 電子發燒友App
電子發燒友App


01 ARM:3A大作 ? ?
將 CPU 的設計與制造相分離的代工模式,給 AMD 提供了高度的靈活性。第二、三代 EPYC 處理器可以相對自由的選擇不同的制程來匹配芯片設計的具體需求,客觀上起到了幫助 AMD“以小博大”,從英特爾手中持續搶下市場份額的作用。 ? 相關閱讀: Arm架構升級,v9與v8版本有何差異? 從X86到ARM,跨越CPU架構鴻溝 ? 不過,這個靈活性的獲益者更多在于 AMD 自身。超大規模用戶如 AWS 和阿里云不滿足于主要調整核心數、運行頻率和 TDP 等指標的傳統定制,希望對 CPU 設計有更多的自主權;又或者,新興 CPU 供應商如 Ampere(安晟培)要選擇適用的技術路線……Arm 幾乎是服務器 CPU 市場上唯一的答案。 ? 如果說臺積電幫助解決 CPU 的制造問題,那么 Arm 幫助解決 CPU 的設計問題。
Cortex 孵化 Neoverse
對亞馬遜(Annapurna Labs)、阿里巴巴(平頭哥)和 Ampere 這有足夠芯片設計能力的“3A”客戶來說,Arm 的 Neoverse 平臺提供了設計一款服務器 CPU 的基礎,包括 CPU 核心的微架構和配套的制程。 ? Arm 對服務器 CPU 市場的正面進攻可以回溯到 2011 年 10 月,Arm 發布加入可選 64 位架構(AArch64)的 ARMv8-A。一年后,Arm 發布實現 ARMv8-A 64 位指令集的微架構 Cortex-A53 和 Cortex-A57,AMD 表態將推出相應的服務器產品——后者多年的服務器市場經驗正是當時的 Arm 陣營所稀缺的。 ? 此后的幾年中,芯片供應商如 Cavium、高通(Qualcomm)和國內的華芯通,超大規模用戶如微軟,都曾積極的推動 64 位 Arm 進入數據中心市場。但是,真正比較成規模化的部署,應當始自 2018 年 11 月 AWS 預覽其首個 Arm 服務器 CPU —— Graviton。
? Graviton 基于 2015 年推出的 Cortex-A72(A57 的繼任者),16nm 制程,16 核、16 線程, 與同時期的 x86 服務器 CPU 比起來,頗有些‘“平平無奇”,最大的仰仗是亞馬遜“自家的孩子”,可以充分優化。 ? Cortex-A 家族已經是 Cortex 三兄弟里最追求性能的了,但畢竟不是面向服務器平臺的產品,不能放寬功耗限制去飆性能。于是,在Graviton 公開之前一個月,Arm 發布了面向云計算和邊緣基礎設施的 Neoverse 平臺,起點便是 16nm 的 A72 和 A75,代號 Cosmos。
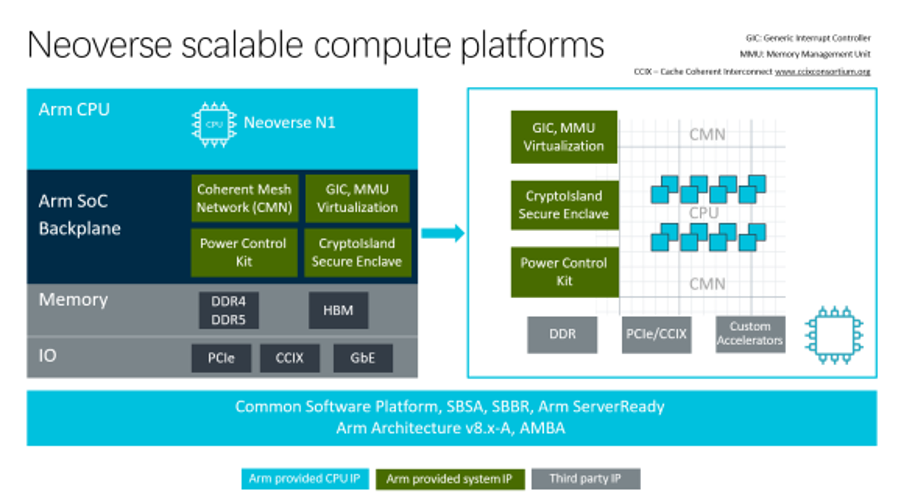
△ Neoverse可伸縮計算平臺 ? 僅僅 4 個月之后,2019 年 2 月,Arm 更新了 Neoverse 平臺的路線圖,推出 7nm 的 Neoverse N1,性能比之前的目標又有 30% 以上的提升。 ? 代號 Ares 的 Neoverse N1,基礎是 2018 年推出的 Cortex-A76,兩者的流水線結構相同,? 均為 11 級短流水線設計,前端都是 4 寬的讀 取 / 解碼器。Arm 將其稱為“手風琴”管道,因為根據指令長度不 同,它可以在延遲敏感的情況下將第二預測階段與第一獲取階段重 疊,將調度階段與第一發布階段重疊,將流水線長度減少到 9 級。L2 Cache 也新增可選的 1MiB 容量,是 A76 的 2 倍。 ?
