 電子發(fā)燒友App
電子發(fā)燒友App


本文重點(diǎn)介紹道路環(huán)境感知對(duì)移動(dòng)機(jī)器人導(dǎo)航的重要性以及相關(guān)技術(shù)。
01 ? 道路三維幾何模型構(gòu)建
首先,三維幾何模型背后的機(jī)理是多視圖幾何學(xué),多視圖幾何學(xué)是指想要得到對(duì)應(yīng)模型的三維幾何架構(gòu),則必須要用相機(jī)在兩個(gè)不同的位置進(jìn)行拍照。如圖1,可以通過利用兩個(gè)相機(jī)在不同位置拍照的方式,去得到三維幾何模型;同樣,也可以利用單個(gè)相機(jī)不斷的移動(dòng),然后不斷的進(jìn)行三維的重建。
主要原理是:利用左相機(jī)平面和右相機(jī)平面去計(jì)算R、T。通常做slam的時(shí)候,先需要對(duì)圖像中的對(duì)應(yīng)點(diǎn)進(jìn)行匹配,然后利用至少八個(gè)對(duì)應(yīng)點(diǎn)去利用SVD來(lái)求解出外參矩陣,再利用這個(gè)外參矩陣進(jìn)行分解得到R、T,得到兩個(gè)相機(jī)的相對(duì)位姿之后,就可以得到對(duì)應(yīng)三維點(diǎn)的坐標(biāo)。
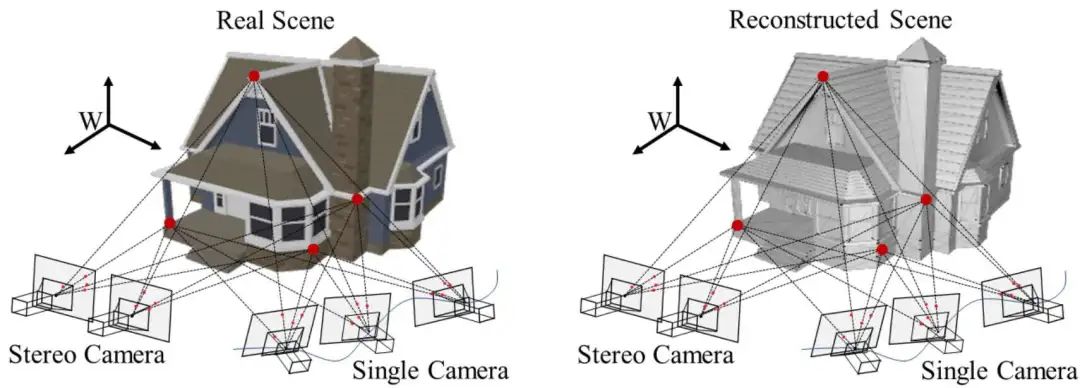
圖1 深度估計(jì)
對(duì)于雙目來(lái)講,需要先對(duì)圖像的平面進(jìn)行一定的變換,因?yàn)槿绻莿倓偟姆椒ǎ谧鎏卣鼽c(diǎn)匹配的時(shí)候,往往是一個(gè)二維匹配的問題,計(jì)算量是比較大。
因此對(duì)于雙目相機(jī)需要變換為圖2中紅色的平面,將對(duì)極點(diǎn)拉到無(wú)限遠(yuǎn)之后,對(duì)應(yīng)點(diǎn)的匹配則變成了一維搜索問題,即從左相機(jī)選擇一個(gè)點(diǎn),然后要在右相機(jī)去選擇對(duì)應(yīng)點(diǎn)的時(shí)候,只需要在同一行上進(jìn)行搜索。
利用雙目去做深度估計(jì)的好處在于通過相機(jī)標(biāo)定可以得到固定的baseline,之后,進(jìn)行一維搜索可以節(jié)省大量的計(jì)算量,得到稠密的視差圖,從而對(duì)應(yīng)得到稠密的深度圖,最后得到稠密的三維點(diǎn)位。
