 電子發燒友App
電子發燒友App


雙向特征融合的數據自適應SAR圖像艦船目標檢測模型
人工智能技術與咨詢 昨天
本文來自《中國圖象圖形學報》,作者張筱晗等
關注微信公眾號:人工智能技術與咨詢。了解更多咨詢!
?
摘要:?利用合成孔徑雷達(synthetic aperture radar,SAR)圖像進行艦船目標檢測是實施海洋監視的重要手段。基于深度學習的目標檢測模型在自然圖像目標檢測任務中取得了巨大成功,但由于自然圖像與SAR圖像的差異,不能將其直接遷移到SAR圖像目標檢測中。針對SAR圖像目標檢測實際應用中對速度和精度的需求,借鑒經典的單階段目標檢測模型(single shot detector,SSD)框架,提出一種基于特征優化的輕量化SAR圖像艦船目標檢測網絡。方法?改進模型并精簡網絡結構,提出一種數據驅動的目標分布聚類算法,學習SAR數據集的目標尺度、長寬比分布特性,用于網絡參數設定;對卷積神經網絡(convolutional neural network,CNN)提取的特征進行優化,提出一種雙向高低層特征融合機制,將高層特征的語義信息通過語義聚合模塊加成到低層特征中,在低層特征中提取特征平均圖,處理后作為高層特征的注意力權重圖對高層特征進行逐像素加權,將低層特征豐富的空間信息融入到高層特征中。結果?利用公開的SAR艦船目標檢測數據集(SAR ship detection dataset,SSDD)進行實驗,與原始的SSD模型相比,輕量化結構設計在不損失檢測精度的前提下,樣本測試時間僅為SSD的65%;雙向特征融合機制將平均精確度(average precision,AP)值由77.93%提升至80.13%,訓練和測試時間分別為SSD的64.1%和72.6%;與公開的基于深度學習的SAR艦船目標檢測方法相比,本文方法在速度和精度上都取得了最佳性能,AP值較精度次優模型提升了1.23%,訓練和測試時間較精度次優模型分別提升了559.34 ms和175.35 ms。結論?實驗充分驗證了本文所提模型的有效性,本文模型兼具檢測速度與精度優勢,具有很強的實用性。
? ? ? 艦船目標檢測是實施海洋監視的重要環節,在軍事偵察、海洋運輸管理、海上犯罪打擊等領域都有著重要應用(Allard等,2008)。得益于全天時、全天候的優勢,合成孔徑雷達(synthetic aperture radar,SAR)圖像成為一種有效的艦船目標遙感數據源,SAR艦船目標檢測得到了廣泛研究。傳統的基于海雜波建模思想的SAR艦船檢測方法通常針對某一場景進行建模(Dalal和Triggs,2005;Agrawal等,2015;Pappas等,2018),無法同時兼顧多類應用場景。而基于數據驅動的深度學習目標檢測方法則不受場景影響,只要提供充足多樣的數據,即可訓練深度網絡自動提取圖像特征,實現目標檢測。
得益于計算機技術與人工智能技術的發展,在計算機視覺領域,基于深度學習的目標檢測方法取得了很多檢測任務的最佳性能。經典的目標檢測模型,包括以Faster RCNN(region convolutional neural network)(Ren等,2017)為代表的雙階段檢測模型、以YOLO(you only look once)(Redmon等,2015)和SSD(single shot multi-box detector)(Liu等,2016)為代表的單階段檢測模型都被引入到SAR艦船檢測中。與傳統方法相比,這些模型多是端到端的,并且在精度和泛化能力上有了很大提升。