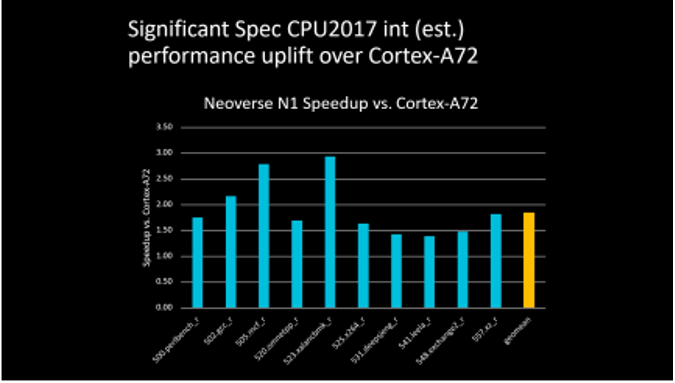
△ 4 vCPU 配置,Neoverse N1 相對 Cortex-A72的整數性能提升 ? 相較于上一代的 A72 平臺,Neoverse N1 平臺帶來了顯著的性能提升, 許多項目的成績翻倍,尤其是在標志性的機器學習項目中,成績接 近上一代產品的 5 倍。雖然 A72 的年頭早了點兒,但這樣的性能差 距也說明 Neoverse N1 確實有了質的飛躍。
Graviton2 與 Altra 系列
? Neoverse N1 平臺帶給數據中心市場的沖擊很大,因為所有人都看 到了它的巨大潛力和價值,以及這背后的機會。如果說之前的 A72 還只是在數據中心市場嶄露頭角的話,那么 Neoverse N1 則讓更多 人相信 Arm 有能力在這個領域分一杯羹。 兩款分別來自云服務商和獨立 CPU 供應商的 7nm CPU,都基于 Neoverse N1。
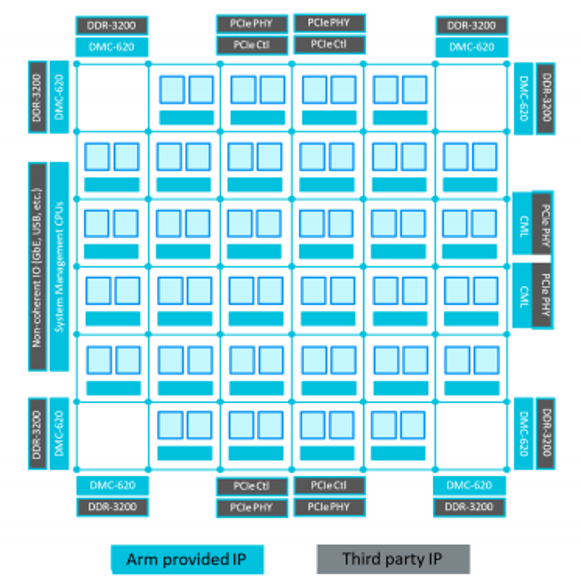
? 2019 年 11 月,AWS 官宣 Graviton2 處理器:
核數暴漲至 64,是一代的 4 倍;
晶體管數更有 6 倍,達到 300 億之多;
64MiB L2 Cache,是一代的 8 倍;
運行頻率 2.5GHz,略高于一代的 2.3GHz。
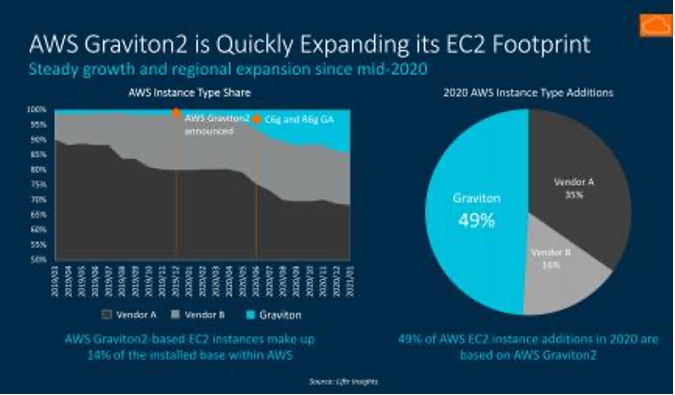
△ 2020 年 AWS 新增的 EC2 實例中,? Gravtion2 占據半壁江山,? Intel 和 AMD 的比例也耐人尋味 ? 基于 Graviton2 的 EC2(Elastic Compute Cloud,彈 性 計 算 云)實 例類型迅速增多,包括但不限于通用型(M6g、T4g)、計算優化 型(C6g)、內存優化型(R6g、X2gd),部署的區域(Region)和數量也從 2020 年中起穩定增長——據統計,2020 年全年,AWS EC2 實例增量中的 49% 基于 AWS Graviton2。 ?
