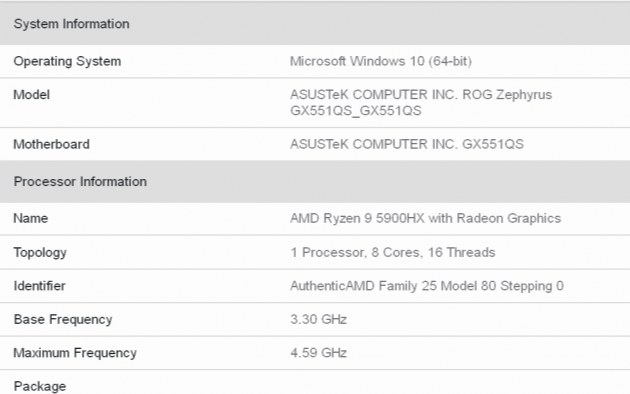
 電子發燒友App
電子發燒友App


AMD 長期以來一直在爭奪 GPU 計算市場份額。自從 Nvidia 憑借其 Tesla 架構搶占先機以來,AMD 就一直在追趕。Terascale 3 從 VLIW5 遷移到 VLIW4,以提高計算工作負載中執行單元的利用率。GCN 取代了 Terascale,并強調 GPGPU 和圖形應用程序的一致性能。然后,AMD 將其 GPU 架構開發分為單獨的 CDNA 和 RDNA 線路,分別專門用于計算和圖形。
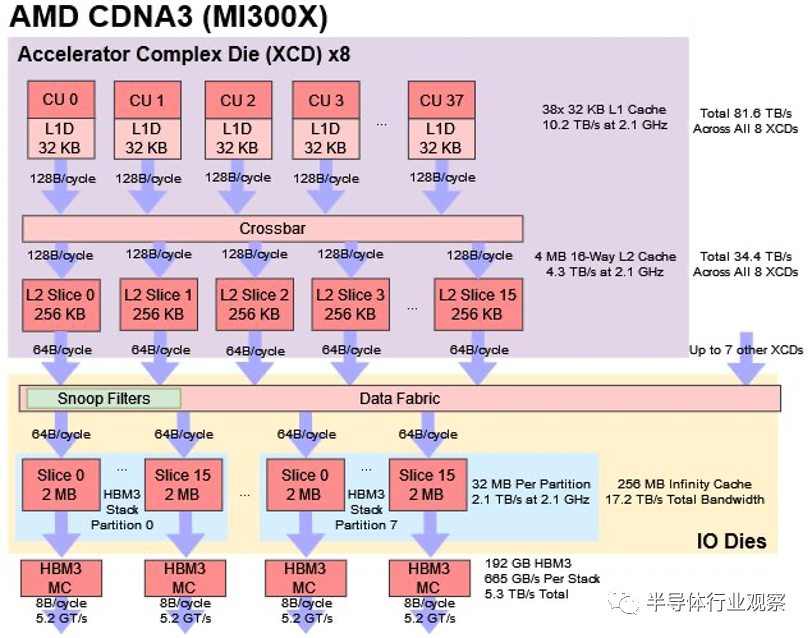
CDNA 2 最終為 AMD 帶來了顯著的成功。MI250X 和 MI210 GPU 贏得了多個超級計算機合同,其中包括 ORNL 的 Frontier,該計算機在 2023 年 11 月的 TOP500 排行榜上排名第一。但是,雖然 CDNA2 提供了穩定且經濟高效的 FP64 計算,但 H100 擁有更好的 AI 性能并提供了更大的統一 GPU。
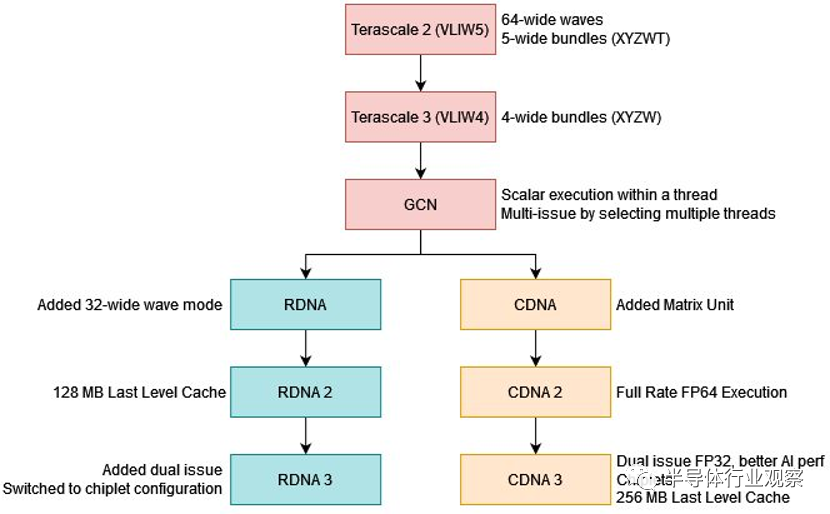
CDNA 3 希望通過提供 AMD 提供的所有功能來縮小這些差距。MI300X 配備了先進的小芯片設置,充分展示了該公司在先進封裝技術方面的經驗。與 Infinity Fabric 組件一起,先進的封裝使 MI300X 能夠進行擴展,以與 Nvidia 最大的 GPU 競爭。在內存方面,RDNA 系列的 Infinity Cache 被引入 CDNA 領域,以緩解帶寬問題。但這并不意味著 MI300X 的內存帶寬很輕。它仍然擁有龐大的 HBM 設置,使其兩全其美。最后,CDNA 3 的計算架構獲得了顯著的世代改進,以提高吞吐量和利用率。
01.?GPU布局
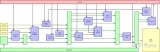
AMD 一直有使用小芯片來廉價擴展 Ryzen 和 Epyc CPU 核心數量的傳統。MI300X 在高級別上使用類似的策略,將計算拆分到加速器復合芯片 (XCD) 上。XCD 類似于 CDNA 2 或 RDNA 3 的圖形計算芯片 (GCD) 或 Ryzen 的核心復合芯片 (CCD)。AMD 可能會更改命名,因為 CDNA 產品缺乏 RDNA 系列中的專用圖形硬件。

每個 XCD 包含一組核心和一個共享緩存。具體來說,每個 XCD 物理上都有 40 個 CDNA 3 計算單元,其中 38 個在 MI300X 上的每個 XCD 上啟用。XCD 上也有一個 4 MB 二級緩存,為芯片的所有 CU 提供服務。MI300X 有 8 個 XCD,總共有 304 個計算單元。
這比 MI250X 的 220 個 CU 有了很大的增加。更好的是,MI300X 可以將所有這些 CU 作為單個 GPU 公開。在 MI250X 上,程序員必須手動在兩個 GPU 之間分配工作,因為每個 GPU 都有單獨的內存池。
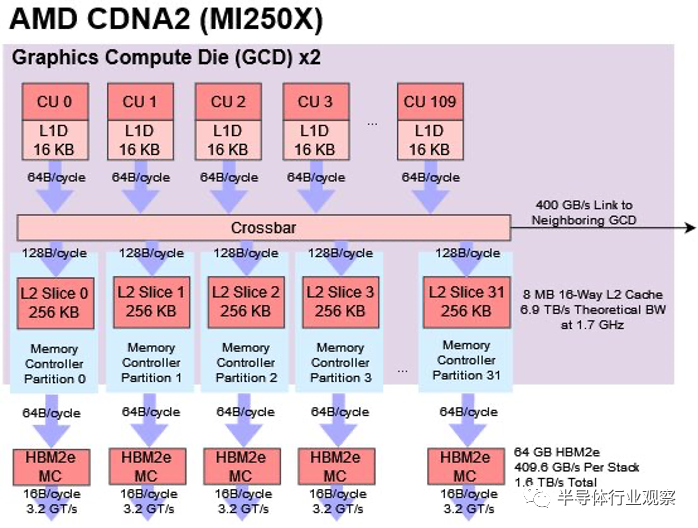
