 電子發燒友App
電子發燒友App


中文題目:基于邊界點優化和多步路徑規劃的機器人自主探索
作者:Baofu Fang ;Jianfeng Ding ; Zaijun Wang
機器人對未知環境的自主探索是機器人智能化的關鍵技術。為了提高搜索效率,作者提出了一種基于邊界點優化和多步路徑規劃的搜索策略。他們主要對邊界點優化、邊界點選擇、路徑規劃三個方面對路徑規劃算法進行改進。在邊界點優化部分,提出了一種隨機邊界點優化(RFPO)算法,選擇評價值最高的邊界點作為目標邊界點。綜合考慮信息增益、導航成本和機器人定位精度,來確定邊界點的評價函數。在路徑規劃部分,提出了一個多步探索策略。沒有直接規劃從機器人當前位置到目標邊界點的全局路徑,而是設置了局部探索路徑步長。當機器人的運動距離達到局部探索路徑步長時,重新選擇當前最優邊界點進行路徑規劃,以減少機器人走一些重復路徑的可能性。最后,通過相關實驗驗證了該策略的有效性。
1 前言
機器人自主探索是機器人領域的一個重要研究課題。主要目標是讓機器人在有限時間且無需人工干預的情況下,獲得最完整、最準確的環境地圖。許多現有的地圖探索策略都是基于邊界,邊界定義為未知空間與已知空間的分界線。基于邊界的探索策略的思想是引導機器人到未知區域完成探索任務,因此自主探索任務一般分為三個步驟:生成邊界點、選擇評價值最高的邊界點、規劃前往所選邊界點的路徑。
邊界點的生成以基于邊界的探索策略為前提。在現有的研究中,常見地邊界點生成算法有:
基于數字圖像處理的邊緣檢測和區域提取技術:為了提取邊界邊緣,必須對整個地圖進行處理,隨著地圖的擴展,處理它將消耗越來越多的計算資源。
Keidar和Kaminka后來提出了一種只處理新的激光讀取數據的邊界檢測算法,加快了計算速度,降低了計算資源的消耗。