Armv9:繼往開來
2011 年 11 月公布的 Armv8,將 Arm 帶入了 64 位時代。在 Arm 與生態合作伙伴的共同努力下,經過數次產品迭代,Arm 陣營用了十年的時間,在服務器市場站穩了腳跟。
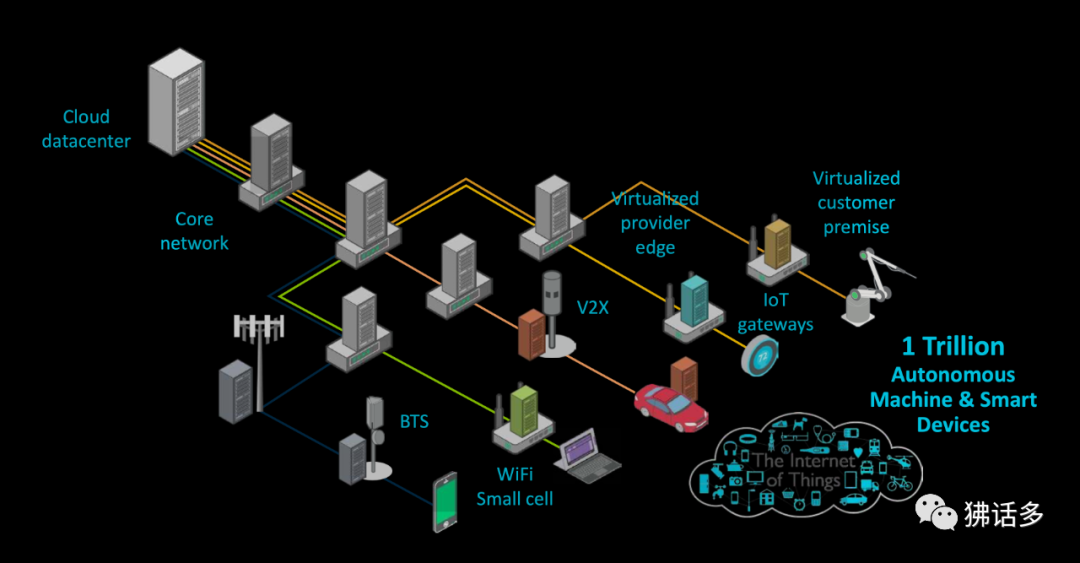
2021 年 3 月底,Armv9 發布,在 Armv8 的基礎上,著重升級了安全性、 機器學習(Machine Learing,ML)和數字信號處理(Digital Signal Processing,DSP)方面的能力。 ? 在新架構所帶來的三大特性中,機器學習或許是大眾最熟悉也是最關心的內容。伴隨著異構應用的崛起,以機器學習為代表的人工智能(Artificial Intelligence,AI)技術已經深入我們生活的方方面面,無論是在后端的數據中心還是在終端、邊緣側,機器學習都大有用武之地。 ? 為了更好地提升 AI 和 DSP 所需的算力,ARMv9 將原本支持的可伸縮矢量擴展(Scalable Vector Extension,SVE)升級到了 2.0 版本。
這項技術可以改善機器學習和數字信號處理應用的性能表現,有助于對 5G 系統、VR/AR、機器學習等一系列工作負載的處理。 ? SVE2 提供了可調節的向量(Vector,矢量)大小,范圍從 128b(bit, 位)到 2048b,從而允許向量的可變粒度為 128b,這種變化并不會受到硬件平臺的影響。這就意味著,軟件開發人員將只需要編譯一次其代碼,就可以適用于 Armv9 乃至于后續產品中,實現“編寫一次,到處運行”。同樣,相同的代碼將能夠在具有較低硬件執行寬度能力的更保守的設計上運行,這對于 Arm 設計從物聯網、移動到數據 中心的 CPU 而言至關重要。
? SVE2 擴展還增加了壓縮和解壓縮 CPU 核心內的代碼和數據的能力,因為將數據移入和移出芯片的過程耗電很大,盡可能多使用芯片內的數據可以減少這種數據移動,從而降低能耗。 ? 更值得一提的是 Confidential Compute Architecture(CCA),中文名稱為機密計算架構,這也是 Arm 本次版本更新最重要的內容。其實安全問題近些年變得愈演愈烈,勒索病毒與黑客攻擊無時無刻不在活動。
面對層出不窮的網絡攻擊問題,既需要網絡服務商、軟件公司的努力,也需要包括 Arm 在內的硬件基礎設施提供商從源頭上封堵可能存在的漏洞,就促成了 CCA 的出現。這是一種基于架構層面的安全防護能力,通過打造基于硬件的安全運行環境來執行計算,保護部分代碼和數據,免于被存取或修改,乃至不受特權軟件的影響。 ?
