 電子發燒友App
電子發燒友App


引言
近年來軟件無線電(SDR)得到了飛速的發展,在很多領域已顯示出其優越性。本文的項目背景是通過軟件無線電方式實現數字音頻廣播(DAB)的基帶信號處理,這要求軟件無線電平臺具有高速實時數字信號處理與傳輸能力。高速可編程邏輯器件(FPGA)和豐富的IP核提供了能高效實現軟件無線電技術的理想平臺。
1 PCIE總線方案論證
PCIE是第3代I/O總線互聯技術,如今已成為個人電腦和工業設備中主要的標準互聯總線。與傳統的并行PCI總線相比,PCIE采用串行總線點對點連接,具有更高的傳輸速率和可擴展性。例如本文采用的8通道1代PCIE 2.0硬核的理論傳輸速率是4 GB/s[1],其總線位寬亦可根據需求選擇×1、×2、×4和×8通道。與其他的串行接口(如RapidIO和Hypertransport)相比,PCIE具有更好的性能和更高的靈活性[2]。
1.1 PCIE總線實現方式
目前,PCI Express總線的實現方式主要有兩種:基于專用接口芯片ASIC和基于IP核的可編程邏輯器件FPGA方案。前者通常采用ASIC+FPGA/DSP的組合方式,專用PCIE接口芯片(如PEX8311)避免用戶過多地接觸PCIE協議,降低了開發難度;但其硬件電路設計復雜,功能固定,靈活性和可擴展性較差。后者使用IP核實現PCIE協議,用戶可以開發其所需的功能和驅動,具有可編程性和可重配置能力;另外,單片FPGA降低了成本和電路復雜程度,更符合片上系統(SoC)的設計思想。本文采用Xilinx公司Virtex6 FPGA和PCIE集成塊,實現雙緩沖模式的高速PCIE接口設計。
1.2 雙緩沖與單緩沖比較
以寫操作(數據從FPGA到內存)為例,雙緩沖PCIE系統框圖如圖1所示。為描述方便,將該FPGA片上系統命名為SRSE(Software Radio System with PCI Express)。
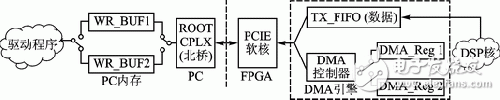
圖1 雙緩沖PCIE系統框圖
PC端的驅動程序在系統內存上為SRSE分配了兩個緩沖區(WR_BUF1/2)用于數據存儲,這兩個緩沖區的地址信息分別存儲在FPGA端的DMA寄存器(DAM_Reg1/2)中。Root Complex連接CPU、內存和PCIE器件,它代表CPU產生傳輸請求[3]CIE核是Xilinx公司提供的集成塊程序,實現PCIE協議的處理;DMA(直接存儲器訪問)引擎用于實現DSP核和PCIE器件間的高速數據存儲與交換;DSP(數字信號處理)核是用戶設計的算法或應用程序。以圖1為例,DSP核將產生的數據寫入TX_FIFO,DMA引擎將數據以傳輸層數據包(TLP)的形式發送至PCIE核,其中數據包的頭信息來自寄存器DMA_Reg1.當SRSE將數據寫入緩沖區WR_BUF1時,驅動分配另外一塊緩沖區WR_BUF2并將該緩沖區的地址信息寫入寄存器DMA_Reg2中;當DMA引擎發出WR_BUF1的寫操作消息中斷(MSI)后,DMA控制器將數據包的頭信息切換至DMA_Reg2,驅動將緩沖區切換至WR_BUF2,繼續傳輸數據。
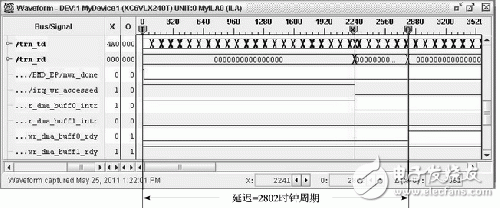
圖2 PCIE總線中斷延遲測量