但是,將這些模型從自然圖像目標檢測遷移到SAR艦船目標檢測時仍面臨著一些問題:1)這些模型參數,如網絡層數和錨框設置多是針對Pascal VOC(visual object classes)(Everingham等,2015)和MS COCO(Lin等,2014)等自然圖像數據集設定的,而這些設置未必適合SAR艦船數據; 2)數據量相對較小的檢測數據集往往不足以從頭訓練規模較大的檢測模型,通常做法是在檢測模型初始化時,將特征提取部分直接載入大型自然圖像分類數據集(如ImageNet等)預訓練好的模型參數,然后使用檢測數據集進行微調; 3)分類任務與檢測任務、自然分類數據集與SAR目標檢測數據集存在偏差; 4)SAR圖像自身的一些特點給檢測增加了難度,如受空間分辨率與成像機理影響,圖像中艦船目標細節信息少,各類艦船尺度不一、分布各異等。在設計SAR艦船目標檢測模型時, 要考慮這些問題。Kang等人(2017)和Yang等人(2018)根據使用的遙感艦船數據重新設置了檢測模型參數。Deng等人(2019)利用密集連接網絡作為特征提取網絡,并采用了特征重用等策略,可以從頭訓練。為了提升SAR艦船目標檢測的精度,學者利用多種方式對網絡提取的特征進行優化,其中,特征融合是一項常用策略(Jiao等,2018;Zhang等,2019)。自從Lin等人(2017)提出特征金字塔網絡(feature pyramid network,FPN),其高低特征層融合的思想大量用于多種模型。卷積神經網絡(convolutional neural network, CNN)在提取特征過程中,隨著網絡層數的加深與池化層的應用,深特征層有著更大的感受野,能夠提取出更多抽象的全局語義特征,而淺層特征空間信息更加豐富。為彌補淺層特征語義信息的不足,將高層特征處理后加入到淺層特征。Wang等人(2018)將FPN中的語義聚合策略應用在SAR艦船檢測中,與原始的SSD模型相比,顯著提升了艦船檢測精度。Kang等人(2017)將淺層特征、中層特征與高層特征都融合起來,輸入到Faster RCNN模型。特征融合的策略能夠提升模型性能,但也增加了運算量,此外,大部分融合模型的融合通道是由上至下的,沒有考慮高層信息中空間信息的不足。
針對上述問題,本文對SAR圖像艦船目標檢測進行研究,針對SAR圖像的特點改進了經典檢測模型SSD,同時提升了目標檢測的速度和精度。本文工作包括兩部分:1)根據SAR數據的特點,精簡了SSD模型結構,提出了一種數據集目標特性聚類算法,用于指導網絡參數的設置;2)借鑒特征融合思想,提出一種雙向特征融合機制,除了利用語義聚合增強淺層特征的語義信息,同時設計了一種新的基于注意力機制的融合方法,將淺層特征豐富的空間信息加成到高層特征。前者主要改進模型適應SAR艦船檢測任務,后者進一步優化模型,提升檢測精度。在公開SAR艦船目標檢測數據集SSDD(SAR ship detection dataset)(Li等,2017)上的實驗充分驗證了本文方法的有效性。
1 LSSD檢測模型
1.1 模型結構