快速探索隨機樹(rapid-exploration Random Tree, RRT)算法:由于RRT算法的隨機性,生成的邊界點分布不均勻。
基于廣度優先搜索(BFS)的方法:這種方法簡單便捷,不重不漏,但在大地圖環境下,相對于其他算法可能計算速度稍慢
目標邊界點的選擇是有效探索的關鍵。以邊界為基礎的戰略是由Yamauchi首先提出的。所使用的探索策略是識別當前地圖中的所有邊界區域,然后驅動機器人前往最近的邊界點。這種方法對于探索任務有兩個缺點。首先,它平等對待所有邊界。其次,它僅限于一個信息來源:尋找新邊界區域。因此很多研究者提出了多種不同的邊界點選擇算法,來改善這一情況。這篇文章是綜合考慮信息增益、導航成本和機器人定位精度,來確定邊界點的評價函數。
最后是機器人的路徑規劃部分,對于機器人自主探索中路徑規劃的研究已經存在很多高效的算法:
基于A*的路徑規劃算法
基于RRT算法生成機器人搜索路徑的算法
帶有信息論目標函數的部分可觀察馬爾可夫決策過程(POMDP)
基于遺傳算法(GA)的路徑規劃方法
為傳統的基于邊界的探測策增加一個概率決策步驟,以決定在計劃路徑上進一步移動到下一個傳感位置是否可取。
2 最優邊界點提取
2.1邊界點的生成
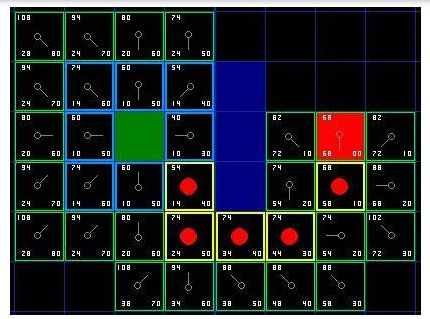
文中采用ROS平臺下常見的SLAM算法--GMapping構建二維占用網格圖,然后使用RRT算法在地圖中生成邊界點,如果新生成的點位于未知區域,則認為該點為邊界點。它會被標記在地圖上,然后我們停止這棵樹的生長。將當前機器人的位置作為新的根節點,我們構建一個新的快速探索隨機樹來生成邊界點。邊界點生成示例如下圖所示。
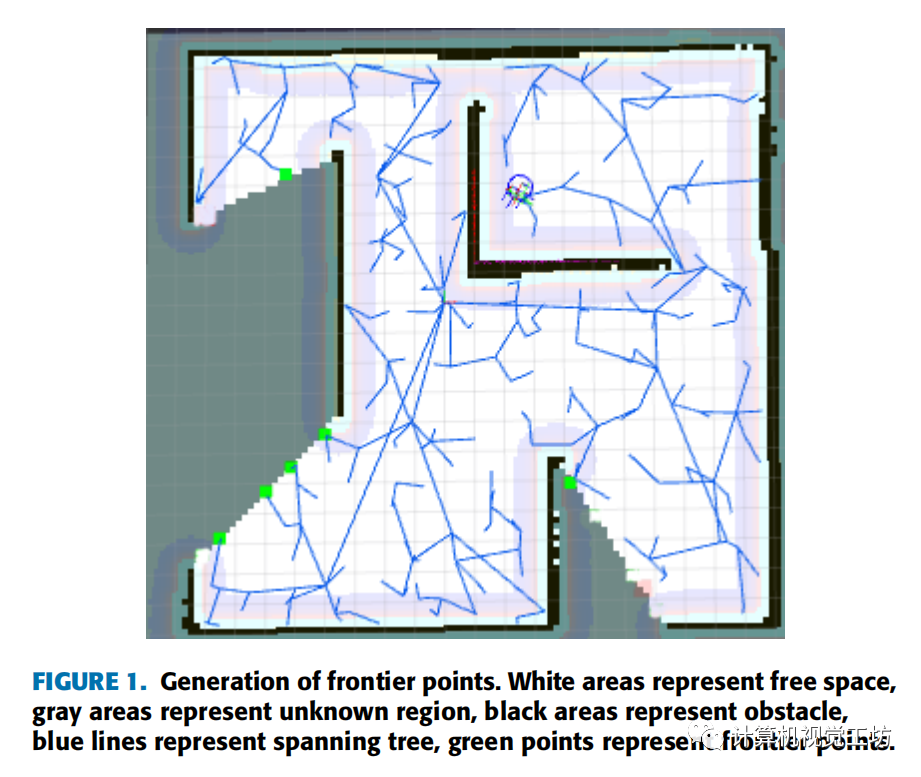