與雙緩沖相對應的是單緩沖模式。以寫操作為例,驅動程序每次在內存上分配一個緩沖區WR_BUF,該緩沖區的地址信息存儲在DMA寄存器DMA_Reg中。當寫滿緩沖區WR_BUF時,DMA引擎會產生MSI中斷,并通過PCIE核通知驅動程序。驅動分配新的緩沖區,并將該緩沖區地址通過PCIE總線寫入DMA寄存器DMA_Reg中。中斷的傳輸和DMA寄存器的更新會產生一定延時,這需要較大的TX_FIFO來存取延時期間DSP核產生的數據。
為精確測量中斷延時時間,搭建了基于DELL T3400型PC和ML605開發套件的平臺,通過ChipScope觀察的波形結果如圖2所示。DMA中斷發生在時刻0(mwr_done:0﹥1);然后PCIE核向驅動發出MSI中斷,驅動程序查詢中斷寄存器發生在時刻2241(irq_wr_accessed:1﹥0);驅動程序分配新的內存緩沖區,然后更新DMA寄存器發生在時刻2802(wr_dma_buff0_rdy:0﹥1)。在這2802個時鐘周期內,PCIE器件無法將數據寫入內存。PCIE的時鐘頻率為250 MHz,所以中斷延時T=2802×(1/250 MHz)=11.2 μs.假定DSP核產生數據的速率為200 MB/s,中斷延時期間將產生11.2 μs×200 MB/s=2241 B大小的數據。考慮到其他不可預測因素,如中斷堵塞等,為了不丟失數據,TX_FIFO至少需要幾KB的空間。這對于FPGA內寶貴的硬件資源(如Block RAM)來說是嚴峻的挑戰。
與單緩沖模式相比,雙緩沖模式優點歸納如下:
① 更新緩沖區不會引入中斷延時,這意味著較小的FIFO即可滿足需求,節約了硬件資源。
② 雙緩沖模式延長了驅動程序處理中斷的時間,也使緩沖區數據的處理更加容易,丟包率大大減小。
③ 數據的傳輸和內存緩沖區的數據處理可以并行處理,系統的實時性得到保證。
④ 雙緩沖更適合Scatter/Gather DMA,取代block DMA,從而提高內存效率。
2 軟件無線電平臺設計
軟件無線電基于可編程、可重構的通用硬件平臺,通過加載不同的軟件實現不同的無線電功能,廣泛應用于軍用和民用領域。為了能夠實現復雜的算法,其平臺需要具備高速數據交換和實時信號處理的能力。該設計參考Xilinx ML605開發套件,基于Xilinx Virtex6 LX240T FPGA芯片,通過增加相應的模塊搭建通用的軟件無線電平臺。
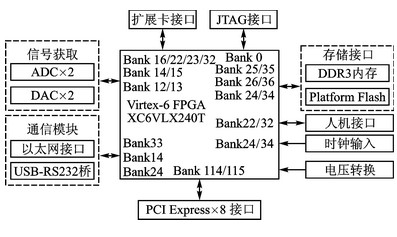
軟件無線電原理框圖如圖3所示。信號獲取模塊采用兩片ADC和DAC以實現IQ兩路信號的數模轉換;通信模塊由以太網和USBRS232接口組成;擴展卡可以是射頻發射機或接收機,通過擴展卡接口與母板相連;JTAG接口提供在線編程和內部測試功能;存儲器件包括512 MB DDR3內存和128 MB平臺Flash,分別用于動態數據存儲和配置FPGA;人機接口由LED/LCD、按鍵和開關等元件組成,實現人機對話;200 MHz有源晶振和SMA時鐘接口組成時鐘輸入模塊,向FPGA提供時鐘基準;8通道PCIE接口和IP核實現平臺與PC間高速數據交換。
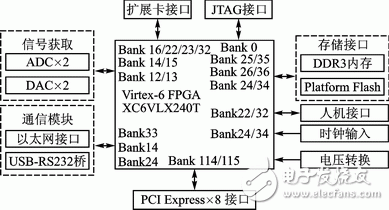
圖3 軟件無線電原理框圖
3 雙緩沖模式PCIE總線設計
3.1 PCIE驅動設計
