 電子發燒友App
電子發燒友App


近年來,大數據來勢洶洶,滲透到各行各業,帶來了一場翻天覆地的變革。讓人們越發認識到,比掌握龐大的數據信息更重要的是掌握對含有意義的數據進行專業化處理的技術。
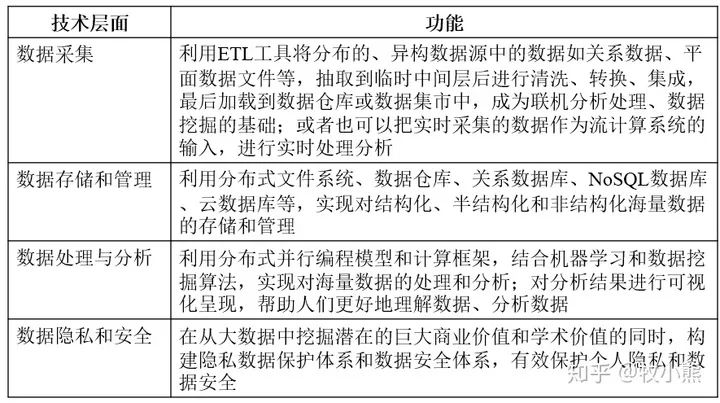
大數據關鍵技術涵蓋從數據存儲、處理、應用等多方面的技術,根據大數據的處理過程,可將其分為大數據采集、大數據預處理、大數據存儲及管理、大數據分析及挖掘等環節。
本文針對大數據的關鍵技術進行梳理,以饗讀者。
Part 1.大數據采集
數據采集是大數據生命周期的第一個環節,它通過RFID射頻數據、傳感器數據、社交網絡數據、移動互聯網數據等方式獲得各種類型的結構化、半結構化及非結構化的海量數據。由于可能有成千上萬的用戶同時進行并發訪問和操作,因此,必須采用專門針對大數據的采集方法,其主要包括以下三種:
A.數據庫采集
一些企業會使用傳統的關系型數據庫MySQL和Oracle等來存儲數據。談到比較多的工具有Sqoop和結構化數據庫間的ETL工具,當然當前對于開源的Kettle和Talend本身也集成了大數據集成內容,可以實現和hdfs,hbase和主流Nosq數據庫之間的數據同步和集成。
B.網絡數據采集
網絡數據采集主要是借助網絡爬蟲或網站公開API等方式,從網站上獲取數據信息的過程。通過這種途徑可將網絡上非結構化數據、半結構化數據從網頁中提取出來,并以結構化的方式將其存儲為統一的本地數據文件。
C.文件采集
對于文件的采集,談的比較多的還是flume進行實時的文件采集和處理,當然對于ELK(Elasticsearch、Logstash、Kibana三者的組合)雖然是處理日志,但是也有基于模板配置的完整增量實時文件采集實現。如果是僅僅是做日志的采集和分析,那么用ELK解決方案就完全夠用的。
Part 2.大數據預處理
數據的世界是龐大而復雜的,也會有殘缺的,有虛假的,有過時的。想要獲得高質量的分析挖掘結果,就必須在數據準備階段提高數據的質量。大數據預處理可以對采集到的原始數據進行清洗、填補、平滑、合并、規格化以及檢查一致性等,將那些雜亂無章的數據轉化為相對單一且便于處理的構型,為后期的數據分析奠定基礎。數據預處理主要包括:數據清理、數據集成、數據轉換以及數據規約四大部分。
A.數據清理
數據清理主要包含遺漏值處理(缺少感興趣的屬性)、噪音數據處理(數據中存在著錯誤、或偏離期望值的數據)、不一致數據處理。主要的清洗工具是ETL(Extraction/Transformation/Loading)和Potter’s Wheel。
遺漏數據可用全局常量、屬性均值、可能值填充或者直接忽略該數據等方法處理;噪音數據可用分箱(對原始數據進行分組,然后對每一組內的數據進行平滑處理)、聚類、計算機人工檢查和回歸等方法去除噪音;對于不一致數據則可進行手動更正。
B.數據集成
數據集成是指將多個數據源中的數據合并存放到一個一致的數據存儲庫中。這一過程著重要解決三個問題:模式匹配、數據冗余、數據值沖突檢測與處理。
來自多個數據集合的數據會因為命名的差異導致對應的實體名稱不同,通常涉及實體識別需要利用元數據來進行區分,對來源不同的實體進行匹配。數據冗余可能來源于數據屬性命名的不一致,在解決過程中對于數值屬性可以利用皮爾遜積矩Ra,b來衡量,絕對值越大表明兩者之間相關性越強。數據值沖突問題,主要表現為來源不同的統一實體具有不同的數據值。
C.數據變換
數據轉換就是處理抽取上來的數據中存在的不一致的過程。數據轉換一般包括兩類:
第一類,數據名稱及格式的統一,即數據粒度轉換、商務規則計算以及統一的命名、數據格式、計量單位等;第二類,數據倉庫中存在源數據庫中可能不存在的數據,因此需要進行字段的組合、分割或計算。數據轉換實際上還包含了數據清洗的工作,需要根據業務規則對異常數據進行清洗,保證后續分析結果的準確性。
D. 數據規約
數據歸約是指在盡可能保持數據原貌的前提下,最大限度地精簡數據量,主要包括:數據方聚集、維規約、數據壓縮、數值規約和概念分層等。數據規約技術可以用來得到數據集的規約表示,使得數據集變小,但同時仍然近于保持原數據的完整性。也就是說,在規約后的數據集上進行挖掘,依然能夠得到與使用原數據集近乎相同的分析結果。
