 電子發燒友App
電子發燒友App


來源:半導體行業觀察
由 Amazon Web Services 的 Annapurna Labs 部門設計的 Graviton 系列 Arm 服務器芯片可以說是當今數據中心市場上產量最大的 Arm 服務器芯片,并且它們恰好擁有一個且只有一個客戶,也是直接客戶——AWS。
這兩個事實說明了Annapurna Labs 為創建更強大的 Arm 服務器處理器所做的設計選擇,并且它們區別于其他兩種針對當今市場上服務器的合理大容量 Arm 服務器 CPU,即富士通的 A64FX 處理器和Ampere Computing 的 Altra 家族。還有其他針對特定地區和用例的 Arm 服務器芯片正在開發中,這似乎總是存在,但它們看起來都不會像 Graviton 和 Altra 系列那樣成為批量產品;富士通 A64FX 是量產產品,因為有使用它的主機——日本理研實驗室的“Fugaku”超級計算機。
AWS 在拉斯維加斯的 re:Invent 大會上推出了第三代 Graviton3 服務器芯片,我們未能參加,我們在 12 月根據當時可用的摘要信息對處理器進行了概述,承諾在提供更多來自技術會議的信息時回過頭來進行更深入的研究。該信息現在可以從云巨頭負責 Graviton 實例的高級首席工程師 Ali Saidi 的演示中看到。Saidi 更詳細地介紹了預覽中的 64 核、550 億晶體管 Graviton3 與其前身——2018 年 11 月預覽的 16 核、50 億晶體管 Graviton 和 2019 年 11 月預覽的64 核、300 億晶體管 Graviton2 的不同之處。AWS 需要幾個月的時間才能使 Graviton 芯片全面生產,一旦使用 Graviton3 芯片的 EC2 服務上的 C7g 實例全面生產并停止預覽,我們就會知道更多。
首先,Saidi 談到了為什么 AWS 甚至費心制造自己的服務器 CPU,也許制造自己的“Nitro”DPU 來卸載 X86 服務器處理器的管理程序以及安全處理和存儲以及網絡虛擬化似乎就足夠了。
“構建我們自己的芯片確實讓我們能夠在各種層次上進行創新,更快地創新,提高安全性,并提供更多價值,”Saidi解釋道。“在創新方面,能夠構建芯片和服務器,并讓編寫軟件的團隊在一個屋檐下進行,這意味著創新速度更快,我們可以跨越傳統界限。我們也可以為我們的需要制造芯片。我們可以將它們專門用于我們正在嘗試做的事情,而不必添加其他人想要的功能。我們可以只為我們認為將為我們的客戶提供最大價值的東西構建它們,而忽略那些實際上不是的東西。我們得到的第三件事是速度。我們可以控制項目的開始、進度和交付。我們可以并行化硬件和軟件開發,并使用大規模的云來進行構建芯片所需的所有模擬。最后,操作。通過運行 EC2,我們可以深入了解操作,我們可以將功能放入芯片中,以執行諸如刷新固件以解決問題或增強功能等操作,而不會打擾在機器上運行的客戶。”