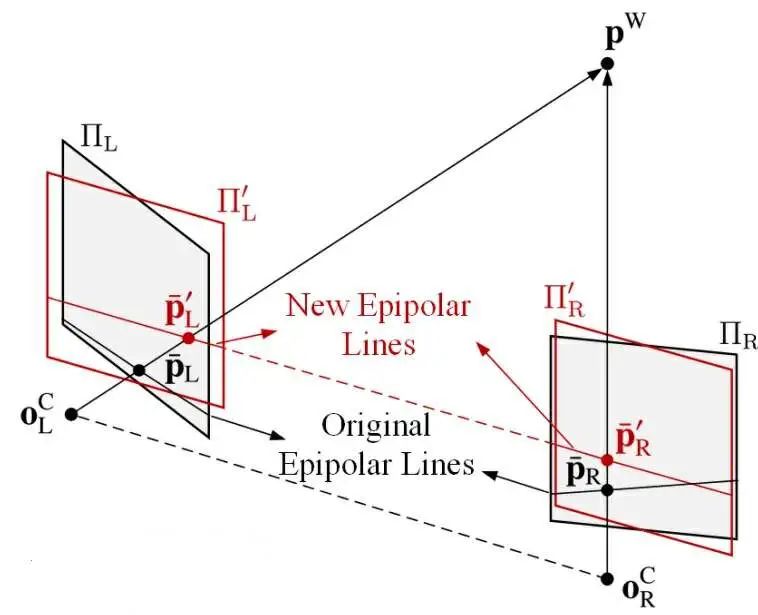
圖2 立體匹配
隨著深度學(xué)習(xí)的發(fā)展,現(xiàn)在有很多網(wǎng)絡(luò)是基于一些深度學(xué)習(xí)的網(wǎng)絡(luò)去得到視差圖,但現(xiàn)在深度學(xué)習(xí)的方法大多是基于數(shù)據(jù)驅(qū)動(dòng)。數(shù)據(jù)驅(qū)動(dòng)存在一個(gè)很大問題是有時(shí)并不知道ground-truth是多少。
當(dāng)然現(xiàn)在是可以利用Lidar進(jìn)行同步,之后把雷達(dá)點(diǎn)云投到雙目相機(jī)上,然后利用深度進(jìn)行反推視差。這種方案雖然可以得到真值,但它的真值受限于相機(jī)和激光雷達(dá)標(biāo)定的精度。
基于此,探索了很多自監(jiān)督方式,從而設(shè)計(jì)了PVStereo結(jié)構(gòu),如圖3所示。
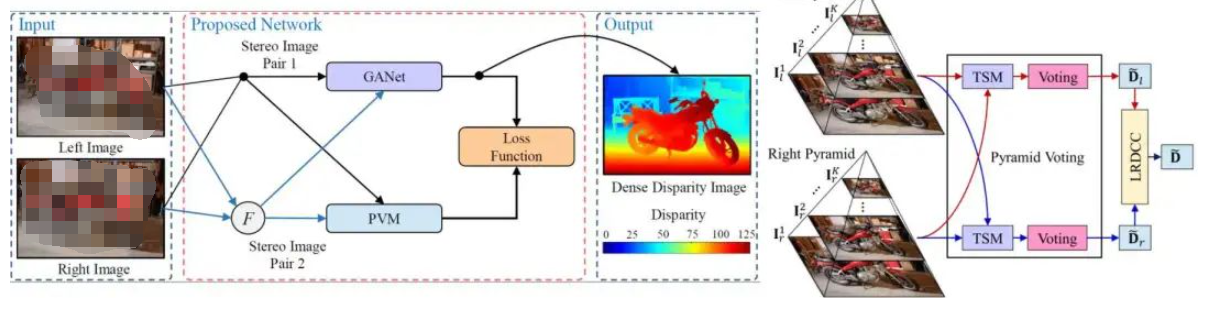
圖3 PVStereo結(jié)構(gòu)
可以看到是利用了不同層級(jí)的圖像進(jìn)行一個(gè)傳統(tǒng)方法的匹配,當(dāng)時(shí)假設(shè)是對(duì)應(yīng)圖像點(diǎn)的視差可靠,那不管是它對(duì)應(yīng)的不同的pyramid都是可靠的,這跟深度學(xué)習(xí)的假設(shè)是一致的。然后,利用傳統(tǒng)的pyramid voting可以得到一個(gè)相對(duì)比較準(zhǔn)確,但比較稀疏一點(diǎn)的視差圖。?
受到了KT數(shù)據(jù)集的啟發(fā),在想能夠用一些稀疏的真值去訓(xùn)練出來(lái)一個(gè)比較好的網(wǎng)絡(luò),所以利用傳統(tǒng)方法去猜測(cè)視差的真值,避免了利用真值去訓(xùn)練網(wǎng)絡(luò)的過程。
基于循環(huán)神經(jīng)網(wǎng)絡(luò)的方法提出了OptStereo網(wǎng)絡(luò),如圖4所示。首先構(gòu)建多尺度成本量,然后采用循環(huán)單元迭代更新高分辨率的視差估計(jì)。這不僅可以避免從粗到細(xì)范式中的誤差累積問題,而且由于其簡(jiǎn)單而高效,因此可以在準(zhǔn)確性和效率之間實(shí)現(xiàn)很大的權(quán)衡。