本文模型是在經典的SSD模型基礎上改進的,并以VGG-16(visual geometry group 16)作為特征提取網絡。標準的SSD-300模型(輸入圖像大小為300 × 300 × 3)保留了VGG-16的前5個卷積單元,去掉全連接層,并繼續在后面連接了6個卷積單元,最終卷積單元輸出的特征圖空間維變成1×1。但是,對SAR圖像來說,某種極化模式下獲取的圖像是單通道的。在使用通用檢測模型時,通常做法是將單通道SAR圖像擴展為3通道作為輸入,這種做法增加了網絡的冗余信息。此外,SAR遙感圖像中的艦船目標尺度變化很大,所占像素從幾個到幾百不等,但受空間分辨率影響,單個艦船目標通常不會占滿圖像(300 × 300像素標準輸入大小)。因此,對模型進行更改,直接以單通道圖像作為輸入,去掉SSD模型的后3個卷積模塊,并將全部卷積層的通道維減半。這樣,與SSD相比,網絡需要訓練的參數量少于原來的1/4,模型顯著變輕量化,將其命名為LSSD(lightweight SSD)。經驗證,即使是較小的檢測數據集如SSDD也可以從頭訓練LSSD,使其不必依賴于分類任務預訓練模型。借鑒SSD模型的設置,同時考慮SAR圖像中的小艦船目標,選取conv3_3、conv4_3、conv7、conv8輸出的特征圖輸入到檢測器中進行后續檢測。
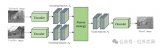
本文模型整體框架如圖 1所示,圖中右側為LSSD網絡的具體設置,圖中S代表語義聚合,A代表注意力引導的融合。
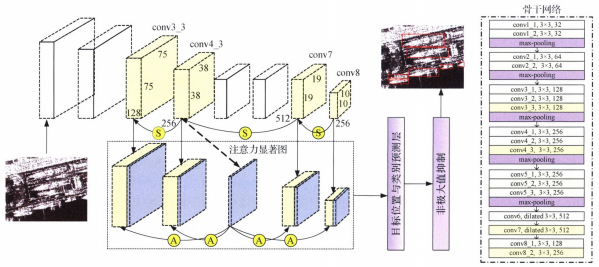
圖 1?本文模型框架圖
Fig. 1?Framework of proposed model
1.2 基于聚類算法的數據集目標特性統計
與Faster RCNN和SSD模型相同,LSSD也是基于錨框(anchor)實施檢測。錨框的設置包括尺度和比例,能夠反映數據集中目標的尺度和比例分布特性,對網絡檢測性能具有重要影響。受YOLOv2(Redmon和Farhadi,2017)中的維度聚類算法啟發,本文設計了一種基于聚類的目標特性分布自動學習算法,具體內容以SSDD數據集為例進行說明。
假設圖像大小為M×NM×N,艦船目標檢測框大小為w×hw×h。目標尺度ss和長寬比rr的定義為
?
|
s=w×hM×Ns=w×hM×N |
(1) |
?
?
|
r=whr=wh |
(2) |
?
1) 學習數據集中艦船目標的尺度分布。假設數據集中所有艦船目標的尺度集合為S:{s1,s2,…,sk}S:{s1,s2,…,sk},設定kk個尺度聚類中心U:{μ1,μ2,???,μk}U:{μ1,μ2,···,μk},其中μiμi初值為[0,1][0,1]區間的隨機值,μ1μ1到μkμk從小到大排列。通過最小化目標各尺度與聚類中心歐氏距離之和dsds,以更新UU的參數,即
?
|
minds=∑i=1n∥si?μj∥2minds=∑i=1n‖si?μj‖2 |
(3) |
?
式中,j∈{1,2,???,k}j∈{1,2,···,k},μjμj為最接近sisi的聚類中心。每次迭代中,μjμj更新為以其為聚類中心的所有目標尺度的均值,不斷迭代直到dsds小于設定閾值。迭代完成后,將學習到的尺度聚類中心UU分配到合適的特征層中,較小的尺度分配給低的特征層,大的錨框尺度則分配給高特征層。
2) 學習數據集中艦船目標的長寬比分布特性。設定特征層lxlx的長寬比聚類中心個數為gg,尺度接近該層各尺度聚類中心的艦船目標長寬比構成集合Rx:{rx1,rx2,…}Rx:{rx1,rx2,…},gg個長寬比聚類中心構成集合Vx:{τ1,τ2,…,τg}Vx:{τ1,τ2,…,τg},τiτi初值設為隨機正數,通過最小化目標長寬比到各自聚類中心歐氏距離之和drsdrs進行優化,即
?
|
mindrs=∑xi=1nx∥rxi?τj∥2mindrs=∑xi=1nx‖rxi?τj‖2 |
(4) |
?