顯然,Graviton 的努力不僅僅是從英特爾和 AMD 那里獲得更便宜的 X86 服務器芯片價格——盡管它也是如此,即使Saidi沒有提到它。但只要 AWS 在其云中托管大量 X86 客戶,它就會為其云客戶購買 Xeon SP 和 Epyc 處理器,用于他們創建的那些不易移植到 Arm 架構并因此從 20 Graviton 系列在 EC2 上的 X86 實例上顯示了 1% 到 40% 的性價比優勢,涵蓋了廣泛的工作負載和場景。
沒有人確切知道 AWS 隊列中有多少 Graviton 處理器,但我們所知道的是 Graviton 處理器以某種方式在 23 個不同的 AWS 區域和十幾種不同的 EC2 實例類型中可用。

AWS擁有超過475不同的EC2實例類型,其在CPU,內存,存儲,網絡和加速器配置方面運行域,以及Graviton實例是明顯的一個很小的部分品種EC2 實例。24 個地區中有 23 個至少擁有一些 Graviton 處理器,這或許更能說明 Graviton 在 AWS 機群中的流行——但不一定。我們認為可以誠實地說,與運行 Web 式工作負載的 X86 處理器相比,性價比提高了 30% 到 40%,并且隨著產品線的發展,Graviton 芯片的功能越來越強大,我們認為 AWS 軟件工作負載的一部分越來越大與在運行 Windows Server 或 Linux 的 X86 處理器上運行其他人的應用程序無關——比如無數的數據庫和 SageMaker AI 服務——最終將使用 Graviton,從而降低這些服務的總體成本,同時保持 AWS 的利潤。

事實上,Saidi 表示,對于 AWS 兜售的 PaaS 和 SaaS 服務,如果客戶在注冊服務時沒有特別指定實例類型,他們將在該服務下獲得一個 Graviton 實例。這表明 AWS 隊列中有相當多的 Graviton 服務器。事實上,在今年的 Prime 會員日,安裝在 EC2 服務下的 Graviton2 實例支持了亞馬遜在線零售業務使用的十幾個核心零售服務。曾經支持跨 Amazon 內部零售數據服務的查找、查詢和聯接的關鍵服務 Datapath 從 X86 服務器移植到由超過 53,000 個基于 Graviton2 的 C6g 實例組成的三區域集群。
這就是事實,這可能也是為什么英特爾和 AMD 需要在 15 年前構建自己的云,而不是讓戴爾、惠普企業和 VMware 嘗試并失敗的原因。在不久的將來,CPU 將成為數據中心的弱勢群體。
這也是英偉達今年與 AWS 合作使其 HPC SDK 在其基于 Graviton 處理器的 ParallelCluster 超級計算服務上運行的原因,這將允許使用 OpenMP 的 C、C++ 和 Fortran 程序并行化應用程序以在 Graviton 實例上運行,并且這也是 SAP 與 AWS 合作將其 HANA 內存數據庫移植到 Graviton 實例并將這些實例用作 SAP 自己的托管在 AWS 上的 HANA 云服務的基礎的原因。
探索Graviton3內部