實(shí)驗(yàn)結(jié)果相對(duì)來(lái)說(shuō)還是比較魯棒的,但是像一些場(chǎng)景會(huì)出現(xiàn)離群值。
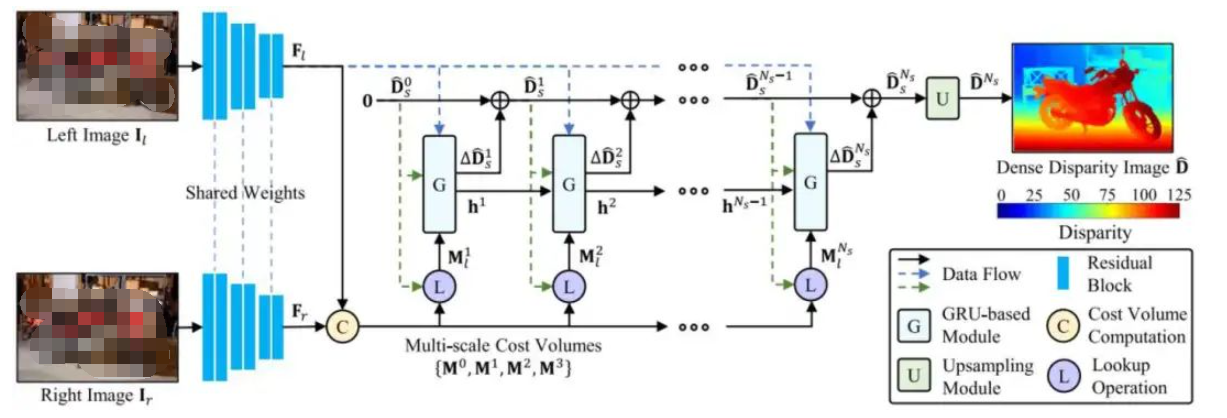
圖4 視差圖生成
既然ground-truth比較難獲得,一種方法是利用傳統(tǒng)方法去猜一些真值來(lái)作為假的ground-truth,然后去訓(xùn)練網(wǎng)絡(luò);另外一種方式是基于無(wú)監(jiān)督的方式進(jìn)行訓(xùn)練。于是基于之前的工作,提出了CoT-Stereo,如圖5所示。
利用兩個(gè)不同的網(wǎng)絡(luò),一個(gè)network a和network b,這兩個(gè)網(wǎng)絡(luò)類似于去模擬了兩個(gè)學(xué)生,且初始化不同,但網(wǎng)絡(luò)結(jié)構(gòu)完全相同。在初始化時(shí), network a和network b掌握了不同的知識(shí),然后a再把自己認(rèn)為對(duì)的知識(shí)分享給b,b也同理分享給a。通過這樣的方式不斷的去進(jìn)行互相的學(xué)習(xí)和進(jìn)化。
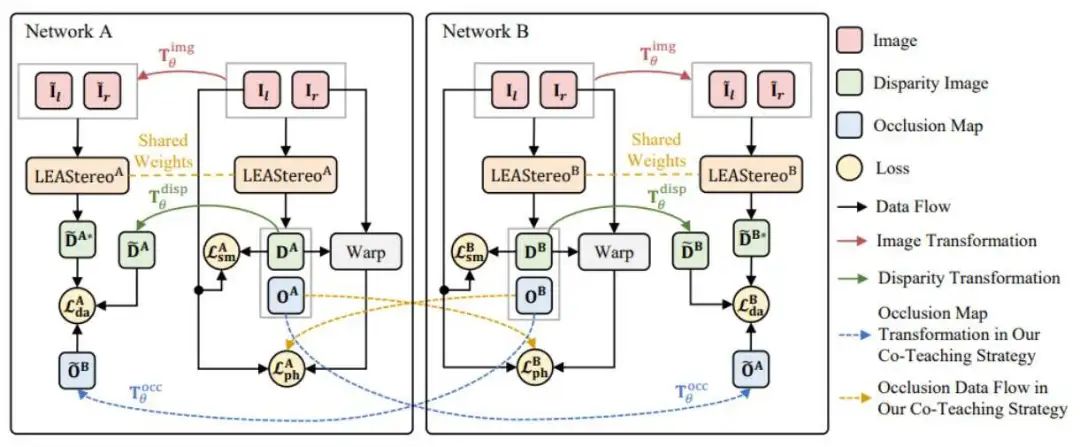
圖5 CoT-Stereo架構(gòu)
無(wú)監(jiān)督雙目估計(jì)的結(jié)果也同許多方法進(jìn)行了比較,雖然ground-truth結(jié)果無(wú)法與全監(jiān)督的方法做媲美,但是該網(wǎng)絡(luò)整體的influence time和對(duì)應(yīng)的L平衡比較好,如圖6所示。
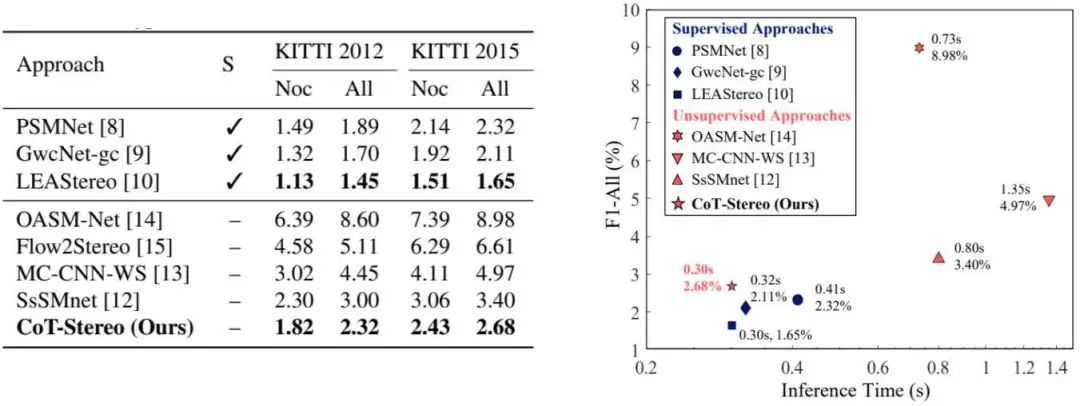
圖6 實(shí)驗(yàn)結(jié)果
如何利用深度或視差變成法向量信息?在做一些感知任務(wù)時(shí),發(fā)現(xiàn)有的時(shí)候深度并不是一個(gè)非常好用的信息,而如果用RGB-D信息進(jìn)行訓(xùn)練的時(shí)候,則存在另外的問題。那如果使用法向量信息,不管近還是遠(yuǎn),最后給到的信息都是差不多,且法向量信息,對(duì)于很多任務(wù)是有一些額外的輔助。
