 電子發(fā)燒友App
電子發(fā)燒友App


卷積神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)優(yōu)化綜述
近年來,卷積神經(jīng)網(wǎng)絡(luò)(Convolutional neural network,CNNs)在計(jì)算機(jī)視覺、自然語言處理、語音識別等領(lǐng)域取得了突飛猛進(jìn)的發(fā)展,其強(qiáng)大的特征學(xué)習(xí)能力引起了國內(nèi)外專家學(xué)者廣泛關(guān)注.然而,由于深度卷積神經(jīng)網(wǎng)絡(luò)普遍規(guī)模龐大、計(jì)算度復(fù)雜,限制了其在實(shí)時要求高和資源受限環(huán)境下的應(yīng)用.對卷積神經(jīng)網(wǎng)絡(luò)的結(jié)構(gòu)進(jìn)行優(yōu)化以壓縮并加速現(xiàn)有網(wǎng)絡(luò)有助于深度學(xué)習(xí)在更大范圍的推廣應(yīng)用,目前已成為深度學(xué)習(xí)社區(qū)的一個研究熱點(diǎn).本文整理了卷積神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)優(yōu)化技術(shù)的發(fā)展歷史、研究現(xiàn)狀以及典型方法,將這些工作歸納為網(wǎng)絡(luò)剪枝與稀疏化、張量分解、知識遷移和精細(xì)模塊設(shè)計(jì)4 個方面并進(jìn)行了較為全面的探討.最后,本文對當(dāng)前研究的熱點(diǎn)與難點(diǎn)作了分析和總結(jié),并對網(wǎng)絡(luò)結(jié)構(gòu)優(yōu)化領(lǐng)域未來的發(fā)展方向和應(yīng)用前景進(jìn)行了展望.
卷積神經(jīng)網(wǎng)絡(luò)(Convolutional neural network,CNNs)作為最重要的深度模型之一,由于具有良好的特征提取能力和泛化能力,在圖像處理、目標(biāo)跟蹤與檢測、自然語言處理、場景分類、人臉識別、音頻檢索、醫(yī)療診斷諸多領(lǐng)域獲得了巨大成功.卷積神經(jīng)網(wǎng)絡(luò)的快速發(fā)展一方面得益于計(jì)算機(jī)性能的大幅提升,使得構(gòu)建并訓(xùn)練更大規(guī)模的網(wǎng)絡(luò)不再受到硬件水平的限制;另一方面得益于大規(guī)模標(biāo)注數(shù)據(jù)的增長,增強(qiáng)了網(wǎng)絡(luò)的泛化能力.以大規(guī)模視覺識別競賽(ImageNet large scale visual recognition competition,ILSVRC)的歷屆優(yōu)秀模型為例,AlexNet[1] 在ILSVRC 2012 上的Top-5識別正確率達(dá)到83.6%,隨后幾年卷積神經(jīng)網(wǎng)絡(luò)的性能持續(xù)提升[2?4],ResNet-50[5] 在ILSVRC 2015上的Top-5 識別正確率達(dá)到96.4%,已經(jīng)超過人類平均水平.在此之后,卷積神經(jīng)網(wǎng)絡(luò)被進(jìn)一步應(yīng)用于其他領(lǐng)域,比如由谷歌DeepMind 公司開發(fā)的人工智能圍棋程序AlphaGo 在2016 年戰(zhàn)勝世界圍棋冠軍李世石.
卷積神經(jīng)網(wǎng)絡(luò)的整體架構(gòu)大體上遵循著一種固定的范式,即網(wǎng)絡(luò)前半部分堆疊卷積層,間或插入若干池化層以組成特征提取器,最后連上全連接層作為分類器,構(gòu)成一個端到端的網(wǎng)絡(luò)模型,如圖1 中LeNet-5[6] 所示.卷積神經(jīng)網(wǎng)絡(luò)一般通過增加卷積層數(shù)量以增加網(wǎng)絡(luò)深度,用這種方式獲得的深度模型在分類任務(wù)上有更好的表現(xiàn)[7].從表1 可以看出,卷積神經(jīng)網(wǎng)絡(luò)的性能不斷增長,其在ImageNet 數(shù)據(jù)集的識別錯誤率不斷降低,同時其時間復(fù)雜度和空間復(fù)雜度也相應(yīng)上升.具體地,卷積神經(jīng)網(wǎng)絡(luò)的網(wǎng)絡(luò)層數(shù)呈持續(xù)增加態(tài)勢,其訓(xùn)練參數(shù)數(shù)量和乘加操作數(shù)量也保持在一個較高的水平,例如VGGNet-16 具有高達(dá)138 M 參數(shù)量,其整體模型規(guī)模超過500 M,需要155 億次浮點(diǎn)數(shù)操作才能對一張圖片進(jìn)行分類.
深度卷積神經(jīng)網(wǎng)絡(luò)通常都包含有幾十甚至上百卷積層,訓(xùn)練參數(shù)量動輒上百萬,在GPU 加速支持下仍然需要花費(fèi)幾天或幾周時間才能完成訓(xùn)練(如ResNet 需用8 個GPU 訓(xùn)練2 ~3 周時間),制約了其在移動設(shè)備、嵌入式系統(tǒng)等資源受限場景下的應(yīng)用.如表1 所示,過去由于卷積層在網(wǎng)絡(luò)訓(xùn)練階段和預(yù)測階段的前向推導(dǎo)過程中涉及大量的浮點(diǎn)數(shù)計(jì)算操作,而全連接層的神經(jīng)元之間采用全連接方式,擁有絕大多數(shù)訓(xùn)練參數(shù),所以卷積神經(jīng)網(wǎng)絡(luò)的時間復(fù)雜度主要由卷積層決定,空間復(fù)雜度主要由全連接層決定.隨著卷積神經(jīng)網(wǎng)絡(luò)逐漸向更深層次發(fā)展,卷積層數(shù)量急劇增加,在前向推導(dǎo)過程中產(chǎn)生的中間變量會占用大量內(nèi)存空間,此時卷積層同時決定了網(wǎng)絡(luò)的時間復(fù)雜度和空間復(fù)雜度.因此,降低卷積層和全連接層的復(fù)雜度有助于優(yōu)化卷積神經(jīng)網(wǎng)絡(luò)的結(jié)構(gòu),對于網(wǎng)絡(luò)的壓縮與加速也有重要的促進(jìn)作用.
針對網(wǎng)絡(luò)結(jié)構(gòu)優(yōu)化的相關(guān)研究在90 年代已被提出[8?9],然而由于當(dāng)時神經(jīng)網(wǎng)絡(luò)大多屬于淺層網(wǎng)絡(luò),對于結(jié)構(gòu)優(yōu)化的需求尚不強(qiáng)烈,因此未能引起廣泛關(guān)注.如今卷積神經(jīng)網(wǎng)絡(luò)的規(guī)模日益龐大,而大量應(yīng)用場景都無法提供相應(yīng)的必需資源,因此探討在保證網(wǎng)絡(luò)精度的前提下壓縮并加速模型是網(wǎng)絡(luò)結(jié)構(gòu)優(yōu)化領(lǐng)域的前沿?zé)狳c(diǎn).隨著對卷積神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)優(yōu)化研究的逐漸深入,大量成果不斷涌現(xiàn),一些學(xué)者對這一領(lǐng)域的相關(guān)工作進(jìn)行了歸納與總結(jié),如文獻(xiàn)[10]重點(diǎn)討論了模型壓縮與加速各種方法的優(yōu)缺點(diǎn),文獻(xiàn)[11]從硬件和軟件兩方面整理了網(wǎng)絡(luò)加速的研究進(jìn)展,文獻(xiàn)[12]簡要介紹了深度網(wǎng)絡(luò)壓縮的典型方法.本文在這些工作的基礎(chǔ)上,結(jié)合最新研究進(jìn)展和成果,全面地梳理與總結(jié)了卷積神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)優(yōu)化方面的研究工作.其中第1 節(jié)到第4 節(jié)分別從網(wǎng)絡(luò)剪枝與稀疏化、張量分解、知識遷移和精細(xì)化結(jié)構(gòu)設(shè)計(jì)4 個方面歸納了相關(guān)研究思想和方法,第5 節(jié)綜合卷積神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)優(yōu)化領(lǐng)域的研究現(xiàn)狀,對其未來研究趨勢和應(yīng)用方向進(jìn)行了展望.