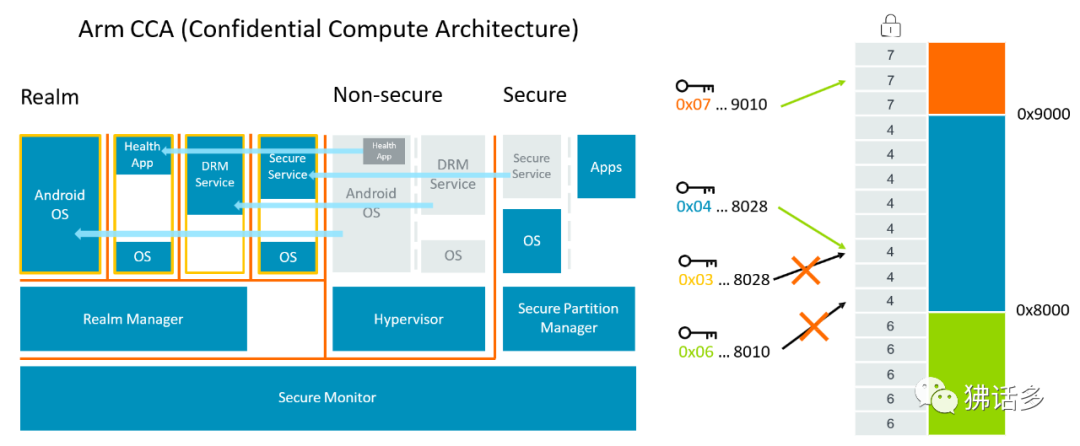
△ Arm 機密計算架構(左),Android 11 和 OpenSUSE 引入的內存標簽擴展技術(右) ? 為此 CCA 引入了動態創建機密領域(Realms)的概念——這是一個安全的容器化執行環境,支持安全的數據操作,可將數據與 hypervisor 或操作系統隔離。Hypervisor 的管理功能由“領域管理器” (realms manager)承擔,而 hypervisor 本身只負責調度和資源分配。使用“領域”的優勢在于極大地減少了在設備上運行給定應用程序的信任鏈,操作系統在很大程度上對安全問題變得透明,也允許需要監督控制的關鍵任務應用程序能夠在任何設備上運行。
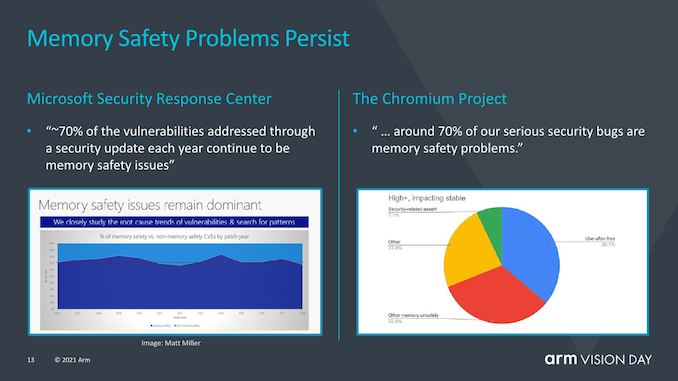
? 在實際應用中,內存是非常容易被攻擊的一環,內存安全也一直成為行業的關注點,如何在內存安全漏洞被利用之前就能發現問題,是提高全球軟件安全的重要一步。為此,Arm 與 Google 持續合作開發的“內存標簽擴展”(MTE)技術也成為 Armv9 的一個組成部分,可在軟件中查找內存的空間和時間安全問題,將指向內存的指針和標簽建立聯系,并在使用指針時檢查這個標簽是否正確。如果存取超過范圍,標簽檢查就會失敗,從而可以在第一時間發現內存安全漏洞并進行封堵。 ?
Arm架構升級,v9與v8版本有何差異?
在過去多年里,Arm對ISA進行了改進,也對體系結構進行了各種更新和擴展。當中一些可能很重要,有些可能也是一瞥而過。 ?
