 電子發(fā)燒友App
電子發(fā)燒友App


引 言
紅外視頻處理系統(tǒng)是典型的實時信號處理系統(tǒng),具有數(shù)據(jù)吞吐量大和運算密集度高的特點,一般由通用DSP實現(xiàn)復雜的視頻處理算法。目前高端通用DSP的主頻已達到600 MHz以上,內(nèi)部集成多個運算單元,運算能力可以滿足大多視頻處理算法的要求。但是一般的通用DSP只有一條數(shù)據(jù)總線,數(shù)據(jù)吞吐能力低,必須在DSP外部進行數(shù)據(jù)輸入緩沖和輸出緩沖,需要DSP內(nèi)核參與整個數(shù)據(jù)吞吐過程,這就大大削弱了DSP的運算能力,同時增加了系統(tǒng)構架的復雜度,因此,數(shù)據(jù)吞吐成為基于通用DSP的紅外視頻處理系統(tǒng)的最大瓶頸。
Blackfin系列DSP專門針對高速數(shù)據(jù)吞吐集成了并行外圍接口(PPI),在傳統(tǒng)的數(shù)據(jù)總線的基礎上增加了一條數(shù)據(jù)吞吐通道。PPI接口:1)能以最高66 MHz 的頻率接收數(shù)據(jù),以最高60 MHz 的頻率輸出數(shù)據(jù);2)不再需要額外的數(shù)據(jù)輸入/輸出緩沖,直接連接高速AD/DA輸入輸出數(shù)據(jù);3)能夠輸入或輸出ITU-R601/656 格式和帶行場同步時鐘的RGB格式的數(shù)字視頻。使用PPI接口輸入輸出數(shù)據(jù),輔以強大的DMA流量控制和高速SDRAM,使BlackfinDSP的內(nèi)核獨立于數(shù)據(jù)吞吐過程,充分發(fā)揮其密集運算能力,并簡化了系統(tǒng)構架,在紅外視頻處理通用模塊中取得了良好的應用。
紅外視頻處理通用模塊數(shù)據(jù)吞吐分析
一個通用的紅外視頻處理流程如圖1所示,利用高速AD采集探測器輸出的模擬信號,形成原始視頻數(shù)據(jù)流,再經(jīng)過視頻處理單元的實時視頻處理,以特定的視頻格式高速輸出。
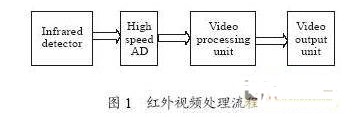
紅外視頻處理過程是一個高速數(shù)據(jù)吞吐和密集運算的并發(fā)過程。當視頻處理算法復雜時,視頻處理單元多由高性能通用DSP構成。DSP接收AD輸出的原始視頻數(shù)據(jù)是數(shù)據(jù)寫入的過程,DSP輸出處理后視頻是數(shù)據(jù)讀出的過程,DSP進行視頻處理運算至少需要一次數(shù)據(jù)讀出和一次數(shù)據(jù)寫入,因此數(shù)據(jù)寫入、數(shù)據(jù)讀出和中間的視頻處理三者同時進行,至少包含兩次數(shù)據(jù)讀和兩次數(shù)據(jù)寫。一般的通用DSP只有一條數(shù)據(jù)總線,無法并行進行數(shù)據(jù)吞吐和視頻處理運算,所以通常在高速AD和DSP之間、在DSP和視頻輸出單元之間,增加FIFO、雙口RAM或雙片SRAM 輪換,構成數(shù)據(jù)緩沖環(huán)節(jié),由DSP內(nèi)核控制數(shù)據(jù)緩沖過程。這使得系統(tǒng)構架變得非常復雜,而且數(shù)據(jù)緩沖過程占用了DSP內(nèi)核進行數(shù)據(jù)運算的時間,大大降低了DSP的效率。
本文基于Analog Device公司Blackfin系列BF561型通用DSP,利用其特有的PPI接口,提出一種紅外視頻處理通用模塊的構架,省略了數(shù)據(jù)緩沖環(huán)節(jié),使數(shù)據(jù)吞吐過程獨立于DSP內(nèi)核,基本不占用DSP進行數(shù)據(jù)運算的時間,充分發(fā)揮了DSP密集運算的優(yōu)勢。系統(tǒng)構架如圖2所示。
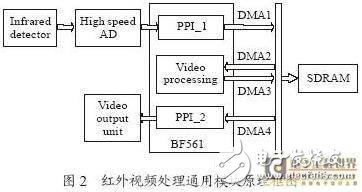