Nvidia 的 H100 由 132 個流式多處理器 (SM) 組成,并將它們作為一個大型統一 GPU 呈現給程序員。H100 采用傳統方法,在大型單片芯片上實現所有計算。即使所有東西都在同一個芯片上,H100 也太大了,無法讓所有 SM 平等地訪問緩存。因此,H100 將 L2 拆分為兩個實例。單個 SM 可以使用全部 50 MB 的 L2,但訪問超過 25 MB 會導致性能損失。
盡管如此,Nvidia 的策略比 MI300X 的策略更有效地利用了緩存容量。MI300X XCD 不會使用其他 XCD 上的 L2 容量進行緩存,就像 Epyc/Ryzen 上的 CCD 不會分配到彼此的 L3 緩存中一樣。
英特爾的 Ponte Vecchio (PVC) 計算 GPU 進行了非常有趣的比較。PVC 將其基本計算構建塊放置在稱為“Compute Tiles”的芯片中,這大致類似于 CDNA 3 的 XCD。同樣,PVC 的 Base Tile 具有與 CDNA 3 的 IO 芯片類似的功能。兩者都包含大型末級緩存和 HBM 內存控制器。與 MI300X 一樣,Ponte Vecchio 卡可以作為具有統一內存池的單個 GPU 公開。
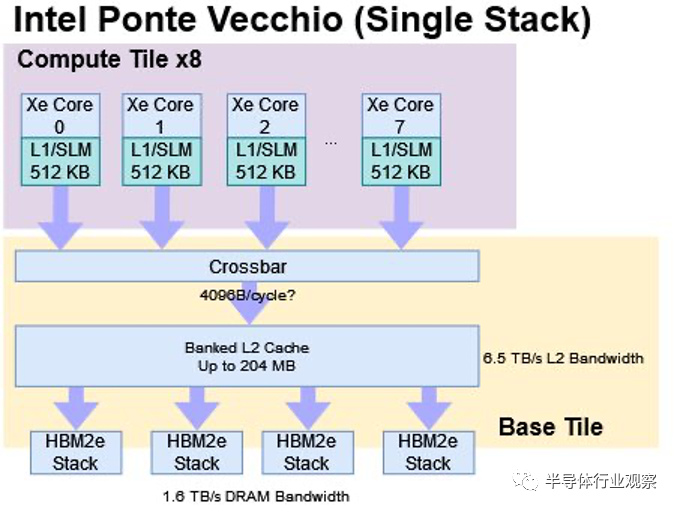
然而,也存在重要的差異。與 CDNA 3 XCD 上的 38 個計算單元相比,Ponte Vecchio 的計算塊更小,只有 8 個 Xe 核心。英特爾沒有使用計算塊寬緩存,而是使用更大的 L1 緩存來減少跨芯片流量需求。使用兩層 Ponte Vecchio 部件作為統一 GPU 也帶來了挑戰。兩個堆棧之間的 EMIB 橋僅提供 230 GB/s 的帶寬,如果訪問跨所有內存控制器進行條帶化,則不足以充分利用 HBM 帶寬。為了解決這個問題,英特爾提供了 API,可以讓程序在 NUMA 配置中與 GPU 配合使用。
在物理構造方面,PVC和CDNA 3的設計面臨著不同的挑戰。CDNA 3 提供具有 HBM 的統一內存池的能力需要 IO 芯片之間的高帶寬。PVC 使用帶寬相對較低的 EMIB 鏈路。但 PVC 的設計變得復雜,因為它使用四種具有不同工藝節點和鑄造廠的模具類型。AMD 在 MI300X 中僅使用兩種芯片類型,并且兩個節點(6 納米和 5 納米)均來自臺積電。
02.?解決帶寬問題
幾十年來,計算速度一直超過內存。與 CPU 一樣,GPU 也通過日益復雜的緩存策略來應對這一問題。CDNA 2 使用具有 8 MB L2 的傳統兩級緩存層次結構,依靠 HBM2e 來保持執行單元的運行。但即使使用 HBM2e,MI250X 的帶寬需求也比 Nvidia 的 H100 更嚴重。如果 AMD 只是增加更多的計算能力,帶寬匱乏可能會成為一個嚴重的問題。因此,AMD 借鑒了 RDNA(2) 的經驗,添加了“無限緩存”。