調(diào)研發(fā)現(xiàn)并沒有太多的工作或是幾乎沒有工作去研究如何把深度圖或視差圖快速的變成法向量信息,于是這里研究了此類工作,初衷在于能夠在幾乎不占用任何計(jì)算資源的情況下,進(jìn)行深度到法向量的translation,大概框架如圖7所示。
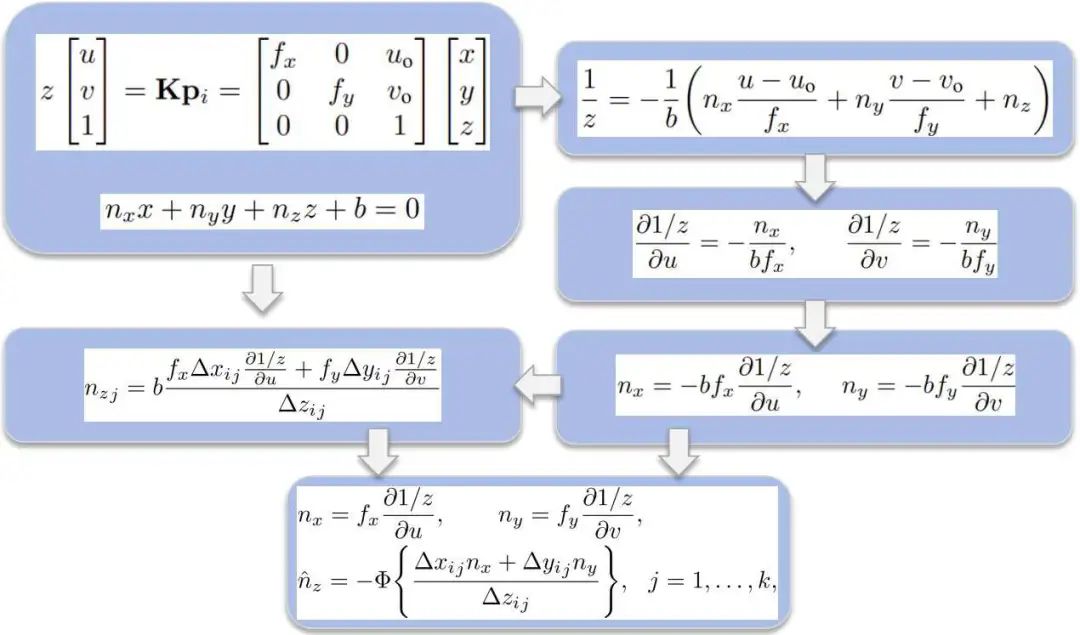
圖7 Three-Filters-to-Normal框架
可以看到這是最基本的一個(gè)透視變換過程,即把一個(gè)3D坐標(biāo)利用相機(jī)的內(nèi)參,可以變成一個(gè)圖像坐標(biāo)。如果已知局部點(diǎn)滿足平面特性方程,可以很驚奇的發(fā)現(xiàn),如果把這兩個(gè)方程聯(lián)立,就可以得到Z分之一這樣的公式表達(dá)。
通過一系列的計(jì)算后,可以看到1/V對(duì)u方向的偏導(dǎo)在圖像處理領(lǐng)域很容易處理,1/V對(duì)應(yīng)視差,但跟視差是差一個(gè)倍數(shù),因此,若對(duì)1/V求偏導(dǎo),就是對(duì)視差圖進(jìn)行卷積。所以,其實(shí)法向量估計(jì)的方法不需要像傳統(tǒng)方法一樣,將深度圖轉(zhuǎn)化為三維點(diǎn)云,再進(jìn)行KNN,再進(jìn)行局部平面擬合,這個(gè)過程非常復(fù)雜。但這個(gè)方法可以很簡(jiǎn)單的通過已知Z或是已知深度圖或視差圖轉(zhuǎn)化得到法向量。
利用這個(gè)方法去做了一系列的相關(guān)實(shí)驗(yàn),結(jié)果如圖8所示。和當(dāng)時(shí)最主流的方法進(jìn)行了比較,發(fā)現(xiàn)本文方法在速度和精度的平衡非常好,雖然精度可能稍微差一些,但是已經(jīng)超越了幾乎大多數(shù)的方法,速度使用C++帶單核CPU可以達(dá)到260Hz,如果是CUDA則可以達(dá)到21kHz,對(duì)應(yīng)圖像分辨率為640 乘480。
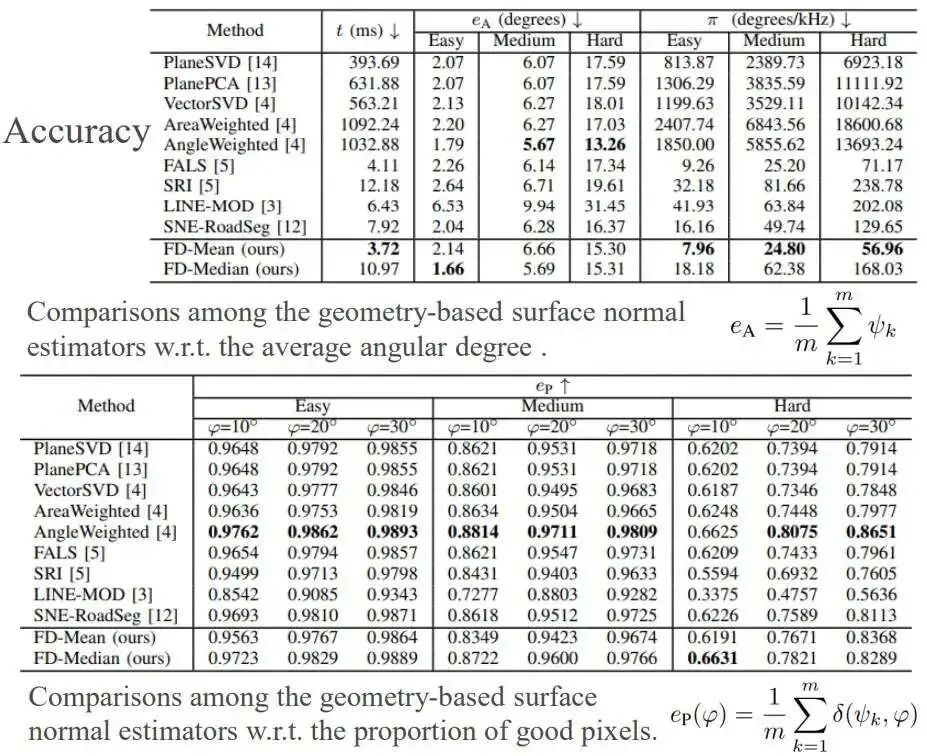
圖8 實(shí)驗(yàn)結(jié)果
