 電子發燒友App
電子發燒友App


近日,Dishashree Gupta 在 Analyticsvidhya 上發表了一篇題為《Architecture of Convolutional Neural Networks (CNNs) demystified》的文章,對用于圖像識別和分類的卷積神經網絡架構作了深度揭秘;作者在文中還作了通盤演示,期望對 CNN 的工作機制有一個深入的剖析。
?
引言
先坦白地說,有一段時間我無法真正理解深度學習。我查看相關研究論文和文章,感覺深度學習異常復雜。我嘗試去理解神經網絡及其變體,但依然感到困難。
接著有一天,我決定一步一步,從基礎開始。我把技術操作的步驟分解開來,并手動執行這些步驟(和計算),直到我理解它們如何工作。這相當費時,且令人緊張,但是結果非凡。
現在,我不僅對深度學習有了全面的理解,還在此基礎上有了好想法,因為我的基礎很扎實。隨意地應用神經網絡是一回事,理解它是什么以及背后的發生機制是另外一回事。
今天,我將與你共享我的心得,展示我如何上手卷積神經網絡并最終弄明白了它。我將做一個通盤的展示,從而使你對 CNN 的工作機制有一個深入的了解。
在本文中,我將會討論 CNN 背后的架構,其設計初衷在于解決圖像識別和分類問題。同時我也會假設你對神經網絡已經有了初步了解。
1. 機器如何看圖?
人類大腦是一非常強大的機器,每秒內能看(捕捉)多張圖,并在意識不到的情況下就完成了對這些圖的處理。但機器并非如此。機器處理圖像的第一步是理解,理解如何表達一張圖像,進而讀取圖片。
簡單來說,每個圖像都是一系列特定排序的圖點(像素)。如果你改變像素的順序或顏色,圖像也隨之改變。舉個例子,存儲并讀取一張上面寫著數字 4 的圖像。
基本上,機器會把圖像打碎成像素矩陣,存儲每個表示位置像素的顏色碼。在下圖的表示中,數值 1 是白色,256 是最深的綠色(為了簡化,我們示例限制到了一種顏色)。

一旦你以這種格式存儲完圖像信息,下一步就是讓神經網絡理解這種排序與模式。
2. 如何幫助神經網絡識別圖像?
表征像素的數值是以特定的方式排序的。

假設我們嘗試使用全連接網絡識別圖像,該如何做?
全連接網絡可以通過平化它,把圖像當作一個數組,并把像素值當作預測圖像中數值的特征。明確地說,讓網絡理解理解下面圖中發生了什么,非常的艱難。
即使人類也很難理解上圖中表達的含義是數字 4。我們完全丟失了像素的空間排列。
我們能做什么呢?可以嘗試從原圖像中提取特征,從而保留空間排列。
案例 1
這里我們使用一個權重乘以初始像素值。

現在裸眼識別出這是「4」就變得更簡單了。但把它交給全連接網絡之前,還需要平整化(flatten) 它,要讓我們能夠保留圖像的空間排列。
案例 2
現在我們可以看到,把圖像平整化完全破壞了它的排列。我們需要想出一種方式在沒有平整化的情況下把圖片饋送給網絡,并且還要保留空間排列特征,也就是需要饋送像素值的 2D/3D 排列。
我們可以嘗試一次采用圖像的兩個像素值,而非一個。這能給網絡很好的洞見,觀察鄰近像素的特征。既然一次采用兩個像素,那也就需要一次采用兩個權重值了。

希望你能注意到圖像從之前的 4 列數值變成了 3 列。因為我們現在一次移用兩個像素(在每次移動中像素被共享),圖像變的更小了。雖然圖像變小了,我們仍能在很大程度上理解這是「4」。而且,要意識到的一個重點是,我們采用的是兩個連貫的水平像素,因此只會考慮水平的排列。
這是我們從圖像中提取特征的一種方式。我們可以看到左邊和中間部分,但右邊部分看起來不那么清楚。主要是因為兩個問題:
1. 圖片角落左邊和右邊是權重相乘一次得到的。
2. 左邊仍舊保留,因為權重值高;右邊因為略低的權重,有些丟失。
現在我們有兩個問題,需要兩個解決方案。
案例 3
遇到的問題是圖像左右兩角只被權重通過一次。我們需要做的是讓網絡像考慮其他像素一樣考慮角落。我們有一個簡單的方法解決這一問題:把零放在權重運動的兩邊。