PC端基于Linux(Ubuntu 10.10)操作系統。該操作系統免費開源,安全穩定靈活,適合低成本軟件開發。驅動程序包含數據流接口和控制接口。數據流接口用于Linux用戶空間和SRSE平臺間高速的數據交換;控制接口使用戶可以觀察和配置SRSE平臺寄存器,例如通過控制接口,用戶可以在PC端改變SRSE平臺的調諧頻率等參數。數據流接口是雙向獨立的,支持雙/單工,即可以同時讀和寫數據。以數據發送(從PC到SRSE)為例,用戶空間調用write()函數將任意數量的數據發送至驅動,驅動整理數據碎片以滿足PCIE對數據對齊和傳輸塊數據量的要求。當數據滿足4096字節,驅動將數據塊發送至Root Complex并保留已發送數據的列表,等待接收來自SRSE平臺的寫操作中斷。PCIE驅動數據接收的原理如圖4所示。當用戶空間調用read()函數或者驅動接收到來自PCIE設備的數據時,驅動初始化讀操作。驅動程序將保持阻塞(blocking),直到用戶空間調用read()函數,并且已接收到足夠的數據包,從而能夠填滿read()請求的數據量。碎片整理模塊對已接收的數據進行整理,然后將數據塊返回至用戶空間,并通知其解除驅動阻止。
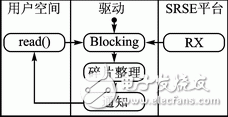
圖4 PCIE驅動中的數據接收
3.2 PCIE核配置
Virtex6 PCIE Endpoint Block[4]集成了傳輸層(TL)、數據鏈路層(DLL)和物理層(PL)協議,它完全符合PCIE基本規范,可配置性增加了設計的靈活性,降低了成本。其功能框圖與接口如圖5所示。其中收發器通過PCIE總線與Root Complex實現數據包的傳遞,PCIE總線由系統接口和PCIE接口組成;系統接口由復位和時鐘信號組成,PCIE接口由8條差分傳輸和接收對組成(8lane)。TX/RX Block RAM用來存儲來自DMA引擎和系統內存的數據,其大小可以通過Xilinx Core Generator配置。傳輸接口為用戶提供了產生和接收TLP的機制;物理層接口使用戶能夠觀測和控制鏈路的狀態;配置接口使用戶能夠觀察和配置PCIE終端的配置空間,即DMA寄存器;中斷接口實現DMA與PCIE核之間的中斷傳輸。用戶通過這些接口設計符合其需要的DMA引擎。
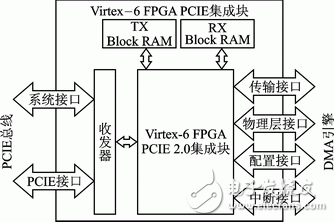
圖5 PCIE功能框圖與接口
本文使用Xilinx CORE Generator生成PCIE核,其主要配置參數如表1所列。

表1 PCIE核主要配置參數
3.3 總線主控DMA傳輸
參考Xilinx應用實例XAPP1052[5],本文設計的DMA結構框圖如圖6所示,各部分功能介紹如下:
① 發射引擎。發射引擎產生傳輸層數據包(TLP)并通過傳輸接口發送至PCIE核,數據包的數據來自TX_FIFO,頭信息來自DMA控制/狀態寄存器,也負責驅動對DMA寄存器的讀取。
② 接收引擎。接收引擎將來自上位機的數據包解碼并轉存至RX_FIFO中,也接收來自驅動的配置信息并將寄存器值寫入DMA控制/狀態寄存器中。
③ DMA控制/狀態寄存器。該模塊是DMA的主控制器,控制著DMA復位、讀寫等操作;內存緩沖區的地址信息和TLP包長度等信息也存儲在該寄存器中。
④ MSI中斷控制器。該模塊產生讀寫中斷,然后通過中斷接口通知PCIE核,進而通知驅動程序。
⑤ TX/RX_FIFO.通過Xilinx Core Generator將FIFO配置為獨立時鐘異步模式,實現不同時鐘域的數據緩沖和位寬轉換。本文PCIE時鐘為250 MHz、位寬64位,而DSP核時鐘為200 MHz、位寬32位。
⑥ PCIE核。該模塊為例化的PCIE集成塊,框圖和參數詳見圖5和表1.