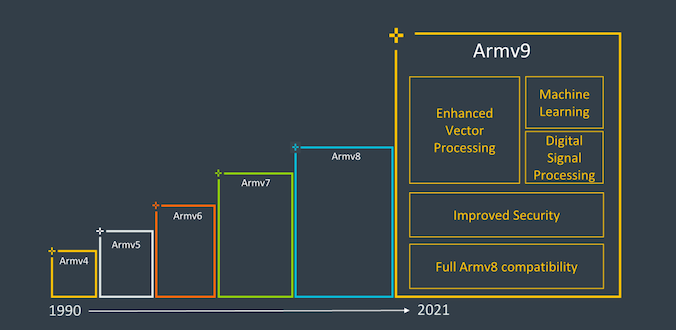
? 近日,作為Arm的Vision Day活動的一部分,該公司正式發布了該公司的新一代Armv9架構的首個細節,為Arm未來十年內成為下一個3000億芯片的計算平臺奠定了基礎。 ?
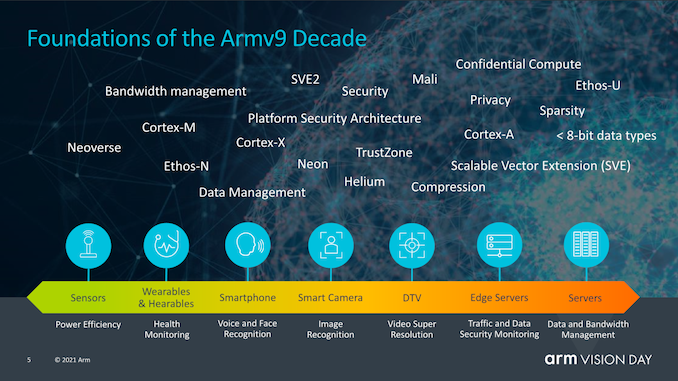
? 讀者可能會問的一個大問題是,Armv9與Armv8究竟有何不同,能讓架構獲得如此大的提升。確實,從純粹的ISA角度來看,v9可能不像v8相比v7那樣實現根本性的跳躍,后者引入了AArch64,一個完全不同的執行模式和指令集,該指令集與AArch32相比具有更大的微體系結構分支,例如擴展寄存器,64位虛擬地址空間和更多改進。
? Armv9繼續使用AArch64作為基準指令集,但是在其功能上增加了一些非常重要的擴展,以保證architecture numbering的增加,并且允許Arm不僅可以獲得對AArch64進行某種軟件重新基準化v9的新功能,還能保持我們多年來在v8上獲得的擴展。 ? Arm認為新架構Armv9有三個主要支柱,即安全性、AI以及改進的矢量和DSP功能。對于v9,安全性是一個非常重要的主題,我們將深入探討新擴展和功能的新細節,但是首先談到的DSP和AI功能應該很簡單。 ?
? ? 新的Armv9兼容CPU所承諾的最大的新功能可能是開發人員和用戶可以立即看到的——SVE2作為NEON的后繼產品。 ? 可伸縮矢量擴展(SVE)的于2016年首次亮相,并首次在富士通的A64FX CPU內核中實現,該芯片已為日本排名第一的超級計算機Fukagu提供支持。SVE的問題在于,新的可變矢量長度SIMD指令集的第一次迭代的范圍相當有限,并且更多地針對HPC工作負載,缺少了許多仍由NEON涵蓋的更通用的指令。 ?
SVE2于2019年4月發布,旨在通過用所需指令補充新的可擴展SIMD指令集來解決此問題,以服務于類似DSP等目前仍在使用NEON的工作負載。 ? 除了增加的各種現代SIMD功能外,SVE和SVE2的優勢還在于其可變的向量大小,范圍覆蓋了128b到2048b,讓其無論在什么硬件運行,都允許向量的可變粒度為128b。如果純粹從向量處理和編程的角度來看,這意味著軟件開發人員將只需要編譯一次其代碼,并且如果將來某個CPU帶有本地的512b SIMD execution pipelines,該代碼將能夠充分利用單元的整個寬度。同樣,相同的代碼將能夠在具有較低硬件執行寬度能力的保守設計上運行,這對于Arm設計從物聯網、移動到數據中心的CPU而言至關重要。在保留Arm體系結構的32b編碼空間的同時,它還可以完成所有這些工作。然而類似X86這樣的架構則需要根據矢量尺寸增加新的指令和擴展。 ?
