 電子發(fā)燒友App
電子發(fā)燒友App


1 引言
機器人聽覺系統(tǒng)主要是對人的聲音進行語音識別并做出判斷,然后輸出相應(yīng)的動作指令控制頭部和手臂的動作,傳統(tǒng)的機器人聽覺系統(tǒng)一般是以PC機為平臺對機器人進行控制,其特點是用一臺計算機作為機器人的信息處理核心通過接口電路對機器人進行控制,雖然處理能力比較強大,語音庫比較完備,系統(tǒng)更新以及功能拓展比較容易,但是比較笨重,不利于機器人的小型化和復(fù)雜條件下進行工作,此外功耗大、成本高。本次設(shè)計采用了性價比較高的數(shù)字信號處理芯片TMS320VC5509作為語音識別處理器,具有較快的處理速度,使機器人在脫機狀態(tài)下,獨立完成復(fù)雜的語音信號處理和動作指令控制,FPGA系統(tǒng)的開發(fā)降低了時序控制電路和邏輯電路在pcb板所占的面積,使機器人的“大腦”的語音處理部分微型化、低功耗。一個體積小、低功耗、高速度能完成特定范圍語音識別和動作指令的機器人系統(tǒng)的研制具有很大的實際意義。
2 系統(tǒng)硬件總體設(shè)計
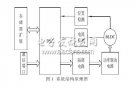
系統(tǒng)的硬件功能是實現(xiàn)語音指令的采集和步進電機的驅(qū)動控制,為系統(tǒng)軟件提供開發(fā)和調(diào)試平臺。如圖1所示。
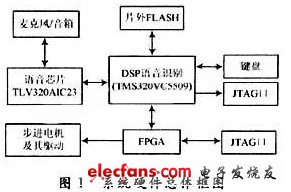
系統(tǒng)硬件分為語音信號的采集和播放,基于DSP的語音識別,F(xiàn)PGA動作指令控制、步進電機及其驅(qū)動、DSP外接閃存芯片,JTAG口仿真調(diào)試和鍵盤控制幾個部分。工作流程是麥克風(fēng)將人的語音信號轉(zhuǎn)化為模擬信號,在經(jīng)過音頻芯片TLV320AIC23量化轉(zhuǎn)化成數(shù)字信號輸入DSP.DSP完成識別后,輸出動作指令。
FPGA根據(jù)DSP輸入的動作指令產(chǎn)生正確的正反轉(zhuǎn)信號和準(zhǔn)確的脈沖給步進電機驅(qū)動芯片,驅(qū)動芯片提供步進電機的驅(qū)動信號,控制步進電機的轉(zhuǎn)動。片外FLASH用于存儲系統(tǒng)程序和語音庫并完成系統(tǒng)的上電加載。JTAG口用于與PC機進行聯(lián)機在線仿真,鍵盤則用于參數(shù)調(diào)整和功能的切換。
3 語音識別系統(tǒng)設(shè)計
3.1 語音信號的特點
語音信號的頻率成分主要分布在300~3400Hz之間,根據(jù)采樣定理選擇信號的采樣率為8 kHz。語音信號的一個特點在于他的“短時性”,有時在一個短時段呈現(xiàn)隨機噪聲的特性,而另一段表現(xiàn)周期信號的特性,或二者兼而有之。語音信號的特征是隨時間變化的,只有一段時間內(nèi),信號才表現(xiàn)穩(wěn)定一致的特征,一般來說短時段可取5~50 ms,因此語音信號的處理要建立在其“短時性”上,系統(tǒng)將語音信號幀長設(shè)為20 ms,幀移設(shè)為10 ms,則每幀數(shù)據(jù)為160×16 b。
3.2 語音信號的采集和播放
語音采集和播放芯片采用的是TI公司生產(chǎn)的TLV320AIC23B,TLV320AIC23B的模數(shù)轉(zhuǎn)換(ADC)和數(shù)模轉(zhuǎn)換(DAC)部件高度集成在芯片內(nèi)部,芯片采用8 k采樣率,單聲道模擬信號輸入,雙聲道輸出。TLV320AIC23具有可編程特性,DSP可通過控制接口來編輯該器件的控制寄存器,而且能夠編譯SPI,I2C兩種規(guī)格的接口,TLV320AIC23B與DSP5509的電路連接如圖2所示。
