 電子發燒友App
電子發燒友App


編者按
大家一直有個誤解,覺得通用和專用,是對等的兩個選擇。例如,牧本波動(Makimoto's Wave),是一個與摩爾定律類似的電子行業發展規律,它認為集成電路有規律的在“通用”和“專用”之間變化,循環周期大約為10年。
我們的觀點則是:相比專用,通用是更高級的能力。集成電路等各種事物發展規律的常態是通用,“通用到專用”只是達到通用狀態后的一些新的探索,是臨時狀態,最終還是要回歸到通用。專用是事物表面的、臨時的、局部的特征,而通用則是事物本質的、長期的、全面的特征。
對大芯片來說,通用是成功的必由之路。CPU是通用芯片,成就了Intel的成功;GPU是通用芯片,成就了NVIDIA的成功。目前,還沒有看到做專用芯片非常成功的案例。長期地看,專用是臨時的,專用的芯片也是臨時的,最終的結果只能是走向消亡。
今天這篇文章,我們聊聊通用和通用計算的話題。
1 相比專用,通用是更高級別的能力
1.1 牧本波動
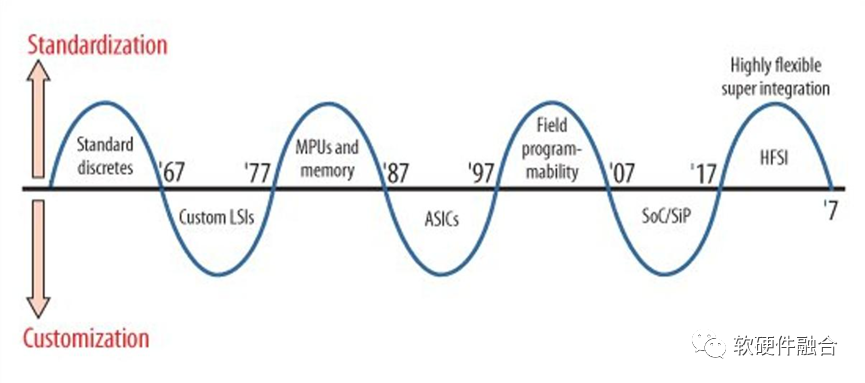
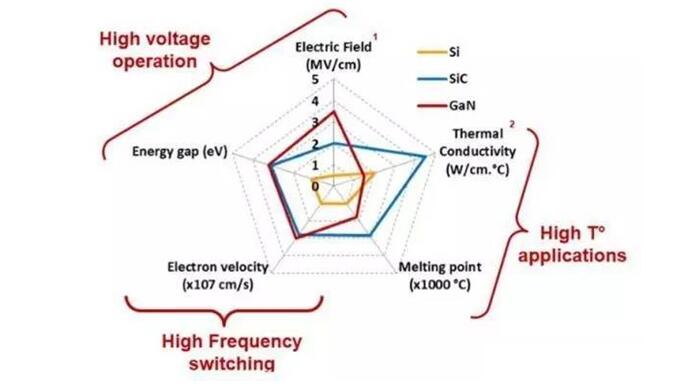
1987年,原日立公司總工程師牧本次生(Tsugio Makimoto)提出,集成電路發展過程中,芯片產品總是在“標準化”與“定制化”之間交替擺動,大概每十年波動一次。牧本波動(Makimoto's Wave,也稱為牧本定律)背后是性能、功耗和開發效率之間的一個平衡。
也因為同樣的理解,芯片行業的很多人認為,“通用”和“專用”是對等的,是一個天平的兩邊。設計研發的產品,偏向通用或偏向專用,是基于客戶場景需求,對產品實現的權衡。
1.2 專用是臨時的,通用是永恒的
如果我們深入的分析牧本波動的規律,會發現:通用時代的產品都逐漸沉淀下來了,并且仍在發展壯大;而專用時代的產品,要么消失在歷史長河里了,要么是也在變得越來越通用。
以GPU為例,最開始的GPU(Graphics Processing Unit)其實是專用的圖形加速芯片。在上世紀90年代,有太多的公司做專用的GPU加速芯片或者其他各種專用類型的加速芯片。后來NVIDIA發現GPU中有非常多的并行計算部分,于是把GPU改造成由很多高效能的小CPU核(CUDA核)組成的通用GPU(GPGPU),最終才獲得了成功。而其他仍然堅持做專用加速芯片的公司,都已經銷聲匿跡。
所以呢,牧本波動只是一個現象規律,而不是本質規律。透過現象看本質,我們會發現,集成電路等各種事物發展的常態是通用,“通用到專用”只是達到通用狀態后,持續向前發展的一些新的探索,是臨時狀態,最終還是要回歸到新的通用階段、新的通用狀態。專用是事物表面的、臨時的、局部的特征,而通用則是事物本質的、長期的、全面的特征。
一言以蔽之:相比專用,通用是更高級的能力。? ?