1 網(wǎng)絡(luò)剪枝與稀疏化
文獻(xiàn)[13]的研究表明,卷積神經(jīng)網(wǎng)絡(luò)從卷積層到全連接層存在大量的冗余參數(shù),大多數(shù)神經(jīng)元被激活后的輸出值趨近于0,即使將這些神經(jīng)元剔除也能夠表達(dá)出模型特征,這種現(xiàn)象被稱為過參數(shù)化.例如ResNet-50 擁有50 層卷積層,整個模型需要95 MB 存儲空間,在剔除75% 的參數(shù)后仍然正常工作,而且運(yùn)行時間降低多達(dá)50%[14].因此,在網(wǎng)絡(luò)訓(xùn)練過程中可以尋求一種評判機(jī)制,剔除掉不重要的連接、節(jié)點(diǎn)甚至卷積核,以達(dá)到精簡網(wǎng)絡(luò)結(jié)構(gòu)的目的.網(wǎng)絡(luò)結(jié)構(gòu)精簡的一個具體表現(xiàn)是網(wǎng)絡(luò)的稀疏化,這給模型訓(xùn)練帶來了三點(diǎn)好處:首先是由于網(wǎng)絡(luò)參數(shù)的減少,有效緩解了過擬合現(xiàn)象的發(fā)生[15];其次,稀疏網(wǎng)絡(luò)在以CSR (Compressed sparse row format,CSR)和CSC(Compressed sparse column format)等稀疏矩陣存儲格式存儲于計(jì)算機(jī)中可大幅降低內(nèi)存開銷;最后,訓(xùn)練參數(shù)的減少使得網(wǎng)絡(luò)訓(xùn)練階段和預(yù)測階段花費(fèi)時間更少.由于網(wǎng)絡(luò)剪枝具有易于實(shí)施且效果顯著的優(yōu)點(diǎn),目前已成為模型壓縮與加速領(lǐng)域最重要的結(jié)構(gòu)優(yōu)化技術(shù).
根據(jù)卷積神經(jīng)網(wǎng)絡(luò)訓(xùn)練階段的不同,網(wǎng)絡(luò)剪枝與稀疏化方法主要包含訓(xùn)練中稀疏約束與訓(xùn)練后剪枝兩個大類[16].對于前者,通過在優(yōu)化函數(shù)添加稀疏性約束,誘導(dǎo)網(wǎng)絡(luò)結(jié)構(gòu)趨于稀疏,這種端到端的處理方法不需要預(yù)先訓(xùn)練好模型,簡化了網(wǎng)絡(luò)的優(yōu)化過程.對于后者,通過剔除網(wǎng)絡(luò)中相對冗余、不重要的部分,同樣可以使得網(wǎng)絡(luò)稀疏化、精簡化.事實(shí)上,無論是在訓(xùn)練中引入稀疏約束還是訓(xùn)練后剪枝網(wǎng)絡(luò),最終目的都是使網(wǎng)絡(luò)的權(quán)重矩陣變得稀疏,這也是加速網(wǎng)絡(luò)訓(xùn)練、防止網(wǎng)絡(luò)過擬合的重要方式.
對于網(wǎng)絡(luò)損失函數(shù)中的稀疏約束,主要是通過引入l0或l1正則化項(xiàng)實(shí)現(xiàn)的.假設(shè)訓(xùn)練數(shù)據(jù)集D包含N 個數(shù)據(jù)對(x1,y1),(x2,y2),···,(xN,yN),訓(xùn)練參數(shù)為θ,則網(wǎng)絡(luò)訓(xùn)練的目標(biāo)優(yōu)化函數(shù)一般表示為:
其中,
,p=0,1.優(yōu)化函數(shù)的第一項(xiàng)是經(jīng)驗(yàn)風(fēng)險(xiǎn),第二項(xiàng)是正則化項(xiàng),帶有正則化約束的優(yōu)化函數(shù)在反向傳播時驅(qū)使不重要權(quán)重的數(shù)值變?yōu)榱?使得訓(xùn)練后的網(wǎng)絡(luò)具有一定的稀疏性和較好的泛化性能.Collins 等[17] 在參數(shù)空間中通過貪婪搜索決定需要稀疏化的隱含層,能夠大幅減少網(wǎng)絡(luò)中的權(quán)重連接,使模型的存儲需求降低了3 倍,并且克服了OBS 與OBD 處理大型網(wǎng)絡(luò)面臨的精度下降問題.Jin 等[18] 提出的迭代硬閾值(Iterative hard thresholding,IHT)方法分兩步對網(wǎng)絡(luò)進(jìn)行剪枝,在第一步中剔除隱含節(jié)點(diǎn)間權(quán)值較小的連接,然后微調(diào)(Fine-tune)其他重要的卷積核,在第二步中激活斷掉的連接,重新訓(xùn)練整個網(wǎng)絡(luò)以獲取更有用的特征.相比于傳統(tǒng)方式訓(xùn)練的網(wǎng)絡(luò),通過IHT 訓(xùn)練的網(wǎng)絡(luò)具有更加優(yōu)越的泛化能力和極低的內(nèi)存大小.Zeiler 等[19] 利用前向–后向切分法(Forwardbackward splitting method)處理帶有稀疏約束的損失函數(shù),避免了在反向傳播中需要求取二階導(dǎo)數(shù)等計(jì)算復(fù)雜度較高的運(yùn)算,加快了網(wǎng)絡(luò)訓(xùn)練速度.Wen 等[20] 認(rèn)為網(wǎng)絡(luò)結(jié)構(gòu)從卷積核到卷積通道都充斥著冗余無用的信息,他們提出的結(jié)構(gòu)化稀疏學(xué)習(xí)(Structured sparsity learning,SSL)直接學(xué)習(xí)到的硬件友好型稀疏網(wǎng)絡(luò)不僅具有更加緊湊的結(jié)構(gòu),而且運(yùn)行速度可提升3 倍至5 倍.Lebedv 等[21] 以分組形式剪枝卷積核輸入,以數(shù)據(jù)驅(qū)動的方式獲取最優(yōu)感受野(Receptive field),在AlexNet 中獲得8.5倍的速度提升而損失精度不到1%.Louizos 等[22]利用一系列優(yōu)化措施將不可微分的l0范數(shù)正則項(xiàng)加入到目標(biāo)函數(shù),學(xué)習(xí)到的稀疏網(wǎng)絡(luò)不僅具有良好的泛化性能,而且極大加速了模型訓(xùn)練和推導(dǎo)過程.
Dropout 作為一種強(qiáng)有力的網(wǎng)絡(luò)優(yōu)化方法,可被視為特殊的正則化方法,被廣泛用于防止網(wǎng)絡(luò)訓(xùn)練過擬合[23?24].Dropout 在每次訓(xùn)練時隨機(jī)使一半神經(jīng)元暫時失活,相當(dāng)于在一定時間內(nèi)訓(xùn)練了多個不同網(wǎng)絡(luò)并將其組合,避免了復(fù)雜的共適應(yīng)現(xiàn)象(Co-adaptation)發(fā)生,在圖像分類、語音識別、文件分類和生物計(jì)算等任務(wù)都有較好表現(xiàn).然而,由于Dropout 在每次訓(xùn)練時都會嘗試訓(xùn)練不同的網(wǎng)絡(luò),這將導(dǎo)致訓(xùn)練時間的大幅延長.因此,目前也有一些工作針對Dropout 的加速展開研究,如Li 等[25]提出的自適應(yīng)Dropout 根據(jù)特征和神經(jīng)元的分布使用不同的多項(xiàng)式采樣方式,其收斂速度相對于標(biāo)準(zhǔn)Dropout 提高50%.