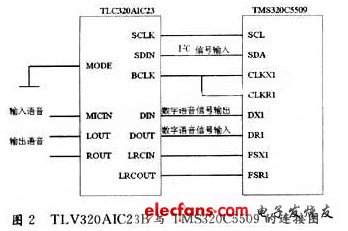
DSP采用I2C口對TLV320AIC23的寄存器進行設(shè)置。當(dāng)MODE=O時,為I2C規(guī)格的接口,DSP采用主發(fā)送模式,通過I2C口對地址為0000000~0001111的11個寄存器進行初始化。I2C模式下,數(shù)據(jù)是分為3個8 b寫入的。而TLV320AIC23有7位地址和9位數(shù)據(jù),也就是說,需要把數(shù)據(jù)項上面的最高位補充到第二個8 B中的最后一位。
MCBSP串口通過6個引腳CLKX,CLKR,F(xiàn)SX,F(xiàn)SR,DR和CX與TLV320AIC23相連。數(shù)據(jù)經(jīng)MCBSP串口與外設(shè)的通信通過DR和DX引腳傳輸,控制同步信號則由CLKX,CLKR,F(xiàn)SX,F(xiàn)SR四個引腳實現(xiàn)。將MCBSP串口設(shè)置為DSP Mode模式,然后使串口的接收器和發(fā)送器同步,并且由TLV320AIC23的幀同步信號LRCIN,LRCOUT啟動串口傳輸,同時將發(fā)送接收的數(shù)據(jù)字長設(shè)定為32 b(左聲道16 b,右聲道16 b)單幀模式。
3.3 語音識別程序模塊的設(shè)計
為了實現(xiàn)機器人對非特定人語音指令的識別,系統(tǒng)采用非特定人的孤立詞識別系統(tǒng)。非特定人的語音識別是指語音模型由不同年齡、不同性別、不同口音的人進行訓(xùn)練,在識別時不需要訓(xùn)練就可以識別說話人的語音[2]。系統(tǒng)分為預(yù)加重和加窗,短點檢測,特征提取,與語音庫的模式匹配和訓(xùn)練幾個部分。
3.3.1 語音信號的預(yù)加重和加窗
預(yù)加重處理主要是去除聲門激勵和口鼻輻射的影響,預(yù)加重數(shù)字濾波H(Z)=1一KZ-1,其中是為預(yù)加重系數(shù),接近1,本系統(tǒng)中k取0.95。對語音序列X(n)進行預(yù)加重,得到預(yù)加重后的語音序列x(n):x(n)=X(n)一kX(n一1) (1)
系統(tǒng)采用一個有限長度的漢明窗在語音序列上進行滑動,用以截取幀長為20 ms,幀移設(shè)為10 ms的語音信號,采用漢明窗可以有效減少信號特征的丟失。
3.3.2 端點檢測
端點檢測在詞與詞之間有足夠時間間隙的情況下檢測出詞的首末點,一般采用檢測短時能量分布,方程為:

其中,x(n)為漢明窗截取語音序列,序列長度為160,所以N取160,為對于無音信號E(n)很小,而對于有音信號E(n)會迅速增大為某一數(shù)值,由此可以區(qū)分詞的起始點和結(jié)束點。
3.3.3特征向量提取
特征向量是提取語音信號中的有效信息,用于進一步的分析處理。目前常用的特征參數(shù)包括線性預(yù)測倒譜系數(shù)LPCC、美爾倒譜系數(shù)MFCC等。語音信號特征向量采用Mel頻率倒譜系數(shù)MFCC(Mel Frequency Cepstrum Coeficient的提取,MFCC參數(shù)是基于人的聽覺特性的,他利用人聽覺的臨界帶效應(yīng)[3],采用MEL倒譜分析技術(shù)對語音信號處理得到MEL倒譜系數(shù)矢量序列,用MEL倒譜系數(shù)表示輸入語音的頻譜。在語音頻譜范圍內(nèi)設(shè)置若干個具有三角形或正弦形濾波特性的帶通濾波器,然后將語音能量譜通過該濾波器組,求各個濾波器輸出,對其取對數(shù),并做離散余弦變換(DCT),即可得到MFCC系數(shù)。MFCC系數(shù)的變換式可簡化為:

