 電子發(fā)燒友App
電子發(fā)燒友App


基于句式元學(xué)習(xí)的Twitter分類
人工智能技術(shù)與咨詢?
本文來自《北京大學(xué)學(xué)報(自然科學(xué)版)》,作者閆雷鳴等
摘要?針對多類別的社交媒體短文本分類準確率較低問題, 提出一種學(xué)習(xí)多種句式的元學(xué)習(xí)方法, 用于改善 Twitter 文本分類性能。將 Twitter 文本聚類為多種句式, 各句式結(jié)合原類標簽, 成為多樣化的新類別, 從而原分類問題轉(zhuǎn)化為較多類別的 few-shot 學(xué)習(xí)問題, 并通過訓(xùn)練深層網(wǎng)絡(luò)來學(xué)習(xí)句式原型編碼。用多個三分類Twitter 數(shù)據(jù)來檢驗所提 Meta-CNN 方法 , 結(jié)果顯示, 該方法的學(xué)習(xí)策略簡單有效, 即便在樣本數(shù)量不多的情況下, 與傳統(tǒng)機器學(xué)習(xí)分類器和部分深度學(xué)習(xí)分類方法相比, Meta-CNN 仍能獲得較好的分類準確率和較高的F1值。
關(guān)鍵詞?元學(xué)習(xí); 少次學(xué)習(xí); 情感分析; 卷積神經(jīng)網(wǎng)絡(luò)
對微博和Twitter這類社交平臺的短文本評論信息來說, 在多分類問題上, 即便采用深度學(xué)習(xí)方法, 分類準確率不高仍然是困擾業(yè)界的一個難題。社交平臺的文本評論信息字數(shù)少、語法格式自由、大量使用縮略語和新詞語等, 隱喻、反諷和極性遷移等句型經(jīng)常出現(xiàn), 各類型樣本數(shù)量分布很不平衡,造成社交平臺短文本分類的困難。以 SemEval 2017的Twitter 分類比賽結(jié)果為例, 前三名系統(tǒng)雖然在二分類任務(wù)(正向、負向)上準確率都超過 86%, 但是對于三分類問題(正向、負向和中性), 最好的系統(tǒng)準確率僅為 65.8%, F1-score 為 68.5%[1]。有標簽訓(xùn)練樣本不足是性能偏低的主要原因之一。隨著分類類別的增加, 樣本分布不平衡的情況進一步加劇,總體需要的訓(xùn)練樣本進一步增加。雖然遷移學(xué)習(xí)策略希望通過遷移到其他領(lǐng)域, 利用已有的領(lǐng)域知識來解決目標領(lǐng)域中僅有少量有標記樣本的問題[2],但由于社交媒體短文本長度短、形式自由以及常違背語法的特點, 難以遷移其他源領(lǐng)域的知識。分類模型的泛化能力不足是另一個主要原因。由于句型的靈活多變, 詞語的組合形式難以窮盡, 訓(xùn)練樣本不可能覆蓋所有的語義形式, 即測試樣本中有大量形式?jīng)]有出現(xiàn)在訓(xùn)練樣本中, 因此模型無法正確識別。
目前在社交媒體的短文本情感分析方面, 特別是多級情感分類方面的研究, 仍然面臨有標簽樣本數(shù)量不足、分類模型泛化能力不足的挑戰(zhàn)。本文提出一種適合少樣本、多類別的 Twitter 分類框架, 該框架基于 few-short learning 策略, 利用 deep CNNs提取樣本的 meta-features, 用于識別訓(xùn)練樣本中未出現(xiàn)的類型, 從而提高分類模型的泛化(generalization)能力。
1 相關(guān)研究
詞向量被設(shè)計成詞的低維實數(shù)向量, 采用無監(jiān)督學(xué)習(xí)方法, 從海量的文本語料庫中訓(xùn)練獲得, 語法作用相似的詞向量之間的距離相對比較近[3], 這就讓基于詞向量設(shè)計的一些模型能夠自帶平滑功能, 為應(yīng)用于深層網(wǎng)絡(luò)帶來便利[4]。一些將詞向量與長短期記憶網(wǎng)絡(luò)(LSTM)相結(jié)合的研究都獲得明顯的性能改善[5-6]。Kim[7]設(shè)計的文本卷積神經(jīng)網(wǎng)絡(luò), 雖然只有一層卷積層, 但其分類性能顯著優(yōu)于普通的機器學(xué)習(xí)分類算法, 例如最大熵、樸素貝葉斯分類和支持向量機等。Tang 等[8]基于深度學(xué)習(xí),設(shè)計 Twitter 情感分析系統(tǒng) Cooolll, 將詞向量與反映 Twitter 文法特點的特征(例如是否大寫、情感圖標、否定詞、標點符號簇集等)進行拼接, 以求輸入更多有效的特征, 在 SemEval 2104 國際語義評測競賽中獲得第 2 名。深度學(xué)習(xí)方法需要大量的訓(xùn)練樣本, 增加訓(xùn)練樣本是非常有效的提高分類準確率的方法, 但是成本很高, 甚至在很多情況下難以實施, 制約了基于深度學(xué)習(xí)的文本分類方法的性能。