訓(xùn)練后網(wǎng)絡(luò)剪枝是從已有模型著手,消除網(wǎng)絡(luò)中的冗余信息,這避免了重新訓(xùn)練網(wǎng)絡(luò)帶來的高昂資源花費(fèi).根據(jù)剪枝粒度的不同,目前主要有層間剪枝、特征圖剪枝、k×k 核剪枝與核內(nèi)剪枝4 種方式[26],如圖2 所示.層間剪枝一個直接的后果就是減少了網(wǎng)絡(luò)的深度,而特征圖剪枝則減少了網(wǎng)絡(luò)的寬度.這兩種粗粒度的剪枝方法在減少網(wǎng)絡(luò)參數(shù)方面效果明顯,但面臨網(wǎng)絡(luò)性能下降嚴(yán)重的問題.k×k核剪枝與核內(nèi)剪枝兩種細(xì)粒度方法在參數(shù)量與模型性能之間取得了一定的平衡,但提高了方法的復(fù)雜度.
事實(shí)上,網(wǎng)絡(luò)剪枝方法在深度學(xué)習(xí)流行起來就已被提出,其早在上世紀(jì)九十年代即被廣泛用于網(wǎng)絡(luò)的優(yōu)化問題.Hanson 等[27]在誤差函數(shù)中引入權(quán)重衰減項(xiàng)使網(wǎng)絡(luò)趨于稀疏,即減少隱含節(jié)點(diǎn)數(shù)目以降低網(wǎng)絡(luò)復(fù)雜度.LeCun 等[8] 提出的最優(yōu)腦損傷(Optimal brain damage,OBD)通過移除網(wǎng)絡(luò)中不重要的連接,在網(wǎng)絡(luò)復(fù)雜度和訓(xùn)練誤差之間達(dá)到一種最優(yōu)平衡狀態(tài),極大加快了網(wǎng)絡(luò)的訓(xùn)練過程.Hassibi 等[9] 提出的最優(yōu)腦手術(shù)(Optimal brain surgeon,OBS)與OBD 的最大不同在于損失函數(shù)中的Hessian 矩陣沒有約束,這使得OBS 在其他網(wǎng)絡(luò)中具有比OBD 更普遍的泛化能力.盡管OBD與OBS 最初取得了較好效果,但由于其損失函數(shù)中需要求取二階導(dǎo)數(shù),在處理大型復(fù)雜網(wǎng)絡(luò)結(jié)構(gòu)時計(jì)算量巨大,且面臨著網(wǎng)絡(luò)精度損失嚴(yán)重的問題,因此探索適合于深度卷積神經(jīng)網(wǎng)絡(luò)的網(wǎng)絡(luò)剪枝與稀疏化方法對于網(wǎng)絡(luò)結(jié)構(gòu)優(yōu)化具有重要的研究價(jià)值.
網(wǎng)絡(luò)剪枝方法使得精簡后的小型網(wǎng)絡(luò)繼承了原始網(wǎng)絡(luò)的有用知識,與此同時具有與其相當(dāng)?shù)男阅鼙憩F(xiàn),目前已取得一系列卓有成效的成果.Han等[28] 提出的深度壓縮(Deep compression)綜合應(yīng)用了剪枝、量化、編碼等方法,在不影響精度的前提下可壓縮網(wǎng)絡(luò)35 ~49 倍,使得深度卷積網(wǎng)絡(luò)移植到移動設(shè)備上成為可能.Srinivas 等[29] 針對全連接層的神經(jīng)元而非網(wǎng)絡(luò)連接進(jìn)行剪枝操作,提出的方法擺脫了對于訓(xùn)練數(shù)據(jù)的依賴,由于避免了多次重復(fù)訓(xùn)練,極大降低了計(jì)算資源需求和花費(fèi)時間.Guo 等[30] 認(rèn)為參數(shù)的重要性會隨著網(wǎng)絡(luò)訓(xùn)練開始而不斷變化,因此恢復(fù)被剪枝的重要連接對于改善網(wǎng)絡(luò)性能具有重要作用.他們提出的動態(tài)網(wǎng)絡(luò)手術(shù)(Dynamic network surgery)在剪枝過程中添加了修復(fù)操作,當(dāng)已被剪枝的網(wǎng)絡(luò)連接變得重要時可使其重新激活,這兩個操作在每次訓(xùn)練后交替進(jìn)行,極大改善了網(wǎng)絡(luò)學(xué)習(xí)效率.Liu 等[31] 針對Winograd最小濾波算法與網(wǎng)絡(luò)剪枝方法無法直接組合應(yīng)用的問題,提出首先將ReLU 激活函數(shù)移至Winograd域,然后對Winograd 變換之后的權(quán)重進(jìn)行剪枝,在CIFAR-10、CIFAR-100 和ImageNet 數(shù)據(jù)集上的乘法操作數(shù)分別降低了10.4 倍、6.8 倍和10.8 倍.
近年來針對更高層級的網(wǎng)絡(luò)結(jié)構(gòu)剪枝方法層出不窮,有力推動了模型壓縮與加速的發(fā)展,對于卷積神經(jīng)網(wǎng)絡(luò)的結(jié)構(gòu)優(yōu)化也有重要的促進(jìn)作用.He等[32] 基于LASSO 正則化剔除冗余卷積核與其對應(yīng)的特征圖,然后重構(gòu)剩余網(wǎng)絡(luò),對于多分支網(wǎng)絡(luò)也有很好的效果.Li 等[33] 發(fā)現(xiàn)基于重要度(Magnitudebased)的剪枝方法盡管在全連接層可以取得較好效果,但是對于卷積層就無能無力了.他們直接去除對于輸出精度影響較小的卷積核以及對應(yīng)的特征圖,以一種非稀疏化連接的方式降低了百分之三十的計(jì)算復(fù)雜度.Anwar 等[26] 按照粒度大小將剪枝方法劃分為層級剪枝、特征圖剪枝、卷積核剪枝、卷積核內(nèi)部剪枝4 個層級,結(jié)合特征圖剪枝與卷積核剪枝提出的一次性(One-shot)優(yōu)化方法可獲得60%~70% 的稀疏度.同樣是針對卷積核剪枝,Luo 等[34] 提出的ThiNet 在訓(xùn)練和預(yù)測階段同時壓縮并加速卷積神經(jīng)網(wǎng)絡(luò),從下一卷積層而非當(dāng)前卷積層的概率信息獲取卷積核的重要程度,并決定是否剪枝當(dāng)前卷積核,對于緊湊型網(wǎng)絡(luò)也有不錯的壓縮效果.表2 比較了不同網(wǎng)絡(luò)剪枝方法對于卷積神經(jīng)網(wǎng)絡(luò)的壓縮效果,可以發(fā)現(xiàn)這些方法能夠大幅減少訓(xùn)練參數(shù)而不會顯著影響網(wǎng)絡(luò)精度,表明網(wǎng)絡(luò)剪枝與稀疏化是一種強(qiáng)有力的網(wǎng)絡(luò)結(jié)構(gòu)優(yōu)化方法.
2 張量分解
由于卷積神經(jīng)網(wǎng)絡(luò)規(guī)模逐漸向更深、更大層次發(fā)展,卷積操作過程中所需計(jì)算資源以及每次卷積后所需存儲資源已成為制約模型小型化、快速化的瓶頸.比如說,ResNet-152 網(wǎng)絡(luò)來自于卷積層的參數(shù)數(shù)量為全部參數(shù)的92%,而來自于卷積層的計(jì)算量占到總計(jì)算量的97%.已有研究結(jié)果表明[35],卷積神經(jīng)網(wǎng)絡(luò)僅需很少一部分參數(shù)即可準(zhǔn)確地預(yù)測結(jié)果,這說明卷積核中存在大量的冗余信息.張量分解對于去除冗余信息、加速卷積計(jì)算是一種極為有效的方法,可以有效壓縮網(wǎng)絡(luò)規(guī)模并提升網(wǎng)絡(luò)運(yùn)行速度,有益于深度神經(jīng)網(wǎng)絡(luò)在移動嵌入式環(huán)境下的高效運(yùn)行.