與消費級 RDNA GPU 非常相似,MI300 的無限緩存就是技術文檔中所稱的“附加最后一級內存”(MALL),這是一種奇特的說法,表示最后一級緩存級別是內存端緩存。與更靠近計算單元的 L1 和 L2 緩存相比,Infinity Cache 連接到內存控制器。所有內存流量都會通過無限緩存,無論它來自哪個塊。其中包括 IO 流量,因此對等 GPU 之間的通信可以受益于無限緩存帶寬。由于無限高速緩存始終具有 DRAM 內容的最新視圖,因此它不必處理窺探或其他高速緩存維護操作。
但由于內存端緩存距離計算較遠,因此通常會出現較高的延遲。因此,AMD 在 CDNA 3 和 RDNA 2 上都配備了數兆字節的 L2 緩存,以將計算與內存端緩存的較低性能隔離開來。
與 RDNA 2 一樣,CDNA 3 的無限緩存是 16 路組相聯的。然而,CDNA 3 的實現針對帶寬比針對容量進行了更優化。它由 128 個片組成,每個片容量為 2 MB,每個周期讀取帶寬為 64 字節。所有切片每個周期總共可以傳輸 8192 字節,這對于 2.1 GHz 下的 17.2 TB/s 來說是不錯的。
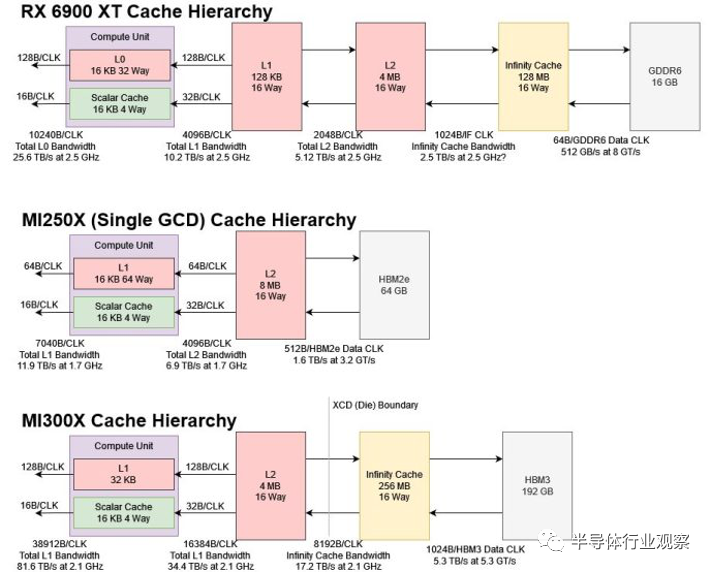
相比之下,RDNA 2 的 128 MB 無限緩存可以在所有片上每個周期提供 1024 字節,從而在 2.5 GHz 下提供 2.5 TB/s 的理論帶寬。芯片截圖顯示每個 Infinity Cache 片有 4 MB 的容量,并提供 32B/周期。因此,RDNA 2 使用更大的slice、更少的slice,并且每個slice的帶寬也更少。
MI300X 對帶寬的關注意味著計算密度較低的工作負載如果能夠獲得足夠的無限緩存命中,仍然可以享受不錯的性能。這應該會讓 CDNA 3 的執行單元更容易運行,盡管主內存帶寬與計算的比率沒有太大變化并且仍然落后于 Nvidia。
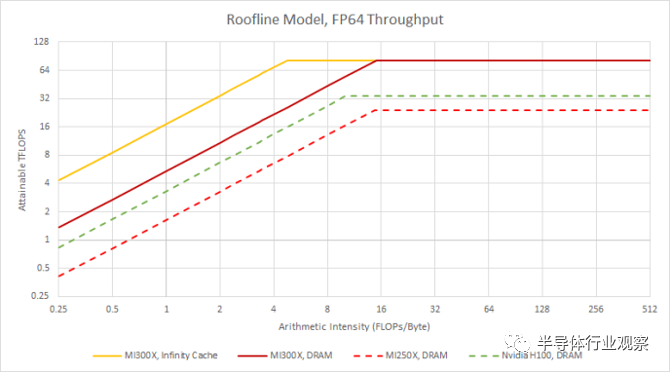
如果我們使用 Infinity Cache 的理論帶寬構建 MI300X 的屋頂線模型,我們可以實現完整的 FP64 吞吐量,每字節加載 4.75 FLOP。與 DRAM 相比,這是一個巨大的改進,DRAM 每加載一個字節需要 14.6FLOP 到 15 次 FLOP。
03.?跨芯片帶寬可能面對的挑戰
MI300X 的 Infinity Fabric 跨越四個 IO 芯片,每個芯片連接到兩個 HBM 堆棧和關聯的緩存分區。然而,當 MI300X 作為具有統一內存池的單個邏輯 GPU 運行時,芯片到芯片連接的帶寬可能會限制實現完整的無限緩存帶寬。如果內存訪問在內存控制器(以及緩存分區)上均勻分布,就像大多數 GPU 設計的典型情況一樣,可用的芯片到芯片帶寬可能會阻止應用程序達到理論上的無限緩存帶寬。
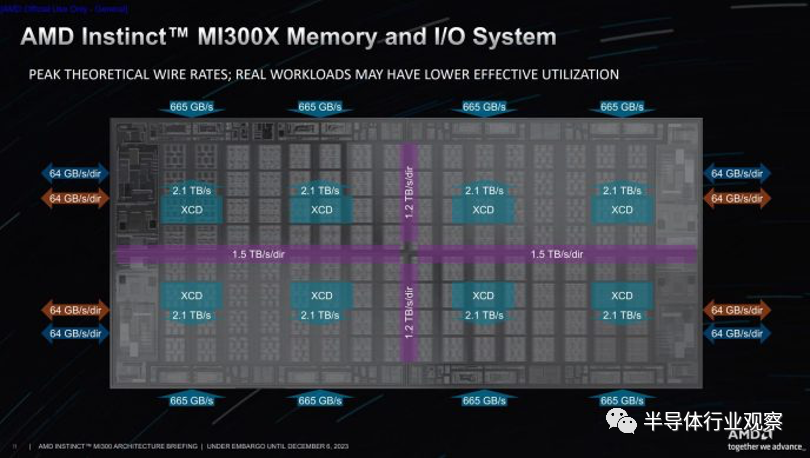
首先,讓我們關注單個 IO die 分區。它沿著與其他 IO 芯片相鄰的兩個邊緣具有 2.7 TB/s 的入口帶寬。它的兩個 XCD 可以獲得 4.2 TB/s 的 Infinity 緩存帶寬。如果 L2 未命中請求在芯片上均勻分布,則該帶寬的 3/4 或 3.15 TB/s 必須來自對等芯片。由于 3.15 TB/s 大于 2.7 TB/s,跨芯片帶寬將限制可實現的緩存帶寬。