2.2邊界點評價函數
文章從邊界點的信息增益、導航成本和機器人定位精度三個方面對邊界點進行評估。
信息增益被定義為對于一個給定邊界點預期被探索的未知區域面積。本文采用直接測量目標邊界點可見區域內未檢測到的空間大小的方法計算信息增益。以邊界點為圓心,以激光雷達探測距離為半徑形成圓。邊界點檢測圈如下圖所示。通過計算圓圈中未知單元格的數量來量化信息增益。
導航成本定義為機器人到達邊界點的預期距離,使用機器人當前位置到目標邊界點的歐氏距離來表示。
在目標邊界點的探測范圍內,如果能檢測到更多的直線特征或其他特征(如斷點、拐角、折線),機器人就能更準確地定位自己。文章用邊界點檢測圈內障礙物的面積來表示定位精度。通過計算圓圈中被占用的單元數來量化。邊界點評價函數定義如下所示:
其中α、β、γ分別為信息增益、導航成本和障礙物面積的權重。這些權重用于調整不同因素的重要性,可根據不同的任務和環境進行設置。如果探索任務要求盡快完成探索,則增加α,降低γ;如果探索任務更注重地圖的準確性,則減少α,增加γ。β通常取1表示單位導航成本下的增益值。利用邊界點評價函數對所有邊界點進行評價。選取值最大的點作為目標邊界點。
PS:在計算導航成本時,如果環境地圖過于復雜,可以選擇使用A*規劃出的路徑長度作為導航成本項,但會造成過大的資源計算消耗;另外,作者提出的這種計算模型是比較合理的,導航成本在分母上,也就是說距離越大得分越低,信息增益和障礙物面積在分子上,機器人在選擇目標點時,肯定傾向于選擇信息增益高、導航精度高的目標點。
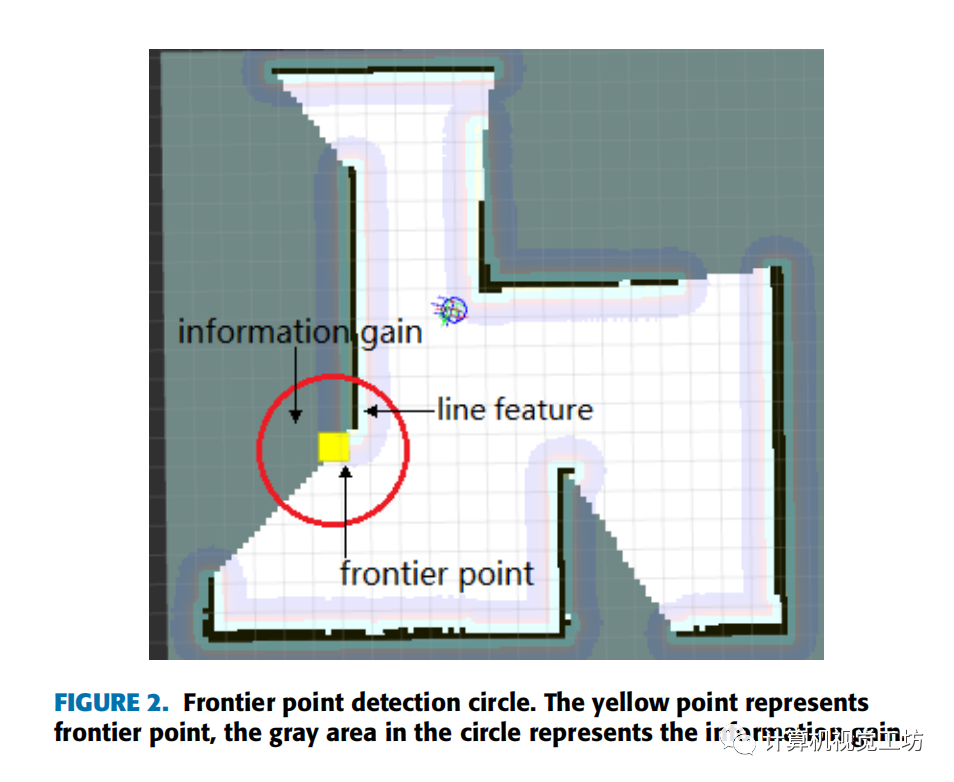
2.3隨機邊界點優化算法