式中,j∈{1,2,…,g}j∈{1,2,…,g},τjτj為最接近rxirxi的長寬比聚類中心。每次迭代中,τjτj更新為聚類中心目標長寬比的均值。不斷進行迭代,直到drsdrs小于設定閾值。最后根據長寬比聚類中心的值設置該層錨框的長寬比參數。
2 基于雙向融合的特征優化
2.1 原理分析
卷積神經網絡提取的分層特征有著不同的特點。與SSD一樣,為檢測多尺度目標,LSSD也使用了多層特征。其中淺層特征通常包含更多目標細節信息,缺乏高級語義信息; 深層特征信息更加抽象,但缺乏空間位置信息。以FPN網絡為代表的從上到下的語義聚合的特征融合方式已經得到了廣泛應用,針對如何將淺層豐富的空間信息傳遞到深特征層,本文提出了基于注意力機制的融合方式。
為直觀理解CNN提取的特征,本文將訓練好的LSSD模型中不同層的特征進行可視化。圖 2是訓練好的LSSD模型提取的兩幅SAR圖像conv3_3、conv4_3、conv7、conv8的第1通道和第64通道的特征圖及各通道平均熱力圖。可以看出,針對輸入的特定圖像,不同卷積層在不同通道提取了不同特征,但很難解釋特定通道特征的含義。為展示每個卷積層提取的整體特征,在特征層通道維進行全局平均池化,得到特征的空間維平均圖,并以熱圖的形式展示。從平均圖可以看出,隨著特征層的增深,平均特征中關于目標的表征越來越抽象。其中,在conv4_3的特征平均圖中,無論背景是較為簡單的水面,還是更復雜的陸地,艦船目標與背景分離最明顯。受計算機視覺中注意力機制(Woo等,2018)啟發,將conv4_3特征平均圖視為空間注意力顯著圖,指導網絡更關注的位置。可以直接利用conv4_3特征平均圖作為權重圖,去對其余更深的特征層進行加權,以這種方式將低特征層的目標位置信息傳遞到更深的特征層中,實現特征自下而上的融合。

圖 2?訓練好的LSSD模型從SAR圖像提取的特征圖
Fig. 2?Feature maps extracted by our trained model from SAR image
((a) original images; (b) conv3_3; (c) conv4_3; (d) conv7; (e) conv8)
2.2 特征雙向融合實施流程
采用的雙向特征融合操作流程如圖 3所示。首先進行自上而下的語義聚合,然后實施注意力機制引導下的自下而上的特征融合。語義聚合模型(圖 3(a))主要包括深層特征上采樣、特征圖通道維串聯以及1×1卷積修正通道數等過程,最終融合特征與淺層特征在空間維和通道維的尺寸相同。基于注意力引導的特征融合模塊如圖 3(b)所示,來自conv4_3的特征圖在通道維進行平均池化,得到大小為pp的平均特征圖FF,作為融合中的注意力圖。FF通過sigmoid函數進行歸一化,得到注意力權重圖,具體計算為
?
|
F(x)=11+e?xF(x)=11+e?x |
(5) |
?
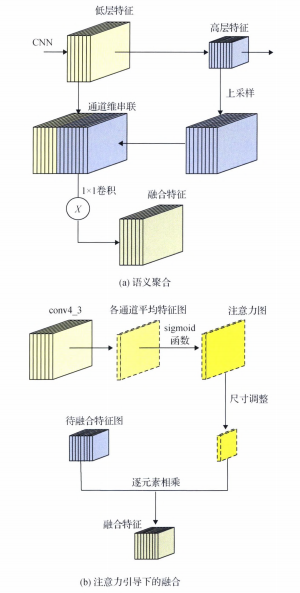
圖 3?特征融合算法流程圖
Fig. 3?Framework of our feature fusion module
((a) semantic aggregation block; (b) attention guided fusion block)
式中,xx代表FF中各像素值,F(x)∈(0,1)F(x)∈(0,1)。該權重圖被用來對其余特征層進行加權。融合前,需要通過下采樣等方式將權重圖的大小改為高層特征圖的空間大小,然后對高層特征的每個通道的特征圖進行逐元素相乘的操作,得到融合特征圖。注意該操作只自下而上進行,conv4_3特征圖得到的注意力權重圖不再影響conv3_3。
3 實驗與結果分析
對本文方法利用公開的SSDD數據集進行實驗,首先利用基于聚類的數據集目標特性統計方法指導的網絡參數設置與原SSD網絡參數設置進行對比,然后逐步對比本文方法每一模塊的效果,最后將本文方法與其他SAR艦船目標檢測的方法進行對比。