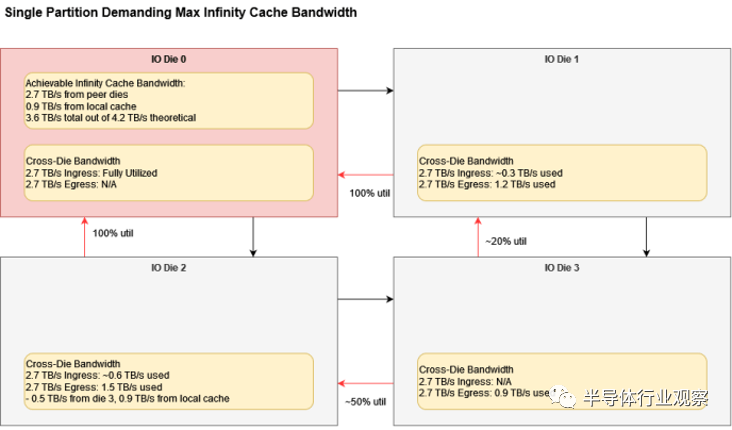
我們可以在對角添加芯片而不會產生任何差異,因為其所需的所有芯片間帶寬都在相反的方向上。MI300X 具有雙向芯片到芯片鏈接。
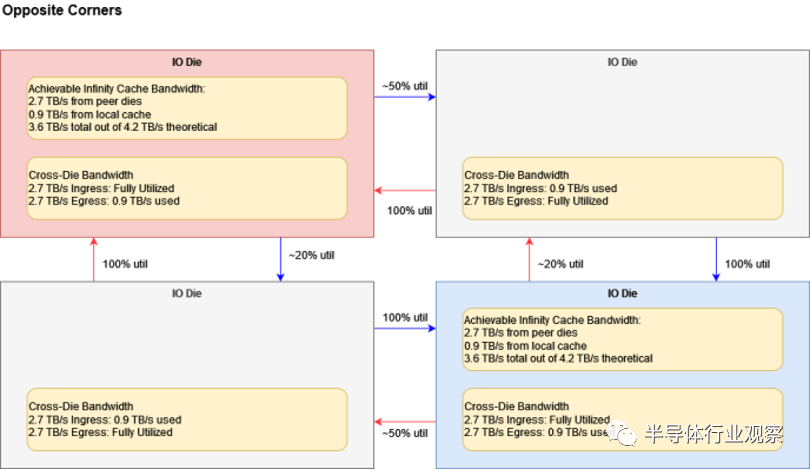
如果所有芯片都需要統一配置中的最大無限緩存帶寬,事情就會變得更加復雜。消耗額外的跨芯片帶寬,因為對角芯片之間的傳輸需要兩跳,這會減少每個芯片可用的入口帶寬。
雖然 MI300X 的設計就像一個大型 GPU,但將 MI300X 拆分為多個 NUMA 域可以提供更高的組合無限緩存帶寬。AMD 可能會有一個 API,可以在不同的 IO 芯片之間透明地分割程序。此外,高 L2 命中率(hit rates)將最大限度地減少帶寬問題的可能性,這將有助于避免這些瓶頸。在 Infinity Cache 命中率較低的情況下,MI300X 的芯片間鏈接足夠穩健,并提供充足的帶寬來順利處理 HBM 流量。
04.?跨XCD一致性
盡管無限緩存不必擔心一致性,但二級緩存卻需要擔心。普通 GPU 內存訪問遵循寬松的一致性模型,但程序員可以使用atomics來強制線程之間的排序。AMD GPU 上的內存訪問也可以用 GLC 位(全局級一致:Global Level Coherent)進行標記。如果 AMD 希望將 MI300X 作為單個大 GPU 而不是像 MI250X 那樣的多 GPU 配置,那么這些機制仍然必須發揮作用。
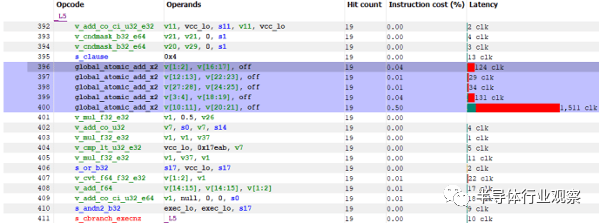
在之前的 AMD GPU 上,atomics和coherent 訪問是在 L2 處理的。設置 GLC 位的加載將繞過 L1 緩存,從而從 L2 獲取最新的數據副本。這不適用于 MI300X,因為緩存行的最新副本可能位于另一個 XCD 的 L2 緩存上。AMD 可以使相干訪問繞過 L2,但這會降低性能。這可能適用于游戲 GPU,因為游戲 GPU 的一致性訪問并不是太重要。但 AMD 希望 MI300X 在計算工作負載方面表現良好,并需要 MI300A(APU 變體)在 CPU 和 GPU 之間高效共享數據。這就是 Infinity Fabric 的用武之地。

與 Ryzen 上的 Infinity Fabric 一樣,CDNA 3 具有 XCD 連接到 IO 芯片的 Coherent Master(CM)。相干從屬設備 (CS:Coherent Slaves) 與無限高速緩存 (IC:Infinity Cache) 片一起位于每個內存控制器中。我們可以通過 Ryzen 文檔推斷它們是如何工作的,該文檔顯示 Coherent Slaves 有一個探針過濾器和用于處理原子事務的硬件。MI300X 可能有類似的 CS 實現。

