 電子發燒友App
電子發燒友App


???全球 CPU 商用市場基本被 Intel、AMD 兩家壟斷,國產 CPU 具備廣闊拓展空間。CPU 目前從市場占有率來說,Intel 依靠其強大的 X86 生態體系和領先的制造能力,在通用 CPU 市場占據領先地位。2021 年,Intel 市場份額不低于 80%,AMD 近期追趕勢頭明顯,其他廠商整體市場份額不超過 7%。
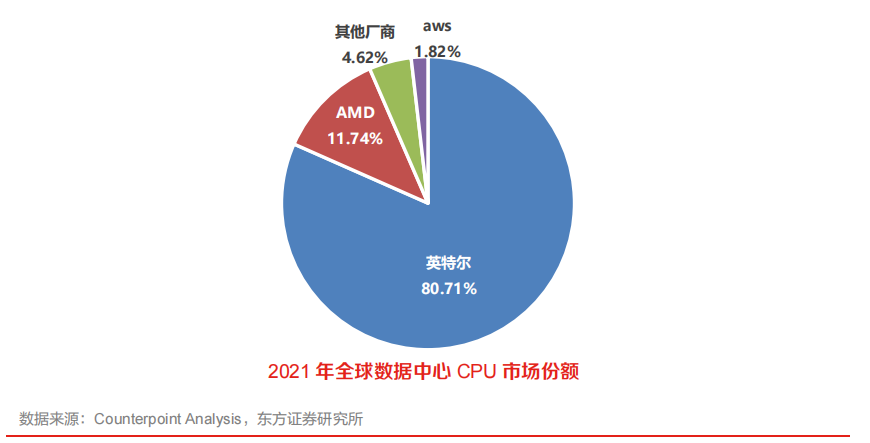
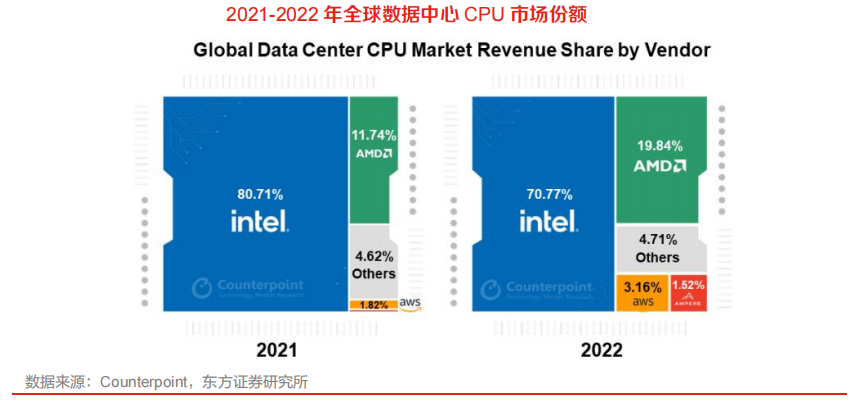
英特爾優勢降低,數據中心領域集中度有所降低。2022 年,數據中心領域 Intel 市場占有率為71%,較 21 年下降 10pcts,AMD 22 年市占率快速提升 8pcts 至 20%,亞馬遜、Ampere 等新興玩家份額快速提升,給總計份額不足 5%的國產廠商發展帶來了借鑒意義。
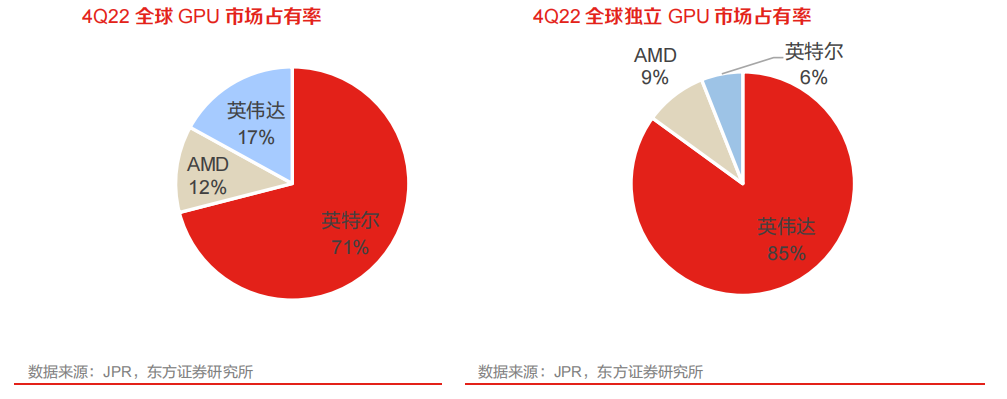
全球 GPU 市場為三足鼎立的寡頭競爭格局,英偉達在獨顯領域一家獨大。在獨立顯卡市場上,長期以來都是 AMD 及 NVIDIA 兩家的二人轉,2022 年 Intel 正式殺入了顯卡市場,目前獨立 GPU市場則主要由 NVIDIA、AMD 和英特爾三家公司占據,2022 年 Q4 全球獨立 GPU 市場占有率分別為 85%、9%和 6%,其中,NVIDIA 在 PC 端獨立 GPU 領域市場占有率優勢明顯。
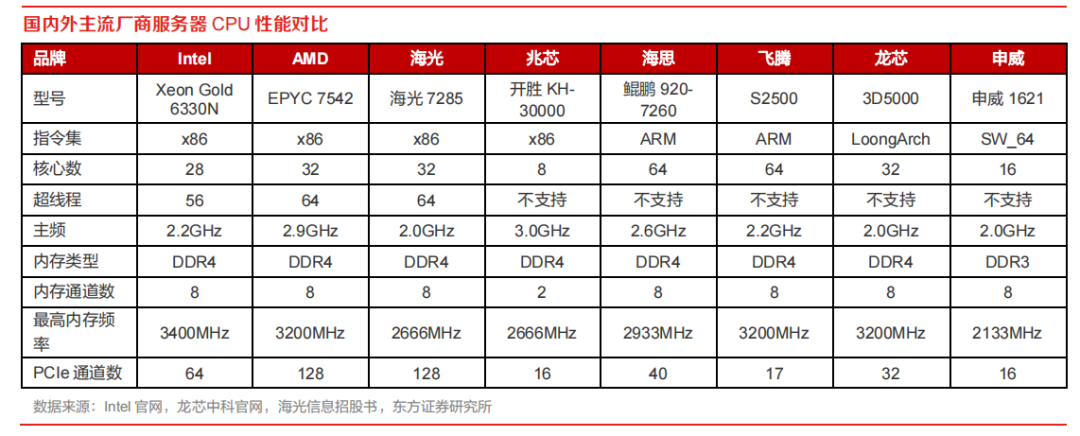
1、多數參數我國CPU具備比肩能力,但性能差距大
影響國內CPU市占率的主要是技術差異,即產品性能。CPU性能的主要影響因素為頻率和IPC,其他影響 CPU 性能的因素還有總線寬度、制程、存儲、內核數、封裝技術等。
(1)主頻,外頻和倍頻和 IPC。主頻是 CPU 的時鐘頻率,即 CPU 的工作頻率,一般來說,一個時鐘周期完成的指令數是固定的,所以主頻越高,CPU單位時間運行的指令數越多。外頻即CPU和周邊傳輸數據的頻率,具體是指 CPU 到芯片組之間的總線速度,CPU 的外頻決定著整塊主板的運行速度。產生的輸出信號頻率是輸入信號頻率的整數倍稱為倍頻,倍頻和外頻相乘就是主頻,當外頻不變時,提高倍頻,CPU主頻也就越高。IPC指 CPU每一個頻率周期里處理的指令數量。
(2)地址總線寬度。地址總線是專門用來傳送地址的,CPU 通過地址總線來選用外部存儲器的存儲地址,總線寬度決定了 CPU 可以訪問的物理地址空間(尋址能力),簡單地說就是 CPU 到底能夠使用多大容量的內存。例如 32 位的地址總線,最多可以直接訪問 4GB 的物理空間。8 位微機的地址總線為 16 位,則其最大可尋址空間為 2^16=64KB。
(3)數據總線寬度。數據總線寬度決定了 CPU 與內存以及輸入、輸出設備之間一次數據傳輸的信息量。
