 電子發燒友App
電子發燒友App


賽靈思 All Programmable FPGA 和 SoC 針對一系列計算密集型工作負載提供最高效、最具成本效益、時延最低、最具設計靈活性并且滿足未來需求的計算平臺。
為了滿足不斷攀升的數據處理需求,未來系統需要在計算能力上大幅改進。傳統解決方案(例如 x86 處理器)再也無法以高效、低成本的方式提供所需的計算帶寬,系統設計人員必須尋找新的計算平臺。FPGA 和 GPU 越來越多地被系統設計人員看好,認為它們能夠滿足未來需求的計算平臺。為新時代提供必要的計算效率和靈活性,本文將對 GPU 以及賽靈思 FPGA和 SoC 器件進行分析。
簡介
未來系統(例如云數據中心 [DC] 和自動駕駛汽車)需要在計算能力上大幅改進,以支持不斷增多的工作負載以及不斷演進的底層算法 [ 參考資料 1]。例如,大數據分析、機器學習、視覺處理、基因組以及高級駕駛員輔助系統 (ADAS) 傳感器融合工作負載都在促使計算性能能以低成本、高效的方式實現提升,并且超出現有系統(例如 x86 系統)的極限。
系統架構師正在尋找能滿足要求的新計算平臺。該平臺需要足夠靈活,以便集成到現有的架構中 , 并支持各種工作負載及其不斷演進的算法。此外,這些系統很多還必須提供確定性的低時延性能,以支持實時系統(例如自動駕駛汽車)所需的快速響應時間。
圖形處理單元 (GPU) 廠商非常積極地將 GPU 定位成新時代計算平臺的最佳之選,主要依據其在機器學習訓練的高性能計算 (HPC) 領域取得的成功。在此過程中,GPU 廠商針對機器學習推斷工作負載修改了他們的架構。
然而,GPU 廠商還是忽視了基本的 GPU 架構的局限性。這些局限性會嚴重影響 GPU 以高效、低成本方式提供必要的系統級計算性能的能力。例如,在云端 DC 系統中,對工作負載的需求在一天內會發生很大變化。此外,這些工作負載的底層算法也會發生快節奏變化。GPU 架構的局限性會阻止很多今天的工作負載和明天形成的工作負載映射到 GPU,導致硬件閑置或低效。本白皮書的“GPU 架構的局限性”部分對這些局限性進行了更詳細介紹。
相反,賽靈思 FPGA 和 SoC 具有眾多關鍵屬性,使它們非常適合解決未來系統要求所提出的種種挑戰。
這些獨特屬性包括 :
? 針對所有數據類型提供極高的計算能力和效率
? 具備極高靈活性,能夠針對多種工作負載將計算和效率優勢最大化
? 具備 I/O 靈活性,能方便地集成到系統中并實現更高效率
? 具備大容量片上存儲器高速緩存,可提高效率并實現最低時延
本白皮書的“賽靈思 FPGA 和 SoC 的獨特優勢”章節介紹了賽靈思架構的優勢,并與 GPU 架構及其局限性進行對比。
GPU 起源和目標工作負載
GPU 的起源要追溯到 PC 時代,英偉達 (NVidia) 公司聲稱在 1999 年推出世界首款 GPU,但有很多其他顯卡要先于該公司的出品 [ 參考資料 2]。GPU 是一款全新設計的產品,用來分擔 / 加速圖形處理任務,例如替 CPU 進行像素陣列的陰影和轉換處理,其架構非常適合高并行吞吐量處理 [ 參考資料 3]。本質上,GPU 的主要作用是為視覺顯示器 (VDU) 渲染高質量圖像。
多年來,少量非圖形的大規模并行和存儲器相關工作負載是在 GPU(而非 CPU)上實現并且受益良多,例如需要大規模矩陣計算的醫療成像應用。GPU 廠商意識到他們可以將 GPU 的市場延伸到非圖形應用領域,并導致 GPU 的非圖形編程語言(諸如 OpenCL)應運而生。這些編程語言實際上是將 GPU 轉化成了通用 GPU (GPGPU)。
機器學習
最近,能夠良好映射到 GPU 實現方案的工作負載之一就是機器學習訓練。通過充分運用 GPU,顯著縮短了深度神經網絡的訓練時間。
GPU 廠商試圖利用機器學習訓練方面的成功來助推其在機器學習推斷上的發展(部署經過訓練的神經網絡)。隨著機器學習算法和所需數據精度的發展演進,GPU 廠商一直在調整他們的架構以保持自身地位優勢。例如,英偉達在他們的 Tesla P4 產品中提供 INT8 支持。然而,即使是更低的精度,例如二進制和三進制,今天也正在被很多用戶探索 [ 參考資料 4]。要利用機器學習及其它領域的進步,GPU 用戶必須等待新硬件推出之后購買新硬件。正如本白皮書后面所述,賽靈思 FPGA 和 SoC 的用戶則無需等待或購買新硬件,因為這類產品本身就具有高度的靈活性。
GPU 廠商想使自身成為這個新計算時代的首選計算平臺,機器學習是他們的基礎。但要弄清楚 GPU 是否適合未來系統,還要做更全面的系統級分析,需要考慮 GPU 架構的很多局限性以及系統要求如何隨時間發展演進。
GPU 架構的局限性
本部分將深入研究典型的 GPU 架構,以揭示它的局限性以及如何將它們應用于各種算法和工作負載。
SIMT ALU 陣列
圖 1 給出了典型的 GPU 方框圖。通用 GPU 計算功能的核心是大型的算數邏輯單元 (ALU) 或內核陣列。這些 ALU 通常被認為是單指令多線程 (SIMT),類似于單指令多數據 (SIMD)。
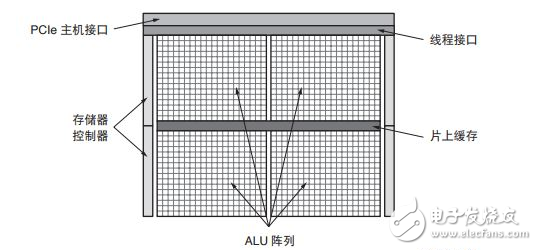
?