如果 CS 上出現一致寫入,則必須確保任何執行一致讀取的線程都會觀察到該寫入,無論該線程在 GPU 上的何處運行。這意味著任何緩存了該行的 XCD 都必須從 Infinity Cache 重新加載它才能獲取最新數據。這一般會讓我們認為,CS 必須跨所有 XCD 探測 L2 緩存,因為其中任何一個都可以緩存相應的數據。探測過濾器通過跟蹤哪些 XCD 實際緩存了該行來幫助避免這種情況,從而避免不必要的探測流量。CDNA 3 的白皮書稱窺探過濾器(探針過濾器的另一個名稱)足夠大,可以覆蓋多個 XCD L2 緩存。我當然相信他們,因為 MI300X 在所有 8 個 XCD 上都有 32 MB 的 L2。即使是消費級 Ryzen 部件也可以擁有更多 CCD 專用緩存,供探針過濾器覆蓋。
得益于 CS 和 CM 等類似 CPU 的 Infinity Fabric 組件,XCD 可以擁有私有回寫式 L2 緩存,能夠處理芯片內一致訪問,而無需跨越 IO 芯片結構。AMD 本來可以采用一種簡單的解決方案,即連貫操作和atomics繞過 L2 直接進入無限緩存。這樣的解決方案將節省工程工作并創建更簡單的設計,但代價是降低一致性操作的性能。顯然,AMD 認為優化原子和相干訪問非常重要,因此需要付出更多努力。
然而,XCD 中的 CDNA 3 的工作方式仍然與之前的 GPU 非常相似。顯然,正常的內存寫入不會像 CPU 那樣自動使來自對等緩存的寫入行無效。相反,代碼必須顯式告訴 L2 write back dirty lines,并使對等 L2 緩存使非本地 L2 行無效。
05.?二級緩存
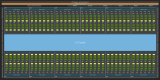
靠近計算單元,每個 MI300X XCD 都包含一個 4 MB 二級緩存。L2 是更傳統的 GPU 緩存,由 16 個slice構建。每個 256 KB slice可以提供每個周期 128 字節的帶寬。在 2.1 GHz 下,這對于 4.3 TB/s 來說是不錯的。作為與計算單元位于同一芯片上的最后一級緩存,L2 在充當 L1 未命中(misses)的后備裝置方面發揮著重要作用。
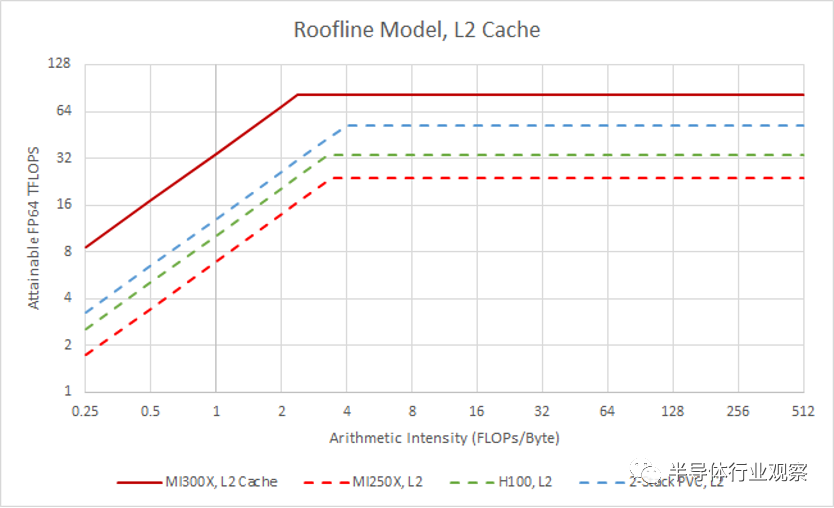
與H100和MI250X相比,MI300X具有更高的L2帶寬計算比。由于每個 XCD 都配有 L2,因此隨著 CDNA 3 產品配備更多 XCD,L2 帶寬自然會擴展。換句話說,MI300X 的 L2 布局避免了將單個緩存連接到大量計算單元并維持大量帶寬的問題。
PVC的L2則形成鮮明對比。隨著英特爾添加更多計算塊,基礎塊的共享 L2 的帶寬需求也不斷增加。從緩存設計的角度來看,PVC 的配置更簡單,因為 L2 充當單點一致性和 L1 未命中的后備。但它無法提供與 MI300X 的 L2 一樣多的帶寬。MI300X 還可能享有更好的 L2 延遲,使應用程序更容易利用緩存帶寬。
06.?一級緩存
CDNA 3 對高緩存帶寬的關注延續到了 L1。在與 RDNA 相匹配的舉措中,CDNA 3 的 L1 吞吐量從每周期 64 字節增加到 128 字節。與 GCN 中的 2048 位相比,CDNA 2 將每 CU 向量吞吐量提高到每周期 4096 位,因此 CDNA 3 翻倍的 L1 吞吐量有助于保持與 GCN 相同的計算與 L1 帶寬比率。
