 電子發燒友App
電子發燒友App


寫這個源自我在清華同窗一個技術八卦群聊起了nvlink的若干技術,然后就打算寫一寫我作為一個旁觀者所見并試圖還原的nvlink的歷史。 ? 首先申明,我沒有在NVIDIA工作過一天,也沒有獲取一些非正常渠道的秘密信息或文檔,但這不妨礙我把所有從公開渠道獲得的零碎信息組裝成一個相對完備的邏輯………… 大多數歷史都是官方潤色過的并故意隱藏掉細節的,nvlink也不例外。 正如一個博主所說,我們在談到馬嵬坡的時候,往往想到的歷史就是楊玉環、李白、《妖貓傳》,還有山口百惠,但是真正能夠讓我們以史為鑒知興替的,是為什么是在馬嵬坡?這一切究竟是怎么發生的?禁軍的榮譽感和忠誠度呢?為什么面臨帝國內亂,他們想到的第一件事情不是逃難,不是反攻,而是干掉一個叫做楊國忠的人?為什么干掉楊國忠那么重要? 甚至于最近的,為什么是那個廚子? ? 這個世界沒有什么下大棋,歷史的真相如果當局者沒有總結,后人或者旁觀者都只能通過一個個小故事的細節和關系,梳理總結成完整的邏輯。我希望通過推測盡可能看到Nvlink歷史上的若干細節故事,還原出它的部分真實。
nvlink的誕生
Nvlink誕生于超算 :) 是的,超算。 在AI出盡風頭之前,IT領域真正的技術探索其實都是依賴于超算驅動的,這是一個類似于攀登珠穆朗瑪峰并沿途下蛋的持續性技術改良的模式 :) 和當下AI驅動技術動輒就顛覆的模式相差蠻大,說不上誰優誰劣,最終都是優勝劣汰吧。 Nvlink的初始技術相當大部分來源于IBM,是的,IBM幾乎是一切技術的源頭。考慮到IBM那些年在美國的超算市場逐漸下滑,曾經的Blue Gene黯然失色,而Nvidia又恰好想在技術上更進一步,他們的結合以IBM的高傲大概率是Nvidia主動貼上去的,但也算得上郎有情妾有意,不過分手的時候也大概率Nvidia賺得最大。 IBM和Nvidia曾經是有過一段如膠似漆的日子。最簡單的,你看業界的文檔標注IO帶寬的時候,只有兩家是乘以二把TX和RX算到一起的,例如正常我們談200G網口的時候,這網口就是8組25Gbps的Serdes,但IBM和Nvidia是唯二把這個IO標成400G的 :) 后來被NVIDIA收養的Mallenox應該很不習慣。 Nvidia GPGPU的片上總線NoC看上去也有很多IBM的影子,我經常把IBM的NOC論文中的行為套到Nvidia上,幾乎都對。 應該還有很多,我們能夠找到關于這段感情遺留的痕跡。 嗯,回到Nvlink,它提出的主旨很簡單,就是突破PCIe的屏障,達成GPU-GPU及CPU-GPU的高效數據交互,當年正是intel把持pcie最惡劣的情況,PCIe device之間的數據直通需要經過CPU才行(基于所謂訪問安全的約束)。所以,那是2016年的秋天,橙黃橘綠,IBM的Power8和Nvidia的P100完成了基于Nvlink的靈與肉的結合,2+4,沒有PCIe,產品是HPC。
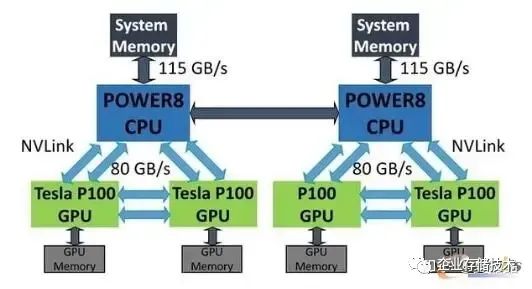
Nvlink的演進
