 電子發燒友App
電子發燒友App


?
? ? ? ?通過用于重構高級算法描述的簡單流程,就可以利用高層次綜合功能生成更高效的處理流水線。
如果您正在努力開發計算內核,而且采用常規內存訪問模式,并且循環迭代間的并行性比較容易提取,這時,Vivado設計套件高層次綜合(HLS)工具是創建高性能加速器的極好資源。通過向C語言高級算法描述中添加一些編譯指示,就可以在賽靈思FPGA上快速實現高吞吐量的處理引擎。結合使用軟件管理的DMA機制,就可以比通用處理器提速數十倍。
然而,實際應用中經常會遇到難以處理的復雜內存訪問問題,尤其是當突破科學計算和信號處理算法領域時更是如此。我們設計出了一種簡單方法,可供您在此類情況下生成高效的處理流水線。在詳細介紹之前,我們首先了解一下Vivado HLS的工作原理,更重要的是了解它何時不起作用。
HLS工具如何起作用?
高層次綜合功能試圖獲取由高級語言描述的控制數據流圖 (CDFG)中的并行性。對計算操作和內存訪問進行分配和調度時,應根據它們之間的依賴約束和目標平臺的資源約束來執行。電路中特定操作的激活與某個時鐘周期相關,同時,沿數據路徑綜合的中央控制器協調整個CDFG的執行。
單純在內核上應用HLS可以建立一條具有眾多指令級并行性的數據路徑。但是當它被激活時,就需要頻繁停下來等待數據送入。
由于調度工作是在靜態下完成的, 因此加速器運行時間的行為相當簡單。所生成電路的不同部分相互之間以相同步調運行;并不需要動態的相關性檢查機制,例如高性能CPU上出現的那種。例如,在圖1(a) 所示的函數中,循環索引添加和curInd的加載可以并行處理。此外,下次迭代可以在當前迭代完成前開始。
同時,由于浮點乘法通常使用上次迭代的乘法結果
因此可以開始新迭代的最短間隔受到浮點乘法器時延的限制。該函數的執行調度如圖2(a)所示。
該方案何時達不到理想效果?
這種方案的問題在于整個數據流圖嚴格按調度運行。片外通信產生的拖延會傳播到整個處理引擎,從而導致性能大幅下降。當內存訪問模式已知,數據能在需要使用之前移動到芯片上,或者如果數據集足夠小,則可完全高速緩存在FPGA上,這類情況下不會有問題。然而,就很多有趣的算法而言,數據訪問取決于計算結果,而且內存占用決定了需要使用片外RAM。現在,在內核上單純應用HLS可建立一條具有眾多指令級并行性的數據路徑。但是,當它被激活時,就需要頻繁停下來等待數據送入。
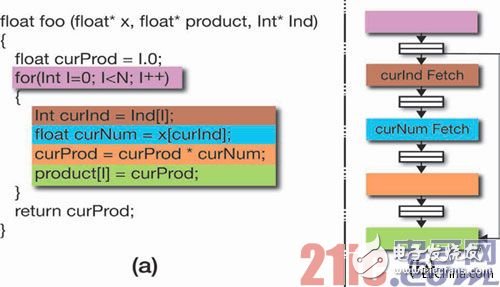
圖1 – 設計實例:(a) 包含不規則內存訪問模式的函數;(b) 重構得到的流水線結構
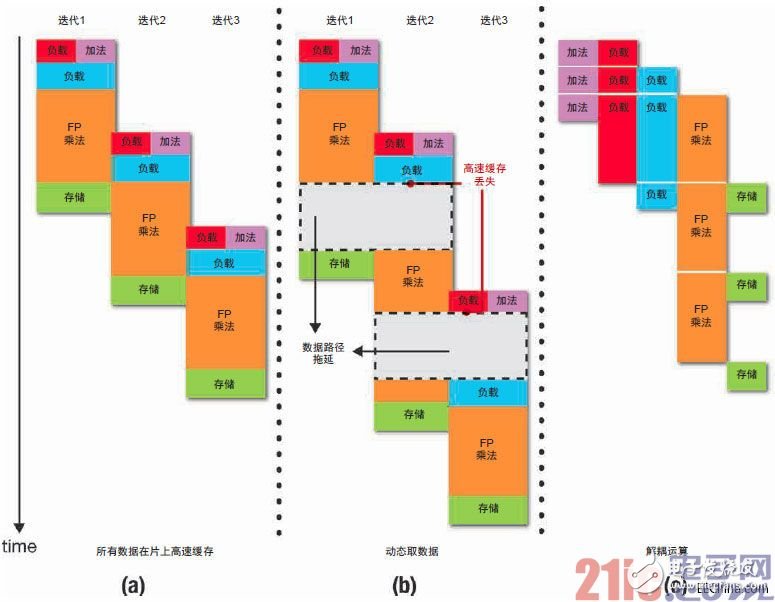
圖2 – 不同情形下的執行調度:(a) 當所有數據都在片上高速緩存;
(b) 動態取數據;(c) 解耦運算
圖2(b)給出了針對實例函數生成的硬件模塊的執行情況,此時數據集太大,需要動態送入片上高速緩存。注意減速程度如何反映所有高速緩存缺失時延的綜合影響。不過,情況并非一定如此,因為計算圖中有些部分的進展不需要立即提供內存數據。這些部分應該可以向前移動。執行調度中這點額外自由度有可能產生顯著影響,就像我們看到的那樣。
重構/解耦實例