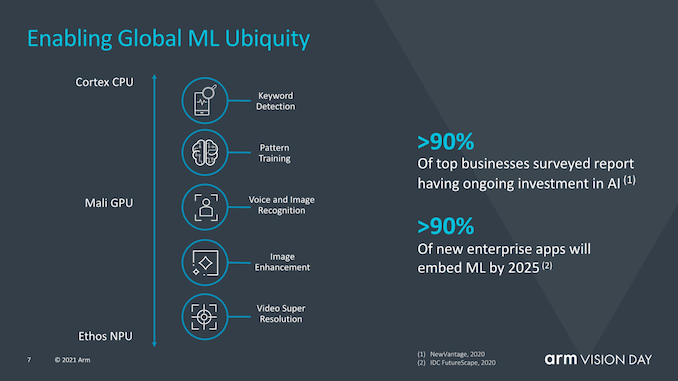
? 機器學習也被視為Armv9的重要組成部分,因為Arm認為在未來幾年中,越來越多的ML工作負載將變得司空見慣,當中包括了對性能或電源效率有至關重要要求的場景中。那就讓在專用加速器上運行ML工作負載變成長久的需要,與此同時,我們還會繼續在CPU上運行較小范圍的ML工作負載。 ? 矩陣乘法指令(Matrix multiplication instructions )是此處的關鍵,它將代表生態系統中將更大范圍采用v9 CPU作為基本功能所邁出的重要一步。 ?
通常,我認為SVE2可能是保證升級到v9的最重要因素,因為它是更確定的ISA功能,可以在日常使用中與v8 CPU區別開來,并且可以保證軟件生態系統能夠正常運行,這與現有的v8堆棧有所不同。對于服務器領域的Arm來說,這實際上已經成為一個相當大的問題,因為軟件生態系統仍在基于v8.0的軟件包基礎上,不幸的是,該軟件包缺少了最重要的v8.1大型系統擴展。 ? 使整個軟件生態系統向前發展,并假設新的v9硬件具有新的體系結構擴展功能,這將有助于推動事情發展,并可能解決某些當前情況。
? 但是,v9不僅涉及SVE2和新指令,它還非常注重安全性,在安全性方面我們將看到一些更根本的變化。 ?
介紹機密的計算架構
? 在過去的幾年中,安全性和硬件安全性漏洞已成為芯片行業的頭等大事,Spectre,Meltdown等漏洞的出現及其所有同級邊信道攻擊都表明,重新思考如何保證安全成為了一個基本需求。Arm希望用來解決這一總體問題的方法是通過引入Arm機密計算體系結構(Arm Confidential Compute Architecture:CAA)來重新設計安全應用程序的工作方式。 ?
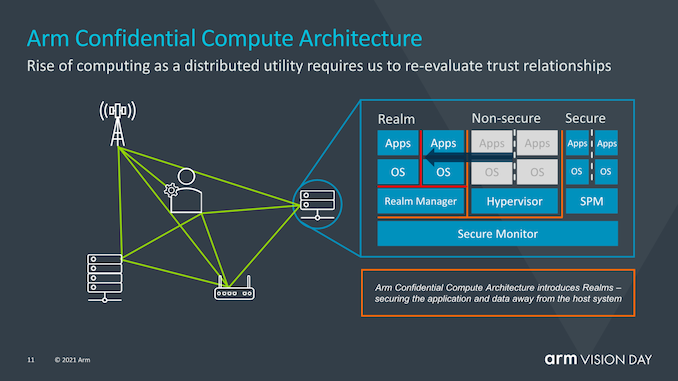
? 在繼續之前,我想提箱一下,今天的披露僅僅是對新CCA運作方式的高層次解釋,Arm說,有關新安全機制的確切工作原理的更多細節將在今年夏天的晚些時候公布。 ?
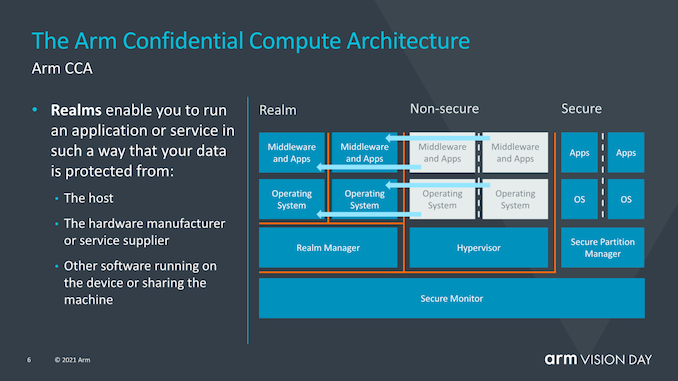
? CCA的目標是從當前的軟件堆棧情況中獲得更大的收益,在當前的軟件堆棧情況下,在設備上運行的應用程序必須固有地信任它們所運行的操作系統和虛擬機管理程序。傳統的安全模型是基于以下事實建立的:更高特權的軟件層被允許查看較低層的執行,然而當操作系統或系統管理程序被以任何方式損害時,這就可能成為了一個問題。
? CCA引入了動態創建““realms”的新概念,可以將其視為對OS或虛擬機管理程序完全不透明的安全容器化執行環境。系統管理程序將仍然存在,但僅負責調度和資源分配。而“realm”將由稱為“ealm manager”的新實體管理,其被認為是一段新的代碼,大致大小約為hypervisor的1/10。 ? realm內的應用程序將能夠“證明”領域管理器以確定其是否可信任,這對于傳統的虛擬機管理程序而言是不可能的。 ?