在得到上述信息后,要進(jìn)行場(chǎng)景解析,目前比較主流的方法是語(yǔ)義分割,目標(biāo)檢測(cè)和實(shí)例分割。對(duì)于場(chǎng)景理解,尤其是語(yǔ)義分割及一些傳統(tǒng)方法是基于RGB信息進(jìn)行處理。
這里主要關(guān)注的是RGB-X,即如何對(duì)RGB加depth或normal進(jìn)行特征提取。主要應(yīng)用關(guān)注于可行有序檢測(cè),即開車時(shí)看到的可行區(qū)域,目前是提出了如圖9所示的框架。
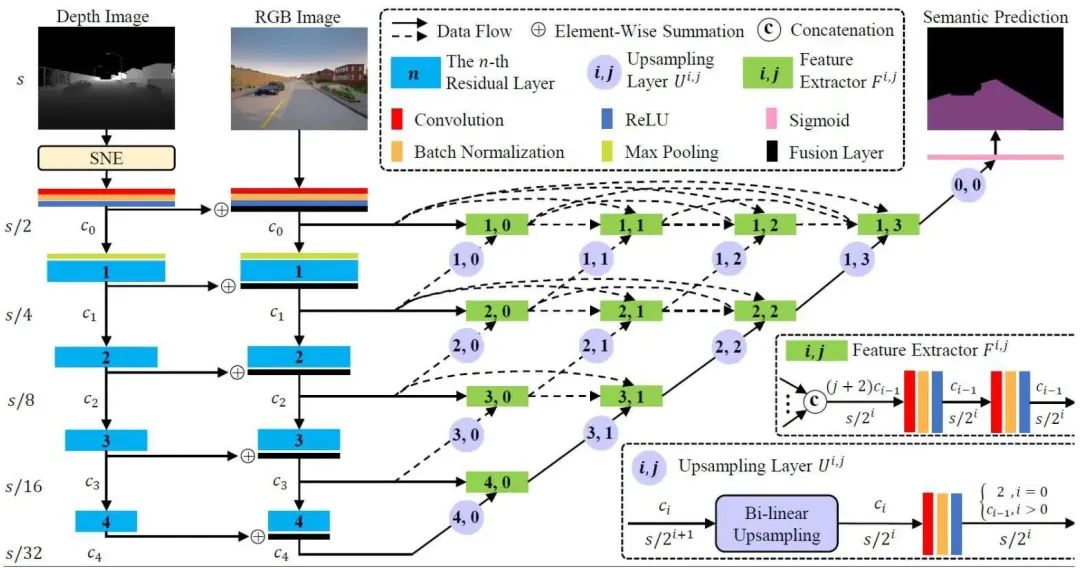
圖9 網(wǎng)絡(luò)結(jié)構(gòu)
這里是利用雙路結(jié)構(gòu)分別進(jìn)行特征提取,其中一路是從RGB信息去提取特征,另外一路是從deepth或者normals去提取特征,如果是depth則需要轉(zhuǎn)化為normal。然后,可以把這兩個(gè)不同信息的特征進(jìn)行融合,最后得到一個(gè)更好的特征,既包含了RGB信息中的紋理特性,又包含deepth圖像中的幾何特性。最后,通過connection去得到更好的語(yǔ)義分割結(jié)果圖。
針對(duì)上述的版本進(jìn)行一些改進(jìn),如圖10所示。由于網(wǎng)絡(luò)的融合結(jié)構(gòu)比較復(fù)雜,所以有進(jìn)一步提升的空間,所以這里做了這樣的工作:首先,利用深監(jiān)督的方式在不同的通道添加一些約束,然后再去學(xué)習(xí),這樣可以解決梯度爆炸的問題。其次,由于之前網(wǎng)絡(luò)收斂過快,這里設(shè)計(jì)了一套新的SNE+算法,效果比SNE要更好。
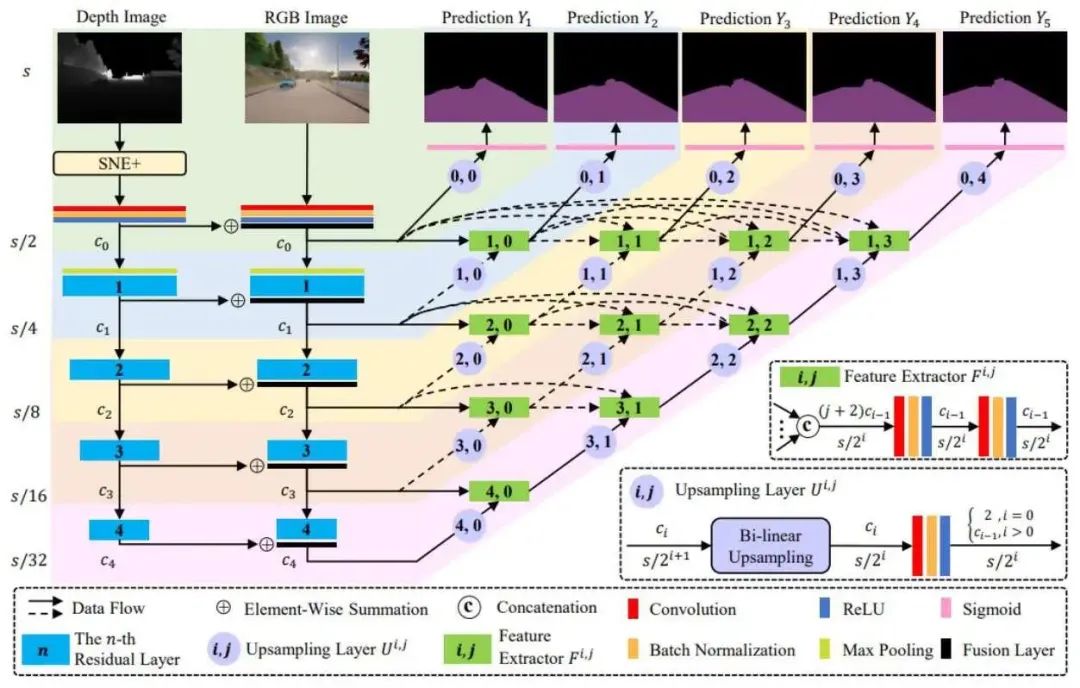
圖10 改進(jìn)網(wǎng)絡(luò)結(jié)構(gòu)
前面一直是基于特征層級(jí)的融合,這里也研究了一些數(shù)據(jù)層級(jí)的融合。如何通過多個(gè)視角和單ground-truth去提升性能,這里是提出了如圖11所示的網(wǎng)絡(luò)結(jié)構(gòu)。