由于邊界點的生成部分始終運行在整個探測過程中,因此隨著探測任務的執行,將得到許多邊界點。然而,由于RRT算法的隨機性,這些邊界點的分布是不均勻的。因此,需要對生成的邊界點進行優化。文中借鑒GSO算法的思想,提出RFPO算法。GSO算法是一種新型的仿生群體智能優化算法。它模擬了高亮度螢火蟲會吸引低亮度螢火蟲向其移動的自然現象,使所有螢火蟲集中在一個更好的位置,從而實現問題的優化。在RFPO算法中,將每個邊界點視為一只螢火蟲,并將邊界點評價函數的值E作為其絕對亮度值L:
螢火蟲會被絕對亮度值更大的螢火蟲所吸引,并向其移動。這種吸引力的大小由螢火蟲對螢火蟲的相對亮度值決定,螢火蟲在螢火蟲所在位置的亮度強度定義為螢火蟲對螢火蟲的相對亮度,相對亮度值越大,吸引力越大。然后對相對亮度進行建模。對于每個邊界點,都有一個感知半徑。它的值應根據感知傳感器的范圍來設置。在這個范圍內,每一個邊界點都會找到絕對亮度值大于自己的其他邊界點,形成自己的鄰域集。在鄰域集中使用輪盤賭的方法,選擇下一個要移動的目標點。
PS:這里的建模過程不是文章主要內容,就不過多展開,感興趣可以在原文查看詳細推導過程。
3 多步探索策略
采用多步探索的原因:在機器人運動的過程中,會產生一些新的邊界點,一些舊的邊界點會失效,而新生成的邊界點可能會優于當前的最優目標邊界點。這可能會導致機器人選擇一些重復的路徑。
文中解決方法:定義了一個局部探索路徑步長。每次當機器人的運動距離達到步長時,就清除無效點,并對所有剩余的邊界點進行重新優化和重新選擇。在每個局部探索路徑步長內,采用動態窗口法進行機器人避障局部路徑規劃。
PS:動態窗口法是ROS中常見地局部路徑規劃方法,主要思想是在速度空間中進行采樣,生成下一時間步的模擬軌跡,然后根據評估函數選擇得分最高的路徑,驅動機器人移動。