一般來說,向量稱為一維張量,矩陣稱為二維張量,而卷積神經(jīng)網(wǎng)絡(luò)中的卷積核可以被視為四維張量,表示為K∈Rd×d×I×O,其中,I,d,O 分別表示輸入通道,卷積核尺寸和輸出通道.張量分解的思想即是將原始張量分解為若干低秩張量,有助于減少卷積操作數(shù)量,加速網(wǎng)絡(luò)運(yùn)行過程.前常見的張量分解方法有CP 分解、Tucker 分解等,Tucker 分解可將卷積核分解為一個核張量與若干因子矩陣,是一種高階的主成分分析方法,其表達(dá)形式為:
其中,K∈Rd×d×I×O 為分解后的核張量,U1∈Rd×r1、U2∈Rd×r2、U3∈RI×r3、U4∈RO×r4 為因子矩陣.CP 分解的表達(dá)形式為:
其中,K1∈Rd×r、K2∈Rd×r、K3∈RI×r、K4∈RO×r.CP 分解屬于Tucker 分解的一種特殊形式,其分解過程更為簡單,然而分解矩陣的秩r 的選取是一個NP 難問題,并且可能涉及到分解穩(wěn)定性問題.值得注意的是,由于全連接層也可以視為二維張量,因此可利用矩陣奇異值分解(Singular value decomposition,SVD)去除全連接層的冗余信息,分解表達(dá)式為:
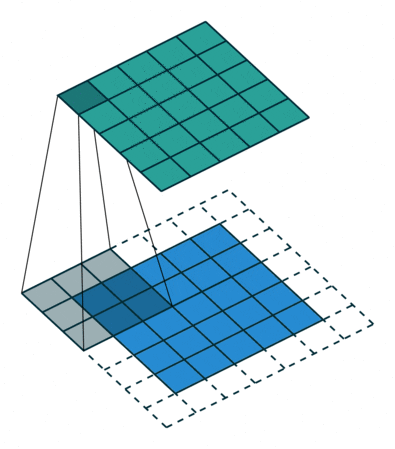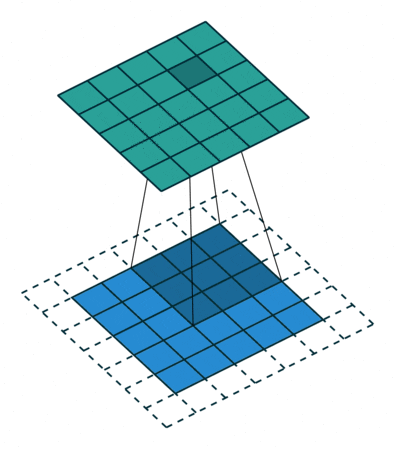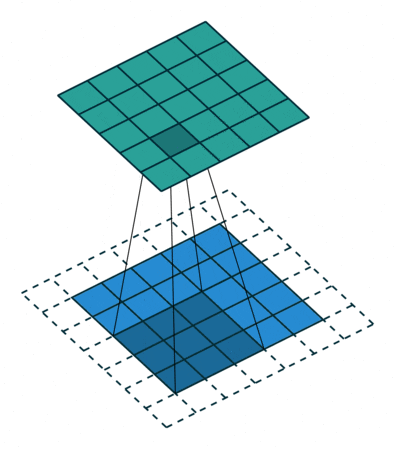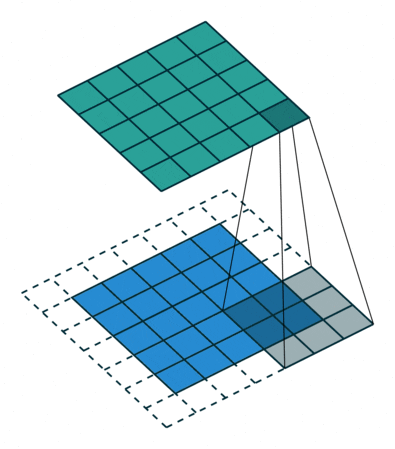
其中,W∈Rm×n 為待分解張量,U∈Rm×m 和V∈Rn×n 是正交矩陣,S∈Rm×n 是對角矩陣.圖3 展示了將一個W∈Rd×d×I×O 張量分解為一個P∈RO×K 張量和一個
∈RK×d×d×I 張量的過程.圖3(a)中W 為原始張量,復(fù)雜度為O(d2IO);圖3(b)中P 和
為分解后張量,復(fù)雜度為O(OK)+O(d2KI).對于大多數(shù)網(wǎng)絡(luò)有O(OK)
O(d2KI),所以分解后復(fù)雜度為原來的O/K,并且K 值越小,壓縮效果越明顯.
利用張量分解以加速卷積過程已有很長的一段時間,最典型的例子就是將高維離散余弦變換(Discrete cosine transform,DCT)分解為一系列一維DCT 變換相乘,以及將小波系統(tǒng)分解為一系列一維小波的乘積[10].Rigamonti 等[36] 基于字典學(xué)習(xí)的思想,提出的分離卷積核學(xué)習(xí)方法(Learning separable filters)能夠?qū)⒃季矸e核用低秩卷積核表示,減少所需卷積核數(shù)量以降低計(jì)算負(fù)擔(dān).同時,作者認(rèn)為在構(gòu)建網(wǎng)絡(luò)時不用再精心設(shè)計(jì)卷積核結(jié)構(gòu),只需通過分離卷積核學(xué)習(xí)就可以得到最優(yōu)的卷積核組合.Jaderberg 等[37] 提出了一種逐層分解方法,每當(dāng)一個卷積核被分解為若干一階張量,則固定此卷積核并基于一種重構(gòu)誤差標(biāo)準(zhǔn)以微調(diào)其余卷積核,研究結(jié)果表明在場景文本識別中可加速網(wǎng)絡(luò)4.5 倍而準(zhǔn)確度僅降低1%.Denton 等[38] 認(rèn)為卷積神經(jīng)網(wǎng)絡(luò)的絕大部分冗余參數(shù)都位于全連接層,因此主要針對全連接層展開奇異值分解,分解后的網(wǎng)絡(luò)網(wǎng)絡(luò)參數(shù)最多減少13 倍,同時其運(yùn)行速度可提升2 ~3 倍.Lebedev 等[39] 提出了基于CP 分解的卷積核張量分解方法,通過非線性最小二乘法將卷積核分解為4個一階卷積核張量.對于36 類的ILSVRC 分類實(shí)驗(yàn),該方法在CPU 上可獲得8.5 倍加速,實(shí)驗(yàn)結(jié)果同時表明張量分解具有正則化效果.Tai 等[40] 提出了一種帶有低秩約束的張量分解新算法,將非凸優(yōu)化的張量分解轉(zhuǎn)化為凸優(yōu)化問題,與同類方法相比提速明顯.
以上基于張量分解的方法雖然能夠取得一定效果,然而它們僅僅壓縮與加速一層或幾層網(wǎng)絡(luò),欠缺對于網(wǎng)絡(luò)整體的考量.Zhang 等[41] 提出了一種非對稱張量分解方法以加速整體網(wǎng)絡(luò)運(yùn)行,例如一個D×D 卷積核可被分解為1×D、D×1 和1×1等張量.此外,文獻(xiàn)[41]還提出了基于PCA 累積能量的低秩選擇方法和具有非線性的重構(gòu)誤差優(yōu)化方法,在ImagNet 上訓(xùn)練的大型網(wǎng)絡(luò)可被整體加速4倍.與文獻(xiàn)[41]不同,Kim 等[42] 提出了基于變分貝葉斯的低秩選擇方法和基于Tucker 張量分解的整體壓縮方法.由于模型尺寸、運(yùn)行時間和能量消耗都大幅降低,使用該方法壓縮的網(wǎng)絡(luò)可以移植到移動設(shè)備上運(yùn)行.Wang 等[43] 認(rèn)為網(wǎng)絡(luò)壓縮不能僅僅考慮卷積核,同時要考慮卷積核在網(wǎng)絡(luò)運(yùn)行過程中映射的巨量特征圖.文獻(xiàn)[43]利用循環(huán)矩陣剔除特征圖中的冗余信息,獲取特征圖中最本質(zhì)的特征,進(jìn)一步重構(gòu)卷積核以匹配壓縮后的特征圖.實(shí)驗(yàn)結(jié)果表明文獻(xiàn)[43]中的方法盡管只有很少參數(shù),但具有與原始網(wǎng)絡(luò)相當(dāng)?shù)男阅?Astrid 等[44] 提出了一種基于優(yōu)化CP 分解全部卷積層的網(wǎng)絡(luò)壓縮方法,在每次分解單層網(wǎng)絡(luò)后都微調(diào)整個網(wǎng)絡(luò),克服了由于CP分解不穩(wěn)定引起的網(wǎng)絡(luò)精度下降問題.