Saidi 的演講比 re:Invent 主題演講詳細得多,實際上展示了 Graviton3 封裝的一個鏡頭,這是我們聽說的小芯片(chiplet)設計。這是顯示 Graviton3 封裝的幻燈片:

這個die頂部的特寫圖像放大了一點,但原始圖像是模糊的——所以不要怪我們。這與 Graviton3 封裝的圖像一樣好。
下面的示意圖讓 Graviton3 上的小芯片如何分解其功能更加清晰:
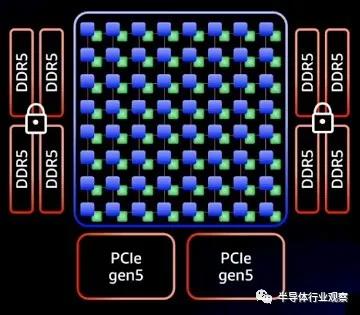
Annapurna Labs 團隊沒有像 AMD 使用“Rome”Epyc 7002 和“Milan”Epyc 7003 X86 服務器芯片那樣擁有中央 I/O 和內存芯片,然后圍繞它的小芯片內核,而是保留了所有 64 個內核在中心的 Graviton3 上,然后斷開與這些內核分離的 DDR5 內存控制器(具有內存加密)和 PCI-Express 5.0 外圍控制器。封裝底部有兩個 PCI-Express 5.0 控制器和四個 DDR5 內存控制器,封裝兩側也各有兩個。(這是第一個支持 DDR5 內存的服務器芯片,其帶寬比當今服務器中常用的 DDR4 內存高 50%。當然,今年其他芯片也會跟進。)
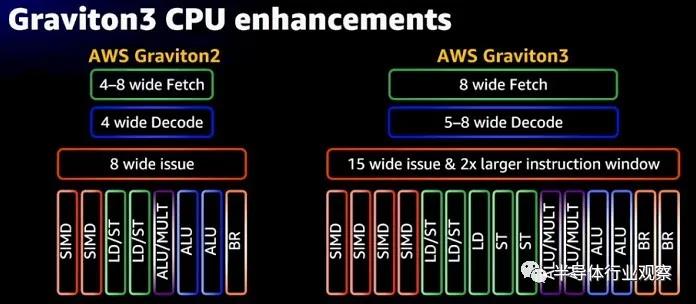
與 Graviton2 相比,Graviton3 增加了 250 億個晶體管,其中大部分,據Saidi 說,是為了加強內核,正如 AWS 公用事業計算高級總裁 Peter DeSantis已經在他的主題演講中解釋的那樣,這個想法是通過加強pipeline讓內核做更多種類的工作以及更多的工作。像這樣:
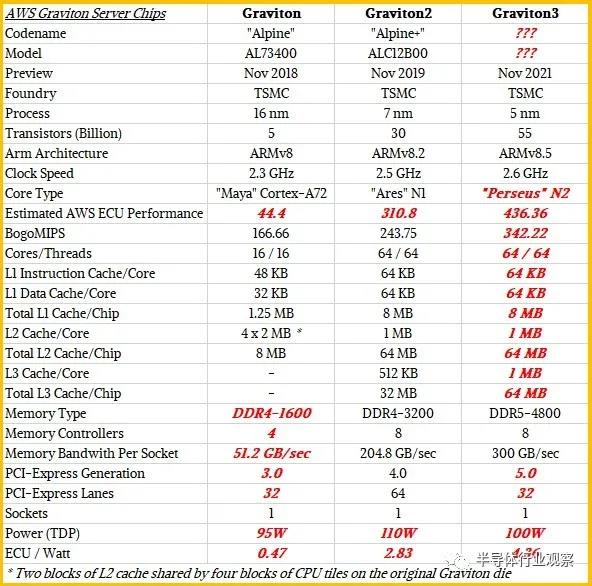
Graviton2 基于 Arm Holding 的 Neoverse “Ares”N1 內核設計的,他們在去年 4 月又發布了“Perseus”V1 和“Zeus”N2 內核。正如我們已經指出的,與一些人的看法相反,我們認為 Graviton3 是基于 N2 核心,而不是 V1 核心。AWS 尚未確認正在使用什么核心。我們做了大量嘗試,試圖去確認 Annapurna Labs 在 Graviton3 中的確使了 N2 核心。我們公開承認,這是一個瘋狂的猜測,因為紅色粗體顯示的項目是:
無論如何,回到pipeline方面。Saidi 解釋說,與 Graviton2 的 N1 內核相比,Graviton3 內核的性能提高了 25%——我們認為這意味著更高的每時鐘指令數或 IPC。Graviton3 以稍高的時鐘速度運行(2.6 GHz,而 Graviton2 為 2.5 GHz)。據Saidi 說,核心的前端寬度是原來的兩倍,而且還有一個更大的分支預測器。指令調度幾乎是兩倍寬,指令窗口是兩倍寬,SIMD向量單元具有兩倍的性能并支持SVE(富士通和Arm為富岳超級計算機的A64FX處理器發明的可變長度可伸縮向量擴展在 RIKEN)和 BFloat16(由 Google Brain 人工智能團隊創建的創新格式)。每個時鐘有兩倍的內存操作來平衡這一切,還有一些增強的預取器,可以將兩倍的未完成事務泵送到那些增強的 Gravition3 內核。核心的乘法器更寬,數量是其兩倍。