如下圖所示,黃色點為目標邊界點。作者在不同的速度集上模擬了許多軌跡。根據他們定義的軌跡評價函數,選取得分最高的軌跡(下圖中用紅色標記的路徑)。可以看出,機器人執行紅色軌跡可以快速到達目標邊界點。同時,軌跡與墻體有一定的安全距離,墻體邊界可以幫助機器人更準確地定位自身。
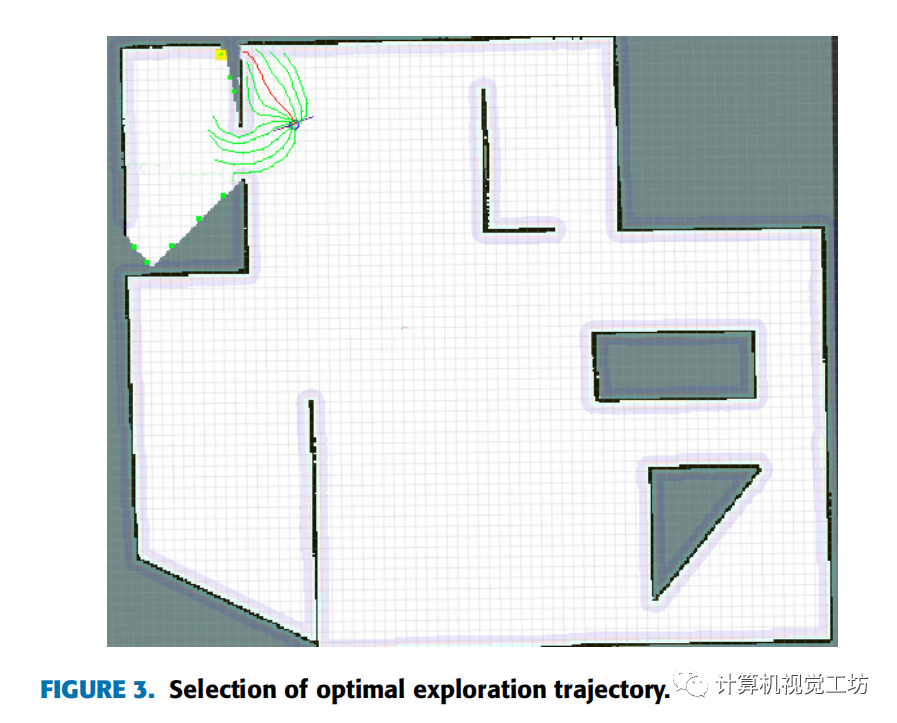
4 實驗與結果
4.1 實驗設置
通過仿真地圖和真實地圖對所提出策略的性能進行了實驗驗證,并與其他策略進行了比較。所有用于比較的策略都是在運行Ubuntu 14.04的Intel core i7 3.60GHz處理器和8GB RAM的計算機上使用ROS庫在c++中開發為ROS組件。
文章實驗參數表如下:
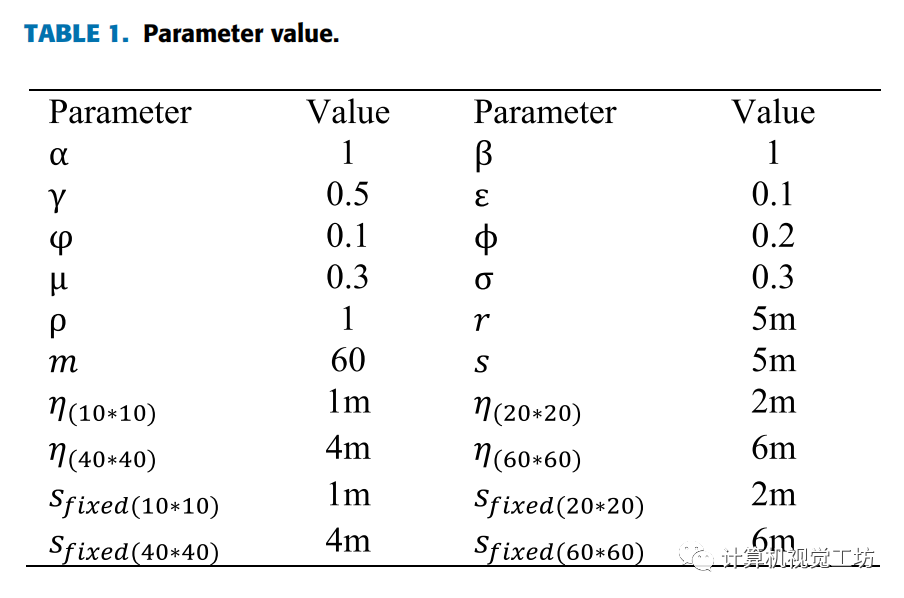
對于仿真環境,我們使用Gazebo模擬器構建一個封閉空間,如下圖4(a)所示。考慮到地圖尺寸變化的影響,使用了不同的地圖尺寸(2020m, 4040m, 6060m)。機器人的半徑為0.2m,激光傳感器的范圍設置為10m。圖4(c)為在2020m的模擬環境中建立的二維占用網格圖。
在真實環境中,作者利用擋板構建了一個10m * 10m的空間,如下圖4(b)所示。實驗中使用的移動機器人平臺為EAIBOT Dashgo-D1。它配備了一個Hokuyo UST-10LX 2D激光傳感器(10米的檢測范圍和270°視野)。圖4(d)為在真實環境中構建的二維占用網格圖。

4.2 邊界點優化結果
如下圖5(a)所示。由于RRT算法的隨機性,邊界點的位置都是隨機的。可以看出,有的邊界有很多邊界點,有的邊界只有很少的邊界點。此外,在地圖的各個邊界上,邊界點的分布也不均勻。圖5(b)是用文中提出的算法生成的邊界點。優化后邊界點數量大大減少,各邊界上的邊界點分布基本均勻。黃色點是根據定義的邊界點評價函數計算出的當前情況下的最優邊界點。