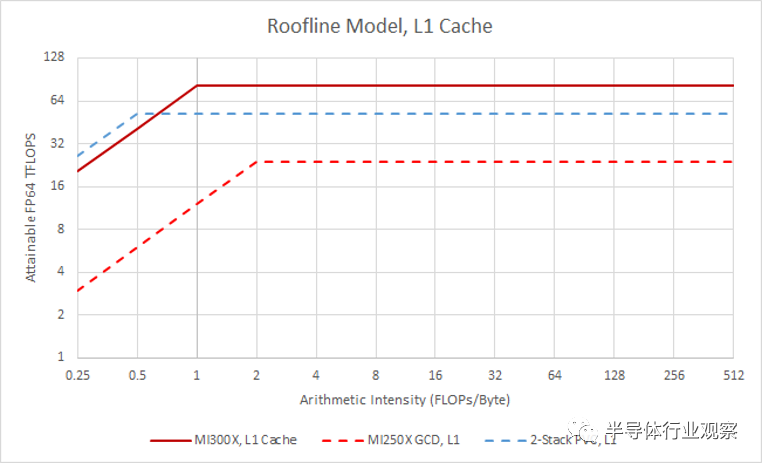
除了更高的帶寬外,CDNA 3 還將 L1 容量從 16 KB 增加到 32 KB。這一舉措再次反映了 RDNA 系列的發展,其中 RDNA 3 的一級緩存也獲得了類似的大小提升。較大緩存的較高命中率將降低平均內存訪問延遲,從而提高執行單元利用率。從 L2 及更高層傳輸數據會消耗電力,因此更高的命中率也有助于提高電力效率。
雖然 CDNA 3 改進了一級緩存,但 Ponte Vecchio 仍然是該類別的冠軍。PVC 中的每個 Xe 核心每個周期可傳輸 512 字節,為英特爾提供非常高的 L1 帶寬計算比。L1 也很大,為 512 KB。適合 L1 的內存綁定內核將在英特爾架構上表現良好。然而,Ponte Vecchio 缺乏計算塊級別的中級緩存,并且當數據溢出 L1 時可能會面臨嚴酷的性能懸崖。
07.?調度和執行單元
復雜的小芯片設置和修改后的緩存層次結構讓 AMD 將 MI300X 作為單個 GPU 呈現,從而解決了 MI250X 的最大弱點之一。但 AMD 并沒有就此解決。他們還對核心計算單元架構進行了迭代改進,解決了 CDNA 2 使用 FP32 單元的困難。
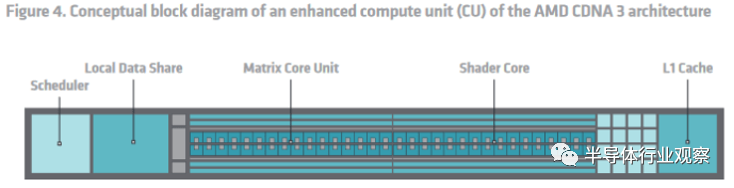
當 CDNA 2 轉向原生處理 FP64 時,AMD 通過打包執行提供了雙倍速率 FP32。編譯器必須將兩個 FP32 值打包到相鄰的寄存器中,并對這兩個值執行相同的指令。通常,除非程序員明確使用向量,否則編譯器很難實現這一點。
CDNA 3 通過更靈活的雙發行機制解決了這個問題。最有可能的是,這是 GCN 多問題功能的擴展,而不是 RDNA 3 的 VOPD/wave64 方法。每個周期,CU 調度程序都會選擇四個 SIMD 之一,并檢查其線程是否已準備好執行。如果多個線程準備就緒,GCN 可以選擇最多五個線程發送到執行單元。當然,GCN SIMD 只有一個 16 寬向量 ALU,因此 GCN 必須選擇具有不同指令類型的線程,準備好進行多發出。例如,標量 ALU 指令可以與矢量 ALU 指令一起發出。
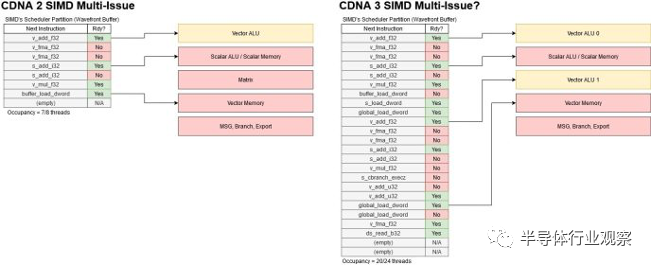
另一種方法是利用 wave64 更寬的寬度,讓線程在四個周期內完成兩條向量指令。然而,這樣做會破壞 GCN 在 4 個時鐘周期的倍數內處理 VALU 指令的模型。CDNA 3 與 GCN 的關系仍然比 RDNA 更為密切,重用 GCN 的多發行策略是明智之舉。AMD 還可以使用 RDNA 3 的 VOPD 機制,其中特殊的指令格式可以包含兩個操作。雖然該方法可以提高每個線程的性能,但依靠編譯器來查找雙問題對可能會成功或失敗。
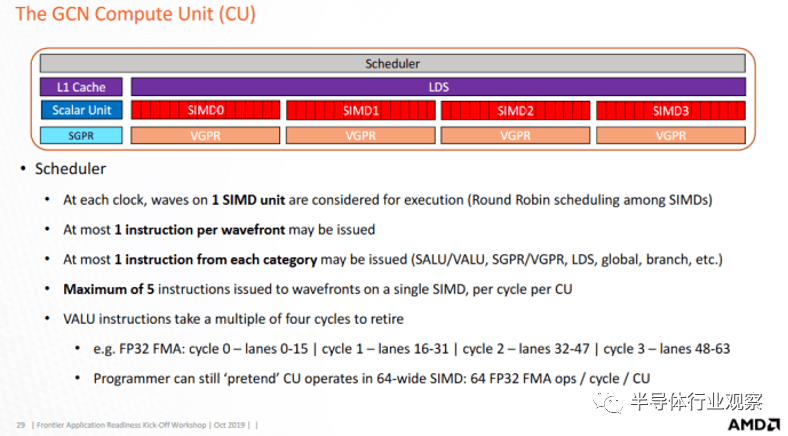
