 電子發燒友App
電子發燒友App


縱觀傳統互聯網時代,如果用一個詞來總結和概括的話,“連接”這詞再合適不過了,傳統互聯網時代主要建立了三種連接:第一,人和信息的連接;第二,人和人的連接;第三,人與商品服務的連接。第一種連接成就了Google和百度這樣的互聯網巨頭;人和人的連接成就了Facebook和騰訊這樣的互聯網公司,人和商品服務的連接,成就了Amazon、阿里巴巴、京東這樣的巨頭。從這個意義上看,傳統互聯網最典型的特征就是連接。
過去3-4年,我們可以看到,互聯網其實發生很大變化,交互的設備已經從PC和智能手機延伸到更廣泛的智能設備。智能設備的快速發展正在改變著人類和設備的交互方式。不難看出,無論是智能設備的發展和普及,還是用戶的接受度都在快速增長,都促使人和設備之間交互方式的巨大改變,我們已經進入“交互時代“。
正在發生的變化
那么,交互時代,人和設備究竟如何通過自然語言對話展開對話交互的呢?首先,對話交互的特點,我認為主要有以下四點:
1、人和智能設備的交互一定是自然語言。因為對于人來說,自然語言是最自然的方式,也是門檻最低的方式。
2、人和設備的對話交互應該是雙向的。
3、人和設備的對話交互是多輪的。為了完成一個任務,比如定機票,這里會涉及多輪交互。
4、上下文的理解。這是對話交互和傳統的搜索引擎最大的不同之處,傳統搜索是關鍵詞,前后的關鍵詞是沒有任何關系的。對話交互實際上是要考慮到上下文,在當前的上下文理解這句話什么意思。
從連接到對話交互,一個本質的改變是什么?舉個例子,比如淘寶網首頁,拋開內容,其本質就是鏈接和按鈕。對于用戶來說,無論是點擊鏈接還是按鈕,他的行為完全是由產品經理定義好的和是完全確定的,所以它是一種受控、受限的行為,這種方式并不能確保好的用戶體驗。
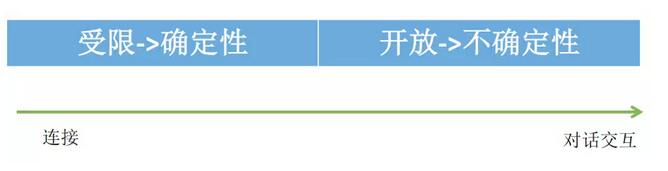
而對話交互,用戶可以說任何內容,天文、地理,包羅萬象。我認為這背后的本質改變就是從“確定性”轉變為“不確定性”。實際上,后面無論是算法還是交互設計,基本上都想辦法提高語言理解的確定性或者是降低交互設計的不確定性。
阿里巴巴在智能對話交互方向上的進展和實踐
下面介紹下阿里巴巴在智能對話交互方向的進展和實踐。先看對話交互邏輯的概況,傳統的對話交互大概會分以下幾個模塊,從云識別把語言轉成文字,語言理解是把用戶說的文字轉化成一種結構化的表示,對話管理是根據剛才那些結果來決定采取什么樣的合作。在語言設置這一塊就是根據action生成一句話,通過一種比較自然的方式把它讀出來。
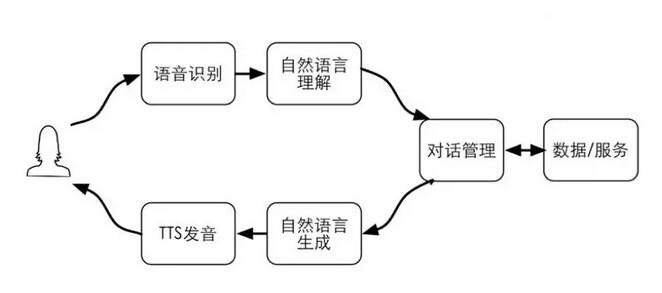
我認為現在人機交互和傳統的人機交互一個主要不同點就在于數據和服務。隨著互聯網的發展,數據和服務越來越豐富,那人機交互的目的是什么?歸根到底還是想獲取互聯網的信息和各種各樣的服務。
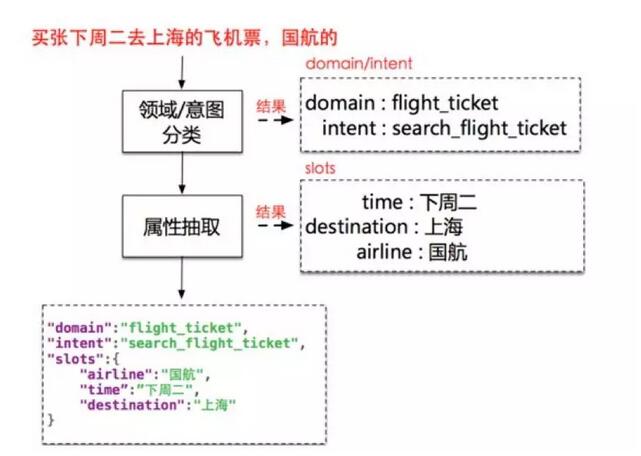
語言理解簡單來說就是把用戶說的話,轉換為一種結構化的語義表示,從方法上會分成兩個模塊:意圖的判定和屬性的抽取。