Few-shot 學(xué)習(xí)[9-10]是近年興起的一種新型元學(xué)習(xí)技術(shù), 使用較少樣本訓(xùn)練深層網(wǎng)絡(luò)模型, 主要應(yīng)用于圖像識別領(lǐng)域, 目前只有非常少的研究將其用于文本分析。這種方法首先以zero-shot (零次)學(xué)習(xí)和 one-shot (一次)學(xué)習(xí)出現(xiàn), 逐步發(fā)展成 few-shot學(xué)習(xí)。此類方法的基本思想是, 將圖片特征和圖片注釋的語義特征非線性映射到一個嵌入空間, 學(xué)習(xí)其距離度量。當(dāng)輸入未知樣本或未出現(xiàn)在訓(xùn)練集中的新類別樣本時, 計算樣本與其他已知類別的距離,判斷其可能的類別標簽。雖然有標簽的訓(xùn)練樣本較少, 但此類方法仍然在圖像識別領(lǐng)域(特別是在圖片類別達到數(shù)百到 1000 的分類任務(wù)中)獲得成功。Zhang 等[11]研發(fā)了一種基于最大間隔的方法, 用于學(xué)習(xí)語義相似嵌入, 并結(jié)合語義相似, 用已知類別的樣本度量未知類別樣本間的相似性。Guo 等[12]設(shè)計了一種新穎的 zero-shot 方法, 引入可遷移的具有多樣性的樣本, 并打上偽標簽, 結(jié)合這些遷移樣本訓(xùn)練 SVM, 實現(xiàn)對未知類別樣本的識別。Oriol 等[13]基于 metric learning 技術(shù)和深層網(wǎng)絡(luò)的注意力機制,提出一種 matching 網(wǎng)絡(luò)機制, 通過支持集學(xué)習(xí)訓(xùn)練CNN 網(wǎng)絡(luò)。Rezende 等[14]將貝葉斯推理與深層網(wǎng)絡(luò)的特征表示組合起來, 進行 one-shot 學(xué)習(xí)。Koch 等[15]訓(xùn)練了兩個一模一樣的孿生網(wǎng)絡(luò)進行圖像識別, 獲得良好的效果。一些學(xué)者基于“原型” (prototype)概念設(shè)計 few-shot 學(xué)習(xí)方法, 但是對原型的定義不一致。Snell 等[16]提出原型網(wǎng)絡(luò)概念, 將滿足k近鄰的數(shù)據(jù)對象非線性映射到一個嵌入空間, 該空間中的原型是同類標簽樣本映射的平均值向量, 通過計算未知樣本與原型的距離來判別類標簽。Blaes等[9]定義的全局原型是一種元分類器, 希望利用全局特征對圖像進行分類。Hecht 等[17]的研究顯示, 基于原型的深度學(xué)習(xí)方法在訓(xùn)練事件和內(nèi)存開銷方面都比普通深度學(xué)習(xí)方法有優(yōu)勢。
2 文本句式元學(xué)習(xí)
受 meta-learning 和圖像 few-shot 學(xué)習(xí)的啟發(fā),本文提出一種文本句式元學(xué)習(xí)方法。基本思想為,將多種典型的語句變化視為新的類別和“句式”, 即將原本只有幾種類別標簽的文本樣本集合, 改造為多種新的類別——“句式”style。劃分出更多的類別后, 強迫深層模型學(xué)習(xí)細粒度的語法和語義特征。本文方法包含 4 個基礎(chǔ)部分:句式提取、訓(xùn)練片段episode 構(gòu)造、句式深層編碼以及分類模型 Finetunning。方法框架如圖1所示。
2.1 提取句式
首先, 將較少類別的文本分類問題轉(zhuǎn)化為較多類別的 few-shot 學(xué)習(xí)問題。本文根據(jù)距離相似度,用k均值聚類方法, 將訓(xùn)練樣本劃分為若干簇集,將每個簇集視為一種文本類型, 并進一步劃分為句式。