- Pascal的Nvlink1.0的IO速率是20Gbps,8Lane per Port,每個Port 320Gbps(雙向),這其實是一代不完全成熟的產品,因為這個Port的速率很獨特,GPGPU內部微架構團隊可能也還沒有完全接納。
- Volta的Nvlink2.0的IO速率是25Gbps,8Lane per Port,每個Port 400Gbps(雙向),從此時開始,GPGPU對這個數字就鎖定了。
- Ampere的Nvlink3.0的IO速率是50Gbps,4Lane per Port,每個Port 400Gbps(雙向)。
- Hopper的Nvlink4.0的IO速率是100Gbps,2Lane per Port,每個Port 400Gbps(雙向)。
- Blackwill的Nvlink5.0,沒發布,但以此類推,大致就是IO速率200Gbps,1Lane per Port,每個Port 400Gbps。
我就好奇大了,Blackwill Next咋辦呢?IO速率400Gbps?1/2 Lane per Port ? P:V:A:H:B的Port數量依次是4:6:12:18:24,以此遞增芯片帶寬160GB/s:300GB/s:600GB/s:900GB/s:1200GB/s。 很多人對單個Port速率固定,每代增加Port數量的方式不太理解:) 這其實是一個芯片快速設計的技巧,即每個Port的MAC在逐代演進中可以做到幾乎不變或只是不斷精細化打磨。 至于多個端口之間帶寬怎樣分配?其實也是解耦的,Nvidia采用了Swizzle隨機+地址求模的方式均衡Port間的帶寬(從這里你能看到Nvlink是多路徑亂序的協議)。 ? ?
DGX和HGX
大狗熊和黑狗熊,很多人傻傻分不清。
Nvidia最初推出的是DGX,2016年發布的第一代DGX-1,這玩意兒其實是一個單機,嚴格來講,小型機。雖然當年數據中心建設雖然如火如荼,但Nvidia還是希望能以一個硬件system的模式,把一個Box賣給客戶,并獲得足夠高的利潤。君不見,這玩意兒渾身內外都涂滿中東土豪的金色,差點就想告訴你你買了一塊大金磚。 ? DGX-1差不多是15萬美元左右,到DGX-2則到了40萬美元,相比買單卡的溢價非常高,買到即虧到。 DGX并不適合世界上最大的IT采購商:Cloud,缺乏彈性,我猜它賣得并不那么好,當然作為旗艦產品撐場子是絕對合格。 簡單的說,DGX V100的CPU連塊網口都沒配置,更不用提符合Cloud Service的DPU。 其實Nvidia也是到了Ampere的時代,才理解了數據中心的OVS :) 其標識在于CPU開始配置獨立網卡CX6并支持VPI。 大狗熊和黑狗熊長得是很像 :) 但細節展開差別蠻大的。 今天講Nvlink,那以V100 DGX vs HGX為參考,DGX的跨板Nvlink是通過背板互聯的,而HGX的跨板Nvlink是通過線纜互聯的。 就這么個點,至少就決定了DGX只能整機在Nvidia購買,而HGX是可以賣獨立器件再OEM給浪潮、Dell制造組裝的(后者是大型互聯網客戶的典型采購模式)。 其實呢,互聯網的同學們也是騙自己,還在假裝自己是買到了最便宜的白盒Device,然后做了高難度的DIY呢 :)