比如用戶說:“我要買一張下周去上海的飛機票,國航的“。第一個模塊就要返回理解,用戶的意圖是要買飛機票,第二,使用抽取模塊,要把這些關鍵的信息出處理出來,出發時間、目的地、航空公司,從而得到一個比較完整的結構化的表示。
那么,人機對話中的語言理解面臨哪些挑戰呢?我總結為四類:

表達的多樣性。同樣一個意圖,不同的用戶有不同的表達方式。那對于機器來說,雖然表達方式不一樣,但是意圖是一樣的,機器要能夠理解這件事情。
語言的歧義性。比如說,“我要去拉薩“,它是一首歌的名字。當用戶說:“我要去拉薩”的時候,他也可能是聽歌,也可能是買一張去拉薩的機票,也可能是買火車票,或者旅游。
語言理解的混亂性,因為用戶說話過程當中,比較自然隨意,語言理解要能夠捕獲住或者理解用戶的意圖。
?
上下文的理解。這是人機對話交互一個非常大的不同,它的理解要基于上下文。
在語言理解這一塊,我們把用戶語言的意圖理解抽象為一個分類問題,之后,就有一套相對標準的方法解決,比如CNN神經網絡、SVM分類器等等。阿里巴巴現在就是采用CNN神經網絡方法,并在詞的表示層面做了針對性的改進。機器要理解用戶的話的意思,背后一定要依賴于大量的知識。比如說,“大王叫我來巡山”是一首歌的名字,“愛探險的朵拉”是一個視頻,互聯網上百萬量級這樣開放領域的實體知識,并且每天都會有新的歌曲/視頻出現,如果沒有這樣大量的知識,機器是很難真的理解用戶的意圖的。那么,在詞的語義表示這塊,除了word embedding,還引入了基于知識的語義表示向量。
剛才提到了,用戶說的話實際上是比較隨意和自然的,那怎么樣讓這個模型有比較好的魯棒性來解決口語的隨意性問題呢?我們主要針對用戶標注的數據,通過算法自動加一些噪音,加噪之后(當然前提是不改變語義),基于這樣的數據再training模型,這樣處理之后模型就會有比較好的魯棒性了。
第二個模塊是屬性抽取,在這一塊,我們把它抽象為一個序列標注問題。這個問題,神經網絡也有比較成型的方法,我們現在也是用這種雙向LSTM,在上面有一層CRF解碼器,取得了不錯的效果,但是這背后更大的功夫來自于對數據的分析和加工。
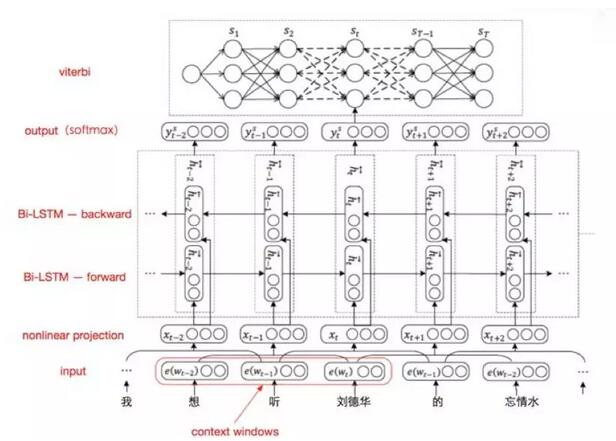
以上所述的人機對話語言理解最大的特色就是基于上下文的理解,什么是上下文?我們看一個例子,用戶說:“北京天氣怎么樣?”,回答說,北京的天氣今天溫度34度。接著用戶說“上海呢?”,在這里用戶的潛臺詞是指上海的天氣,所以要能夠理解用戶說的話需要根據上文意思來分析。針對這樣的場景,我們再對問題做了一個抽象,在上下文的情況下,這句話和上文有關還是無關,把它抽象為二分的分類問題,做了抽象和簡化以后,這個問題就有相對成型的解決方法了。
剛才介紹的是語言理解,下面我介紹下對話引擎。
對話引擎就是根據語言理解的這種結構化的語意表示以及對照到上下文,來決定采取什么樣的動作。這個動作我們把它分成幾類。
第一,用于語言生成的動作。
第二,服務動作。