定義1?句式:設(shè)類標簽有K種,L={1,2,...,K},聚類獲得的文本類型(句型)有M種,M?K,不同類型和不同類標簽組合為一種新的類別, 稱為“句式”(style)。樣本集合由原來的K種樣本, 重新劃分為N=M×K種句式, 表示為 {sik|1 ≤i≤M,1≤k≤K},新的類別標簽為L′={(i,k)|0 <i≤N,k∈L},k為樣本原始類標簽, 如圖 2 所示。訓(xùn)練集中對應(yīng)新標簽的樣本稱為該句式的支持樣本。
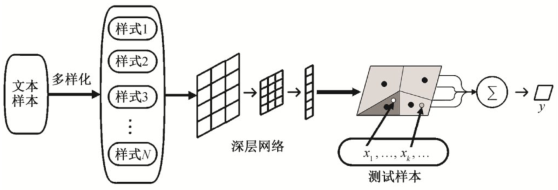
圖1 句式元學(xué)習(xí)框架
Fig.1 Sentence styles meta-learning framework
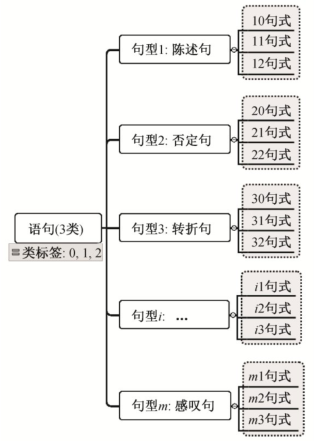
圖2 句式標簽劃分示意圖
Fig.2 Example for sentence style labeling
定義2?元句式:每種句式的支持樣本集合的中心樣本(即代表樣本)稱為元句式。元句式可以用樣本向量的平均值表示。
新的句式數(shù)量大于原來的類別, 相應(yīng)地, 支持每種句式的有標簽樣本減少了, 甚至可能有的句式只有一個樣本。對這類特殊的句式, 可以根據(jù)聚類發(fā)現(xiàn)的離群點進行添加或刪除。我們需要為每種句式構(gòu)造訓(xùn)練集, 相同句式標簽的樣本稱為該句式的“候選支持集”。將這些樣本輸入深層網(wǎng)絡(luò), 再進行有監(jiān)督模型訓(xùn)練。需要注意的是, 劃分為多種句式后, 導(dǎo)致每種不同句式的支持樣本數(shù)大大減少。將原分類任務(wù)直接轉(zhuǎn)變?yōu)橹С謽颖据^少的多分類問題, 不利于提高分類性能。鑒于此, 本文方法借鑒圖像多分類問題的 few-shot 學(xué)習(xí)思想, 劃分多種句式的目的不是直接進行多分類學(xué)習(xí), 而是用于發(fā)現(xiàn)多個具有代表意義的句型原型“prototype”, 通過比較未知類別樣本與句型 prototype 的距離, 提高分類準確率。
鑒于缺少有標簽的句型樣本, 本文采用一種簡單直接的策略, 根據(jù)語句相似距離, 用k均值聚類方法提取句式。用距離相似發(fā)現(xiàn)句式是基于詞向量模型將語句轉(zhuǎn)化為向量。詞向量的優(yōu)點是可在一定程度上表達語義或語法作用相似, 向量疊加時仍然可以保持原有相似性。因此, 聚類方法不能明確發(fā)現(xiàn)否定句、感嘆句、隱喻和反諷等實際句型, 但是可以從向量相似的角度, 將語義和結(jié)構(gòu)上相似的樣本聚為一類。我們采用 Doc2Vec 模型, 將語句轉(zhuǎn)化為向量, 將不同長度的語句都轉(zhuǎn)化為相同長度的向量。實現(xiàn)過程如下。
1)分詞, 訓(xùn)練一個 Doc2Vec 模型, 將每個樣本轉(zhuǎn)化為一個向量, 長度為300。
2)設(shè)定k, 調(diào)用k均值算法, 對文本向量進行聚類。
3)為每個樣本分配新的類別編號=聚類編號×10+原類別編號; 每種新類別為一種“句式”。
4)輸出聚類結(jié)果。
2.2 訓(xùn)練片段(episode)的構(gòu)造
在 few-shot 學(xué)習(xí)中, 模型訓(xùn)練過程由多個episode 構(gòu)成。k-shot 學(xué)習(xí)包含K個片段。通常, 對于N類“句式”, 每種句式的樣本都平均劃分為K份,每個 episode 應(yīng)該包含 1 份樣本作為訓(xùn)練集, 以及 1份樣本作為測試集。為了測試模型對新類別的識別能力, 選擇訓(xùn)練集中未出現(xiàn)的“句式”作為測試集樣本。
2.3 元句式深層編碼
元句式深層編碼即學(xué)習(xí)句式原型。基本思想是, 將N種文本句式的樣本向量, 經(jīng)深層網(wǎng)絡(luò)(例如CNN)映射到一個嵌入空間RD,在DR內(nèi)通過分類算法, 不斷調(diào)整網(wǎng)絡(luò)權(quán)值, 使得該深層網(wǎng)絡(luò)根據(jù)類別標簽和距離, 學(xué)習(xí)可區(qū)分的不同句式的非線性編碼。句式原型經(jīng)深層編碼, 被映射到一個非線性空間, 如圖 3 所示, 每個區(qū)域?qū)?yīng)于一種句式原型,灰色圓點表示該句式的支持樣本, 黑色圓點為該句式的代表點, 即元句式。圖 3 中空心圓圈表示一個未知標簽的新樣本經(jīng)編碼進入嵌入空間, 可以通過計算到各個原型代表點的距離來判斷類標簽。