主要是基于平面的單應(yīng)性,單應(yīng)性是對(duì)應(yīng)點(diǎn)可以通過四對(duì)點(diǎn)進(jìn)行單應(yīng)矩陣估計(jì),并且若已知單應(yīng)矩陣和left-right的圖像,可以通過ground-truth變成另外一個(gè)圖像的視角。可以看到這里對(duì)應(yīng)給定一個(gè) reference image,給定一個(gè)targetimage,然后通過對(duì)應(yīng)點(diǎn)去估計(jì)出對(duì)應(yīng)的homegra-marix,然后可以直接把target image變成generated image。
generateimage看起來(lái)跟對(duì)應(yīng)的reference image很像,但存在一個(gè)問題是它只是在道路區(qū)域看起來(lái)很像,但其實(shí)在網(wǎng)絡(luò)訓(xùn)練時(shí)兩個(gè)圖像會(huì)共用了一套ground-truth,因?yàn)樵诜锹访鎱^(qū)域存在一些偏差,所以最后讓網(wǎng)絡(luò)學(xué)出來(lái),能夠更好的識(shí)別路面。
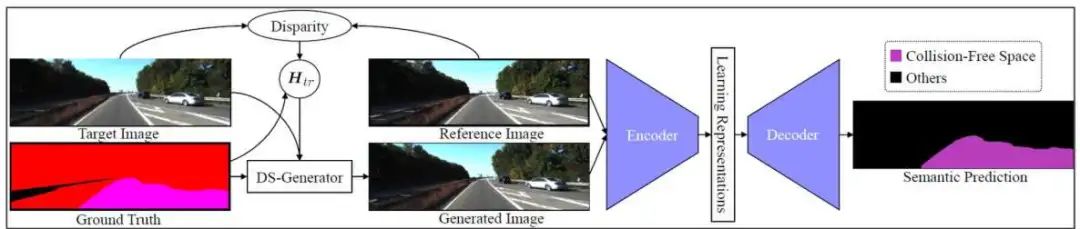
圖11 多視角分割網(wǎng)絡(luò)
02 ? 道路質(zhì)量檢測(cè)
地面移動(dòng)機(jī)器人可以顯著改善人們的舒適度和生活質(zhì)量。在移動(dòng)機(jī)器人的所有視覺環(huán)境感知任務(wù)中,可駕駛區(qū)域和道路的聯(lián)合檢測(cè)像素級(jí)的異常是一個(gè)關(guān)鍵問題。準(zhǔn)確高效的可行駛區(qū)域和道路異常檢測(cè)可以有助于避免此類車輛發(fā)生事故。然而,現(xiàn)有的基準(zhǔn)測(cè)試大多是為自動(dòng)駕駛汽車設(shè)計(jì)的,地面移動(dòng)機(jī)器人缺乏基準(zhǔn),而道路狀況會(huì)影響到駕駛的舒適性和安全性。
基于這些問題,研究如何去評(píng)估道路的質(zhì)量,另外最早的時(shí)候是交通和土木的人在關(guān)注的事情,因?yàn)樗麄冏龅缆吩u(píng)估,更多是為了去修補(bǔ)道路或是道路養(yǎng)護(hù)。最早期數(shù)據(jù)采集是用一些雷達(dá)車去進(jìn)行,價(jià)格昂貴,隨意在想能否用比較低成本的方式去做道路數(shù)據(jù)采集。