張量分解對于深度網(wǎng)絡(luò)的壓縮與加速具有直接作用,可以作為網(wǎng)絡(luò)結(jié)構(gòu)優(yōu)化設(shè)計(jì)方法的重要補(bǔ)充.然而目前大多數(shù)的張量分解方法都是逐層分解網(wǎng)絡(luò),缺乏整體性的考慮,有可能導(dǎo)致不同隱含層之間的信息損失.此外,由于涉及到矩陣分解操作,會造成網(wǎng)絡(luò)訓(xùn)練過程的計(jì)算資源花費(fèi)高昂.最后,由于每次張量分解過后都需要重新訓(xùn)練網(wǎng)絡(luò)至收斂,這進(jìn)一步加劇了網(wǎng)絡(luò)訓(xùn)練的復(fù)雜度.
3 知識遷移
知識遷移是屬于遷移學(xué)習(xí)的一種網(wǎng)絡(luò)結(jié)構(gòu)優(yōu)化方法,即將教師網(wǎng)絡(luò)(Teacher networks)的相關(guān)領(lǐng)域知識遷移到學(xué)生網(wǎng)絡(luò)(Student networks)以指導(dǎo)學(xué)生網(wǎng)絡(luò)的訓(xùn)練,完成網(wǎng)絡(luò)的壓縮與加速.一般地,教師網(wǎng)絡(luò)往往是單個復(fù)雜網(wǎng)絡(luò)或者是若干網(wǎng)絡(luò)的集合,擁有良好的性能和泛化能力,而學(xué)生網(wǎng)絡(luò)則具有更小的網(wǎng)絡(luò)規(guī)模,還未獲得充分的訓(xùn)練.考慮利用教師網(wǎng)絡(luò)本身的知識或通過教師網(wǎng)絡(luò)學(xué)習(xí)到的知識去指導(dǎo)學(xué)生網(wǎng)絡(luò)訓(xùn)練,使得學(xué)生網(wǎng)絡(luò)具有與教師網(wǎng)絡(luò)相當(dāng)?shù)男阅?但是參數(shù)數(shù)量大幅降低,同樣可以實(shí)現(xiàn)網(wǎng)絡(luò)壓縮與加速的效果.
知識遷移主要由教師網(wǎng)絡(luò)獲取和學(xué)生網(wǎng)絡(luò)訓(xùn)練兩部分內(nèi)容構(gòu)成,在教師網(wǎng)絡(luò)獲取中,由于教師網(wǎng)絡(luò)規(guī)模較大,需要用大量標(biāo)簽數(shù)據(jù)對其進(jìn)行訓(xùn)練以獲得較高的預(yù)測準(zhǔn)確率.在學(xué)生網(wǎng)絡(luò)訓(xùn)練過程中,首先將未標(biāo)簽數(shù)據(jù)輸入教師網(wǎng)絡(luò)進(jìn)行預(yù)測,然后將預(yù)測到的結(jié)果與輸入數(shù)據(jù)人工合成為標(biāo)簽數(shù)據(jù),最后將這些人工合成的標(biāo)簽數(shù)據(jù)作為領(lǐng)域知識以指導(dǎo)學(xué)生網(wǎng)絡(luò)的訓(xùn)練.由于學(xué)生網(wǎng)絡(luò)規(guī)模較小,因此只需少量的標(biāo)簽數(shù)據(jù)即可完成訓(xùn)練.知識遷移的整體流程如圖4 所示.
Bucila 等[45] 首先提出了基于知識遷移的模型壓縮方法,通過人工合成數(shù)據(jù)訓(xùn)練學(xué)生網(wǎng)絡(luò)以完成壓縮與加速.其具體步驟為首先將大型無標(biāo)簽數(shù)據(jù)集輸入教師網(wǎng)絡(luò)以獲得相應(yīng)的標(biāo)簽,獲得人工合成的標(biāo)簽數(shù)據(jù),然后在人工標(biāo)簽數(shù)據(jù)集上訓(xùn)練學(xué)生網(wǎng)絡(luò),實(shí)驗(yàn)結(jié)果表明學(xué)生網(wǎng)絡(luò)尺寸減少了1 000 倍,同時運(yùn)行速度提升了1 000 倍.最初由大型復(fù)雜網(wǎng)絡(luò)獲得的知識可根據(jù)softmax 函數(shù)計(jì)算的類別概率標(biāo)簽來表示,相比于one-hot 標(biāo)簽,類別概率標(biāo)簽包含了訓(xùn)練樣本中的相關(guān)近似程度,可以更加有效地訓(xùn)練學(xué)生網(wǎng)絡(luò).然而類別概率標(biāo)簽的大多數(shù)概率值在通過softmax 函數(shù)后都趨近于0,損失了大量有效信息.Ba 等[46] 提出利用logits (通過softmax 函數(shù)前的輸入值,均值為0)來表示學(xué)習(xí)到的知識,揭露了標(biāo)簽之間的相對關(guān)系和樣本之間的近似度.與文獻(xiàn)[45]類似,Ba 等[46] 將教師網(wǎng)絡(luò)獲得數(shù)據(jù)集的logits標(biāo)簽作為知識指導(dǎo)學(xué)生網(wǎng)絡(luò)的訓(xùn)練,在TIMIT 和CIFAR-10 數(shù)據(jù)庫上都能夠達(dá)到與深度網(wǎng)絡(luò)相當(dāng)?shù)淖R別精度.Hinton 等[47] 認(rèn)為類別概率標(biāo)簽和logits 標(biāo)簽都是softmax 層的極端輸出,其中T 分別為1 和正無窮.他們提出的知識精餾(Knowledge distilling,KD)采用合適的T 值,可以產(chǎn)生一個類別概率分布較緩和的輸出(稱為軟概率標(biāo)簽(Soft probability labels)).軟概率標(biāo)簽揭示了數(shù)據(jù)結(jié)構(gòu)間的相似性,包含大量的有用信息,可利用軟概率標(biāo)簽訓(xùn)練學(xué)生網(wǎng)絡(luò)以模擬復(fù)雜的網(wǎng)絡(luò)集合.Romero等[48] 提出的FitNet 不僅利用了教師網(wǎng)絡(luò)的輸出,同時也將教師網(wǎng)絡(luò)的隱含層輸出作為知識遷移到學(xué)生網(wǎng)絡(luò)中.通過這種方式訓(xùn)練的學(xué)生網(wǎng)絡(luò)相比于教師網(wǎng)絡(luò)更深更窄,因此具有更好的非線性變換能力.
與之前基于類別概率標(biāo)簽的知識遷移不同,Luo等[49] 利用教師網(wǎng)絡(luò)的高層神經(jīng)元輸出來表示需要遷移的領(lǐng)域知識.這種方式不會損失任何信息,但是學(xué)生網(wǎng)絡(luò)可以獲得更高的壓縮率.Chen 等[50] 基于函數(shù)保留變換(Function-preserving transformation)提出的Net2Net 是加速知識遷移流程的有效工具,可以快速地將教師網(wǎng)絡(luò)的有用信息遷移到更深(或更寬)的學(xué)生網(wǎng)絡(luò).Zagoruyko 等[51] 借鑒知識精餾的思想,提出了一種基于注意力的知識遷移方法.他們使用教師網(wǎng)絡(luò)中能夠提供視覺相關(guān)位置信息的注意力特征圖來監(jiān)督學(xué)生網(wǎng)絡(luò)的學(xué)習(xí),并且從低、中、高三個層次進(jìn)行注意力遷移,極大改善了殘差網(wǎng)絡(luò)等深度卷積神經(jīng)網(wǎng)絡(luò)的性能.Lucas 等[52]提出了一種結(jié)合Fisher 剪枝與知識遷移的優(yōu)化方法,首先利用預(yù)訓(xùn)練的高性能網(wǎng)絡(luò)生成大量顯著性圖作為領(lǐng)域知識,然后利用顯著性圖訓(xùn)練網(wǎng)絡(luò)并利用Fisher 剪枝方法剔除冗余的特征圖,在圖像顯著度預(yù)測中可加速網(wǎng)絡(luò)運(yùn)行多達(dá)10 倍.Yim 等[53] 將教師網(wǎng)絡(luò)隱含層之間的內(nèi)積矩陣作為領(lǐng)域知識,不僅能更快更好地指導(dǎo)學(xué)生網(wǎng)絡(luò)的訓(xùn)練,而且在與教師網(wǎng)絡(luò)不同的任務(wù)中也能獲得較好效果.Chen 等[54]結(jié)合文獻(xiàn)[47?48]的相關(guān)方法,首次提出了基于知識遷移的端到端的多目標(biāo)檢測框架,解決了目標(biāo)檢測任務(wù)中存在的欠擬合問題,在精度與速度方面都有較大改善.