3.1 數據集說明與實驗設置
SSDD數據集是國內第1個公開的SAR艦船目標檢測數據集,包含1 160幅圖像與2 456個艦船實例。實驗平臺操作系統為64位單GTX 1080Ti GPU計算機,操作系統為Ubuntu 16.06,編程語言為Python,使用的深度學習框架為TensorFlow,并使用CUDA9.0與cuDNN7.0加速。訓練次數設為12萬次,前2萬次初始學習率為0.000 1,接下來6萬次學習率設為0.000 01,最后4萬次學習率設為0.000 001。訓練中,批次容量設為24,使用momentum訓練優化器。
為評價測試結果,采用精確率(precision)、召回率(recall)以及平均精確率(average precision,AP)作為客觀評價指標,指標的具體定義與Kang等人(2017)采用的定義相同。精確率和召回率是在交并比(intersection-over-union,IoU)閾值設為0.5、分類得分閾值設為0.2的情況下計算的。這些指標值越高,說明算法檢測性能越好。此外,利用單幅圖像的平均訓練與測試時間衡量算法的運行速度。
3.2 實驗結果
3.2.1 網絡參數設置對檢測結果的影響
實驗采用兩組參數設置在SSD模型上進行。一組為SSD原始參數,錨框采用SSD模型中的6層特征,如表 1所示;另一組為使用本文提出的基于聚類的數據集目標特性學習方法為指導的網絡參數,錨框采用LSSD模型中的4層特征,如表 2所示。
表 1?采用SSD模型中6層特征的錨框參數
Table 1?Anchor settings of SSD in the 6 feature layers
| 卷積層 | 尺度 | 長寬比 | 額外尺度 |
|---|---|---|---|
| conv4_3 | 0.1 | 1 :1, 1 :2, 2 :1 | 0.141 4 |
| conv7 | 0.2 | 1 :1, 1 :2, 2 :1, 1 :3, 3 :1 | 0.273 9 |
| conv8_2 | 0.375 | 1 :1, 1 :2, 2 :1, 1 :3, 3 :1 | 0.454 1 |
| conv9 | 0.55 | 1 :1, 1 :2, 2 :1, 1 :3, 3 :1 | 0.631 5 |
| conv10 | 0.725 | 1 :1, 1 :2, 2 :1 | 0.807 8 |
| conv11 | 0.9 | 1 :1, 1 :2, 2 :1 | 0.983 6 |
表 2?采用LSSD模型中4層特征的錨框參數
Table 2?Anchor settings of LSSD in the 4 feature layers
| 卷積層 | 尺度 | 長寬比 | 額外尺度 |
|---|---|---|---|
| conv3_3 | 0.005 | 1 :1, 1 :2, 2 :1 | 0.01 |
| conv4_3 | 0.020 | 1 :1, 4 :7, 20 :11 | 0.04 |
| conv7 | 0.060 | 1 :1, 4 :7, 3 :1, 1 :4, 20 :11 | 0.12 |
| conv8_2 | 0.250 | 1 :1, 4 :7, 3 :1, 1 :4, 20 :11 | 0.40 |
兩組實驗除錨框設置不同外,其余實驗條件均相同,實驗結果如表 3所示。可以看出,錨框的參數設置對檢測結果有很大影響。在其他條件不變的前提下,適合檢測數據集的網絡參數設置對挖掘模型的性能潛力非常重要。本文方法不受人為經驗影響,完全基于數據集特性優化網絡參數設置。
表 3?SSD模型采用不同錨框參數的檢測結果
Table 3?Detection results of SSD with different anchors parameters?