第三,指導客戶端做操作的動作。
再看一個簡單的對話例子。用戶說:“我要去杭州,幫我訂一張火車票”,這個時候機器首先要理解用戶的意圖是買火車票,之后就要查知識庫,要買火車票依賴于時間和目的地,但是現在用戶只說目的地沒說時間,所以它就要發起一個詢問時間的動作,機器問了時間之后,用戶回答說“明天上午”。這個時候機器要理解用戶說的明天上午正好是在回答剛才用戶問的問題,這樣匹配了之后,基本上這個機器就把這個最關鍵的信息都收集回來了:時間和目的地,之后,機器就可以發起另外一個請求服務指令,然后把火車票的list給出來。這個時候用戶接著說:“我要第二個”。機器還要理解用戶說的第二個,就是指的要打開第二個鏈接,之后用戶說“我要購買”,這個時候機器要發起一個指令去支付。
綜上,對話交互,我會把它分成兩個階段:
第一階段,通過多輪對話交互,把用戶的需求表達完整,因為用戶信息很多,不可能一次表達完整,所以要通過對話搜集完整。第一階段得到結構化的信息,出發地、目的地、時間,有了這些信息之后,第二階段,請求服務。接著用還要去做選擇、確定、支付、購買等等后面的動作。
傳統的人機對話,包括現在市面上常見的人機對話,一般都是只在做第一階段的對話,第二階段的對話做得不多。
在對話交互這塊,阿里巴巴還是做了一些有特色的東西:
對話引擎之后,我們再看下我們的問答引擎和聊天引擎:
問答引擎:其實人和機器對話過程中,不僅僅是有task的對話還有問答和聊天,我們在問答引擎這塊,目前還是著力于基于知識圖譜的問答,因為基于知識圖譜的問答能夠比較精準地回答用戶的問題。
聊天引擎:我們設計了兩類聊天引擎。
對話交互平臺的開發策略
剛才語言理解引擎、對話引擎、聊天引擎再加上語音識別合成,形成了完整的一套系統和平臺,我們稱之為自然交互平臺。在這套平臺上,一端是連接著各種各樣的設備,另外一端是連接了各種各樣的服務,這樣用戶和設備的交互就能夠用比較自然的方式進行下去了。

值得一提的是,這樣的自然交互平臺在阿里巴巴已經有比較多的應用了。比如說在互聯網汽車對話交互,我們和合作伙伴設計開發了汽車前裝和汽車后裝場景的對話交互。在功能上,比如說像地圖、導航、路況,還有圍繞著娛樂類的音樂、有聲讀物。
在汽車場景下的對話交互,還和其他場景有非常多的不同。因為產品方希望當這個車在郊區網絡不好的時候,最需要導航的時候,你要能夠工作,所以我們的語音識別還有語言理解、對話引擎,就是在沒有網絡的情況下,要在端上能夠完全工作,這里面的挑戰也非常大。
現在正在把這樣的對話交互平臺開放出來,讓合作伙伴去開發自己場景的對話交互,所以我們正在開發面向開發者的平臺,這個平臺背后有端上的解決方案和云上的解決方案,端上包括聲音的采集、VAD、端上無網情況下完整的對話方案,服務端的能力會更加強大了。
在合作伙伴這塊有兩類:一類是面向設備的,比如說汽車、電視、音箱、機器人、智能玩具。另外一類就是類似于行業應用,比如說智能客服這樣的一個場景。