知識遷移方法能夠直接加速網(wǎng)絡(luò)運(yùn)行而不需要較高硬件要求,大幅降低了學(xué)生網(wǎng)絡(luò)學(xué)習(xí)到不重要信息的比例,是一種有效的網(wǎng)絡(luò)結(jié)構(gòu)優(yōu)化方法.然而知識遷移需要研究者確定學(xué)生網(wǎng)絡(luò)的具體結(jié)構(gòu),對研究者的水平提出了較高的要求.此外,目前的知識遷移方法僅僅將網(wǎng)絡(luò)輸出概率值作為一種領(lǐng)域知識進(jìn)行遷移,沒有考慮到教師網(wǎng)絡(luò)結(jié)構(gòu)對學(xué)生網(wǎng)絡(luò)結(jié)構(gòu)的影響.提取教師網(wǎng)絡(luò)的內(nèi)部結(jié)構(gòu)知識(如神經(jīng)元)并指導(dǎo)學(xué)生網(wǎng)絡(luò)的訓(xùn)練,有可能使學(xué)生網(wǎng)絡(luò)獲得更高的性能.
4 精細(xì)模塊設(shè)計(jì)
網(wǎng)絡(luò)剪枝與稀疏化、張量分解、知識遷移等方法都是在已有高性能模型基礎(chǔ)上,保證模型性能的前提下降低時間復(fù)雜度和空間復(fù)雜度.目前還有一些工作專注于設(shè)計(jì)高效的精細(xì)模塊,同樣可以實(shí)現(xiàn)優(yōu)化網(wǎng)絡(luò)結(jié)構(gòu)的目的.基于這些精細(xì)模塊構(gòu)造的網(wǎng)絡(luò)具有運(yùn)行速度快、占用內(nèi)存少、能耗低下的優(yōu)點(diǎn),此外,由于采用模塊化的網(wǎng)絡(luò)結(jié)構(gòu)優(yōu)化方法,網(wǎng)絡(luò)的設(shè)計(jì)與構(gòu)造流程大幅縮短.目前具有代表性的精細(xì)模塊有Inception 模塊、網(wǎng)中網(wǎng)和殘差模塊,本節(jié)對其進(jìn)行了詳盡討論與分析.
4.1 Inception 模塊
對于如何設(shè)計(jì)性能更好的卷積神經(jīng)網(wǎng)絡(luò),目前的主流觀點(diǎn)是通過增加網(wǎng)絡(luò)深度與寬度來擴(kuò)大模型的規(guī)模.但是這會帶來兩個無法避免的問題:1)隨著網(wǎng)絡(luò)尺寸的增加,網(wǎng)絡(luò)的訓(xùn)練參數(shù)也會大幅增加,這在訓(xùn)練數(shù)據(jù)不足時不可避免地會帶來過擬合問題;2)網(wǎng)絡(luò)尺寸和訓(xùn)練參數(shù)的增加使得網(wǎng)絡(luò)模型占用計(jì)算資源和內(nèi)存資源過高的問題加劇,將會導(dǎo)致訓(xùn)練速度降低,難以應(yīng)用于實(shí)際工程問題.
為解決以上問題,Szegedy 等[4] 從網(wǎng)中網(wǎng)(Network in network,NiN)[55] 中得到啟發(fā),提出了如圖5 所示的Inception-v1 網(wǎng)絡(luò)結(jié)構(gòu).與傳統(tǒng)卷積神經(jīng)網(wǎng)絡(luò)采用11×11、9×9 等大尺寸卷積核不同,Inception-v1 大量并行使用5×5、3×3 卷積核,有效提升了網(wǎng)絡(luò)的寬度,并引入1×1 卷積核為獲取到的特征降維.Inception-v1 結(jié)構(gòu)在增加卷積神經(jīng)網(wǎng)絡(luò)深度和寬度的同時,并沒有增加額外的訓(xùn)練參數(shù).此外,將不同尺寸的卷積核并行連接能夠增加特征提取的多樣性,而引入的1×1 卷積核則加速了網(wǎng)絡(luò)運(yùn)行過程.
Ioffe 等[56] 認(rèn)為,卷積神經(jīng)網(wǎng)絡(luò)在訓(xùn)練時每層網(wǎng)絡(luò)的輸入分布都會發(fā)生改變,這將會導(dǎo)致模型訓(xùn)練速度降低.因此,他們在Inception-v1 的基礎(chǔ)上提出了Inception-v2 結(jié)構(gòu),引入了批標(biāo)準(zhǔn)化(Batch normalization,BN).批標(biāo)準(zhǔn)化一般用于激活函數(shù)之前,其最重要的作用是解決反向傳播中的梯度問題(包括梯度消失和梯度爆炸).此外,批標(biāo)準(zhǔn)化不僅允許使用更大的學(xué)習(xí)速率,而且還簡化了網(wǎng)絡(luò)參數(shù)的初始化過程,將人們從繁重的調(diào)參工作中解放出來.最后,由于批標(biāo)準(zhǔn)化具有正則化效果,在某些情況下還可以減少對Dropout 的需求.
為進(jìn)一步增加網(wǎng)絡(luò)深度,Szegedy 等[57] 提出的Inception-v3 網(wǎng)絡(luò)借鑒了VGGNet 的卷積核分解思想,除了將7×7、5×5 等較大的卷積核分解為若干連續(xù)的3×3 卷積核,還將n×n 卷積核非對稱分解為1×n 和n×1 兩個連續(xù)卷積核(當(dāng)n=7 時,效果最好).Inception-v3 還引入輔助分類器(Auxiliary classifiers)以加速卷積神經(jīng)網(wǎng)絡(luò)訓(xùn)練的收斂過程,支持了Inception-v2 中的批標(biāo)準(zhǔn)化具有正則化作用的觀點(diǎn).通過卷積核分解,Inception-v3 不僅能夠提升網(wǎng)絡(luò)的深度和寬度,而且有效降低了時間復(fù)雜度和空間復(fù)雜度.此外,Inception-v3 加速訓(xùn)練過程并減輕了過擬合,同時還強(qiáng)化了網(wǎng)絡(luò)對不同維度特征的適應(yīng)能力和非線性表達(dá)能力.圖6(a)展示了將一個5×5 的卷積核分解為兩個連續(xù)3×3 的卷積核后的計(jì)算過程,由于一個5×5 卷積核有5×5=25 個參數(shù),而兩個3×3 卷積核只有3×3+3×3=18 個參數(shù),因此參數(shù)量降低了28% 而卷積效果相同;圖6(b)展示了將一個3×3 卷積核分解為一個1×3卷積核和一個3×1 卷積核后的計(jì)算過程,一個3×3卷積核有3×3=9 個參數(shù),而兩個分解后卷積核有1×3+3×1=6 個參數(shù),參數(shù)量降低了33% 而卷積效果相同.