| /% | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 參數 | 平均精確率 | 精確率 | 召回率 | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? |
| SSD中6層特征的錨框參數 | 76.95 | 86.35 | 87.00 | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? |
| LSSD中4層特征的錨框參數 |
78.03 |
89.15 |
88.80 |
? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? |
| 注:加粗字體為每列最優結果。 | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? | |||
3.2.2 模型簡化實驗
通過模型簡化實驗的方法驗證所提輕量化設置、雙向特征融合模塊對檢測結果的影響。將采用LSSD模型中4層特征的錨框參數設置的SSD模型作為比較的基準模型,與LSSD模型、結合了語義聚合的LSSD模型、結合了注意力引導融合的LSSD模型以及結合了雙向特征融合方法的LSSD模型分別進行性能指標與速度指標的對比,結果如表 4所示。可以看出,與SSD模型相比,本文提出的LSSD模型在速度方面具有顯著優勢,測試時間僅為SSD模型的65%,而檢測精度與SSD模型基本一致。語義聚合和注意力引導特征融合都可以提高檢測的精度,而在訓練和測試中,只增加了很少的時間。兩個模塊的組合在精度方面實現了最佳性能,平均精確率與SSD相比提高了2.1%。
表 4?模型簡化實驗結果
Table 4?The testing results in ablation study
| 模型 | 語義聚合 | 注意力引導融合 | 平均精確率/% | 精確率/% | 召回率/% | 訓練時間/ms | 測試時間/ms |
|---|---|---|---|---|---|---|---|
| SSD | - | - | 78.03 | 89.15 | 88.80 | 20.79 | 14.02 |
| LSSD | - | - | 77.93 | 89.54 | 88.60 |
12.74 |
9.17 |
| LSSD +語義聚合 | √ | - | 78.68 | 94.55 | 88.00 | 13.01 | 9.72 |
| LSSD +注意力引導融合 | - | √ | 72.20 | 95.26 | 89.20 | 12.97 | 9.57 |
| LSSD +雙向特征融合 | √ | √ |
80.13 |
96.68 |
89.60 |
13.33 | 10.18 |
| 注:加粗字體為每列最優結果。“-”表示沒有采用對應方法,“√”表示采用了該方法。 | |||||||
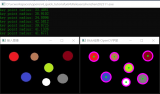
為進一步展示這些模型的檢測結果,圖 4給出了部分典型檢測結果樣例。可以看出,結合了雙向特征融合模塊的模型在提升召回率、減少虛警率等方面表現最佳,說明本文的融合方法是一種有效的特征優化方法。
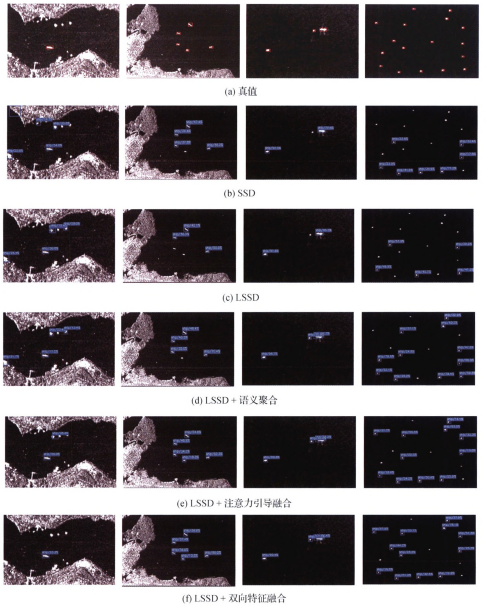
圖 4?不同方法部分檢測結果樣例圖
Fig. 4?Some samples of detecting results using different methods((a) ground truths; (b) SSD; (c) LSSD; (d) LSSD with semantic aggregation module; (e) LSSD with attention fusion module; (f) LSSD with bi-directional fusion module)
3.2.3 與其他方法對比