這里設(shè)計(jì)了一套實(shí)驗(yàn)設(shè)備和網(wǎng)絡(luò)框架如圖12所示,網(wǎng)絡(luò)輸入left frame和right frame,主要經(jīng)過三個(gè)流程,第一個(gè)是 perspective transformation,第二個(gè)是SDM,最后一個(gè)是global finement。
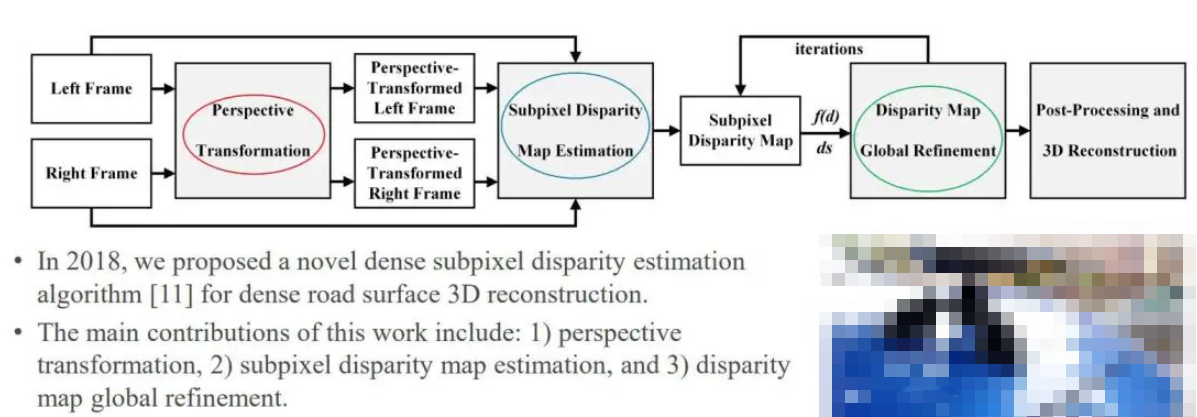
圖12 實(shí)驗(yàn)設(shè)備及網(wǎng)絡(luò)
第一步是最有意思的一個(gè)創(chuàng)新,因?yàn)楹苤庇^的傳統(tǒng)印象是:如果用雙目進(jìn)行三維重建,baseline越大,效果應(yīng)該越好,精度越高。但存在一個(gè)問題是baseline越大的時(shí)候,盲區(qū)越大,并且這兩個(gè)圖像的視角差異會(huì)越大。進(jìn)行相關(guān)研究發(fā)現(xiàn),有時(shí)角度雖然大了,但從理論上來(lái)講,會(huì)得到一個(gè)更好的三維幾何模型,但導(dǎo)致匹配的效果可能會(huì)下降,所以,將左圖變換成右圖的樣子,進(jìn)而實(shí)現(xiàn)處理,從而在速度和精度方面實(shí)現(xiàn)更好的視差估計(jì)。
在駕駛場(chǎng)景的時(shí)候,經(jīng)常會(huì)看到道路的視差是漸變的,但障礙物的差異保持不變。因此,在算法中首先估計(jì)如圖13中最下面一行的差異,然后使用三個(gè)相鄰像素從底部向頂部傳播搜索范圍,再進(jìn)行迭代估計(jì)差異,最后視差圖的可視化結(jié)果如圖14所示。
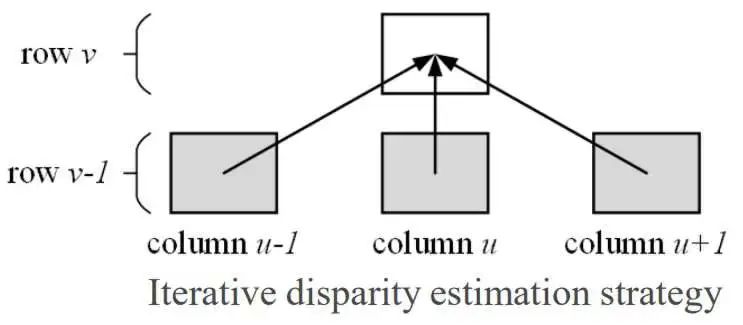
圖13 視差變化
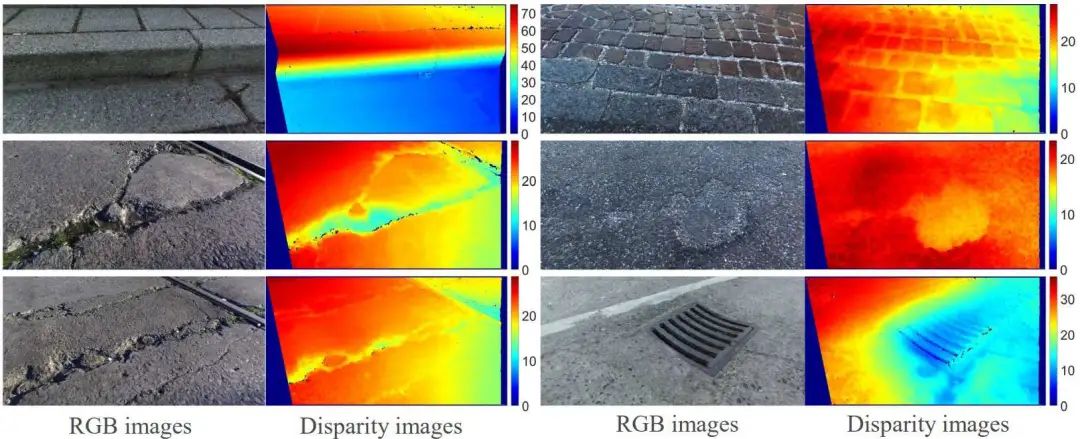
圖14 可視化結(jié)果
后面也基于一些網(wǎng)絡(luò)去做圖像分割,比如單模態(tài)網(wǎng)絡(luò)或是一些數(shù)據(jù)融合的網(wǎng)絡(luò)操作。如圖15所示,基于圖神經(jīng)網(wǎng)絡(luò),設(shè)計(jì)了一些新的框架。這個(gè)框架并沒有像圖神經(jīng)網(wǎng)絡(luò)一樣去設(shè)計(jì)一套新的圖網(wǎng)絡(luò),而是結(jié)合圖網(wǎng)絡(luò)去進(jìn)行一些公式推導(dǎo),發(fā)現(xiàn)圖網(wǎng)絡(luò)對(duì)于一些語(yǔ)義分割的情況,并不需要復(fù)雜的一些情況,只需要修改參數(shù)和變量,就可以去進(jìn)行一些操作。