⑦ DSP核。該模塊為用戶設計的算法或者功能模塊,例如通過Simulink調用Xilinx庫實現某種功能。
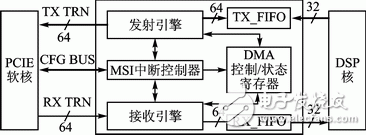
圖6 DMA結構框圖
3.4 雙緩沖PCIE協議
以寫操作為例,雙緩沖PCIE協議如圖7所示。初始化時,驅動程序在內存中分配兩塊緩沖區Buff 1a/2a,然后將Buff 1a的地址信息寫入DMA控制/狀態寄存器DMA_Reg1(圖1)中并開始寫操作;DMA引擎將FIFO中的數據以數據包的形式通過PCIE總線發送至緩沖區Buff 1a中,期間驅動程序將Buff 2a的地址信息發送至DMA控制/狀態寄存器DMA_Reg2中;當Buff 1a寫操作完成時,MSI中斷控制器產生MSI中斷并通知驅動,此時驅動和DMA控制器同時切換緩沖區,即驅動將緩沖區切換至Buff 2a,DMA控制器將TLP頭信息切換至DMA_Reg2,如此繼續傳輸數據。
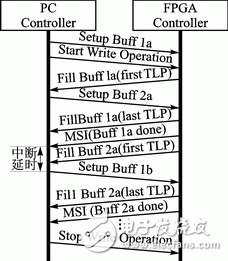
圖7 雙緩沖PCIE操作協議(寫操作)
將MSI中斷與新緩沖區配置間的時間間隔稱為中斷延時,如圖2和圖7所示。雙緩沖模式的引入消除了中斷延時的影響,使SRSE在中斷延時期間仍能傳輸數據,節約了硬件資源,驅動程序也有更多時間來處理緩沖區的數據。
4 PCIE調試與性能
提供了Root Port的Test Bench,它可以模擬PC和驅動程序,如初始化DMA引擎、產生下行數據流并發送至PCIE設備,也可以接收來自PCIE設備的上行數據流等,使整個系統(PCIE核+DMA引擎+DSP核)可以在Modelsim SE環境下仿真。這大大縮短了開發周期,提高了開發效率。功能仿真通過后,使用Xilinx ISE 軟件完成代碼的輸入、綜合、實現、驗證和下載。
硬件平臺為DELL T3400型PC和Xilinx ML605開發套件。PC端基于Ubuntu 10.10操作系統運行驅動程序,FPGA端DSP核(圖6)通過Matlab Simulink調用Xilinx元件庫實現。本文DSP核由32位計數器和加法器組成:計數器將值寫入TX_FIFO,PC端檢測接收數據以驗證寫操作(SRSE→PC);同樣地,PC端產生+1計數值并將數據寫入RX_FIFO,DSP核的加法器用來驗證讀操作(PC→SRSE)。
結語
本文設計了基于Xilinx Virtex6 FPGA的通用軟件無線電平臺,利用C語言開發了基于Linux系統的驅動程序,利用Verilog語言設計基于Xilinx PCIE硬核的雙緩沖DMA控制器。雙緩沖消除了中斷延時的影響,節約了硬件資源,提高了數據傳輸速度。





























 工商網監
工商網監
評論