其中,i為三角濾波器的個數(shù),本系統(tǒng)選P為16,F(xiàn)(k)為各個濾波器的輸出數(shù)據(jù),M為數(shù)據(jù)長度。
3.3.4 語音信號的模式匹配和訓(xùn)練
模型訓(xùn)練即將特征向量進行訓(xùn)練建立模板,模式匹配即將當(dāng)前特征向量與語音庫中的模板進行匹配得出結(jié)果。語音庫的模式匹配和訓(xùn)練采用隱馬爾可夫模型HMM(Hidden Markov Models),他是一種統(tǒng)計隨機過程統(tǒng)計特性的概率模型一個雙重隨機過程,因為隱馬爾可夫模型能夠很好地描述語音信號的非平穩(wěn)性和可變性,因此得到廣泛的使用[4]。
HMM的基本算法有3種:Viterbi算法,前向一后向算法,Baum-Welch算法。本次設(shè)計使用Viterbi算法進行狀態(tài)判別,將采集語音的特征向量與語音庫的模型進行模式匹配。Baum-Welch算法用來解決語音信號的訓(xùn)練,由于模型的觀測特征是幀間獨立的,從而可以使用Baum-Welch算法進行HMM模型的訓(xùn)練。
3.4 語音識別程序的DSP開發(fā)
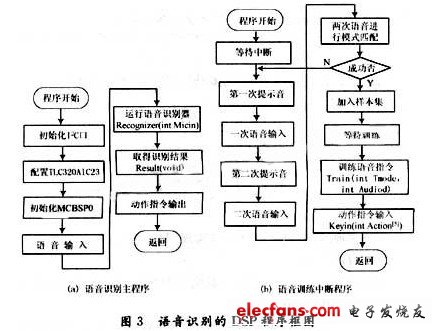
DSP的開發(fā)環(huán)境為CCS3.1及。DSP/BIOS,將語音識別和訓(xùn)練程序分別做成模塊,定義為不同的函數(shù),在程序中調(diào)用。定義語音識別器函數(shù)為int Recognizer(int Micin),識別結(jié)果輸出函數(shù)為int Result(void),語音訓(xùn)練器函數(shù)為int Train(int Tmode,int Audiod),動作指令輸入函數(shù)為int Keyin(int Action[5])。
語音識別器的作用是將當(dāng)前語音輸入變換成語音特征向量,并對語音庫的模板進行匹配并輸出結(jié)果,語音應(yīng)答輸出函數(shù)將獲取的語音識別結(jié)果對應(yīng)的語音應(yīng)答輸出,語音訓(xùn)練是將多個不同年齡、不同性別、不同口音的人語音指令輸入轉(zhuǎn)化為訓(xùn)練庫的模板。為防止樣本錯誤,每個人的語音指令需要訓(xùn)練2次,對于2次輸入用用歐氏距離去進行模式匹配,若2次輸入相似度達到95%,則加入樣本集。語音應(yīng)答輸入函數(shù)是為每個語音庫中模板輸入對立的語音輸出,以達到語言應(yīng)答目的。系統(tǒng)工作狀態(tài)為執(zhí)行語言識別子程序,訓(xùn)練時執(zhí)行外部中斷,執(zhí)行訓(xùn)練函數(shù),取得數(shù)據(jù)庫模板,訓(xùn)練完畢返回。程序框圖如圖3所示。
4 機器人的動作控制系統(tǒng)設(shè)計
4.1 FPGA邏輯設(shè)計
系統(tǒng)通過語音控制機器人頭部動作,頭部運動分為上下和左右運動2個自由度,需要2個步進電機控制,DSF完成語音識別以后,輸出相應(yīng)的動作指令,動作執(zhí)行結(jié)束后,DSP發(fā)出歸零指令,頭部回到初試狀態(tài)。FPGA的作用是提供DSP接口邏輯,設(shè)置存儲DSP指令的RAM塊,同時產(chǎn)生步進電機驅(qū)動脈沖控制步進電機轉(zhuǎn)動方向和角度。