CDNA 3 的雙問題方法可能會將責任推給程序員,以通過更大的調度大小來公開更多線程級并行性,而不是依賴編譯器。如果 SIMD 有更多正在運行的線程,它將有更好的機會找到兩個帶有 FP32 指令準備執行的線程。至少,SIMD 需要兩個活動線程才能實現完整的 FP32 吞吐量。實際上,CDNA 3 需要更高的占用率才能實現良好的 FP32 利用率。GPU 使用按順序執行,因此各個線程通常會因內存或執行延遲而被阻塞。即使在滿員的情況下,保持一組執行單元的供電也可能很困難。
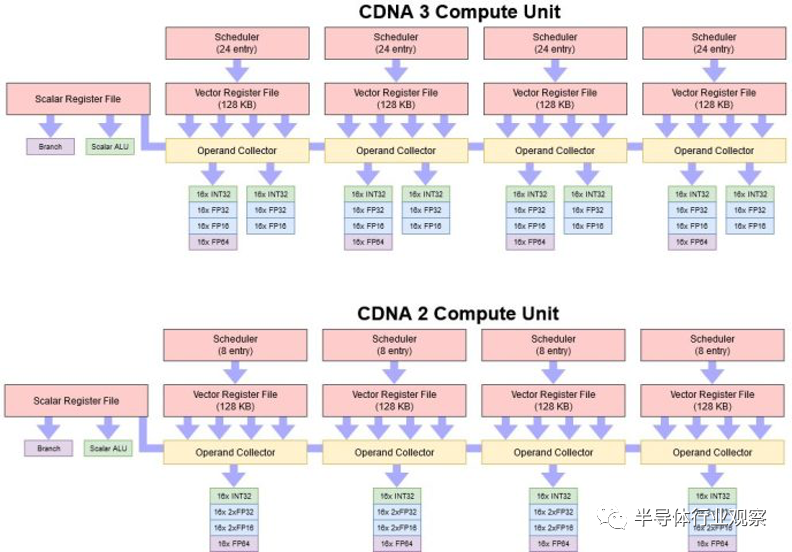
因此,AMD 將每個 CDNA 3 SIMD 可以跟蹤的線程數量從 8 個大幅增加到24 個。如果程序員可以利用這一點,CDNA 3 將更好地定位于多問題。但這可能很困難。AMD 沒有提到矢量寄存器文件容量的增加,這通常會限制 SIMD 可以運行的線程數量。如果每個線程使用較少的寄存器,向量寄存器文件可以保存更多線程的狀態,因此 CDNA 3 的多發出功能可能最適合具有很少活動變量的簡單內核。
寄存器文件帶寬對雙重發行提出了另一個挑戰。CDNA 2 的打包 FP32 執行不需要從向量寄存器文件中進行額外的讀取,因為它利用了傳遞 64 位值所需的更寬的寄存器文件端口。但單獨的指令可以引用不同的寄存器,并且需要從寄存器文件中進行更多讀取。添加更多寄存器文件端口的成本高昂,因此 CDNA 3“逐代改進了源緩存,以提供更好的重用和帶寬放大,以便每個向量寄存器讀取可以支持更多下游向量或矩陣操作” 。最有可能的是,AMD 正在使用更大的寄存器緩存來緩解端口沖突并保持執行單元的運行。
08.?矩陣運算
隨著機器學習的興起,矩陣乘法變得越來越重要。Nvidia 在這一領域投入了大量資金,多年前就在其 Volta 和 Turing 架構中添加了矩陣乘法單元(張量核心)。AMD 的 CDNA 架構增加了矩陣乘法支持,但當代 Nvidia 架構在矩陣乘法吞吐量方面投入了更多資金。這尤其適用于 AI 中常用的低精度數據類型,例如 FP16。
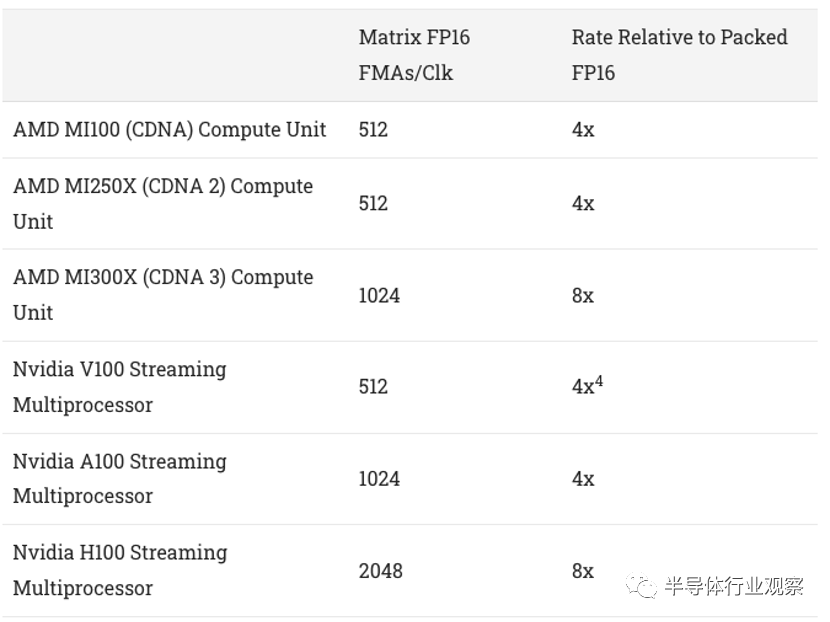
與前幾代 CDNA 相比,MI300X 通過將每 CU 矩陣吞吐量提高了一倍來迎頭趕上。最重要的是,MI300X 的小芯片設計允許大量的 CU。但 Nvidia 更高的每 SM 矩陣性能仍然使其成為一支不可忽視的力量。因此,CDNA 3延續了AMD從矢量FP64性能方面重擊Nvidia的趨勢,同時保持了孤立的強大AI性能。
09.?指令緩存
除了處理指令請求的內存訪問之外,計算單元還必須從內存中獲取指令本身。傳統上,GPU 的指令傳遞比較容易,因為 GPU 代碼往往很簡單并且不會占用大量內存。在DirectX 9時代,Shader Model 3.0甚至對代碼大小進行了限制。隨著 GPU 不斷發展以承擔計算任務,AMD 推出了具有 32 KB 指令緩存的 GCN 架構。如今,CDNA 2 和 RDNA GPU 繼續使用 32 KB 指令緩存。
CDNA 3 將指令緩存容量增加至 64 KB。關聯性也加倍,從 4 路變為 8 路。這意味著具有更大、更復雜內核的 CDNA 3 的指令緩存命中率更高。我懷疑 AMD 的目標是將 CPU 代碼天真地移植到 GPU。復雜的 CPU 代碼可能會對GPU 造成影響,因為它們無法通過長距離指令預取和準確的分支預測來隱藏指令緩存未命中延遲。更高的指令緩存容量有助于容納更大的內核,而增加的關聯性有助于避免沖突未命中。