1.3 通用案例:智能手機
幾乎我們每個人都擁有智能手機,但可能年輕一些的朋友沒有見過這么多“古老”的電子設備。它們每個設備都有自己特定的功能,導航儀用于導航,電子詞典用于查詞和學習,MP3用于播放音樂等等。后來,隨著智能手機的出現,這些專用的電子設備就都消失在了歷史長河中。
智能手機,是通用的個人移動智能終端,在通用的硬件之上,通過各種不同的軟件應用,實現各種各樣豐富多彩的功能。
1.4 通用案例:AGI大模型
AGI通用人工智能,指的是具備與人類同等甚至超越人類的智能,能表現出正常人類所具有的所有智能行為。? ?
傳統的基于中小模型的人工智能,是專用AI,聚焦某個相對具體的業務方面。比如專門用于人臉識別的AI,專門用于檢測某種特定行為的AI等等。“場景千千萬,模型千千萬”。傳統AI是完全碎片化的一個局面,場景之間的數據和模型等信息無法傳遞,無法整合。傳統AI是弱人工智能。
目前火爆的GPT,則是模型參數發展量變到質變的過程,也是從專用的臨時態往通用的常態發展的過程。目前,GPT4具備了一定的AGI能力,隨著GPT的成功,AGI已經成為全球競爭的焦點。GPT所在的OpenAI公司CEO奧特曼表示,AGI將于2030年之前到來。
隨著GPT等具有通用能力的AI模型出現,之前的諸多專用AI模型已經在快速地萎縮,未來也必然走向消亡。
2 通用,是大芯片成功的必由之路
2.1 越來越復雜的系統需要通用
隨著業務場景越來越復雜,場景的變化也就越來越快。即使同一領域同一場景,不同客戶的業務之間仍然存在巨大差異,甚至在大客戶內部,不同團隊的業務之間也存在差異。此外,業務仍在快速地迭代。
作為芯片,無法做到為每一個場景定制開發專用芯片,一方面是專用芯片覆蓋場景太少,此外專用芯片的生命周期較短。通用芯片,是唯一解決之道。
并且,越來越復雜的場景及場景的差異化,對芯片的通用性設計也提出了更高的要求。芯片的通用性設計,難度越來越高,需要更多的創新思路和更多的投入。? ?
2.2 大芯片的高門檻需要通用
大芯片系統越來越龐大,設計規模越來越大,研發成本越來越成天文數字,門檻越來越高。芯片只有更大規模地落地,才能有效攤薄研發成本。
更大的落地規模,意味著需要更多的場景和領域覆蓋,意味著更高的通用性能力。
2.3 云邊端融合需要通用
云邊端融合,需要架構生態的整合,而不是碎片化:
最開始,當我們的設備是孤島的時候,設備間相互約束較少,設備可以是任意架構,任意開發和運行環境,相互之間影響較小。
隨著互聯網和物聯網的發展,萬物互聯,設備和設備之間開始有了通信。這個時候,我們需要雙方按照既定的規范進行通信。
更進一步,更多的設備連接到一塊了,我們的計算可以跳脫單機的約束,分布式計算逐漸流行。分布式計算,需要考慮不同設備工作之間的工作劃分和協同。因為工作的劃分和協同,于是有了云邊端。
隨著發展,僅考慮協同也會有問題。哪些工作應該在終端做,哪些工作應該在云端做,哪些工作應該在邊緣做,都是提前規劃好的,此刻的協同是靜態的。但隨著協同的工作越來越多、越來越復雜,我們發現實際上很難在早期就做好準確而仔細的任務劃分,這樣就需要在運行階段動態地調整云邊端的工作劃分和協同。于是,融合產生了。在融合階段,云邊端的架構和環境是一致的,某種程度上,從協同階段的數以萬計的設備單系統,升級成了融合階段的數以萬計設備組成的宏觀的單個超級大系統。這個階段,軟件可以動態地、自由地在不同的平臺上調度和運行。??