FPGA器件為動作指令控制單元,設(shè)計采用FLEXlOKE芯片,接收DSP數(shù)據(jù)后并行控制2路步進電機。FPGA內(nèi)部結(jié)構(gòu)邏輯如圖4所示,F(xiàn)PGA內(nèi)部設(shè)置2個元件為電機脈沖發(fā)生器,控制電機的工作脈沖以及正反轉(zhuǎn)。AO~A7為DSP數(shù)據(jù)輸入端口,WR為數(shù)據(jù)寫端口,P1,P2為2個步進電機驅(qū)動芯片脈沖輸入口,L1,L2為電機正反轉(zhuǎn)控制口,ENABLE為使能信號。
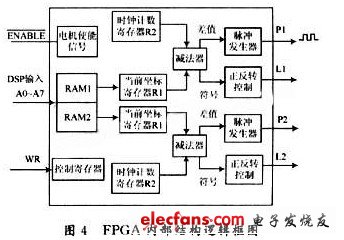
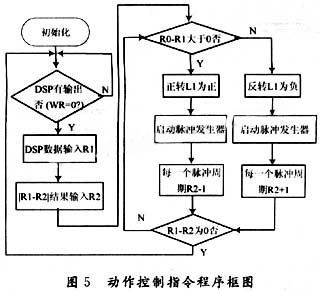
RAM1和RAM2分別為2個步進電機的指令寄存器,電機脈沖發(fā)生器發(fā)出與RAM中相應(yīng)數(shù)量的方波脈沖。DSP通過DO~D8數(shù)據(jù)端輸出8位指令,其中。D8為RAM選擇,為1時選擇RAM1,為0時選擇RAM0,DO~D7為輸出電機角度,電極上下和左右旋轉(zhuǎn)角度為120°,精度為1°,初始值都為60°,DO~D7的范圍為00000000~11111000,初始值為00111100。FPGA作為步進脈沖發(fā)生器,通過時鐘周期配置控制電機轉(zhuǎn)速,與初始值對應(yīng)坐標(biāo)決定正反轉(zhuǎn)。系統(tǒng)動作指令程序如圖5所示。
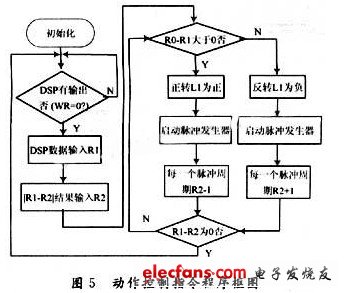
其中R1為DSP指令寄存器,R2為當(dāng)前坐標(biāo)寄存器,通過DSP的輸出坐標(biāo)與FPGA的當(dāng)前坐標(biāo)進行差值運算來確定步進電機的旋轉(zhuǎn)方向和旋轉(zhuǎn)角度,優(yōu)點是可以根據(jù)新的輸入指令的變化,結(jié)束當(dāng)前動作以運行新的指令,指令執(zhí)行完畢后,系統(tǒng)清零,步進電機回到初始狀態(tài)。
4.2 FPGA邏輯仿真
FPGA以MAX-PLUSⅡ開發(fā)平臺,用語言為VHDL語言對上述邏輯功能進行設(shè)計,并通過JTAG接口進行了調(diào)試,F(xiàn)LEXl0KE芯片能夠根據(jù)DSP輸出指令輸出正確的正反轉(zhuǎn)信號和脈沖波形。
4.3 步進電機驅(qū)動設(shè)計
FPGA通過P1,L1,P2,L2輸出控制控制步進電機驅(qū)動芯片。步進電機驅(qū)動采用的是東芝公司生產(chǎn)的單片正弦細(xì)分二相步進電機驅(qū)動專用芯片TA8435H,F(xiàn)PGA與TA8435H電路連接如圖6。
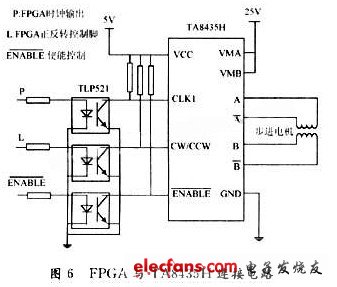
由于FLEX1OKE和TMS320VC5509工作電壓為3.3 V,而TA8435H為5 V和25 V,所以管腳連接使用光電耦合器件TLP521,使兩邊電壓隔離。CLK1為時鐘輸入腳,CW/CCW為正反轉(zhuǎn)控制腳,A,A,B,B為二相步進電機輸入。
5 結(jié) 語
系統(tǒng)充分利用了DSP的高處理速度和可擴展的片外存儲空間,具有高速、實時、識別率高的特點并支持大的語音庫,F(xiàn)PGA的使用使系統(tǒng)電路獲得簡化,一片F(xiàn)LEXl0KE芯片可以完成2個步進電機的時序控制。雖然在處理速度和語音庫的存儲容量上與PC機系統(tǒng)具有一定的差距,但在機器人的微型化、低功耗和特定功能實現(xiàn)上,以DSP和FPGA為核心的嵌入式系統(tǒng)無疑具有廣闊的前景。




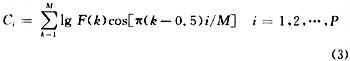





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論