用于編碼的深層模型, 采用 CNN 網(wǎng)絡(luò)構(gòu)造。基本策略為, 首先用聚類后的、多樣化句式的數(shù)據(jù)有監(jiān)督地訓(xùn)練網(wǎng)絡(luò)學(xué)習(xí)多種句式, 然后使用原始數(shù)據(jù)優(yōu)化模型的分類性能, 在已有 CNN 權(quán)重的基礎(chǔ)上,訓(xùn)練一個新的 softmax 分類層, 對原始數(shù)據(jù)進行分類。
基于 softmax 函數(shù), 分類目標函數(shù)可以定義為,對于未知樣本x*,其屬于任意類的概率:
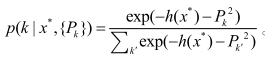
根據(jù)極大似然假設(shè), 基于交叉熵的損失函數(shù)為
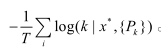
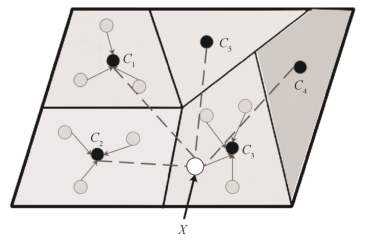
圖3 句式原型與映射空間
Fig.3 Style prototypes and embedding space
綜上所述, 本文所提方法屬于一種 few-shot 學(xué)習(xí)策略, 可將此類方法視為一種元特征學(xué)習(xí)方法,側(cè)重特征向量的學(xué)習(xí), 發(fā)現(xiàn)樣本的原型 prototype,其優(yōu)化函數(shù)通常不以距離為直接目標, 這與 metriclearning 方法有一定的區(qū)別。在實現(xiàn)上也與 metriclearning 有所不同, few-shot 學(xué)習(xí)需要基于深層網(wǎng)絡(luò)搭建模型。但是從最新的研究成果[9-10]來看, 由于few-shot 學(xué)習(xí)通常利用k近鄰思想進行最后的分類,因此 metric-learning 方法對于 few-shot 有很強的借鑒意義, 二者的融合應(yīng)該是一種必然的趨勢。本文所提“元句式”的概念, 更類似于一種句子“prototype”, 基本思想是發(fā)現(xiàn)并深層編碼這些基本prototype, 計算樣本與 prototype 樣本的距離, 通過加權(quán)來判斷樣本類別。
3 實驗
使用 3 個公開的 Twitter 數(shù)據(jù), 驗證本文的方法,并對結(jié)果進行分析。實驗服務(wù)器配置為 12 核至強CPU, 256 GB 內(nèi)存, 8顆NVIDIA Tesla K20C GPU,操作系統(tǒng)為 Ubuntu 14.0。代碼基于 Tensor-flow 和Keras, 使用Python2.7實現(xiàn)。
本文模型的基本結(jié)構(gòu)包括2層1維卷積層、過濾器 128 個, 過濾器尺寸為 5, 后接 Max-pooling 層和 Dropout 層, 再接一層全連接的神經(jīng)網(wǎng)絡(luò), 激活函數(shù)選擇 Relu, 最后是一個 softmax 分類層。參數(shù)優(yōu)化使用 Adam, 交叉熵作為損失函數(shù), batch size 取50。文本聚類時, 利用 gensim 中的 Doc2Vec 工具實現(xiàn)語句向量化。訓(xùn)練分類模型時, 首先使用聚類后的、增加了句式標簽的數(shù)據(jù)進行模型的預(yù)訓(xùn)練, 再使用原始的數(shù)據(jù)集, 用一個新的 softmax 分類層進行fine-tunning。
3.1 數(shù)據(jù)集
1)MultiGames。該數(shù)據(jù)集為游戲主題的 Twitter數(shù)據(jù), 共 12780 條, 由人工進行情感類型標注, 包括正向 3952 條、負向 915 條和中性 7913 條游戲玩家評論。該數(shù)據(jù)集由加拿大 UNB 大學(xué) Yan 等[18]發(fā)布。該數(shù)據(jù)集中的評論多俚語、網(wǎng)絡(luò)用語以及部分反話。