與之前的 Graviton 和 Graviton2 內核以及 Ampere Computing Altra 系列中使用的內核一樣,Graviton3 內核中沒有試圖提高吞吐量的超線程。不安全和更復雜的權衡不值得提高性能 - 至少對于 AWS 對其應用程序進行編碼的方式。
AWS 沒有做的另一件事是添加 NUMA 電子設備以將多個 Graviton3 CPU 連接到一個共享內存系統中,并且它也沒有像英特爾通過電路和 AMD 使用其至強 SP 那樣將核心塊分解為 NUMA 區域,在羅馬或米蘭 Epyc 封裝上使用八個核心tiles。內核與運行頻率超過 2 GHz 且對分帶寬超過 2 TB/秒的網格互連。
Graviton3 的一個優點是服務器,我們早在 12 月就談到了這一點,AWS 正在創建一個自產的三節點、三插槽服務器,它有一個共享的 Nitro DPU,將它們連接到外部世界。像這樣:
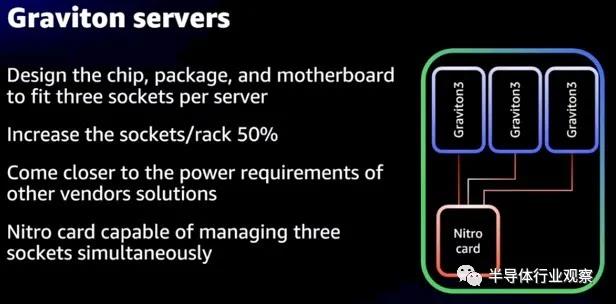
通過將大量 CPU 功能卸載到 Nitro DPU 并將一堆單插槽 Graviton3 節點塞到卡上,AWS 表示它可以將每個機架的插槽增加 50%——這大概意味著不會犧牲任何相關的性能來自 AMD 的 X86 處理器也處于合理的散熱范圍內。
我們已經在之前的 Graviton3 報道中討論了一系列性能指標,但是這個顯示 SPEC 2017 整數和浮點測試很有趣:
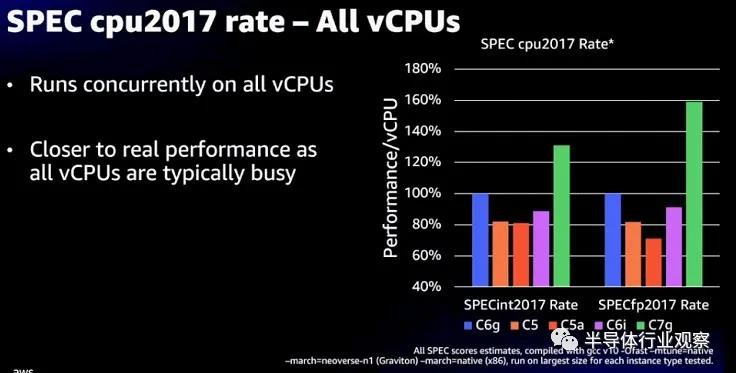
C7g 實例使用 Graviton3,C6g 使用 Graviton2,這表明前者的整數性能比后者高約 30%,浮點性能比后者高約 60%。C5 實例基于英特爾定制的“Cascade Lake”Xeon SP 處理器,而 C5a 實例基于 AMD 的 Rome Epyc 處理器。C6i 實例基于“Ice Lake”Xeon SP。我們更希望擁有這些實例的實際核心數和時鐘速度以進行更好的比較,但很明顯 AWS 想要給人的印象是 Graviton2 已經擊敗了競爭對手,而 Graviton3 確實做到了。
任何真正的比較都將著眼于整數和浮點工作的核心數、成本、散熱和性能,然后權衡所有這些因素,以選擇芯片以在實際應用中進行實際基準測試。SPEC 測試只是玩游戲的賭注。但他們不是游戲。
封面圖片來源:半導體行業觀察
免責聲明:該文章系轉載,登載該文章目的為更廣泛的傳遞市場信息,文章內容僅供參考。
如有內容圖片侵權或者其他問題,請聯系半導體芯科技進行刪除。
審核編輯:鄢孟繁

































 工商網監
工商網監
評論