BF561 內(nèi)部集成了兩個完全相同的BlackfinDSP內(nèi)核,共有兩個PPI接口,分別與高速AD和視頻輸出單元直接接口。原始視頻數(shù)據(jù)、最終輸出的視頻數(shù)據(jù)和視頻處理的中間數(shù)據(jù),全部存儲在高速SDRAM中。通過4 條獨立的DMA通道和BlackfinDSP特有的DMA流量控制,共享SDRAM高達133MHz×16位的帶寬。DSP內(nèi)核只需要初始化DMA的工作參數(shù),具體的數(shù)據(jù)吞吐由DMA控制器獨立完成,不再需要DSP內(nèi)核干預。為進一步縮短數(shù)據(jù)等待時間,提高DSP的運算效率,所有的數(shù)據(jù)讀寫都設置為帶流量控制的乒乓操作,實現(xiàn)了在DMA吞吐數(shù)據(jù)的同時進行視頻處理運算,最大程度上發(fā)揮了DSP的密集運算能力。
PPI接口配置
PPI接口是一種可以配置成8~16 位數(shù)據(jù)寬度的多功能并行同步準雙向接口,包括三條同步信號線和一個連接到外部時鐘的時鐘線,通過修改相應的寄存器設置PPI接口各種工作模式。
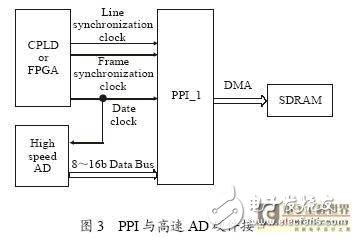
PPI與高速AD硬件接口
如圖3 所示,以CPLD或FPGA實現(xiàn)控制時序,為高速AD和PPI_1 提供數(shù)據(jù)時鐘,根據(jù)探測器輸出的行同步時鐘和場同步時鐘,經(jīng)過一定變換,提供給PPI接口,通過DMA,PPI接口根據(jù)三個時鐘信號將AD輸出的8~16位數(shù)據(jù)寫入SDRAM。本接口支持8~16 位并行輸出的高速AD(例如AD9240),數(shù)據(jù)時鐘最高66 MHz。
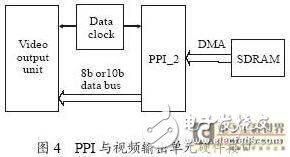
PPI與視頻輸出單元硬件接口
如圖4 所示,通過DMA,PPI_2 讀取SDRAM內(nèi)的視頻數(shù)據(jù),根據(jù)數(shù)據(jù)時鐘,以ITU-R656 格式,輸出到模擬視頻編碼器(例如ADV7171),以PAL或NTSC 制式輸出到監(jiān)視器。
PPI接口寄存器設置
PPI接口可以設置為ITU-R656 輸入模式,ITU-R656 輸出模式,通用輸入模式和通用輸出模式。每種工作模式中又可以設置數(shù)據(jù)寬度,同步時鐘工作方式和數(shù)據(jù)打包/解包等多種工作條件。通過寫PPI_CONTROL、PPI_DELAY 和PPI_COUNT 三個寄存器設置PPI接口的工作模式。
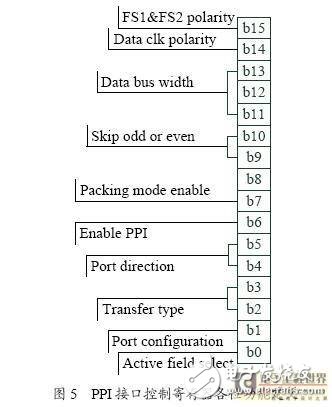
PPI接口控制寄存器:PPI_CONTROL
PPI接口控制寄存器各位功能定義如圖5 所示,與高速AD輸入和視頻輸出相關的設置如下,
1)設置同步時鐘極性和設置數(shù)據(jù)時鐘極性:FS1&FS2polarity,DatAclk polarity 選擇同步時鐘和數(shù)據(jù)時鐘上升沿或是下降沿有效。
2)設置數(shù)據(jù)寬度:DatAbuswidth 設置數(shù)據(jù)總線寬度,最小8 位,最大16 位。
3)設置數(shù)據(jù)打包/解包模式:Packing modeenable設置是否使能數(shù)據(jù)打包/解包模式,若使能,當PPI接口處于8 位輸入模式,則將輸入的兩個8 位數(shù)據(jù)打包為1 個16 位數(shù)據(jù)存儲;當PPI接口處于8 位輸出模式,則將1 個16 位數(shù)據(jù)按低位在前高位在后的順序解包輸出;當PPI接口為8 位數(shù)據(jù)寬度,數(shù)據(jù)打包/解包模式能夠降低1 倍數(shù)據(jù)存儲空間和降低1倍數(shù)據(jù)輸入帶寬。
4)設置同步時鐘工作模式:Portconfiguration選擇輸入或輸出模式下同步時鐘工作模式,與高速AD接口輸入原始視頻數(shù)據(jù)需要兩個同步時鐘,與模擬視頻編碼器接口輸出ITU-R656格式數(shù)字視頻,不需要同步時鐘。
5)設置輸入或輸出子模式:Transfer type與高速AD接口輸入原始視頻數(shù)據(jù)時,使用通用輸入工作模式;與視頻輸出單元接口輸出視頻數(shù)據(jù),使用不帶同步時鐘的輸出工作模式。
6)選擇輸入或輸出方向:Port direction與高速AD接口輸入原始視頻數(shù)據(jù)時,選擇輸入模式;與視頻輸出單元接口輸出視頻數(shù)據(jù),選擇輸出模式。