Szegedy 等[58] 將Inception 結(jié)構(gòu)與殘差結(jié)構(gòu)相結(jié)合,發(fā)現(xiàn)了殘差結(jié)構(gòu)可以極大地加快網(wǎng)絡(luò)的訓(xùn)練速度,提出的Inception-Resnet-v1 和Inception-Resnet-v2 模型在ImageNet 數(shù)據(jù)集上的Top-5錯誤率分別降低到4.3% 和3.7%.他們還提出了Stem、Inception-A、Inception-B、Inception-C、Reduction-A、Reduction-B 等一系列網(wǎng)絡(luò)局部結(jié)構(gòu),并以此構(gòu)造出Inception-v4 網(wǎng)絡(luò)模型,極大地增加了網(wǎng)絡(luò)深度,提高了網(wǎng)絡(luò)性能,同時保證了網(wǎng)絡(luò)訓(xùn)練參數(shù)數(shù)量處于可接受的范圍之內(nèi).
Chollet 等[59] 認(rèn)為傳統(tǒng)的卷積過程同時從二維空間與一維通道進(jìn)行三維的特征提取,而Inceptionv3 部分地將空間操作與通道操作分離開,使得訓(xùn)練過程更加容易且有效率.從Inception-v3 中得到啟發(fā),Chollet 認(rèn)為卷積神經(jīng)網(wǎng)絡(luò)中特征圖的空間維度與通道維度的關(guān)聯(lián)性可以被完全解耦,基于此他們提出了一種區(qū)別于一般卷積(Regular convolution)的Xception(Extremely inception)模塊,并以此構(gòu)造出Xception 網(wǎng)絡(luò)結(jié)構(gòu).Xception 模塊如圖7 所示,首先用卷積核對輸入特征圖進(jìn)行卷積操作,對于輸出特征圖的每個通道都用一個卷積核進(jìn)行卷積操作,最后將所有輸出拼接起來得到新的特征圖.Xception 網(wǎng)絡(luò)的訓(xùn)練參數(shù)比Inception-v3 網(wǎng)絡(luò)更少,但具有與Inception-v3 網(wǎng)絡(luò)相當(dāng)?shù)淖R別精度和訓(xùn)練速度,而且在更大的數(shù)據(jù)集上性能更加優(yōu)越.
Inception 結(jié)構(gòu)從Inception-v1 發(fā)展到Xception,始終致力于增加卷積神經(jīng)網(wǎng)絡(luò)的尺寸(包括深度和寬度)以提升模型的非線性表達(dá)能力.為了避免訓(xùn)練參數(shù)增加而帶來的模型訓(xùn)練速度降低、易過擬合等問題,Inception 結(jié)構(gòu)提出了批標(biāo)準(zhǔn)化、卷積核分解等方法來優(yōu)化更深層次的網(wǎng)絡(luò)結(jié)構(gòu),使得加深后的網(wǎng)絡(luò)參數(shù)量相比于原始網(wǎng)絡(luò)不變甚至更少,訓(xùn)練出來的網(wǎng)絡(luò)模型在各種測試數(shù)據(jù)集上都取得了領(lǐng)先成績.Inception 的成功也進(jìn)一步證明了增加網(wǎng)絡(luò)尺寸是提升網(wǎng)絡(luò)性能的可靠方式,這也是卷積神經(jīng)網(wǎng)絡(luò)未來的一種發(fā)展方向.
4.2 網(wǎng)中網(wǎng)(Network in network)
傳統(tǒng)卷積神經(jīng)網(wǎng)絡(luò)的卷積核作為一種廣義線性模型(Generalized linear model,GLM),在訓(xùn)練樣本的潛在特征是線性可分時能夠獲取表達(dá)能力較強(qiáng)的高維抽象特征.但在很多任務(wù)場景下,獲取到的樣本特征是具有較強(qiáng)非線性的,使用傳統(tǒng)的卷積核不能有效地提取更接近本質(zhì)的抽象特征.Lin等[55] 提出了一種區(qū)別于廣義線性模型的非線性結(jié)構(gòu)—Mlpconv,即在卷積核后面添加一個多層感知機(jī)(Multilayer perceptron,MLP).由于多層感知機(jī)能夠擬合任何函數(shù),因此Mlpconv 結(jié)構(gòu)增強(qiáng)了網(wǎng)絡(luò)對局部感知野的特征辨識能力和非線性表達(dá)能力.通過堆疊Mlpconv 層構(gòu)建出的網(wǎng)絡(luò)被形象地稱為網(wǎng)中網(wǎng)(Network in network,NiN),如圖8 所示.
網(wǎng)中網(wǎng)不僅用Mlpconv 結(jié)構(gòu)替代廣義線性模型以處理更為復(fù)雜的非線性問題,并且用全局均值池化代替全連接層以減少訓(xùn)練參數(shù),避免了訓(xùn)練過程中出現(xiàn)過擬合問題.值得注意的是,Mlpconv 層中的全連接層可以被視為一個1×1 卷積核,后來被廣泛應(yīng)用于包括Inception 在內(nèi)的各種網(wǎng)絡(luò)中的1×1 卷積核都受到了網(wǎng)中網(wǎng)的啟發(fā).在此基礎(chǔ)上,涌現(xiàn)出了大量針對網(wǎng)中網(wǎng)結(jié)構(gòu)的改進(jìn)措施.Chang等[60] 認(rèn)為Mlpconv 層中的ReLU 激活函數(shù)會帶來梯度消失的問題,因此提出用Maxout 替代ReLU以解決這一問題,并將這一網(wǎng)絡(luò)結(jié)構(gòu)稱為Maxout network in network (MIN).Pang 等[61] 認(rèn)為由于MLP 本身也包含全連接網(wǎng)絡(luò),這不可避免地會使得訓(xùn)練參數(shù)大幅增加,因此提出用稀疏連接的MLP代替原來的MLP,并且在通道維度上使用分離卷積(Unshared convolution)而在空間維度上使用共享卷積(Shared convolution),這種網(wǎng)絡(luò)結(jié)構(gòu)被稱為卷積中的卷積(Convolution in convolution,CiC).Han 等[62]提出的MPNIN (Mlpconv-wise supervised pre-training network in network)通過監(jiān)督式預(yù)處理方法初始化網(wǎng)絡(luò)模型的各層訓(xùn)練參數(shù),并結(jié)合批標(biāo)準(zhǔn)化與網(wǎng)中網(wǎng)結(jié)構(gòu)能夠訓(xùn)練更深層次的卷積神經(jīng)網(wǎng)絡(luò).
網(wǎng)中網(wǎng)結(jié)構(gòu)一經(jīng)提出就受到了廣泛的關(guān)注和研究,包括GoogLeNet、ResNet 在內(nèi)的眾多卷積神經(jīng)網(wǎng)絡(luò)都借鑒了這一結(jié)構(gòu).與傳統(tǒng)GLM 卷積核相比,網(wǎng)中網(wǎng)的Mlpconv 層可以實(shí)現(xiàn)跨通道的特征交互與整合,由此發(fā)展而來的1×1 卷積核還能實(shí)現(xiàn)特征降維與升維的功能,使得網(wǎng)絡(luò)模型既能夠提取更加抽象的特征以解決復(fù)雜的非線性問題,還可以訓(xùn)練更深層的網(wǎng)絡(luò)而保持訓(xùn)練參數(shù)處于可接受范圍.值得注意的是,由于Mlpconv 結(jié)構(gòu)引入了額外的多層感知機(jī),有可能會導(dǎo)致網(wǎng)絡(luò)運(yùn)行速度降低,對此進(jìn)行改善將會是未來研究的一個方向.
4.3 殘差模塊
隨著卷積神經(jīng)網(wǎng)絡(luò)逐漸向更深層次發(fā)展,網(wǎng)絡(luò)將面臨退化問題而不是過擬合問題,具體表現(xiàn)在網(wǎng)絡(luò)性能不再隨著深度的增加而提升,甚至在網(wǎng)絡(luò)深度進(jìn)一步增加的情況下性能反而快速下降,此時引入一種稱為旁路連接的(Bypassing connection)結(jié)構(gòu)優(yōu)化技術(shù)可有效解決這一問題.Srivastava 等[63]從長短時記憶模型[64] (Long short-term memory,LSTM)中得到啟發(fā),引入可學(xué)習(xí)門限機(jī)制(Learned gating mechanism)以調(diào)節(jié)網(wǎng)絡(luò)中的信息傳播路徑,允許數(shù)據(jù)跨越多層網(wǎng)絡(luò)進(jìn)行傳播,這一模型被形象地稱為高速網(wǎng)絡(luò)(Highway network).旁路連接使得反向傳播中的梯度能夠跨越一層或多層傳播,而不至于在逐層運(yùn)算中擴(kuò)散甚至消失,在使用隨機(jī)梯度下降法(Stochastic gradient descent,SGD)訓(xùn)練模型時避免了在平層網(wǎng)絡(luò)(Plain network)中易出現(xiàn)的梯度消失現(xiàn)象.旁路連接的引入,突破了深度在達(dá)到40 層時網(wǎng)絡(luò)將面臨退化問題的限制,進(jìn)一步促進(jìn)了網(wǎng)絡(luò)深度的增加[65].