圖 1 :GPU 方框圖
基本原理是將工作負載分成數千個并行的線程。需要大量 GPU 線程來防止 ALU 閑置。然后,對這些線程進行調度,以使 ALU 組并行執行同一(單個)指令。利用 SIMT,GPU 廠商能實現相對 CPU 占位面積更小和能效更高的方案,因為內核的很多資源都可與相同組中的其他內核共享。
然而,顯然只是特定的工作負載(或部分工作負載)能被高效映射到這種大規模并行架構中 [ 參考資料 5]。如果構成工作負載的線程不具有足夠的共性或并行性(例如連續工作負載或適度并行工作負載),則ALU 會閑置,導致計算效率降低。此外,構成工作負載的線程預期要最大化 ALU 利用率,從而產生額外的時延。即使有英偉達的 Volta 架構中的獨立線程調度這樣的功能,底層架構也保持 SIMT,也需要大規模并行工作負載。
對于連續、適度并行或稀疏工作負載,GPU 提供的計算功能和效率甚至低于 CPU [ 參考資料 6]。例如用 GPU 實現稀疏矩陣計算 ;如果非零元素數量較少,則從性能和效率角度看 GPU 低于或等同于 CPU[ 參考資料 7][ 參考資料 8]。
有趣的是,很多研究人員正在研究稀疏卷積神經網絡,以利用很多卷積神經網絡中的大規模冗余[ 參考資料 9]。這種趨勢顯然在機器學習推斷領域向 GPU 提出了挑戰。
稀疏矩陣計算也是大數據分析中的關鍵環節。[ 參考資料 10]
包含大量并行計算任務的大多數工作負載也包含一些連續或適度并行元素,意味著需要 GPU-CPU 混合系統來滿足系統性能要求 [ 參考資料 11]。顯然,高端 CPU 需求會影響平臺的效率和成本效益,CPU 與GPU 之間的通信也會給系統增加潛在瓶頸。
SIMT/GPU 架構的另一個局限性是 ALU 的功能取決于它的固定指令集和所支持的數據類型。
離散數據類型精度支持
系統設計人員正在探索簡化數據類型精度,以此實現計算性能的跳躍式提升,而且不會使精度明顯降低[ 參考資料 12][ 參考資料 13][ 參考資料 14]。
機器學習推斷在降低精度方面一馬當先,首先是 FP16,然后是 INT16 和 INT8。研究人員正在探索進一步降低精度,甚至降到二進制 [ 參考資料 4][ 參考資料 15]。
GPU ALU 通常原生支持單精度浮點類型 (FP32),有些情況支持雙精度浮點 (FP64)。FP32 是圖形工作負載的首選精度,而 FP64 經常用于一些 HPC 用途。低于 FP32 的精度通常無法在 GPU 中得到有效支持。因此采用標準 GPU 上的更低精度,除了能減少所需存儲器帶寬以外,作用甚微。
GPU 通常提供一些二進制運算功能,但通常只能每 ALU 進行 32 位寬運算。32 位二進制運算存在很大的復雜性和面積需求。在二值化神經網絡中,算法需要 XNOR 運算,緊接著進行種群 (population) 計數。NVidia GPU 只能每四個周期進行一次種群計數運算,這會極大影響二進制計算 [ 參考資料 18]。如圖 2 所示,為了與機器學習推斷空間的發展保持同步,GPU 廠商一直進行必要的芯片修改,以支持有限的幾種降精度數據類型,例如 FP16 和 INT8。例如,Tesla P4 和 P40 卡上的 NVidia GPU 支持 INT8,每 ALU/Cuda 內核提供 4 個 INT8 運算。
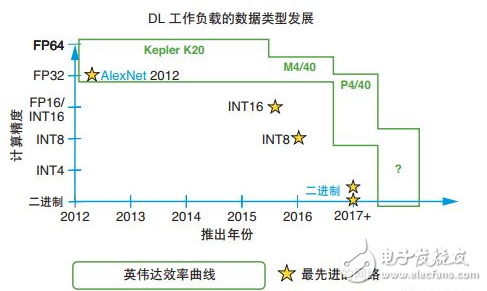
?
圖 2 :英偉達降精度支持
然而,英偉達面向 Tesla P40 上的 GoogLeNet v1 Inference 發布的機器學習推斷基準結果表明,INT8 方案與 FP32 方案相比效率只提升 3 倍,說明要在 GPU 架構中強行降低精度并取得高效結果存在較大難度[ 參考資料 16]。
隨著機器學習和其他工作負載轉向更低精度和定制精度,GPU 廠商需要向市場推出更多新產品,他們的現有用戶也需要升級平臺才能受益于這種改進。










 工商網監
工商網監
評論