Part 3.大數據存儲
大數據存儲與管理要用存儲器把采集到的數據存儲起來,建立相應的數據庫,以便管理和調用。大數據存儲技術路線最典型的共有三種:
A. MPP架構的新型數據庫集群
采用MPP架構的新型數據庫集群,重點面向行業大數據,采用Shared Nothing架構,通過列存儲、粗粒度索引等多項大數據處理技術,再結合MPP架構高效的分布式計算模式,完成對分析類應用的支撐,運行環境多為低成本 PC Server,具有高性能和高擴展性的特點,在企業分析類應用領域獲得極其廣泛的應用。這類MPP產品可以有效支撐PB級別的結構化數據分析,這是傳統數據庫技術無法勝任的。對于企業新一代的數據倉庫和結構化數據分析,目前最佳選擇是MPP數據庫。
B. 基于Hadoop的技術擴展和封裝
基于Hadoop的技術擴展和封裝,圍繞Hadoop衍生出相關的大數據技術,應對傳統關系型數據庫較難處理的數據和場景,例如針對非結構化數據的存儲和計算等,充分利用Hadoop開源的優勢,伴隨相關技術的不斷進步,其應用場景也將逐步擴大,目前最為典型的應用場景就是通過擴展和封裝 Hadoop來實現對互聯網大數據存儲、分析的支撐。這里面有幾十種NoSQL技術,也在進一步的細分。對于非結構、半結構化數據處理、復雜的ETL流程、復雜的數據挖掘和計算模型,Hadoop平臺更擅長。
C. 大數據一體機
這是一種專為大數據的分析處理而設計的軟、硬件結合的產品,由一組集成的服務器、存儲設備、操作系統、數據庫管理系統以及為數據查詢、處理、分析用途而預先安裝及優化的軟件組成,高性能大數據一體機具有良好的穩定性和縱向擴展性。
Part 4.大數據分析挖掘
數據的分析與挖掘主要目的是把隱藏在一大批看來雜亂無章的數據中的信息集中起來,進行萃取、提煉,以找出潛在有用的信息和所研究對象的內在規律的過程。主要從可視化分析、數據挖掘算法、預測性分析、語義引擎以及數據質量和數據管理五大方面進行著重分析。
A. 可視化分析
數據可視化主要是借助于圖形化手段,清晰有效地傳達與溝通信息。主要應用于海量數據關聯分析,由于所涉及到的信息比較分散、數據結構有可能不統一,借助功能強大的可視化數據分析平臺,可輔助人工操作將數據進行關聯分析,并做出完整的分析圖表,簡單明了、清晰直觀,更易于接受。
B. 數據挖掘算法
數據挖掘算法是根據數據創建數據挖掘模型的一組試探法和計算。為了創建該模型,算法將首先分析用戶提供的數據,針對特定類型的模式和趨勢進行查找。并使用分析結果定義用于創建挖掘模型的最佳參數,將這些參數應用于整個數據集,以便提取可行模式和詳細統計信息。
大數據分析的理論核心就是數據挖掘算法,數據挖掘的算法多種多樣,不同的算法基于不同的數據類型和格式會呈現出數據所具備的不同特點。各類統計方法都能深入數據內部,挖掘出數據的價值。
C. 預測性分析
大數據分析最重要的應用領域之一就是預測性分析,預測性分析結合了多種高級分析功能,包括特別統計分析、預測建模、數據挖掘、文本分析、實體分析、優化、實時評分、機器學習等,從而對未來,或其他不確定的事件進行預測。
從紛繁的數據中挖掘出其特點,可以幫助我們了解目前狀況以及確定下一步的行動方案,從依靠猜測進行決策轉變為依靠預測進行決策。它可幫助分析用戶的結構化和非結構化數據中的趨勢、模式和關系,運用這些指標來洞察預測將來事件,并作出相應的措施。
D. 語義引擎
語義引擎是是把已有的數據加上語義,可以把它想象成在現有結構化或者非結構化的數據庫上的一個語義疊加層。它語義技術最直接的應用,可以將人們從繁瑣的搜索條目中解放出來,讓用戶更快、更準確、更全面地獲得所需信息,提高用戶的互聯網體驗。
E. 數據質量管理
是指對數據從計劃、獲取、存儲、共享、維護、應用、消亡生命周期的每個階段里可能引發的各類數據質量問題,進行識別、度量、監控、預警等一系列管理活動,并通過改善和提高組織的管理水平使得數據質量獲得進一步提高。
對大數據進行有效分析的前提是必須要保證數據的質量,高質量的數據和有效的數據管理無論是在學術研究還是在商業應用領域都極其重要,各個領域都需要保證分析結果的真實性和價值性。










 工商網監
工商網監
評論