4.3 多步探索策略的結果
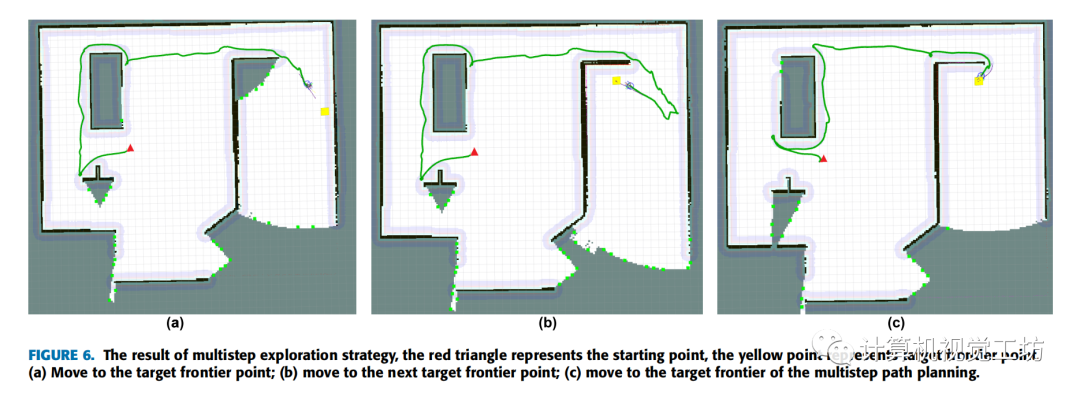
如圖6(a)和圖6(b)所示,在傳統的全局路徑規劃策略下,機器人直接規劃從當前位置到目標邊界點的路徑,并搜索下一個目標邊界點,直到到達前一個目標邊界點。
在多步路徑規劃策略中,每當機器人的運動距離達到確定的局部探索路徑步長時,都會重新計算并重新選擇最優邊界點。從下面的圖6(c)可以看出,在機器人到達圖6(a)中的目標邊界點之前,當前的最優邊界點已經發生了變化。因此,機器人已經規劃了一條新的路徑。結果是圖6(c)的路徑長度明顯短于圖6(a)和圖6(b)。
4.4 與其他策略的比較
文中總共進行了200組實驗,將提出的策略與其他四種策略進行比較。策略1的思想是隨機選擇邊界點進行探索,稱之為RANDOM。策略2的思想是選擇離機器人最近的邊界點,用NEAREST來表示它。策略3采用了貪婪算法的思想,因此將其記為GREEDY。策略4是用UMARI來描述。本文中提出的策略稱為RFPO。為了比較不同地圖尺寸對探索策略的影響,作者使用了4張不同尺寸的地圖進行實驗(一張真實地圖和3張不同尺寸的模擬地圖)。每張地圖都要進行50組探索作業。這50次探索分為5組,每組代表一種探索策略。在40*40 m的模擬地圖中,對于每種策略,從10次探索運行中選擇一個實驗結果來顯示機器人的探索軌跡。結果如圖7所示。
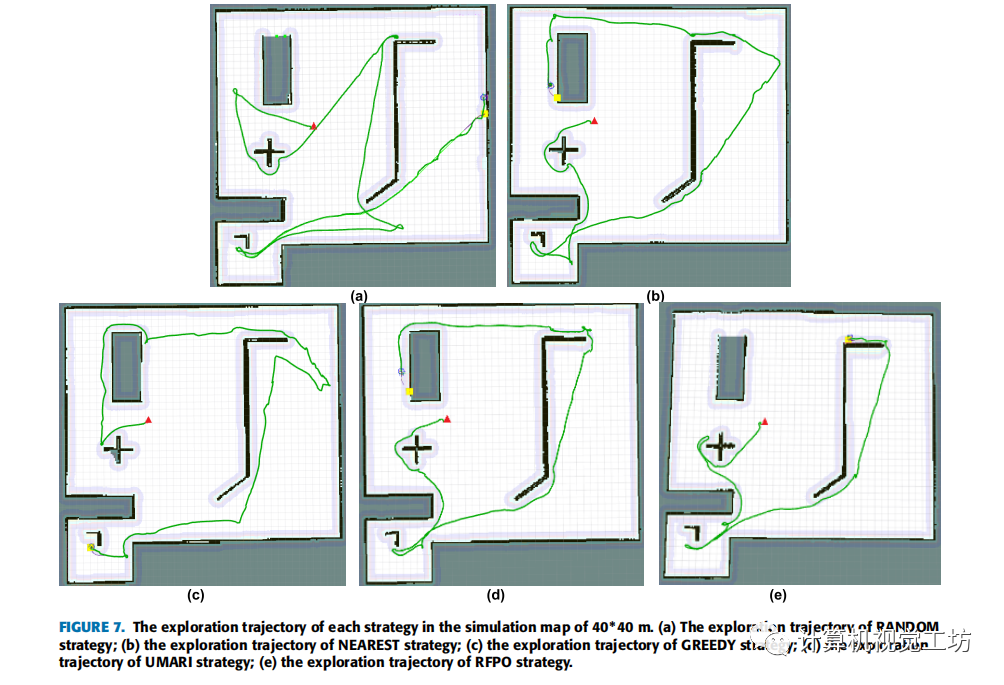
圖8為四種不同地圖中不同探索策略探索結束時的探索時間,圖9為四種不同地圖中不同探索策略探索結束時的探索距離。
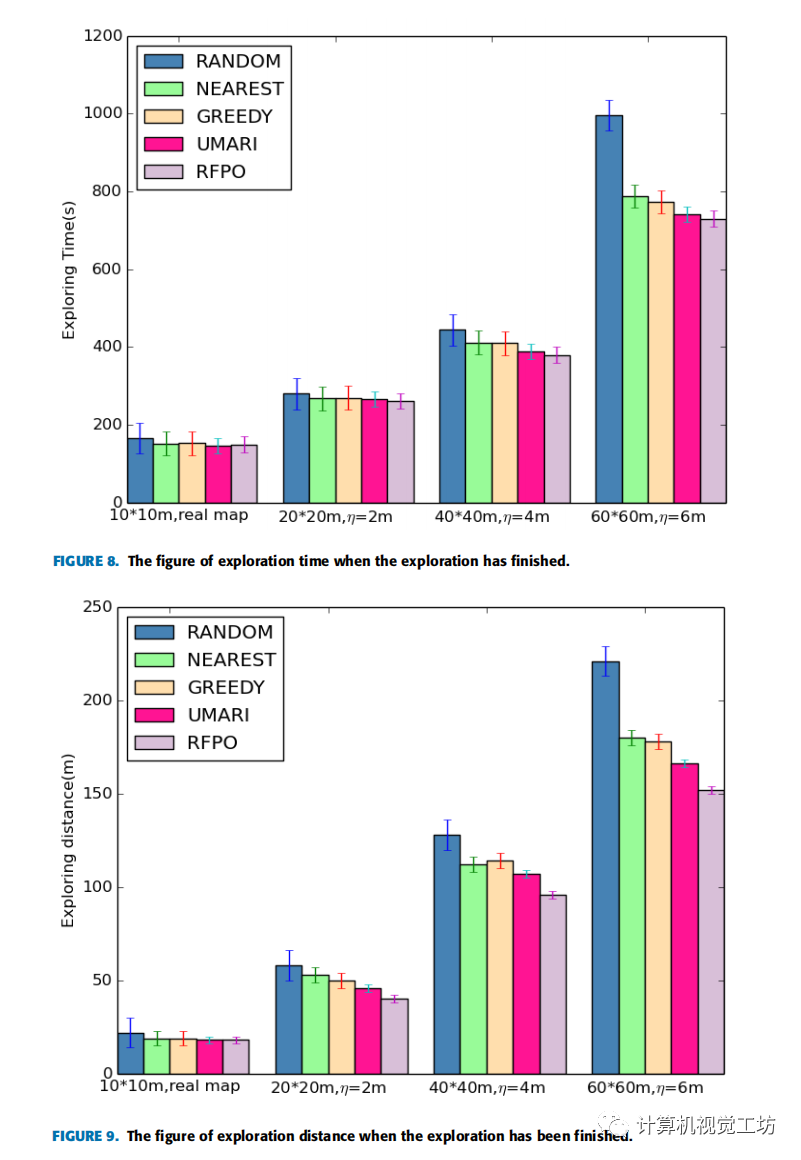