與 CDNA 2 一樣,每個 CDNA 3 指令緩存實例為兩個計算單元提供服務。GPU 內核通常以足夠大的工作大小啟動,以填充許多計算單元,因此共享指令緩存是有效使用 SRAM 存儲的好方法。我懷疑 AMD 沒有在更多計算單元之間共享緩存,因為單個緩存實例可能難以滿足指令帶寬需求。
10.?寫在最后的話
CDNA 3 的白皮書稱“AMD CDNA 3 架構中最大的代際變化在于內存層次結構”,我不得不同意。與 CDNA 2 相比,雖然 AMD 改進了計算單元的低精度數學功能,但真正的改進是添加了無限緩存。
MI250X 的主要問題是它并不是真正的 GPU。它是兩個 GPU 共享同一個包,GCD 之間每個方向每秒只有 200 GB。根據 AMD 的評估,每個方向每秒 200 GB 不足以讓 MI250X 顯示為一個 GPU,這就是 AMD 顯著增加芯片到芯片帶寬的原因。
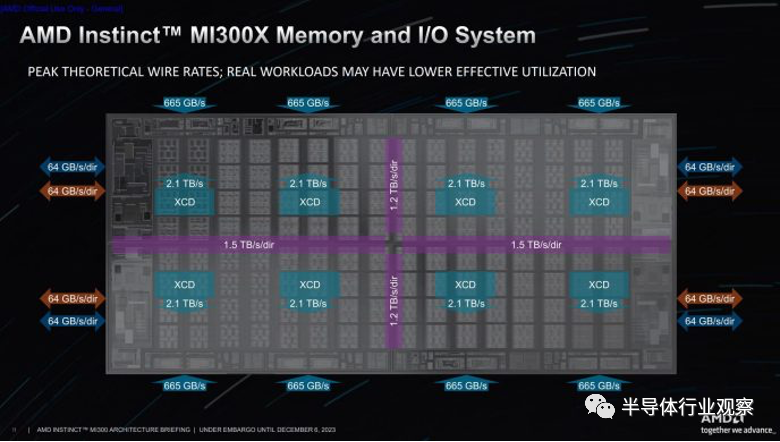
AMD 將東西向總帶寬提高到每個方向 2.4TB/秒,比 MI250X 增加了 12 倍。南北向總帶寬甚至更高,每個方向為 3.0TB/秒。隨著帶寬的大幅增加,AMD 能夠使 MI300 看起來像一個大型的統一加速器,而不是像 MI250X 那樣是 2 個獨立的加速器。
如果兩個 XCD 都需要所有可用內存帶寬,則一個芯片的 4.0 TB/s 總入口帶寬可能看起來不夠。然而,兩個 XCD 組合起來只能從 IO 芯片訪問高達 4.2TB/s 的帶寬,因此實際上 4.0TB/s 的入口帶寬不是問題。最大 4.0TB/s 的入口帶寬意味著單個 IO 芯片無法利用所有 5.3TB/s 的內存帶寬。
這與桌面 Ryzen 7000 部件類似,由于 Infinity Fabric 的限制,一個 CCD 無法充分利用 DDR5 帶寬。然而,這在 MI300X 上可能不是問題,因為所有芯片都在運行時,帶寬需求將最高。在這種情況下,每個芯片將消耗約 1.3 TB/s 的帶寬,通過跨芯片鏈路獲取其中的 3/4 不會有問題。
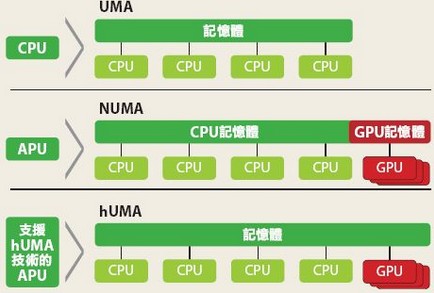
但MI300不只是GPGPU部分,它還有APU部分,在我看來這是這兩款MI300產品中更有趣的一個。AMD 首款 APU Llano 于 2011 年發布,它基于 AMD 的 K10.5 CPU 搭配 Terascale 3 GPU。快進到 2023 年,AMD 在其首款“big iron”APU MI300A 中將 6 個 CDNA3 XCD 與 24 個 Zen 4 核心配對,同時重復使用相同的基礎芯片。這允許 CPU 和 GPU 共享相同的內存地址空間,從而無需通過外部總線復制數據以保持 CPU 和 GPU 彼此一致。
審核編輯:黃飛
?




















 工商網監
工商網監
評論