2)Semeval_b。該數(shù)據(jù)源自國際語義評測大會SemEval-2013 發(fā)布的比賽數(shù)據(jù)[19], 后經(jīng)不斷更新,所有數(shù)據(jù)由人工標注為正向、負向和中性 3 種情感類別。由于部分 tweets 的鏈接失效, 我們共下載7967條數(shù)據(jù)。
3)SS-Tweet。Sentiment Strength Twitter (SSTweet)數(shù)據(jù)集共包含 4242 條人工標注的 tweets 評論。該數(shù)據(jù)最早由 Thelwall 等[20]發(fā)布, 用于評估基于SentiStrenth的情感分析方法。Saif 等[21]對該數(shù)據(jù)重新注釋為正向、負向和中性 3 種情感類別。本文實驗所用數(shù)據(jù)包括 1252 條正向、1037 條負向和1953條中性評論。
所有數(shù)據(jù)集均隨機劃分為 3 個部分, 驗證集和測試集各占 15%, 其余作為訓(xùn)練集。
3.2 實驗結(jié)果與分析
本文以代價敏感的線性支持向量機為基準方法, 特征提取選擇過濾停止詞、詞性標注(POS)、情感符號 Emoticon 和 Unigram。本文方法命名為Meta-CNN。用于對比的深度學(xué)習(xí)方法包括基于自動編碼器的 DSC[18]、文本 Kim-CNN[7]和一個兩層一維卷積層構(gòu)造的 CNN 模型 2CNN1D。DSC 方法仍然提取 POS 和 Emoticon特征, 并過濾停止詞, 然后輸入自動編碼器進行重編碼。Kim-CNN 雖然僅包含一層卷積操作, 但在文本分類中常能獲得較好的準確率。2CNN1D 的網(wǎng)絡(luò)結(jié)構(gòu)與本文用于預(yù)訓(xùn)練的 CNN 結(jié)構(gòu)相同, 與本文 Meta-CNN 方法進行比較, 用于驗證 Meta-CNN 是否能夠在雙層 CNN 網(wǎng)絡(luò)基礎(chǔ)上改善分類性能。基于 CNN 的方法均不做停止詞過濾等預(yù)處理, 分詞后, 直接使用 Google 的預(yù)訓(xùn)練 word2vec 包 GoogleNews-vectors-negative300-SLIM, 轉(zhuǎn)換為詞向量構(gòu)成的語句矩陣, 詞向量長度為300。對所有語句樣本, 利用 Padding 操作將長度統(tǒng)一轉(zhuǎn)化為 150 個詞, 不足 150 個詞時補 0。各方法獲得的最佳準確率如表1所示。
由于數(shù)據(jù)分布不均衡, 不同類別樣本數(shù)量有較大差距, 特別是負向標簽樣本, 通常比中性標簽樣本少很多。數(shù)據(jù)分布的不均衡性對分類器的準確率有較大的負面影響。為了更加客觀地進行評價, 參照 SemEval 對多分類問題上的評價標準, 我們使用正向(Positive)、負向(Negative)樣本的平均 F1 值作為多分類任務(wù)的評價方法。指標計算方法如下:

各方法的值如表 2 所示。可以看出, 基于深度學(xué)習(xí)方法的準確率優(yōu)于線性 SVM。本文提出的 Meta-CNN 方法在 3 個數(shù)據(jù)集上均取得最高的準確率。與 2CNN1D 分類模型相比, 本文 Meta-CNN方法的準確率大大提高, 說明本文方法在預(yù)訓(xùn)練模型的基礎(chǔ)上進行調(diào)優(yōu), 對改善分類性能是有效的。
樣本數(shù)量對模型的性能影響明顯。SS-Tweet數(shù)據(jù)的樣本較少, 從 DSC, Kim-CNN 和 2CNN1D的分類準確率來看, 并未顯著優(yōu)于線性 SVM。但是,本文方法仍然獲得較好的分類性能。
句式種類k的取值對本文方法的準確率有較明顯的影響, 如圖 4 所示。對于數(shù)據(jù)集 MultiGames, 當(dāng)句式的聚類數(shù)k=10 時, 可以獲得 91.6%的準確率。Semeval_b 和 SS-Tweet 數(shù)據(jù)在k=5 時獲得較優(yōu)的準確率。隨著k值增大, 準確率有所波動, 總趨勢下降。這是因為, 隨著k值增大, 分類的類別急劇增大, 預(yù)訓(xùn)練模型的分類準確率下降, 從而影響 finetunning時的模型性能。
表1 準確率對比
Table 1 Accuracy comparision

表2 正負向樣本平均F1對比
Table 2?