我們看一下剛才的實例函數。假設浮點乘法的執行和數據訪問沒有全部由統一的安排聯系在一起。當一個負載運算符等待數據返回時,另一個負載運算符可以開始新的內存請求,乘法器的執行也能向前移動。為達到此目的,每項內存訪問都應該由一個模塊來負責,并按各自的調度運行。此外,乘法器單元應該與所有內存操作異步執行。
不同模塊間的數據相關性
通過硬件FIFO來通信。對于我們的實例而言,可能的重構形式如圖1(b)所示。用于各階段之間通信的硬件隊列可以緩沖已經取回但尚未使用的數據。當內存訪問部件因高速緩存缺失而出現拖延時,當前已產生的積壓數據還可以繼續供乘法器單元使用。在經歷較長時間后,形成的拖延時間會被浮點乘法的長時延掩蓋。
圖2(c)給出了使用解耦處理流水線時的執行調度。這里,通過FIFO的時延沒有考慮在內,不過如果迭代量很大,該時延的影響會達到最小。
我們如何進行重構?
為了給解耦處理模塊生成流水線,首先需要將初始CDFG中的指令進行組合以構成子圖。為使所得的實現方案性能最大化,聚類方法必須滿足幾個要求。
首先,正如我們之前所見,Vivado HLS工具在前面的迭代完成之前使用軟件流水線發起新的迭代。CDFG中最長循環依賴的時延決定可發起新迭代的最小間隔,最終會限制加速器所能實現的總吞吐量。因此,很重要的一點在于這些依賴循環不能遍歷多個子圖,例如用于模塊間通信的FIFO總是會增加時延。
其次,應該將內存操作與涉及長時延計算的依賴循環分開,這樣高速緩存缺失就會被慢速的數據處理所“掩蓋”。在這里,“長時延”是指操作需要一個周期以上的時間才能完成;在這里,我們使用Vivado HLS調度來獲取這一指標。例如,乘法是長時延操作,而整數加法不是。
最后,為了將高速緩存缺失引起的拖延影響限定在局部范圍內,您需要將每個子圖中的內存操作數量減至最少,尤其是在需要尋址存儲空間中的不同部分時更是如此。
第一個要求——防止依賴循環遍歷多個子圖——很容易滿足,只需要找到原始數據流圖中的強連通分量(SCC),并在將它們分為不同集群之前將其打開變成節點。這樣,我們就得到一個有向的非循環圖,其中有些節點是簡單指令,其它則為一組相關的操作。
要滿足第二和第三個要求,即分離內存操作和局部化拖延的影響,我們可以對這些節點進行拓撲排序,然后將它們分區。最簡單的分區方法是在每個內存操作或長時延SCC節點后畫一條“邊界”。圖3展示了如何將此方案應用于我們的實例。集群與圖1中流水線結構之間的對應關系應該做到顯而易見。每個子圖都是一個新的C函數,可獨立通過HLS推送。這些子圖在執行時相互間的步調并不一致。
我們構建了一個簡單的源到源轉換工具,用以執行重構。
我們使用賽靈思IP核,支持FIFO,以連接所生成的獨立模塊。當然,重構給定計算內核的方法不止一種,而且設計空間探索仍在進行中。
流水線化內存訪問
有了解耦處理流水線的初步實施方案后,我們就可以對其執行幾項優化,以提高其效率。正如我們所見,當使用HLS映射C函數時,內存讀取出現阻塞。這個問題也出現在流水線中的個別階段。例如,負責加載x[curInd]的模塊在等待數據時可能會產生拖延,即使在下個curInd已經就緒而且FIFO下游有足夠空間的情況下亦是如此。
為了解決這個問題,我們可以做一下轉變以簡化內存訪問。對于某個特定階段,我們不在C函數中執行簡單的內存加載,而是將地址推送到新的FIFO。然后,單獨實例化一個新的硬件模塊,以讀取地址FIFO送出的地址,并將它們發送到內存子系統。返回的數據被直接推送到下游FIFO。現在,內存訪問得到了有效的流水線化。