要想實現云邊端融合,具有高可擴展性的,架構和生態一致的通用計算芯片,是必選項。
3 既通用又高性能的計算存在嗎?
很多朋友會提出疑問,性能和通用靈活性是矛盾,魚和熊掌不可兼得。我們的答案是:有辦法做到魚和熊掌兼得。
接下來是我們對這個問題的解答。
3.1 系統存在“二八定律”
二八定律是一個非常有意思的存在:
RISC和CISC之爭,是因為二八定律。人們發現,80%時間里,運行的常見指令只占指令數量的20%,而另外80%的指令較少使用。
存儲分層,Cache的存在,也是因為二八定律。程序局部性原理,用二八定律來解釋,就是在某個時間段內,80%的大部分時間里,只是在訪問20%的區域。
云計算,也是二八定律的一個典型的案例。我們從自建數據中心,到云計算IaaS、PaaS和SaaS,其實就是整個計算系統逐漸由供應商接管的過程。系統是符合二八定律的:就是系統中存在80%相對確定且共性的工作,而20%的工作是相對多變且個性的工作。這80%的工作供應商可以接管,而另外20%的工作則由用戶自己把握較好。
并且,二八定律還存在嵌套的情況。基于此,我們可以對系統做如下三個層次的劃分:
從系統中,分離出來80%共性的工作,這部分劃分到系統的基礎設施層。
系統中另外20%的個性的工作,可以再細分,也就是16%(20%*80%)的工作相對共性,而另外4%(20%*20%)的工作是極度個性的:
?16%相對共性的工作,歸屬于系統的彈性加速層。
4%極度個性的工作,歸屬于系統的應用層。
?3.2 團隊分工協同,既通用又高效
DSA是專家,做專業的事情非常高效,但劣勢在于過于專用;CPU是通才,啥都能干,但干啥都不夠高效;而GPU的能力介于兩者之間。
作為單兵,DSA、GPU、GPU都是有長有短。但作為團隊,發揮各自的優勢,可以形成各自能力的高效整合:
80%共性的基礎設施層,因為工作任務相對確定,因此可以采用相對確定且高效的DSA處理器。
16%相對共性的彈性加速層,因為工作任務具有一定的靈活彈性,但也不是無章可循,因此采用相對彈性的GPU處理器比較合適。
4%極度個性的應用層。則采用最通用靈活的CPU處理器。
或者我們換個思路分析。系統中的各項工作,讓各類DSA先挑,DSA挑剩下的工作GPU再挑,DSA和GPU都挑剩下的工作,最后由CPU來兜底完成。這樣就可以達到通用:通過CPU+GPU+DSAs的異構融合系統可以處理所有系統的工作。? ??
可能,會有朋友挑戰,DSA會有很多,萬一不存在一個合適的DSA去處理特定的某個性能敏感的任務,這豈不是只能GPU或CPU來做,這是不是就不是極致的性能效率了?
如果從單機計算來看,這個問題是存在的。但從宏觀的云邊端融合計算來看,這個問題根本就不是問題。可以通過宏觀調度的方式,找到最合適某個或某些DSAs最高效的計算平臺,實現這個小系統的最極致性能的并且通用的運行環境。? ?