(4)制程和封裝。CPU 的生產需要經過硅提純、切割晶圓、影印、蝕刻、分層、封裝、測試 7個工序,制程工藝的提升或更小的制程對于 CPU 性能的提升影響明顯,主要表現為 CPU 頻率提升以及架構優化兩個方面。一方面,工藝的提升與頻率緊密相連,使得芯片主頻得以提升;另一方面工藝提升帶來晶體管規模的提升,從而支持更加復雜的微架構或核心,帶來架構的提升。
(5)工作電壓。指的是 CPU 正常工作所需的電壓。低電壓能夠解決耗電多和發熱過高的問題,使 CPU 工作時的溫度降低,工作狀態穩定。
(6)高速緩沖存儲器。它是一種速度比內存更快的存儲設備,用于緩解 CPU 和主存儲器之間速度不匹配的矛盾,進而改善整個計算機系統的性能。很多大型、中型、小型以及微型計算機中都采用高速緩存。
(7)除上述性能指標外,CPU 還有其他如接口類型、多媒體指令集、裝封形式、整數單元和浮點單元強弱等性能影響指標。
多數參數我國 CPU 具備比肩能力,IPC性能是最主要差距。目前通過公開信息可以看出,主頻、核心數、內存類型等指標我國 CPU 廠商差異不大,具備一定的比肩能力,但落實到具體性能決定指標 IPC,僅 Intel 和 AMD 會公布 IPC“相比上一代提升了多少”,其他國產 CPU 從 IPC 性能來看大致落后于 Intel、AMD 幾年水平。
2、指令級架構與生態綁定多年,創新面臨知識產權等多重壁壘
指令集是 CPU 所執行的指令的二進制編碼方法,是軟件和硬件的接口規范。日常交流中有時也把指令集稱為架構。CPU 按照指令集可分為 CISC(復雜指令集)和 RISC(精簡指令集)兩大類,CISC 型 CPU 目前主要是 x86 架構,RISC 型 CPU 主要包括 ARM、RISC-V、MIPS、POWER 架構等。
指令集架構與生態綁定多年,創新面臨知識產權、時間等多重壁壘。歷經幾十年的發展,全球形成了 Wintel(Windows+Intel)和 AA(Android+ARM)兩大信息化生態體系,并且都由美國主導,在生態和知識產權上都形成了自己的“領地”。中國之前沒有指令集,重新搭建或者在現有的開源指令集基礎上修改,會面臨知識產權問題以及前期需要大量的試錯優化過程。且新的指令集需要新的生態來適配,所需要的操作系統、基礎軟件和各種應用軟件都需要重新適配,這也是目前新指令集發展的一個難點。


(1)x86 架構:主導桌面/服務器 CPU 市場
基于 CISC(復雜指令集)的 x86 架構是一種為了便于編程和提高存儲器訪問效率的芯片設計體系,包括兩大主要特點:一是使用微代碼,指令集可以直接在微代碼存儲器里執行,新設計的處理器,只需增加較少的晶體管電路就可以執行同樣的指令集,也可以很快地編寫新的指令集程式;二是擁有龐大的指令集,x86 擁有包括雙運算元格式、寄存器到寄存器、寄存器到存儲器以及存儲器到寄存器的多種指令類型。
x86 架構主要參與者包括 Intel、AMD、海光、兆芯等。
(2)ARM 架構:崛起移動市場和 MCU 市場