地址的推送操作可在Vivado HLS中通過向FIFO接口的內存存儲來代表,AXI總線協議允許您指定突發長度;而且,通過對解耦C函數進行一些小的修改,并利用流水線化的內存訪問模塊,我們就可利用該功能。
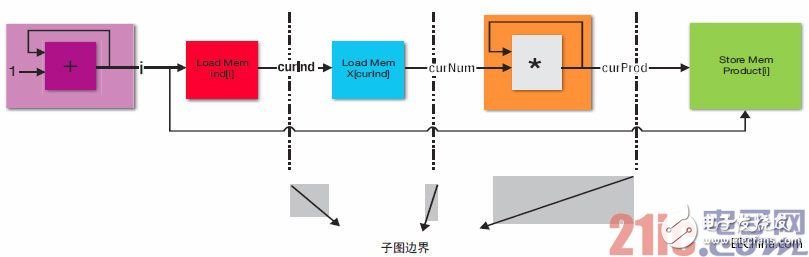
圖3 – 對子圖的重構

圖4 – 背包問題
除了生成地址以外,解耦C函數中每個內存操作符還要在連續存儲塊被訪問時計算突發長度。循環計數器的復制還有助于突發訪問的生成,因為被訪問的字數量可以在每個解耦函數中本地確定。
不過,用以監測下游FIFO和發送內存請求的硬件模塊則采用Verilog實現。這是因為在由Vivado HLS綜合的內存接口中,外發地址和響應數據沒有捆綁在一起。不過這是一個簡單模塊,能在不同基準測試中重用很多次,因此設計工作就被攤銷了。
復制或通信?
在重構內核并生成解耦處理流水線的過程中,用來在不同階段移動數據的FIFO會形成很大開銷。通過復制少量計算指令可以去除一些FIFO,這樣通常很有好處,因為即使是最小深度的FIFO也會占用不少FPGA資源。
一般而言,在權衡利弊以探究最佳設計點的過程中,您可以使用成本模型和規范的優化技術。但在大多數基準測試中,僅僅為它的每個用戶復制簡單的循環計數器就可以節省很多面積,這也正是我們所做的。在這個引導性實例中, 該優化是指復制i的整數加法器,因此存儲結果 i時不需要從其它模塊獲得索引。
內存的突發訪問
第三項優化是內存的突發訪問(burst-memory access)。為了更高效地利用內存帶寬,我們希望通過一次內存事務處理攜帶多個數據字。
實驗評估
我們應用上述方案做了幾個案例研究。 為評估這種方法的優勢,我們將使用該方案生成的解耦處理流水線 (DPP)與單純使用HLS生成的加速器進行比較。當為單純或DPP實現方案調用Vivado HLS時,我們將目標時鐘頻率設置到150MHz,并在布局布線后使用所能達到的最高時鐘速率。此外,我們針對加速器和內存子系統之間的交互嘗試了不同的機制。所用的端口為ACP和HP。我們為每個端口在可重配置陣列上實例化一個64KB高速緩存。
本實驗所用的物理器件是賽靈思的Zynq?-7000 XC7Z020全可編程SoC,安裝在ZedBoard評估平臺上。
我們還在Zynq SoC 的ARM?處理器上運行應用的軟件版本,并將其性能作為實驗的基準。生成的所有加速器功能齊全,無需任何DMA機制將數據移入和移出可重配置架構。
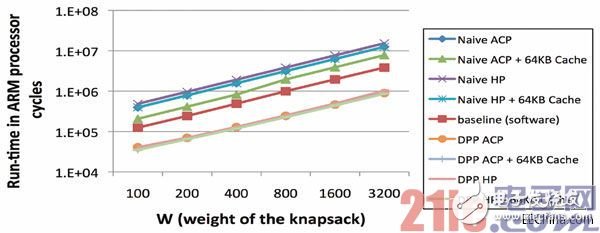
圖5 – 針對背包問題的運行時間比較
案例研究1:
背包問題
眾所周知,背包問題是一個組合問題,可以通過動態編程來求解。內核的結構如圖4所示。其中黑體字的變量都是在運行時間從
內存讀取。因此,無法確切知道從哪個位置加載的變量opt_without。當w和n 比較大時,我們無法在片上緩沖整個opt陣列。我們只能讓計算引擎取回所需的部分。
圖5給出了運行時間對比情況,將使用我們的方案(DPP)生成的加速器與單純通過HLS推送函數而生成的加速器進行比較。圖中還顯示了在ARM處理器上運行函數時的性能。 我們將n(項數)固定為40,使w (背包的總重量)在100至3,200之間變化。