NvSwitch的演進
Nvlink至今到Hopper發展了四代,而Nvswitch至今有三代 :) 也就是說第一代Pascal時期其實是沒有Switch的,當年的一機八卡,是一種類似Cube的直連系統。 多卡系統做Reduce怎么都是跑不掉的,oh,holy shit,當年分析Cube直連系統,算Ring Reduce的路徑覆蓋最大化可真玩死哥了。我感覺應該很多人和我一樣,紛紛給Nvidia留言了“fxxk”、“Damn”等信息,握爪。
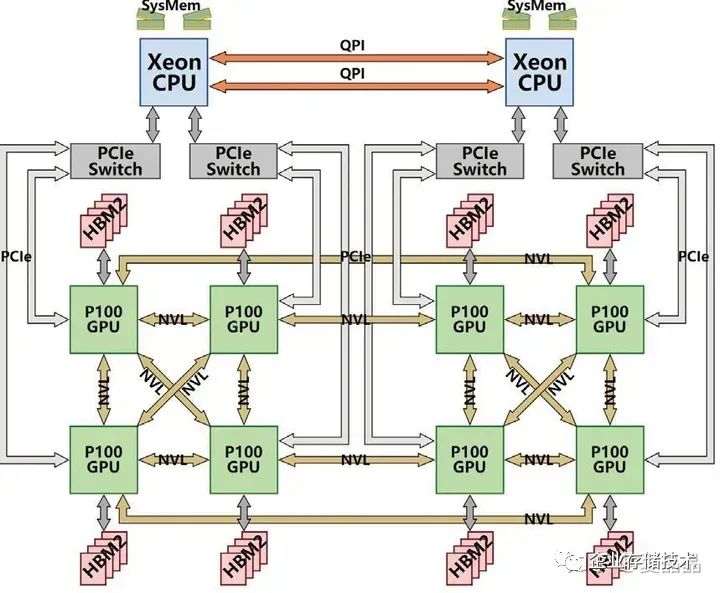
Nvidia受不了了,既然這么多程序員的數學都是體育老師教的,那還是暴力全交換吧。 所以在Volta to Ampere之間的2018年,Nvidia推出了基于NvSwitch的DGX-2(HGX和DGX差別在于硬件設計,邏輯上兩者是一樣的)。
- Pascal只有DGX-1
- Volta有DGX-1和DGX-2
- Ampere及Hopper只有DGX-2
- 什么時候會有DGX-3呢?
nvlink2.0對應的Nvswitch1.0支持18個Port,每個port x8,IO速率25G,交換能力就是400x18 =3.6Tbps nvlink3.0對應的NvSwitch2.0支持36個Port,每個Port x4,IO速率50G,交換能力就是400x36 = 7.2Tbps Nvlink4.0對應的Nvswtch3.0支持64個Port,每個Port x2,IO速率100G,交換能力就是400x64 = 12.8Tbps 嗯,對數字敏感的同學有沒有覺得很奇怪 :) 為什么是18?不是16 = 2^4 ? 不是說好一機八卡嗎? 因為愛啊!!! 這多余的兩個Port是為IBM留著的,其他人都不配。 你不信?你打開你買到的DGX V100/A100的機框看看,所有的NvSwitch芯片,都只連接了16個Port,無論誰家買的,都有2個Port在哪兒,多情自古空余恨啊。Nvidia翹首以盼,整整等了兩代,IBM都無法再次崛起重新入主超算領域,反而迎來了AI的爆發。我們從IBM流出的一張圖可以看到,支持Nvlink3.0(Nvswitch2.0)的Power9原本是在計劃中的(HC30),但最終,IBM,那個男人,他沒有做到他的承諾。
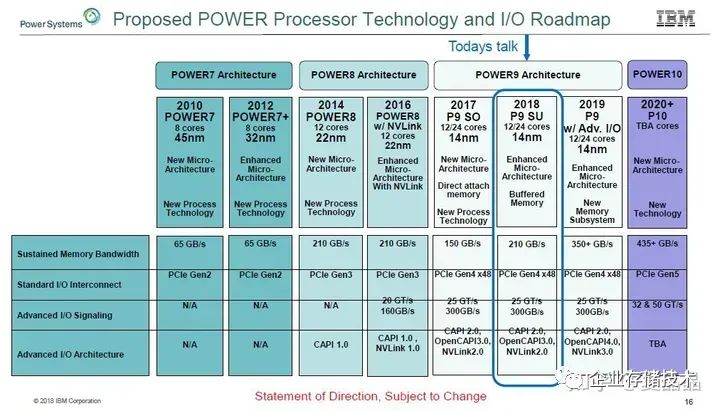
? Nvidia固然從IBM得到了很多,但是最終它并沒有辜負這段感情。
Nvlink-Network的誕生
Nvlink-Network和Nvlink是兩個東西,是兩個東西,是兩個東西。 為什么好好的有Nvlink了,還搞Nvlink-Network ? 這個問題的源頭來自HGX的形態,為什么DGX/HGX-2 V100有8P和16P兩種機器銷售?但DGX/HGX-2 A100卻只有8P唯一形態 ?下圖是Nvidia官方的Nvswitch互聯圖。
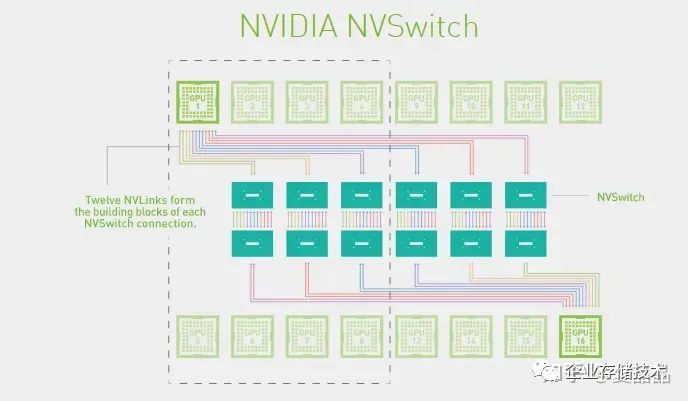