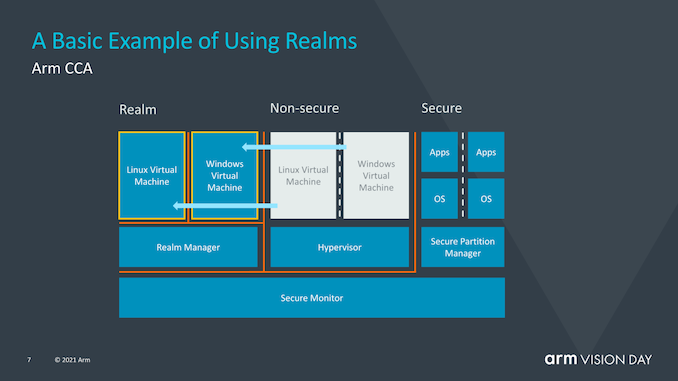
? Arm并沒有深入探討究竟是什么造成了realm與操作系統和虛擬機管理程序的非安全世界之間的這種隔離,但聽起來確實像硬件支持的地址空間,但它們無法相互交互。 ? ?
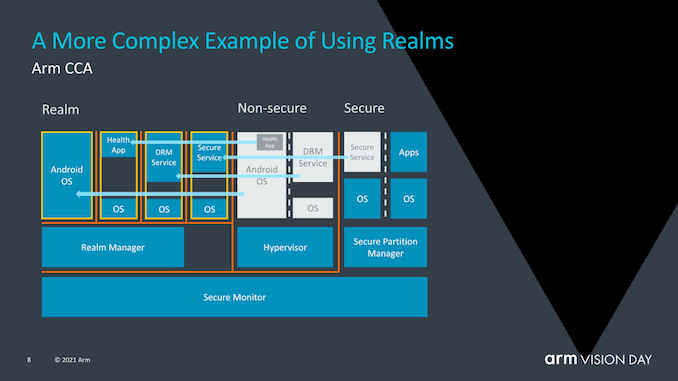
? 使用realms的優勢在于,它極大地減少了設備上運行的給定應用程序的信任鏈,并且OS對安全性問題變得越來越透明。與當今需要企業或企業使用帶有授權軟件堆棧的專用設備的情況相反,需要監督控制的關鍵任務應用程序將能夠在任何設備上運行。 ?
?
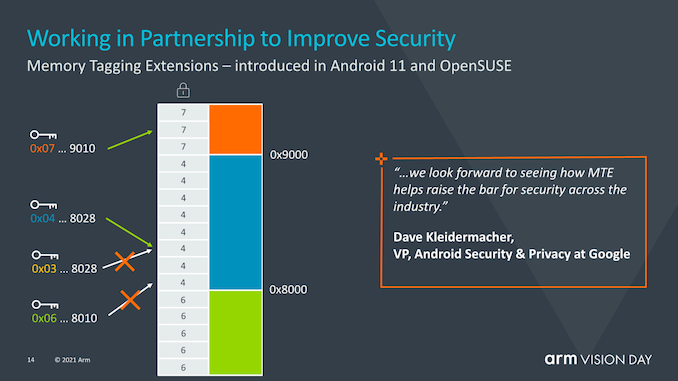
? MTE(memory tagging extensions)并不是v9的新功能,而是隨v8.5一起引入的,MTE或內存標記擴展旨在幫助解決世界軟件中兩個最持久的安全問題。緩沖區溢出(Buffers overflows)和無用后使用(use-after-free)是持續的軟件設計問題,在過去的50年中,這些問題一直是軟件設計的一部分,并且可能需要花費數年的時間才能對其進行識別或解決。MTE旨在通過在分配時標記指針并在使用時進行檢查來幫助識別此類問題。 ?
未來的Arm CPU路線圖
這與v9沒有直接關系,但是與即將到來的v9設計的技術路線圖緊密相關,Arm還談到了有關他們在未來2年中對v9設計的預期性能的一些觀點。 ?