ARM 架構過去稱作進階精簡指令集機器,是一個 32 位精簡指令集處理器架構,其廣泛地使用在許多嵌入式系統設計,近年來也因其低功耗多核等特點廣泛應用在數據中心服務器市場。早期ARM 指令集架構的主要特點:一是體積小、低功耗、低成本、高性能;二是大量使用寄存器,且大多數數據操作都在寄存器中完成,指令執行速度更快;三是尋址方式靈活簡單,執行效率高;四是指令長度固定,可通過多流水線方式提高處理效率。
ARM 架構的 CPU 參與者包括飛騰、鯤鵬等,還有諸多 MCU 廠商用 ARM 架構設計相關產品,包括意法半導體、兆易創新、普冉股份、恒爍股份等。
(3)RISC-V 架構:物聯網時代的新選擇
RISC-V是加州大學伯克利分校設計并發布的一種開源指令集架構,其目標是成為指令集架構領域的 Linux, 主要應用 于物聯 網(IoT) 領域, 但可擴展 至高性能計 算領域 。RISC-V 采用BSDLicense 發布,由于允許衍生設計和開發閉源,吸引了一大批公司的關注,目前已有不少公司開發基于 RISC-V 的 IP 核,如 Si-Five、臺灣晶心、阿里平頭哥等已可提供基于 RISC-V 的處理器 IP 核,部分企業如兆易創新、北京君正等已開發出基于 RISC-V 的 MCU 芯片等。但整體上,由于 RISC-V 產業生態還比較薄弱,未來的發展仍有較長一段路要走。
RISC-V 架構的參與者包括阿里平頭哥,MCU 廠商包括國芯科技、賽昉科技等。
(4)MIPS 架構:在學術界影響廣泛
MIPS 是高效精簡指令集計算機體系結構中的一種,MIPS 的優勢主要有三點:一是發展歷史早,MIPS 在 1990 年代已經廣泛使用在服務器、工作站設備上。二是在學術界影響廣泛,計算機體系結構教材都是以 MIPS 為實際例子。三是 MIPS 在架構授權方面更為開放,授權門檻遠低于 x86、ARM,在2019年曾經有開放授權的實際動作,并且 MIPS允許授權商自行更改設計、擴展指令,允許二次授權。
(5)POWER 架構:在部分汽車控制中有所應用
POWER 架構是由 IBM 設計的一種 RISC 處理器架構,POWER 在大型機領域獨具優勢。POWER3 是全球首款 64 位架構處理器,開始應用銅互聯和 SOI(絕緣體上硅)技術。直至POWER9 依然追求最高性能,不僅具備亂序執行、智能線程等技術,還實現了 SMP(對稱多處理技術)的硬件一致性處理。POWER 架構 CPU 價格高昂,主要應用于高端服務器領域,市場份額逐漸減少。
POWER 架構目前恩智浦、飛思卡爾和國芯科技的部分產品中有采用。
CPU 專用 EDA 國產替代難度大。我國的 CPU 專用 EDA 工具例如數字仿真、邏輯綜合、建模、布局布線等水平比較差,長期依賴國外產品,尚無法完成完整集成電路的功能設計、綜合驗證和物理設計等全流程的軟件工具集群,完全替換應用的難度大。
3、AI芯片的關鍵特征包含數據特點、計算范式、精度、重構能力等
1)新型的計算范式:控制流程簡化、計算量增大
