 電子發燒友App
電子發燒友App


ZYNQ作為首款將高性能ARMCortex-A系列處理器與高性能FPGA在單芯片內緊密結合的產品,為了實現ARM處理器和FPGA之間的高速通信和數據交互,發揮ARM處理器和FPGA的性能優勢,需要設計高效的片內高性能處理器與 FPGA 之間的互聯通路。因此,如何設計高效的 PL 和 PS 數據交互通路是 ZYNQ 芯片設計的重中之重,也是產品設計的成敗關鍵之一。 ?
? ? ? 主要介紹 PS 和 PL 的連接,了解 PS 和 PL 之間連接的技術。
? ? ?其實,在具體設計中我們往往不需要在連接這個地方做太多工作,我們加入 IP 核以后,系統會自動使用 AXI 接口將我們的 IP 核與處理器連接起來,我們只需要再做一點補充就可以了。不過,這部分概念還是了解比較好。
AXI 接口標準介紹
AXI?是 Xilinx 從 6 系列的 FPGA 開始引入的一個接口協議,主要描述了主設備和從設備之間的數據傳輸方式。在 ZYNQ 中繼續使用,版本是AXI4,所以我們經常會看到 AXI4.0,ZYNQ 內部設備都有AXI接口。其實AXI 就是ARM 公司提出的 AMBA(AdvancedMicrocontrollerBusArchitecture)的一個部分,是一種高性能、高帶寬、低延遲的片內總線,也用來替代以前的 AHB 和 APB 總線。第一個版本的 AXI (AXI3)包含在 2003 年發布的 AMBA3.0 中,AXI 的第二個版本 AXI(AXI4)包含在 2010 年發布的AMBA4.0 之中。
AXI 協議主要描述了主設備和從設備之間的數據傳輸方式,主設備和從設備之間通過握手信號建立連接。當從設備準備好接收數據時,會發出 READY 信號。當主設備的數據準備好時,會發出和維持 VALID 信號,表示數據有效。數據只有在 VALID 和 READY 信號都有效的時候才開始傳輸。當這兩個信號持續保持有效,主設備會繼續傳輸下一個數據。主設備可以撤銷 VALID信號,或者從設備撤銷 READY 信號終止傳輸。AXI 的協議如圖 1,T2 時,從設備的 READY信號有效,T3 時主設備的 VILID 信號有效,數據傳輸開始。
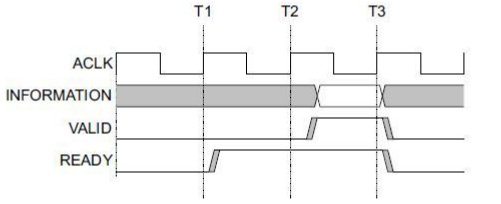
圖 1AXI 握手時序圖
在 ZYNQ 中,支持 AXI-Lite,AXI4 和 AXI-Stream 三種總線,通過表1,我們可以看到這三中 AXI 接口的特性。 ?表 1AXI 接口分類

AXI-Lite:
具有輕量級,結構簡單的特點,適合小批量數據、簡單控制場合。不支持批量傳輸,讀寫時一次只能讀寫一個字(32bit)。主要用于訪問一些低速外設和外設的控制。
AXI4:
接口和 AXI-Lite 差不多,只是增加了一項功能就是批量傳輸,可以連續對一片地址進行一次性讀寫。也就是說具有數據讀寫的 burst 功能。
上面兩種均采用內存映射控制方式,即 ARM 將用戶自定義 IP 編入某一地址進行訪問,讀寫時就像在讀寫自己的片內 RAM,編程也很方便,開發難度較低。代價就是資源占用過多,需要額外的讀地址線、寫地址線、讀數據線、寫數據線、寫應答線這些信號線。
AXI-Stream:
這是一種連續流接口,不需要地址線(很像 FIFO,一直讀或一直寫就行)。對于這類 IP,ARM 不能通過上面的內存映射方式控制(FIFO 根本沒有地址的概念),必須有一個轉換裝置,例如 AXI-DMA 模塊來實現內存映射到流式接口的轉換。AXI-Stream 適用的場合有很多:視頻流處理;通信協議轉換;數字信號處理;無線通信等。其本質都是針對數值流構建的數據通路,從信源(例如 ARM 內存、DMA、無線接收前端等)到信宿(例如 HDMI 顯示器、高速AD 音頻輸出,等)構建起連續的數據流。這種接口適合做實時信號處理。
AXI4 和 AXI4-Lite 接口包含 5 個不同的通道:
ReadAddressChannel
WriteAddressChannel
ReadDataChannel
WriteDataChannel
WriteResponseChannel
其中每個通道都是一個獨立的 AXI 握手協議。下面兩個圖分別顯示了讀和寫的模型:
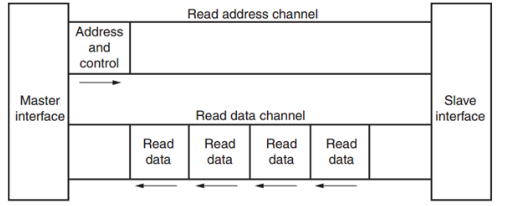
圖 2AXI 讀數據通道
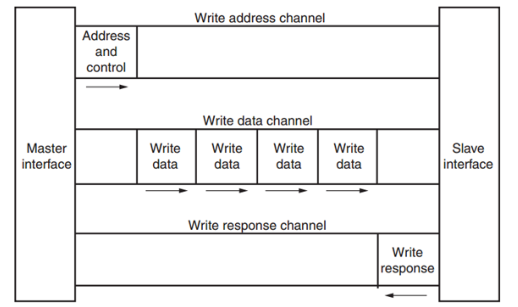
圖 3AXI 寫數據通道
ZYNQ 的 AXI 資源
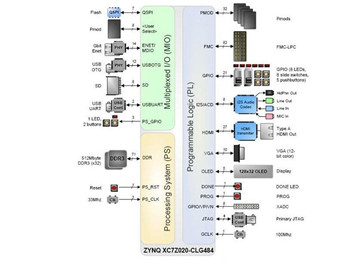
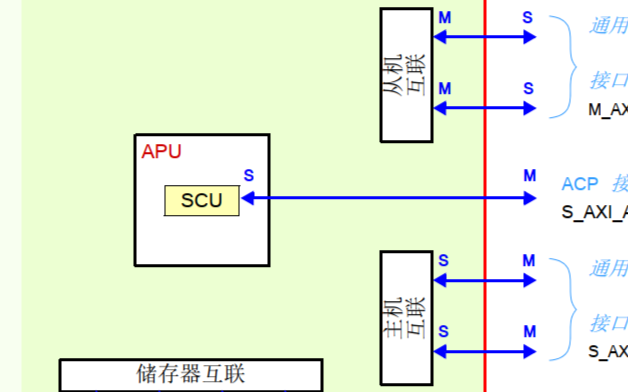
在 ZYNQ 芯片內部用硬件實現了 AXI 總線協議,包括 9 個物理接口,分別為 AXI-GP0~AXI-GP3,AXI-HP0~AXI-HP3,AXI-ACP 接口。
AXI_ACP 接口,是 ARM 多核架構下定義的一種接口,中文翻譯為加速器一致性端口,用來管理 DMA 之類的不帶緩存的 AXI 外設,PS 端是 Slave 接口。
AXI_HP 接口,是高性能/帶寬的 AXI3.0 標準的接口,總共有四個,PL 模塊作為主設備連接。主要用于 PL 訪問 PS 上的存儲器(DDR 和 On-ChipRAM)
AXI_GP 接口,是通用的 AXI 接口,總共有四個,包括兩個 32 位主設備接口和兩個 32 位從設備接口。
AXI接口分布圖如下圖 4 所示:
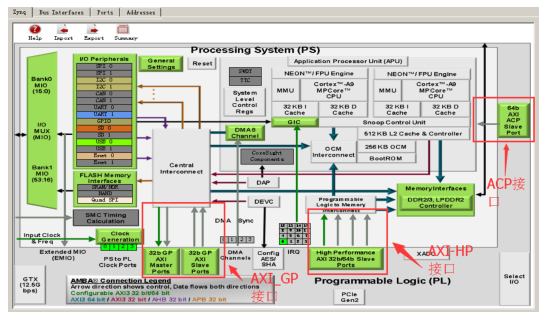
圖4AXI接口分布圖
可以看到,只有兩個 AXI-GP 是 MasterPort,即主機接口,其余 7 個口都是 SlavePort(從機接口)。主機接口具有發起讀寫的權限,ARM 可以利用兩個 AXI-GP 主機接口主動訪問PL 邏輯,其實就是把 PL 映射到某個地址,讀寫 PL 寄存器如同在讀寫自己的存儲器。其余從機接口就屬于被動接口,接受來自 PL 的讀寫,逆來順受。
另外這 9 個 AXI 接口性能也是不同的。GP 接口是 32 位的低性能接口,理論帶寬 600MB/s,而 HP 和 ACP 接口為 64 位高性能接口,理論帶寬 1200MB/s。有人會問,為什么高性能接口不做成主機接口呢?這樣可以由 ARM 發起高速數據傳輸。答案是高性能接口根本不需要 ARMCPU 來負責數據搬移,真正的搬運工是位于 PL 中的 DMA 控制器。
PL 端的 AXI 接口設計
位于 PS 端的 ARM 直接有硬件支持 AXI 接口,而 PL 則需要使用邏輯實現相應的 AXI 協議。Xilinx在Vivado開發環境里提供現成IP如AXI-DMA,AXI-GPIO,AXI-Dataover,AXI-Stream都實現了相應的接口,使用時直接從 Vivado 的 IP 列表中添加即可實現相應的功能。 ? 下圖為Vivado 下的各種 DMAIP:
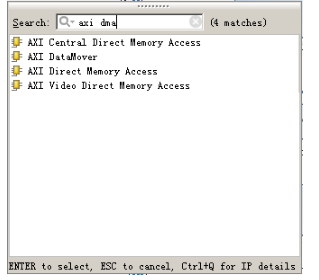
圖 5AXIDMAIP 核
下面為幾個常用的 AXI 接口 IP 的功能介紹:
AXI-DMA:實現從 PS 內存到 PL 高速傳輸高速通道 AXI-HP<---->AXI-Stream 的轉換
AXI-FIFO-MM2S:實現從 PS 內存到 PL 通用傳輸通道 AXI-GP<----->AXI-Stream 的轉換
AXI-Datamover:實現從 PS 內存到 PL 高速傳輸高速通道 AXI-HP<---->AXI-Stream 的轉換,只不過這次是完全由 PL 控制的,PS 是完全被動的。
AXI-VDMA:實現從 PS 內存到 PL 高速傳輸高速通道 AXI-HP<---->AXI-Stream 的轉換,只不過是專門針對視頻、圖像等二維數據的。
AXI-CDMA:這個是由 PL 完成的將數據從內存的一個位置搬移到另一個位置,無需 CPU 來插手。
有時,用戶需要開發自己定義的IP同PS進行通信,這時可以利用向導生成對應的IP。用戶自定義IP核可以擁有AXI-Lite,AXI4,AXI-Stream,PLB 和 FSL 這些接口。后兩種由于 ARM 這一端不支持,所以不用。
有了上面的這些官方 IP 和向導生成的自定義 IP,用戶其實不需要對 AXI 時序了解太多(除非確實遇到問題),因為 Xilinx 已經將和 AXI 時序有關的細節都封裝起來,用戶只需要關注自己的邏輯實現即可。
AXI Interconnect
AXI 協議嚴格的講是一個點對點的主從接口協議,當多個外設需要互相交互數據時,我們需要加入一個 AXIInterconnect 模塊,也就是 AXI 互聯矩陣,作用是提供將一個或多個 AXI主設備連接到一個或多個 AXI 從設備的一種交換機制(有點類似于交換機里面的交換矩陣)。
這個 AXIInterconnectIP 核最多可以支持 16 個主設備、16 個從設備,如果需要更多的接口,可以多加入幾個 IP 核。
AXIInterconnect 基本連接模式有以下幾種:
N-to-1Interconnect
1-to-NInterconnect
N-to-MInterconnect(CrossbarMode)
N-to-MInterconnect(SharedAccessMode)
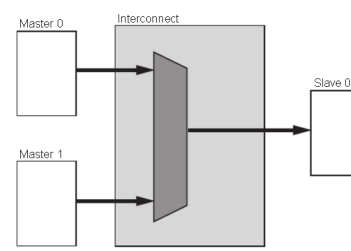
圖 6?多對一的情況
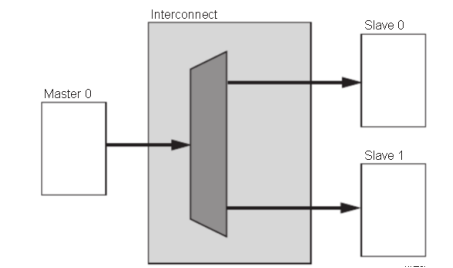
圖7 一對多的情況
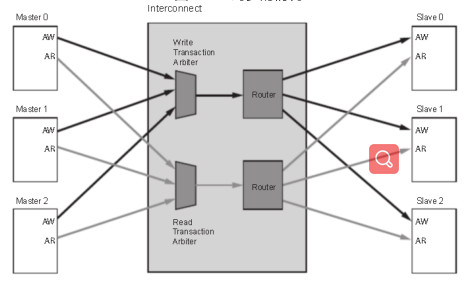
圖8 多對多讀寫地址通道
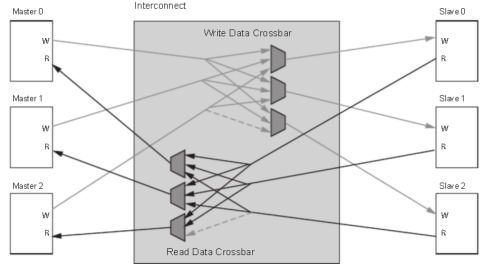
圖9 多對多讀寫數據通道 ? ?
ZYNQ 內部的 AXI 接口設備就是通過互聯矩陣的的方式互聯起來的,既保證了傳輸數據的高效性,又保證了連接的靈活性。Xilinx 在 Vivado 里我們提供了實現這種互聯矩陣的 IP 核axi_interconnect,我們只要調用就可以。
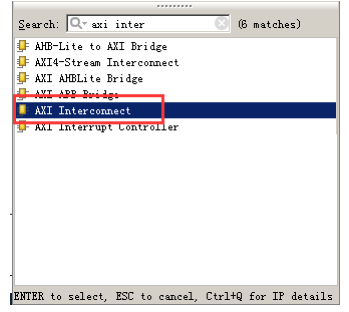
圖10 AXIInterconnectIP
?
審核編輯 :李倩
?



















 工商網監
工商網監
評論