你可以看到通過添加零,來自角落的信息被再訓練。圖像也變得更大。這可被用于我們不想要縮小圖像的情況下。
案例 4
這里我們試圖解決的問題是右側角落更小的權重值正在降低像素值,因此使其難以被我們識別。我們所能做的是采取多個權重值并將其結合起來。
(1,0.3) 的權重值給了我們一個輸出表格

同時表格 (0.1,5) 的權重值也將給我們一個輸出表格。

兩張圖像的結合版本將會給我們一個清晰的圖片。因此,我們所做的是簡單地使用多個權重而不是一個,從而再訓練圖像的更多信息。最終結果將是上述兩張圖像的一個結合版本。
案例 5
我們到現在通過使用權重,試圖把水平像素(horizontal pixel)結合起來。但是大多數情況下我們需要在水平和垂直方向上保持空間布局。我們采取 2D 矩陣權重,把像素在水平和垂直方向上結合起來。同樣,記住已經有了水平和垂直方向的權重運動,輸出會在水平和垂直方向上低一個像素。

特別感謝 Jeremy Howard 啟發我創作了這些圖像。
因此我們做了什么?
上面我們所做的事是試圖通過使用圖像的空間的安排從圖像中提取特征。為了理解圖像,理解像素如何安排對于一個網絡極其重要。上面我們所做的也恰恰是一個卷積網絡所做的。我們可以采用輸入圖像,定義權重矩陣,并且輸入被卷積以從圖像中提取特殊特征而無需損失其有關空間安排的信息。
這個方法的另一個重大好處是它可以減少圖像的參數數量。正如所見,卷積圖像相比于原始圖像有更少的像素。
3.定義一個卷積神經網絡
我們需要三個基本的元素來定義一個基本的卷積網絡
1. 卷積層
2. 池化層(可選)
3. 輸出層
卷積層
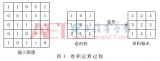
在這一層中,實際所發生的就像我們在上述案例 5 中見到的一樣。假設我們有一個 6*6 的圖像。我們定義一個權值矩陣,用來從圖像中提取一定的特征。

我們把權值初始化成一個 3*3 的矩陣。這個權值現在應該與圖像結合,所有的像素都被覆蓋至少一次,從而來產生一個卷積化的輸出。上述的 429,是通過計算權值矩陣和輸入圖像的 3*3 高亮部分以元素方式進行的乘積的值而得到的。

現在 6*6 的圖像轉換成了 4*4 的圖像。想象一下權值矩陣就像用來刷墻的刷子。首先在水平方向上用這個刷子進行刷墻,然后再向下移,對下一行進行水平粉刷。當權值矩陣沿著圖像移動的時候,像素值再一次被使用。實際上,這樣可以使參數在卷積神經網絡中被共享。
下面我們以一個真實圖像為例。
權值矩陣在圖像里表現的像一個從原始圖像矩陣中提取特定信息的過濾器。一個權值組合可能用來提取邊緣(edge)信息,另一個可能是用來提取一個特定顏色,下一個就可能就是對不需要的噪點進行模糊化。
先對權值進行學習,然后損失函數可以被最小化,類似于多層感知機(MLP)。因此需要通過對參數進行學習來從原始圖像中提取信息,從而來幫助網絡進行正確的預測。當我們有多個卷積層的時候,初始層往往提取較多的一般特征,隨著網絡結構變得更深,權值矩陣提取的特征越來越復雜,并且越來越適用于眼前的問題。
步長(stride)和邊界(padding)的概念
像我們在上面看到的一樣,過濾器或者說權值矩陣,在整個圖像范圍內一次移動一個像素。我們可以把它定義成一個超參數(hyperparameter),從而來表示我們想讓權值矩陣在圖像內如何移動。如果權值矩陣一次移動一個像素,我們稱其步長為 1。下面我們看一下步長為 2 時的情況。

你可以看見當我們增加步長值的時候,圖像的規格持續變小。在輸入圖像四周填充 0 邊界可以解決這個問題。我們也可以在高步長值的情況下在圖像四周填加不只一層的 0 邊界。