4 第三代通用計算
4.1 基于異構協同視角的計算架構劃分
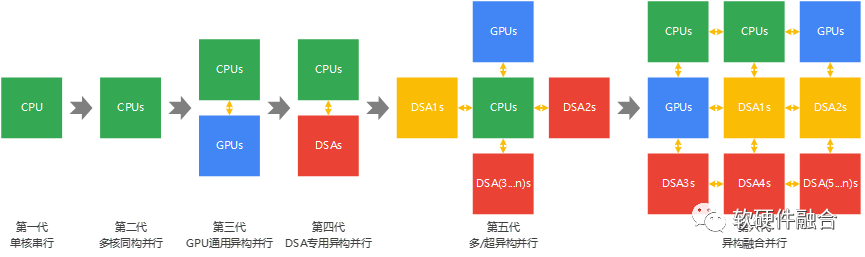
基于多種異構處理器協作的視角,計算架構可以分為六個階段:
第一代,CPU單核串行階段。
第二代,CPU同構多核并行階段。
第三代,CPU+GPU通用異構并行階段。
第四代,CPU+DSA專用異構并行階段。
第五代,CPU+GPU+DSAs的多異構或超異構階段。
第六代,CPU+GPU+DSAs的異構融合階段。
需要說明的是,新的階段開始,并不意味著上一階段的完全消亡,只是說它的場景會越來越少,逐漸走向凋零。

在2023年9月份,工信部電子五所發布的《異構融合計算技術白皮書》中,詳細介紹了 “異構融合計算”技術的發展背景、技術細節,以及未來發展展望,歡迎下載閱讀。
4.2 增加“通用”約束,形成通用計算架構
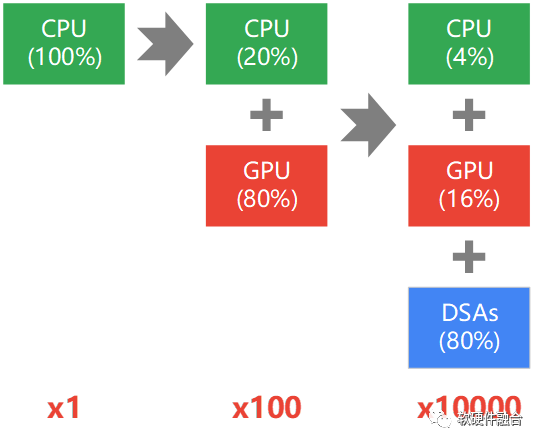

通用,是大芯片成功的必由之路。那么,我們有必要為計算架構增加“通用”的約束,這樣計算架構的六個發展階段可以縮減為三個階段:
第一代通用計算,CPU同構通用計算。依據“二八定律”,這一時期,所有(100%)的工作都是CPU來做。
第二代通用計算,CPU+GPU異構通用計算。這一時期,GPU完成絕大部分(80%)的工作,CPU完成較少部分(20%)的工作。
第三代通用計算,CPU+GPU+DSAs異構融合通用計算。這一時期,DSAs完成絕大部分(80%)的工作,GPU完成剩余較少部分中的絕大部分(16%)工作,剩下的(4%)工作,由CPU完成。
第一代通用計算,成就了Intel的成功;第二代通用計算,成就了NVIDIA的成功;第三代通用計算,才剛剛開始萌芽。“彎道超車”的重要機會,希望國內有廠家能夠脫穎而出,成就偉大的事業。
4.3 最終的形態,為什么是異構融合而不是DSA?
有些朋友可能會問,既然第二代是GPU,那么第三代為什么不是AI-DSA或者DPU這種形態的計算芯片?
在第二代通用計算時代,為了更好的通用性,獨立的加速卡方式是比較好的選擇。所以最終成功的是獨立形態的GPU,而不是CPU+GPU集成形態的APU。? ?
在第三代通用計算時代,我們沒法簡單復制第二階段的做法。因為第三階段存在如下一些問題:
問題一,專用芯片無法承載通用計算。AI芯片是一種DSA,DPU可以當作多種DSA的集合體。DSA是一種專用芯片,無法實現通用計算,也無法主導計算架構的走向。
問題二,架構和生態碎片化。獨立的DSA,面向的領域五花八門,實現的架構五花八門。如果不考慮DSA的整合,會使得計算架構和生態碎片化。
問題三,協同問題。第二代通用計算僅有兩類處理器CPU和GPU,協同相對簡單。但第三階段,處理器芯片的類型通常在5個以上,這一時期,核心問題在協同和融合。來自不同廠商的各自獨立的處理器芯片,幾乎無法高效協同。
目前階段,整合成單芯片的做法是可行的路徑。
審核編輯:黃飛
?

















 工商網監
工商網監
評論