7)啟動PPI接口:EnablePPI啟動PPI接口后,在輸入模式時,當PPI接口接收到正確的同步時鐘信號才開始輸入數(shù)據(jù);在輸出模式時,當相應的同步時鐘開始工作后才開始輸出數(shù)據(jù)。
PPI接口延遲寄存器:PPI_DELAY
在行同步時鐘有效后,延遲PPI_DELAY 個數(shù)據(jù)時鐘,PPI接口開始輸入或輸出行像素。
PPI接口計數(shù)寄存器:PPI_COUNT
在行同步時鐘有效期內(nèi),PPI接口輸入或輸出PPI_COUNT 個行像素。
PPI接口DMA設置
DMA流量控制
DSP內(nèi)核設置PPI接口DMA的初始工作參數(shù)后,由DMA控制器獨立完成PPI接口讀取和寫入SDRAM的操作。SDRAM數(shù)據(jù)總線帶寬為133 MHz×16 位,但只有一條數(shù)據(jù)總線,并且紅外視頻處理過程中數(shù)據(jù)寫入、數(shù)據(jù)讀出和中間的視頻處理三者需要同時進行,至少包含兩次數(shù)據(jù)讀和兩次數(shù)據(jù)寫。如果按時間進程單任務線性安排PPI接口DMA讀寫SDRAM的操作,不能充分利用SDRAM的帶寬,無法完成并發(fā)讀寫SDRAM 的要求。為了充分利用SDRAM 的帶寬,必須使用BlackfinDSP特有的DMA流量控制。
采用DMA流量控制時,DMA控制器首先分析所有使能的DMA通道,提高與正在運行的DMA的讀寫方向一致的DMA通道的優(yōu)先級,例如當前DMA正在讀SDRAM,那么所有讀SDRAM 的DMA均比寫SDRAM 的DMA的優(yōu)先級高,所有讀SDRAM 的DMA按固有優(yōu)先級排列次序。以預置的流量時隙為周期(例如10 字節(jié)),按133 MHz的最大速度,每次發(fā)讀10 字節(jié)數(shù)據(jù)到當前DMA通道的FIFO 內(nèi),輪換到下一個DMA通道。當所有讀SDRAM 的DMA執(zhí)行完一遍后,輪換到寫SDRAM 的DMA,執(zhí)行相同過程。這樣,降低了改變SDRAM 讀寫方向耗費的時間,同時每個使能的DMA通道在設定的周期內(nèi)都以最大速度輪換執(zhí)行了一遍,保證了一定時間內(nèi)對SDRAM 的并發(fā)讀寫操作,充分利用了SDRAM 接口的最大帶寬。
乒乓操作
由于紅外視頻處理過程中數(shù)據(jù)寫入、數(shù)據(jù)讀出和中間的視頻處理三者同時進行,所以當前DMA讀取或?qū)懭氲臄?shù)據(jù),就是DSP內(nèi)核或其他DMA已經(jīng)寫入或?qū)⒁x取的數(shù)據(jù),這是一個級聯(lián)的因果系統(tǒng)。如果當前DMA正在讀寫的數(shù)據(jù)在時間或因果關系上與DSP內(nèi)核或其他DMA發(fā)生沖突,就會導致數(shù)據(jù)等待或數(shù)據(jù)錯誤。
為降低數(shù)據(jù)等待時間并避免因果錯誤,對每個DMA操作,在目標存儲區(qū)內(nèi)都開辟兩個緩沖區(qū),設為BufferA和BufferB。當前DMA正在操作的設為BufferA,這是獨占性操作,不允許其他DMA或DSP內(nèi)核訪問。當前DMA已經(jīng)操作完畢的設為BufferB,開放給其他DMA或DSP內(nèi)核訪問。當前DMA操作在BufferA和BufferB之間切換,通過信號量標志獨占區(qū)和開放區(qū),于是在任一時間,當前DMA都有一個可供其他DMA或DSP內(nèi)核訪問的區(qū)域,這樣就降低了數(shù)據(jù)等待時間,并避免了因果錯誤。
結 論
本文在介紹了PPI接口性能特點的基礎上,提出了一種紅外視頻處理通用模塊的構架,省略了數(shù)據(jù)緩沖環(huán)節(jié),使數(shù)據(jù)吞吐過程獨立于DSP內(nèi)核,提高了DSP的運算效率。





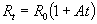










 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論