為進一步驗證本文方法的有效性與實用性,與Faster RCNN(Ren等,2017)、基于卷積神經網絡的檢測模型(CNN-based model)(李健偉等,2018)、基于生成對抗網絡(generative adversarial network,GAN)和線上難例挖掘(online hard example mining,OHEM)的檢測模型(李健偉等,2019)以及密集連接的端到端檢測網絡(densely connected end-to-end neural network)(Jiao等,2018)等模型進行對比實驗,以上對比模型依次稱為模型1、模型2、模型3、模型4,結果如表 5所示。
表 5?本文方法與其他艦船檢測方法對比結果
Table 5?Detection results of different models for comparison
| 模型 | 平均精確率/% | 精確率/% | 召回率/% | 訓練時間/ms | 測試時間/ms |
|---|---|---|---|---|---|
| 模型1 | 73.24 | 92.31 | 88.80 | 540.42 | 159.11 |
| 模型2 | 78.90 | 93.10 | 86.40 | 572.67 | 185.53 |
| 模型3 | 70.24 | 82.01 | 78.40 | 2 152.09 | 330.78 |
| 模型4 | 77.84 | 95.21 | 83.60 | 561.82 | 180.95 |
| 本文 |
80.13 |
96.68 |
89.60 |
13.33 |
10.18 |
| 注:加粗字體為每列最優結果。 | |||||
模型2和模型4都是基于Faster RCNN模型提出的,與Faster RCNN模型相比,它們提高了檢測精度,同時也增加了平均訓練和測試的時間。但是,與本文的單階段檢測方法相比,Faster RCNN在訓練精度上并沒有表現出太大優勢,原因可能由于Faster RCNN系列結構更復雜,像SSDD這樣的小型檢測數據集無法很好地對其進行訓練。模型3利用生成對抗網絡和在線難例挖掘技術來擴大訓練中的數據,并基于RCNN方法進行檢測,不僅速度慢,而且精度也是幾種方法中最低的。而本文方法在召回率和檢測精度等方面都實現了最佳性能,并且在速度方面具有明顯優勢,反映出本文方法的有效性與實用性。
4 結論
本文主要研究SAR圖像艦船目標檢測,著重解決了檢測中速度與精度的平衡問題。為了提高算法的處理速度,設計了輕量化的LSSD模型,與SSD模型相比,需訓練的參數大幅減少,模型可從頭開始訓練而不必依賴預訓練模型。為了提高模型檢測的精度,提出了一種用于參數設置的基于聚類的目標分布特性學習算法,并采用語義聚合塊和新的注意力引導融合塊的雙向特征融合模塊來優化檢測特征,改進了傳統方法中單向特征融合不能優化高層特征的不足。利用公開的SSDD數據集驗證了所提各模塊的效果,結果表明,所提模型在速度和精度方面均表現出良好性能,與基準模型以及其他經典檢測算法相比,訓練和測試速度均有明顯提升,檢測精度也高于其他檢測算法,從檢測結果圖中也可以看出,所提模型有效降低了目標漏檢情況。
然而,盡管本文模型較其他檢測模型表現出更好的速度和精度性能,但測試中仍存在一些失敗案例,如無法較好地檢測密集排列的艦船目標,這也是實驗中各檢測模型存在的普遍問題。其原因主要在于包括本文模型在內的這些模型都采用了垂直矩形邊框作為目標邊界框實施檢測,而相鄰的密集排列艦船目標的檢測框存在大量重疊區域,容易被模型自動合并、刪減,造成檢測框位置不準確甚至漏檢。而采用目標最小外接傾斜矩形框作為目標邊界檢測框可以有效避免這類問題。因此,在今后工作中,將繼續研究基于目標傾斜邊界框的檢測算法,提高檢測效果。此外,本文模型沒有利用SAR圖像的極化信息。如何利用SAR圖像的極化信息提升檢測性能也是接下來一個有意義的研究重點。
?【轉載聲明】轉載目的在于傳遞更多信息。如涉及作品版權和其它問題,請在30日內與本號聯系,我們將在第一時間刪除!
關注微信公眾號:人工智能技術與咨詢。了解更多咨詢!
編輯:fqj



















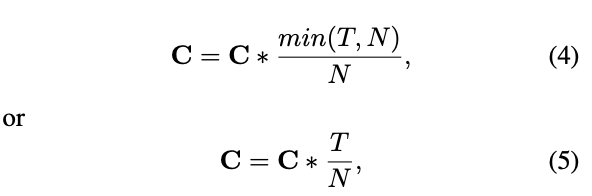















 工商網監
工商網監
評論