圖6 – 稀疏矩陣向量乘法
從對比中很容易看出,通過單純使用Vivado HLS來映射軟件內核這種方法得到的 ARM處理器性能高出約4.5倍。另外,當使用
加速器性能比基準要求慢很多。 DPP時,各種內存訪問機制之間的Zynq SoC 上的超標量 差別相當小——使用我們的方案時,無序式ARM內核能受內存訪問時延的影響要小很多。
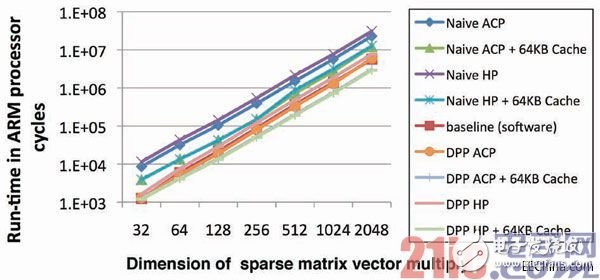
圖7 – 針對稀疏矩陣向量乘法的運行時間對比
很大程度開拓指令級并行性,而且具有一個高性能片上高速緩存。Vivado HLS工具提取的案例研究2:稀疏矩陣向量乘法
附加并行性顯然不足以補償硬處理器內核對于稀疏矩陣向量(SpMV)乘法是一個可編程邏輯的時鐘頻率優勢計算內核,已經在各種研究項目中以很多不同方法進行過研究、變換和基準確定。這里,我們的目的不是以及來自可重配置陣列的使用特殊數據結構和存儲分配方式更長的數據訪問時延。構建最佳性能的SpMV乘法,不過,當內核被解耦,分成而是想根據最基本的算法描述多個處理階段時,看看在使用Vivado HLS時重構性能就會明顯比傳遞能提供多少優勢。
如圖6所示,在我們的實驗中,稀疏矩陣以壓縮稀疏行(CSR)格式存儲。在取回數字以進行實際的浮點乘法之前,需要先執行來自索引數組的負載。用來決定訪問哪個控制流程和內存位置的數值只有在運行時間才知道。在圖7所示的運行時間對比中,矩陣的平均密度為1/16,尺寸在32和2,048之間變化。
此處,單純的映射法在性能上再次落后于軟件版。當不使用FPGA上的高速緩存時,用我們的方法生成的解耦處理流水線在性能上幾乎與基準性能相同。
當在可重配置陣列上實例化一個64KB高速緩存時,DPP的性能接近基準的兩倍。與之前的基準相比,高速緩存的增加對DPP的性能具有更顯著的影響。
案例研究3:FLOYD-WARSHALL 算法
Floyd-Warshall是一種圖形算法,用來找到任意一對頂點之間成對的最短路徑。內存訪問模式比之前的基準要簡單。因此,有可能存在一種方法可以設計出DMA+加速器結構,以獲得很好的計算重疊和片外通信。我們的方案能試著自動實現這種重疊,但是我們尚未進行相關的研究,以表明絕對最佳與實際所得之間的差距。
不過,與之前的基準一樣,我也進行了運行時間對比。這里,我們使圖形的大小在40個節點至160個節點之間變化。每個節點平均有全部節點的1/3作為其鄰點。得到的結果與背包問題中的十分類似。

圖8 –Floyd-Warshall算法
解耦處理流水線所實現的性能約為軟件基準的3倍,吞吐量達到任何單純映射法的兩倍多。當使用DPP時,對FPGA高速緩存的影響也很小,展示出了對于內存訪問時延的容限。
我們這種簡單的技術構建出的處理流水線可以更好地使用內存帶寬,而且對內存時延有更好的容限,因此能夠改善Vivado HLS的性能。所描述的方法可對控制數據流圖中的內存訪問和較長的依賴循環解耦,這樣高速緩存缺失就不會拖延加速器的其它部分。
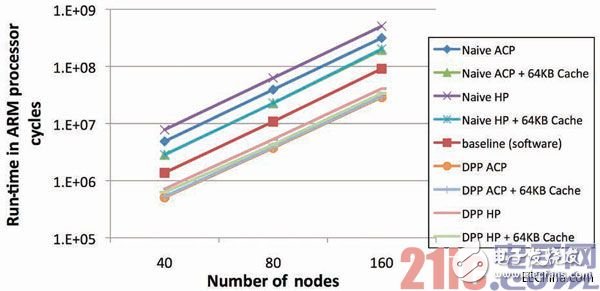
圖9 – 針對Floyd-Warshall算法的運行時間比較












 工商網監
工商網監
評論