下圖是A100的HGX單板,黃教主端在手上,注意看最右側,六顆NvSwitch芯片的右端,是跨板的Nvlink端口,通過這一組端口你可以將兩張8P的A100單板組合成一個16P的HGX系統。 OTT負責基礎設施的老板們啊,中國那花10億美元購買A100的那個公司啊,打開你的機箱看一看,你定制的HGX A100單板,Nwswitch芯片的外側端口,是不是懸空的? ? ? 為什么?難度微軟給OpenAI提供的是一機八卡的HGX做訓練,所以中國做AI的所有人,所有人都認為只能做一機八卡了? 哦,你畫了幾十萬美元買的A100八卡板,他的NvSwitch3.0芯片,都在哭o(╥﹏╥)o啊,18個Port,其中兩個Port永遠地留給了那個男人,但是還有8個Port是懸空的啊,懸空的啊。 嗯,中國購買的所有NvSwitch3.0芯片,都只使能了8/18的Port。。。。。。。老板,快開除那些不上進的家伙。 這個世界上根本就沒有16P的A100,對吧?不對啊,有一家有,如下,Google的A2-MegaGPU-16g實例,這是我在世上唯一找到官方的A100 16P系統。
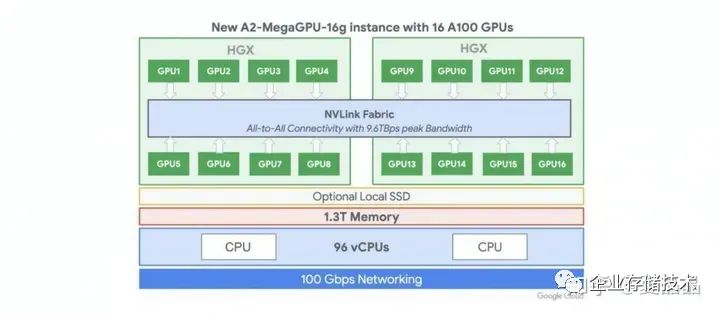
Google Machine Type a2-megagpu-16g https://gcloud-compute.com/a2-megagpu-16g.html ? 微軟和AWS都沒有看到A100的16P實例,先不忙裁人,這事必有蹊蹺 :) 我不是Nvidia的架構師,不知道詳情是什么。我只能猜測一個答案。 Nvlink這個協議其實不適合跨Board,對Cable不適。 大概率,Nvlink是做Nvidia做計算的同學主導的,類似Intel的UPI,做計算的人做IO,往往都圖個簡單粗暴,沒有做強大的糾錯碼,也沒有出錯重傳的設計,遇到丟包直接全機藍屏。 勇敢地說,我是計算的,我做互聯也是這德行 :) Nvlink1的速率是20G,Nvlink2的速率是25G,Nvlink3的速率是50G,Nvlink4的速率是100G,真的都是整數哦,你看,只有做計算的人才干的出來,網絡的人不會這么莽的。 做網絡的同學會用26.5625G、53.125G、106.25G,這種完全無厘頭的頻點,這也是大多數Cable和Optical Fiber的頻點。 此外,16P的A100系統,兩個單板之間需要互聯64x6 = 384 Lane需要互聯,無論是cable還是Connector,大致上都有非常巨大的工程問題。 為什么Google搞定了?為什么技術不能復制到全世界?不知道。 但我猜Mallenox的同學被Nvidia包養之后,來了IO的同學,一看,這隊友是在送人頭 ?扶了一把。 所以,就有了Nvlink-Network。 Nvlink-NetWork大致上是按照網絡的方法做了協議改造,對,你打開Hopper驅動,歷歷在目,100G頻點之外,多了一個106.25G,IB的Sharp也被融合到Nvlink-Network放到了Nvswitch內部(驅動都沒變)。 收購Mallenox是Nvidia最成功的聯合了吧。雖然從近期GH200的故事來看,Nvlink-Network的領域在逐步擴大,已經到了256,下一跳,肉眼可見的范圍內,Nvlink-Network會吃掉IB。