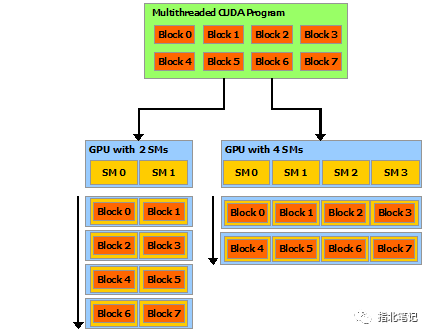
的 CUDA (Compute Unified Device Architecture)編程模型 ,利用 GPU 強大的并行計算能力,為計算機視覺任務(wù)帶來了前所未有的加速效果。 為了能讓 CV
2023-06-13 20:55:03259 
電子發(fā)燒友網(wǎng)站提供《CUDA與Jetson Nano:并行Pollard Rho測試.zip》資料免費下載
2023-06-15 09:30:080 CUDA之所以會成為算力芯片硬件廠商必須要認真考慮的一個選擇,最直接的原因,是其已經(jīng)實現(xiàn)了與算法客戶的強綁定。眾多算法工程師已經(jīng)習慣了CUDA提供的工具庫及其編程語言,向外遷移總是會存在不習慣的問題。
2023-08-16 12:35:45480 
基于 NVIDIA CUDA 架構(gòu)師 Stephen Jones 近期的 CUDA 技術(shù)簡報(Accelerated Computing / CUDA Technical Briefing),開發(fā)者
2023-09-22 18:45:02300 
OpenCV4.8+CUDA+擴展模塊支持編譯指南
2023-11-30 16:45:00314 
在最近的一場“AI Everywhere”發(fā)布會上,Intel的CEO Pat Gelsinger炮轟Nvidia的CUDA生態(tài)護城河并不深,而且已經(jīng)成為行業(yè)的眾矢之的。
2023-12-28 10:26:20458 
vLLM 中,LLM 推理的 prefill 階段 attention 計算使用第三方庫 xformers 的優(yōu)化實現(xiàn),decoding 階段 attention 計算則使用項目編譯 CUDA 代碼實現(xiàn)。
2024-01-09 11:43:21414 
 電子發(fā)燒友App
電子發(fā)燒友App












 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論