comparision
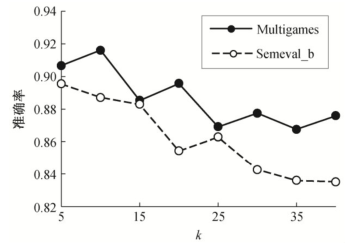
圖4 句式數(shù)量k對分類性能的影響
Fig.4 Relationship between style numberkand accuracy
從實驗結(jié)果來看, 在句式劃分基礎(chǔ)上實現(xiàn)的句式原型學(xué)習(xí), 在一定程度上改善了分類性能, 說明合理的句式劃分有助于提取句子結(jié)構(gòu)特征, 這些特征的引入改善了文本分類性能。但是, 一定程度的句式數(shù)量增加導(dǎo)致類別數(shù)量的增加, 顯然對分類性能有負面影響。本文基于聚類的句式劃分方法不能對句式進行精確的劃分, 因此句式數(shù)量越多, 句型特征提取的誤差積累越大。合理的句式數(shù)量需要通過實驗確定。增加訓(xùn)練樣本數(shù)量是實踐中一種有效提高分類性能的策略。但是, 對于文本分類任務(wù)來說, 多少樣本數(shù)量才是足夠的?對這一問題, 目前在理論上沒有明確的結(jié)論。從實踐和國際上一些 Twitter 分類競賽結(jié)果來看, 數(shù)萬條訓(xùn)練樣本還不足以保證獲得滿意的分類性能, 對于可視為多類別分類的Twitter 情感程度劃分任務(wù), 準確率往往只能達到65%左右。如果成本在可承受的范圍內(nèi), 不能通過數(shù)百萬條訓(xùn)練樣本來訓(xùn)練分類樣本, 那么設(shè)計少樣本學(xué)習(xí)策略來提升分類器性能, 就成為值得研究的方向。本文就是針對少樣本的文本分類研究的一種嘗試。
4 結(jié)語
本文基于元學(xué)習(xí)和 few-shot 學(xué)習(xí)策略, 提出一種文本元學(xué)習(xí)框架, 通過學(xué)習(xí)不同的句式特征, 提取更為細粒度的文本語句特征, 以期改善文本分類性能。多個數(shù)據(jù)集的實驗結(jié)果證實了本文所提方法的有效性, 對于有標記樣本較少情況下的多類別文本分類問題, 使用元學(xué)習(xí)策略, 可以改善多類別文本分類的性能。同時, 本文對“句式”的定義仍舊比較粗糙, 實驗結(jié)果顯示過多的句式數(shù)量, 不利于提高分類性能。后續(xù)研究方向包括:改造其他 metalearning 方法, 使之適用于文本分類任務(wù); 在與本文方法多角度的比較中, 改進本文所提方法; 提出更加精細的句式劃分策略, 以便準確地提取更多的有益語句特征。
關(guān)注微信公眾號:人工智能技術(shù)與咨詢。了解更多咨詢!
編輯:fqj





























































 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論