分析:從圖中可以看出,地圖的尺寸越大,不同策略之間探索效率的差異就越明顯。在60*60m的模擬地圖上,文中提出的策略與其他四種策略相比,平均探索時間分別減少了26.71%、7.36%、5.56%、1.62%,平均探索距離分別減少了31.22%、15.56%、14.61%、8.43%。
對于RANDOM策略來說,由于每次的目標邊界點都是隨機選擇的,機器人會走很多重復的路線,所以探測時間和探測距離都會增加。
而NEAREST策略和GREEDY策略會導致搜索變成局部最優問題,影響搜索的效率。
UMARI的策略直接規劃了機器人從當前位置到探測目標點的路徑,這可能會導致圖6中的問題。
實驗結果表明,無論是與探測時間相比,還是與探測距離相比,文中提出的探測策略的效果都優于其他策略,證明了所提出策略的有效性。
5 總結
本文提出了一種基于邊界點優化和多步路徑規劃的機器人自主探索策略。該策略可以驅動機器人探索未知環境,并在無需人工干預的情況下高效地構建相應的二維占用柵格地圖。在這個探索策略中,作者使用RRT算法來生成邊界點,并提出RFPO算法來優化這些邊界點。然后定義了邊界點評價函數,選取當前最優邊界點進行探索。在路徑規劃部分,設置了一個局部探索路徑步長,當機器人的運動距離達到局部探索路徑步長時,重新選擇目標邊界點進行探索,以減少機器人走一些重復路徑的可能性。最后通過實驗,驗證了所提策略的有效性。
未來改進:目前只使用里程計數據結合激光傳感器數據來構建二維占用網格地圖,地圖中包含的信息相對較少。
可以將視覺傳感器數據融合到自主探索中,視覺傳感器數據的優點是可以獲得更多的環境信息,這些數據可以被融合在一起,為以后的導航任務和其他相關工作構建具有更豐富信息的地圖。
此外,可以嘗試協調多個機器人進行高效探索。
編輯:黃飛












 工商網監
工商網監
評論