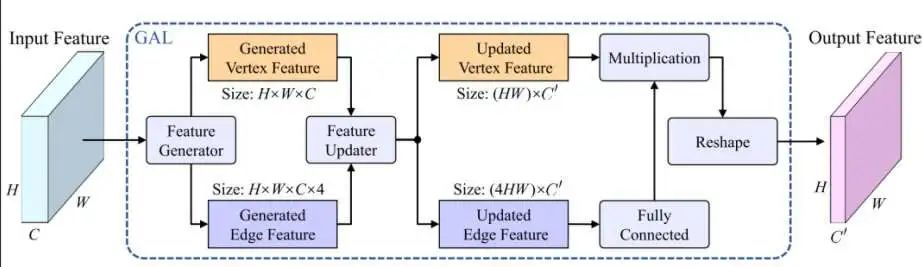
圖15 網(wǎng)絡(luò)框架
這個(gè)網(wǎng)絡(luò)可以放入任何一個(gè)CNN架構(gòu)去提升性能,簡(jiǎn)而言之,提取特征之后,對(duì)特征進(jìn)行細(xì)化,之后把舊特征和新特征拼接在一起再重新輸入進(jìn)去。與當(dāng)時(shí)幾個(gè)主流的網(wǎng)絡(luò)進(jìn)行了驗(yàn)證,發(fā)現(xiàn)加入這個(gè)模塊后都能夠去提升分割的性能,如圖16所示。
然后,也做了一些實(shí)驗(yàn)去驗(yàn)證它不光能夠去應(yīng)用這種特殊道路場(chǎng)景的識(shí)別的任務(wù),而且能夠去應(yīng)用在廣義的無(wú)人駕駛的語(yǔ)義分割或者室內(nèi)的場(chǎng)景理解的語(yǔ)義分割的一些任務(wù)當(dāng)中。

圖16 實(shí)驗(yàn)結(jié)果
03 ? 總結(jié)
(1)由于不再需要標(biāo)記的訓(xùn)練數(shù)據(jù),卷積神經(jīng)網(wǎng)絡(luò)和傳統(tǒng)計(jì)算機(jī)視覺算法的結(jié)合為無(wú)監(jiān)督/自監(jiān)督的場(chǎng)景理解提供了一種可行的解決方案;
(2)數(shù)據(jù)融合方法提供了更好的場(chǎng)景理解準(zhǔn)確性;
(3)使用現(xiàn)代深度學(xué)習(xí)算法進(jìn)行路況評(píng)估是需要更多關(guān)注的研究;
(4)在資源有限的硬件上實(shí)現(xiàn)人工智能算法時(shí),我們還需要考慮計(jì)算復(fù)雜性,因?yàn)榻裉煊懻摰膽?yīng)用程序通常需要實(shí)時(shí)性能。
編輯:黃飛
?















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論