考察一個對話交互平臺的能力,其實第一需要看它背后沉淀和積累的技術,我們在這方面花了三年的時間去沉淀了一些公共場景的對話交互能力。比如像娛樂、出行、理財、美食,有了這樣的能力之后,當一個新的業務方接入的時候,就不需要再去開發了,直接調用就好。用戶只需要開發業務場景中特定的一些場景就可以,大大加快業務方開發對話交互的速度。
第二個能力就是提供足夠強的定制能力,這種能力我們在語言理解,用戶可以定制自己的時點、對話邏輯、聊天引擎、問答引擎,可以把自己積累的數據上傳上來,以及對語音識別的詞語定制,包括TTS聲音的定制等等。
智能對話交互生態的范式思考
過去3-4年,在人機對話領域,應該說,我們還是取得了長足的進步,這樣的進步來自于以聲音學習為代表的算法突破。這個算法的突破帶來語音識別大的改進。同時,另一方面,我們認為當前的對話交互和真正的用戶期望還是有明顯距離的,對話交互能覆蓋的領域比較受限的,大家如果是用智能云交互的產品,你發現翻來覆去就是那幾類,音樂、地圖、導航、講笑話等等,其次,有的服務能力還不夠好,所以對于未來,我們是走自主研發路線還是平臺路線呢?
第一類,自主研發。很多的創業公司或者是團隊基本上都是自主研發的,像蘋果公司它基本上就是自主研發的模式。
第二類,平臺模式。典型代表就是亞馬遜的Alexa,這個平臺的好處是它能夠發動開發者的力量快速地去擴展領域。
兩者各有利弊,所以如何把這兩者結合在一起,有沒有第三種模式。如果有,第三種模式應該具有哪些特點呢?我總結了下,大概有以下幾個特點:
第一,由于自然語言理解的門檻比較高的,門檻高指的是對于開發者來說,它比開發一個APP難多了,從無到有開發出來不難,但要做到效果好是非常難的。所以,語言理解引擎要自研。第二,對話邏輯要平臺化。對于對話交互,因為它和業務比較緊,每個業務方有自己特殊的邏輯,通過平臺化比較合適,讓平臺上的開發者針對各自場景的需求和交互過程來開發對話。第三,需要建立一套評測體系,只有符合這個評測體系的,才能引入平臺當中。第四,需要商業化的機制,能夠讓開發者有動力去開發更多的以及體驗更好的交互能力。
如果這幾點能夠做到,我們稱之為第三種范式,這個平臺能夠相對快速地,并且開發的能力體驗是有效果保證的。這樣它開放給用戶的時候,無論是對B用戶還是C用戶,可以有更多的價值。
總結
最后,總結下我們對于研發對話交互機器人的幾點思考和體會:
堅持用戶體驗為先。這個話說起來很容易,但是我也知道,很多團隊不是以用戶為先的,是以投資者為先的。
降低產品和交互設計的不確定性。如上所說,對話交互最大的問題是不確定性,在產品的交互上,我們要想辦法把這種不確定性盡量降得低一點。
打造語言理解的魯棒性和領域擴展性。語言的理解能力盡量做到魯棒性,才能夠比較好的可擴展。
打造讓機器持續學習能力。對話交互我認為非常重要的一點就是怎么樣能夠讓機器持續不斷地學習。
打造數據閉環。要能夠快速地達到數字閉環,當然這個閉環當中要把數據的效能充分調動起來,結合更多數據的服務。
作者簡介:孫健,博士,阿里巴巴iDST 自然語言理解和人機對話負責人,資深專家。











 工商網監
工商網監
評論