以色列人可能也無所謂吧,畢竟股票賺了那么多。。。。。。。 ? 最后露一個值個幾萬塊的Nvlink-Network的秘密 :) Hopper的Nvlink帶寬是900GB,要在這么巨大的帶寬上同時滿帶寬支持Nvlink-Network需要的特性,包括重傳、糾錯、編碼等,GPU寶貴的Silicon面積會被耗掉非常多,至少1000個CUDA Core起步吧 :) 我給的答案是:只有GPGPU+Nvswitch才能組合出完整的Nvlink-Network,懂的自然懂。
Nvlink-C2C的誕生
先說結論:Nvlink-C2C是個錯誤的技術路徑。 我仿佛記得Nvlink-C2C的主架構師Wei wei是我大學同學 ?有這么個模糊印象。 如果單純從技術的角度,Nvlink-C2C真的是一個恰到好處的設計,挺佩服的。增之一分則太長,減之一分則太短,信號速率低了,PCB會變貴,信號速率高了,功耗會變高。 但是Nvlink-C2C從系統來講,并不是個好選擇。 總遇到有些人,把NVIDIA當作宗教信仰一樣崇拜,把黃教主說的就當做圣言。 嗨。
- 為什么要綁定Grace+Hopper的1:1配比?那下一代Grace+Blackwell也是1:1 ?
- 為什么每個GPU只能配搭500GB DDR容量?GPU這么貴,就不能一顆GPU搭兩顆CPU帶1TB DDR嗎?
- 為什么要配搭高價銷售?愛馬仕賣中國人就一定要配貨銷售嗎?
- 為什么不就用Nvlink?Nvlink C2C是900GB帶寬,也就x36Lane的Nvlink4罷了。
- 資源池化、池化、池化知道不?
嗯,你會說,Nvlink-C2C功耗低啊,號稱是PCIe的1/5啊,話是沒錯,可這省的功耗大致是多少?算一算啊,不到10W! 你明白了嗎?在一個700W功耗的GPU上,有一個技術省了10W,作為一種噱頭,高價賣給你,你是不是賺大了? ? 你已經回顧了Nvlink的整個歷史,你的心中應該有一個正確的答案,最佳的搭配,應該是IBM+Nvidia那種,讓CPU和GPU都支持Nvlink,然后通過NvSwitch應該做非2^N的Port數量,方便搭配,GPU和CPU基于NvSwitch做全交換。當前Nvlink-C2C所號稱的所有好處,DVM、Cache Coherence,都是能夠拿到的。 為什么不呢?我猜Nvidia收購ARM最終沒有成功,雖然魔改了ARM的NoC,但是想在ARM的Memory Model中加入Nvlink接口,水平不夠。 嗯,我上我可以的。^_^
這些大致是截至2023-06的Nvlink的歷史了,從最初的超算想要脫離PCIe的束縛為起點,到現在不僅僅自身不斷在前進,還不斷侵蝕周邊,向上打IB,向下吃Chiplet,都是可以載入人類計算機體系結構的歷史。 但這些大概率都不是其誕生的第一天就規劃好的,他更是像一個活物,隨著環境的變化和各種機緣巧合的事件觸發,不斷膨脹、進化、吞噬,螺旋上升,但天下并無長生不滅者,有生之年,一起扶階而上吧,希望我們可以看至終章吧。
編輯:黃飛
?














 工商網監
工商網監
評論