我們可以看見在我們給圖像填加一層 0 邊界后,圖像的原始形狀是如何被保持的。由于輸出圖像和輸入圖像是大小相同的,所以這被稱為 same padding。

這就是 same padding(意味著我們僅考慮輸入圖像的有效像素)。中間的 4*4 像素是相同的。這里我們已經利用邊界保留了更多信息,并且也已經保留了圖像的原大小。
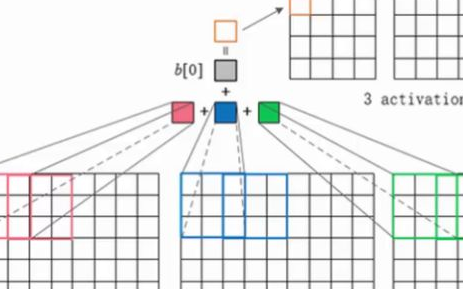
多過濾與激活圖
需要記住的是權值的縱深維度(depth dimension)和輸入圖像的縱深維度是相同的。權值會延伸到輸入圖像的整個深度。因此,和一個單一權值矩陣進行卷積會產生一個單一縱深維度的卷積化輸出。大多數情況下都不使用單一過濾器(權值矩陣),而是應用維度相同的多個過濾器。
每一個過濾器的輸出被堆疊在一起,形成卷積圖像的縱深維度。假設我們有一個 32*32*3 的輸入。我們使用 5*5*3,帶有 valid padding 的 10 個過濾器。輸出的維度將會是 28*28*10。
如下圖所示:

激活圖是卷積層的輸出。
池化層
有時圖像太大,我們需要減少訓練參數的數量,它被要求在隨后的卷積層之間周期性地引進池化層。池化的唯一目的是減少圖像的空間大小。池化在每一個縱深維度上獨自完成,因此圖像的縱深保持不變。池化層的最常見形式是最大池化。

在這里,我們把步幅定為 2,池化尺寸也為 2。最大化執行也應用在每個卷機輸出的深度尺寸中。正如你所看到的,最大池化操作后,4*4 卷積的輸出變成了 2*2。
讓我們看看最大池化在真實圖片中的效果如何。

正如你看到的,我們卷積了圖像,并最大池化了它。最大池化圖像仍然保留了汽車在街上的信息。如果你仔細觀察的話,你會發現圖像的尺寸已經減半。這可以很大程度上減少參數。
同樣,其他形式的池化也可以在系統中應用,如平均池化和 L2 規范池化。
輸出維度
理解每個卷積層輸入和輸出的尺寸可能會有點難度。以下三點或許可以讓你了解輸出尺寸的問題。有三個超參數可以控制輸出卷的大小。
1. 過濾器數量-輸出卷的深度與過濾器的數量成正比。請記住該如何堆疊每個過濾器的輸出以形成激活映射。激活圖的深度等于過濾器的數量。
2. 步幅(Stride)-如果步幅是 1,那么我們處理圖片的精細度就進入單像素級別了。更高的步幅意味著同時處理更多的像素,從而產生較小的輸出量。
3. 零填充(zero padding)-這有助于我們保留輸入圖像的尺寸。如果添加了單零填充,則單步幅過濾器的運動會保持在原圖尺寸。
我們可以應用一個簡單的公式來計算輸出尺寸。輸出圖像的空間尺寸可以計算為([W-F + 2P] / S)+1。在這里,W 是輸入尺寸,F 是過濾器的尺寸,P 是填充數量,S 是步幅數字。假如我們有一張 32*32*3 的輸入圖像,我們使用 10 個尺寸為 3*3*3 的過濾器,單步幅和零填充。
那么 W=32,F=3,P=0,S=1。輸出深度等于應用的濾波器的數量,即 10,輸出尺寸大小為 ([32-3+0]/1)+1 = 30。因此輸出尺寸是 30*30*10。
輸出層
在多層卷積和填充后,我們需要以類的形式輸出。卷積和池化層只會提取特征,并減少原始圖像帶來的參數。然而,為了生成最終的輸出,我們需要應用全連接層來生成一個等于我們需要的類的數量的輸出。僅僅依靠卷積層是難以達到這個要求的。卷積層可以生成 3D 激活圖,而我們只需要圖像是否屬于一個特定的類這樣的內容。輸出層具有類似分類交叉熵的損失函數,用于計算預測誤差。一旦前向傳播完成,反向傳播就會開始更新權重與偏差,以減少誤差和損失。
4. 小結
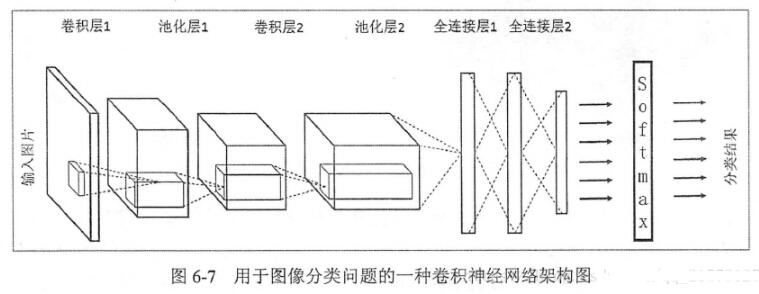
正如你所看到的,CNN 由不同的卷積層和池化層組成。讓我們看看整個網絡是什么樣子:

我們將輸入圖像傳遞到第一個卷積層中,卷積后以激活圖形式輸出。圖片在卷積層中過濾后的特征會被輸出,并傳遞下去。
每個過濾器都會給出不同的特征,以幫助進行正確的類預測。因為我們需要保證圖像大小的一致,所以我們使用同樣的填充(零填充),否則填充會被使用,因為它可以幫助減少特征的數量。
隨后加入池化層進一步減少參數的數量。
在預測最終提出前,數據會經過多個卷積和池化層的處理。卷積層會幫助提取特征,越深的卷積神經網絡會提取越具體的特征,越淺的網絡提取越淺顯的特征。
如前所述,CNN 中的輸出層是全連接層,其中來自其他層的輸入在這里被平化和發送,以便將輸出轉換為網絡所需的參數。
隨后輸出層會產生輸出,這些信息會互相比較排除錯誤。損失函數是全連接輸出層計算的均方根損失。隨后我們會計算梯度錯誤。
錯誤會進行反向傳播,以不斷改進過濾器(權重)和偏差值。
一個訓練周期由單次正向和反向傳遞完成。
5. 在 KERAS 中使用 CNN 對圖像進行分類
讓我們嘗試一下,輸入貓和狗的圖片,讓計算機識別它們。這是圖像識別和分類的經典問題,機器在這里需要做的是看到圖像,并理解貓與狗的不同外形特征。這些特征可以是外形輪廓,也可以是貓的胡須之類,卷積層會攫取這些特征。讓我們把數據集拿來試驗一下吧。
以下這些圖片均來自數據集。

我們首先需要調整這些圖像的大小,讓它們形狀相同。這是處理圖像之前通常需要做的,因為在拍照時,讓照下的圖像都大小相同幾乎不可能。
為了簡化理解,我們在這里只用一個卷積層和一個池化層。注意:在 CNN 的應用階段,這種簡單的情況是不會發生的。
#import various packagesimport osimport numpy as npimport pandas as pdimport scipyimport sklearnimport kerasfrom keras.models import Sequentialimport cv2from skimage import io
%matplotlib inline
#Defining the File Path
cat=os.listdir("/mnt/hdd/datasets/dogs_cats/train/cat")
dog=os.listdir("/mnt/hdd/datasets/dogs_cats/train/dog")
filepath="/mnt/hdd/datasets/dogs_cats/train/cat/"filepath2="/mnt/hdd/datasets/dogs_cats/train/dog/"#Loading the Images
images=[]
label = []for i in cat:
image = scipy.misc.imread(filepath+i)
images.append(image)
label.append(0) #for cat imagesfor i in dog:
image = scipy.misc.imread(filepath2+i)
images.append(image)
label.append(1) #for dog images
#resizing all the imagesfor i in range(0,23000):
images[i]=cv2.resize(images[i],(300,300))
#converting images to arrays
images=np.array(images)
label=np.array(label)
# Defining the hyperparameters
filters=10filtersize=(5,5)
epochs =5batchsize=128input_shape=(300,300,3)
#Converting the target variable to the required sizefrom keras.utils.np_utils import to_categorical
label = to_categorical(label)
#Defining the model
model = Sequential()
model.add(keras.layers.InputLayer(input_shape=input_shape))
model.add(keras.layers.convolutional.Conv2D(filters, filtersize, strides=(1, 1), padding='valid', data_format="channels_last", activation='relu'))
model.add(keras.layers.MaxPooling2D(pool_size=(2, 2)))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(units=2, input_dim=50,activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(images, label, epochs=epochs, batch_size=batchsize,validation_split=0.3)
model.summary()
在這一模型中,我只使用了單一卷積和池化層,可訓練參數是 219,801。很好奇如果我在這種情況使用了 MLP 會有多少參數。通過增加更多的卷積和池化層,你可以進一步降低參數的數量。我們添加的卷積層越多,被提取的特征就會更具體和復雜。
在該模型中,我只使用了一個卷積層和池化層,可訓練參數量為 219,801。如果想知道使用 MLP 在這種情況下會得到多少,你可以通過加入更多卷積和池化層來減少參數的數量。越多的卷積層意味著提取出來的特征更加具體,更加復雜。
結語
希望本文能夠讓你認識卷積神經網絡,這篇文章沒有深入 CNN 的復雜數學原理。如果希望增進了解,你可以嘗試構建自己的卷積神經網絡,借此來了解它運行和預測的原理。














 工商網監
工商網監
評論