AI 計算包括傳統計算和新的計算特質,處理的內容往往是非結構化數據(視頻、圖片等)。處理的過程通常需要很大的計算量,基本的計算主要是線性代數運算(如張量處理),而控制流程則相對簡單。
2)訓練和推斷:需要高效的數據處理能力
AI 系統通常涉及訓練(Training)和推斷(Inference)過程。簡單來說,訓練過程是指在已有數據中學習,獲得某些能力的過程;而推斷過程則是指對新的數據,使用這些能力完成特定任務(比如分類、識別等)。滿足高效能機器學習的數據處理要求是 AI 芯片需要考慮的最重要因素。
3)數據精度:低精度成為趨勢
低精度設計是 AI 芯片的一個趨勢,在針對推斷的芯片中更加明顯。對一些應用來說,降低精度的設計不僅加速了機器學習算法的推斷(也可能是訓練),甚至可能更符合神經形態計算的特征。
4、AI芯片設計趨勢
1)云端訓練和推斷:大存儲、高性能、可伸縮
存儲的需求(容量和訪問速度)越來越高,處理能力推向每秒千萬億次(Peta FLOPS),并支持靈活伸縮和部署。隨著 AI 應用的爆發,對推斷計算的需求會越來越多,一個訓練好的算法會不斷復用。推斷和訓練相比有其特殊性,更強調吞吐率、能效和實時性,未來在云端很可能會有專門針對推斷的 ASIC 芯片(如 Google 的第一代 TPU),提供更好的能耗效率并實現更低的延時。
2)邊緣設備:也需要具備一定的學習、本地訓練能力
相對云端應用,邊緣設備的應用需求和場景約束要復雜很多,針對不同的情況可能需要專門的架構設計。拋開需求的復雜性,目前的邊緣設備主要是執行“推斷”。在這個目標下,AI 芯片最重要的就是提高“推斷”效率。目前,衡量 AI 芯片實現效率的一個重要指標是能耗效率——TOPs/W,這也成為很多技術創新競爭的焦點。未來,越來越多的邊緣設備將需要具備一定的“學習”能力,能夠根據收集到的新數據在本地訓練、優化和更新模型。這也會對邊緣設備以及整個 AI 實現系統提出一些新的要求。最后,在邊緣設備中的 AI 芯片往往是 SoC 形式的產品,AI部分只是實現功能的一個環節,而最終要通過完整的芯片功能來體現硬件的效率。這種情況下,需要從整個系統的角度考慮架構的優化。因此,終端設備 AI 芯片往往呈現為一個異構系統,專門的 AI 加速器和 CPU,GPU,ISP,DSP 等其它部件協同工作以達到最佳的效率。
3)軟件定義芯片:能夠實時動態改變功能,滿足軟件不斷變化的計算需求
在 AI 計算中,芯片是承載計算功能的基礎部件,軟件是實現 AI 的核心。這里的軟件即是為了實現不同目標的 AI 任務,所需要的 AI 算法。對于復雜的 AI 任務,甚至需要將多種不同類型的 AI 算法組合在一起。即使是同一類型的 AI 算法,也會因為具體任務的計算精度、性能和能效等需求不同,具有不同計算參數。因此,AI 芯片必須具備一個重要特性:能夠實時動態改變功能,滿足軟件不斷變化的計算需求,即“軟件定義芯片”。
審核編輯:黃飛
?




















 工商網監
工商網監
評論