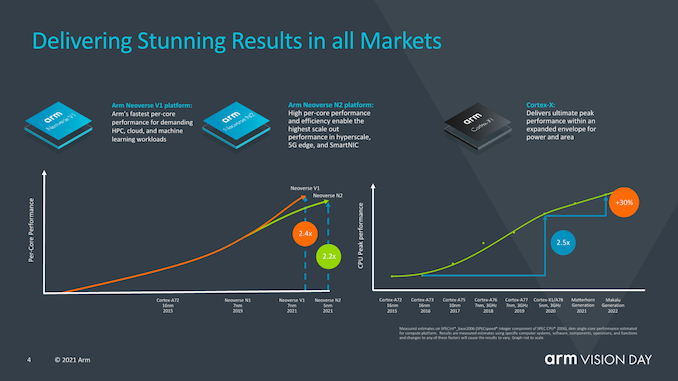
? Arm談到了移動市場在今年如何將帶有X1的設備性能提升了2.4倍(此處我們僅指ISO流程設計的IPC),該性能是幾年前推出的Cortex-A73的兩倍。
? 有趣的是,Arm還談到了Neoverse V1設計及其如何達到A72類似設計性能的2.4倍,并透露他們期待著他今年晚些時候發布的首批V1設備。 ? 對于代號為“ Matterhorn”和“ Makalu”的下一代移動IP內核,該公司公開了這兩代產品的合計預期IPC增益為30%,其中不包括SoC設計人員可以獲得的頻率或任何其他其他性能增益。這實際上代表著這兩種新設計的世代增加了14%,并且如幻燈片中的性能曲線所示,這表明相對于自A76以來Arm在過去幾年所管理的工作而言,改進的步伐正在放緩。不過,該公司指出,進步速度仍然遠遠超過行業平均水平。但潭門也坦言,這被一些行業參與者拖累了。 ?
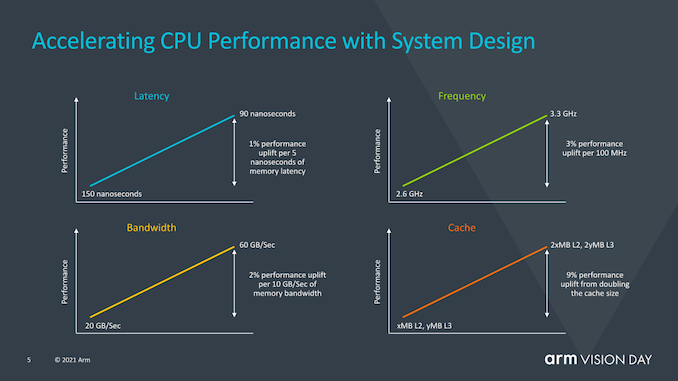
? Arm還提供了一張很有意思的幻燈片,該幻燈片旨在關注系統側對性能的影響,而不僅僅是CPU IP性能。從這里提供的一些數據可以看到,例如每5ns的內存延遲中有1%的性能,這是我們現在已經廣泛討論了幾代的數字,但是Arm在這里還指出,排除了是否通過改善內存路徑,增加緩存或優化頻率功能來改善實現的其他各個方面,他們可以使用整整一代的CPU性能提升,我認為這是對SoC供應商當前保守方法的一種評價,這些方法沒有充分利用X1內核的預期性能余量,并且隨后也未達到新內核的預期性能預測。 ?

? Arm繼續將CPU視為未來最通用的計算模塊。盡管專用的加速器或GPU將會占有一席之地,但它們很難解決一些重要問題,例如可編程性,保護性,普遍性(本質上是在任何設備上運行它們的能力)以及經過驗證的正常工作的能力。當前,計算生態系統在運行方式上極為分散,不僅設備類型不同,而且設備供應商和操作系統也不同。 ?
SVE2和Matrix乘法可以極大地簡化軟件生態系統,并允許計算工作負載以更統一的方法向前邁進,該方法將來將可以在任何設備上運行。 ?

? 最后,Arm還分享了有關Mali GPU未來的新信息,并透露該公司正在開發VRS等新技術,尤其是Ray Tracing。這一點令人非常令人驚訝,也表明AMD和Nvidia引入RT推動的臺式機和控制臺生態系統也有望將移動GPU生態系統推向RT。 ?
Armv9設計即將在2022年初面世
今天的公告以一種非常高級的形式出現,我們希望Arm在接下來的幾個月中,在公司通常的年度技術披露中,更多地談論Armv9的各種細節和新功能,例如CCA。 ? 總的來說,Armv9似乎是更基本的ISA轉變(可以看作SVE2)與軟件生態系統的總體重新基準的結合,以匯總v8擴展的最后十年,并為下一個十年奠定基礎Arm體系結構。 ? Arm于去年下半年已經談論過Neoverse V1和N2,我確實希望N2至少最終是基于v9而設計發布的。Arm進一步透露,更多基于Armv9的 CPU設計(可能是移動端Cortex-A78和X1的后續產品)將于今年推出,而新的CPU可能已經被通常的SoC供應商所采用,并且有望成為在2022年初在商用設備中出現。 ?
審核編輯:黃飛
?














 工商網監
工商網監
評論