He 等[5] 提出的殘差網(wǎng)絡(luò)(Residual network,ResNet)與Highway network 類似,也是允許輸入信息可以跨越多個隱含層傳播.區(qū)別在于殘差網(wǎng)絡(luò)的門限機(jī)制不再是可學(xué)習(xí)的,也即始終保持信息暢通狀態(tài),這極大地降低了網(wǎng)絡(luò)復(fù)雜度,加速了網(wǎng)絡(luò)訓(xùn)練過程,同時突破了由網(wǎng)絡(luò)退化引起的深度限制.殘差模塊如圖9 所示,殘差模塊的輸入定義為X,輸出定義為H(X)= F(X)+X,殘差定義為F(X),在訓(xùn)練過程中網(wǎng)絡(luò)學(xué)習(xí)殘差F(X),這比直接學(xué)習(xí)輸出H(X)更加容易.
殘差網(wǎng)絡(luò)的提出標(biāo)志著卷積神經(jīng)網(wǎng)絡(luò)發(fā)展到了一個新階段,之后又有大量研究針對殘差結(jié)構(gòu)進(jìn)行改進(jìn).Huang 等[66] 利用隨機(jī)深度法(Stochastic depth)在訓(xùn)練過程中隨機(jī)地剔除,某些隱含層并用殘差結(jié)構(gòu)連接剩余部分,訓(xùn)練出一個1 202 層的極深殘差網(wǎng)絡(luò),同時表明原始的殘差網(wǎng)絡(luò)含有大量的冗余結(jié)構(gòu).He 等[67] 發(fā)現(xiàn)前置激活函數(shù)(Preactivation)不僅使得模型優(yōu)化更加容易,而且,在一定程度上緩解了過擬合.作者以此訓(xùn)練了一個1 001層的殘差網(wǎng)絡(luò),在CIFAR-10 數(shù)據(jù)集上的錯誤率降至4.62%.Larsson 等[65] 提出的分形網(wǎng)絡(luò)(Fractal-Net)在寬度和深度上進(jìn)一步擴(kuò)展殘差結(jié)構(gòu),并用一種稱為Drop-path 的方法優(yōu)化網(wǎng)絡(luò)訓(xùn)練,在圖片分類測試中的正確率超過了殘差網(wǎng)絡(luò).Xie 等[68] 提出的ResNeXt 借鑒了Inception 模塊的思想,通過增加旁路連接的數(shù)量以進(jìn)一步擴(kuò)寬網(wǎng)絡(luò),在不增加網(wǎng)絡(luò)復(fù)雜度的前提下提高識別準(zhǔn)確率,同時還減少了超參數(shù)的數(shù)量.
文獻(xiàn)[69]認(rèn)為殘差網(wǎng)絡(luò)僅僅是若干淺層網(wǎng)絡(luò)的組合體,其寬度相比于深度更為重要,訓(xùn)練超過50 層的網(wǎng)絡(luò)是毫無必要的,因此目前存在大量研究工作從網(wǎng)絡(luò)寬度出發(fā)優(yōu)化殘差網(wǎng)絡(luò)的結(jié)構(gòu).Zagoruyko 等[70] 認(rèn)為ResNet 在訓(xùn)練時無法充分地重用特征(Feature reuse),具體表現(xiàn)在梯度反向傳播時不能流經(jīng)每一個殘差模塊(Residual block),只有很少的殘差模塊可以學(xué)習(xí)到有用的特征表示.作者提出的寬殘差網(wǎng)絡(luò)(Wide residual network,WRN)通過增加網(wǎng)絡(luò)寬度并減少網(wǎng)絡(luò)深度,訓(xùn)練速度相較于殘差網(wǎng)絡(luò)提升了2 倍,但網(wǎng)絡(luò)層數(shù)減少了50 倍.Targ 等[71] 提出了一種將殘差網(wǎng)絡(luò)和標(biāo)準(zhǔn)卷積神經(jīng)網(wǎng)絡(luò)并行組合的泛化殘差網(wǎng)絡(luò),在保留有效特征表達(dá)的同時剔除了無效信息,改善了網(wǎng)絡(luò)的表達(dá)能力,在CIFAR-100 數(shù)據(jù)集上效果顯著.Zhang等[72] 為殘差網(wǎng)絡(luò)添加額外的旁路連接,通過增加寬度以提高網(wǎng)絡(luò)的學(xué)習(xí)能力,提出的Residual networks of residual networks (RoR)可以作為構(gòu)造網(wǎng)絡(luò)的通用模塊.Abdi 等[73]通過實(shí)驗(yàn)支持了殘差網(wǎng)絡(luò)是若干淺層網(wǎng)絡(luò)融合得到的假說,作者提出的模型通過增加殘差模塊中殘差函數(shù)的數(shù)量以增強(qiáng)模型的表達(dá)能力,得到的多殘差網(wǎng)絡(luò)在CIFAR-10 和CIFAR-100 的分類準(zhǔn)確率均得到極大改善.
4.4 其他精細(xì)模塊
在網(wǎng)絡(luò)結(jié)構(gòu)的設(shè)計(jì)空間探索方面,還有大量工作針對精細(xì)模塊設(shè)計(jì)展開研究,取得了一系列成果.為減少全連接層的訓(xùn)練參數(shù),文獻(xiàn)[55]首先提出用全局均值池化(Global average pooling,GAP)替代全連接層,相當(dāng)于在整個網(wǎng)絡(luò)結(jié)構(gòu)上做正則化防止過擬合.全局均值池化在特征圖與輸出類別標(biāo)簽之間建立聯(lián)系,相比于全連接層更具有可解釋性,隨后的網(wǎng)中網(wǎng)以及GoogLeNet 都采用這一結(jié)構(gòu)獲得了性能提升.
Huang 等[74] 認(rèn)為極深網(wǎng)絡(luò)的成功來源于旁路連接的引入,他們提出的密集模塊(Dense block)在任何兩層網(wǎng)絡(luò)之間都有直接連接.對于任意網(wǎng)絡(luò)層,它的輸入來源于前面所有網(wǎng)絡(luò)層的輸出,而它的輸出都要作為后面所有網(wǎng)絡(luò)層的輸入.這種密集連接改善了網(wǎng)絡(luò)中信息與梯度的流動,對于網(wǎng)絡(luò)具有正則化的作用,避免在小數(shù)據(jù)集上訓(xùn)練的過擬合問題.密集連接的另一個優(yōu)點(diǎn)是允許特征重用,訓(xùn)練出來的DenseNet 具有結(jié)構(gòu)緊湊、精度高的優(yōu)點(diǎn).張婷等[75] 提出的跨連卷積神經(jīng)網(wǎng)絡(luò)允許第二個池化層跨過兩層直接與全連接層相連接,在10 個人臉數(shù)據(jù)集上的性別分類效果都不低于傳統(tǒng)網(wǎng)絡(luò).李勇等[76]將LeNet-5 網(wǎng)絡(luò)的兩個池化層與全連接層相結(jié)合,構(gòu)造的分類器結(jié)合了網(wǎng)絡(luò)結(jié)構(gòu)提取的低層次特征與高層次特征,在人臉表情識別中取得較好效果.
Howard 等[77]提出的MobileNet 將傳統(tǒng)卷積過程分解為深度可分離卷積(Depthwise convolution)和逐點(diǎn)卷積(Pointwise convolution)兩步,在模型大小和計(jì)算量上都進(jìn)行了大量壓縮,由此構(gòu)造的輕量型網(wǎng)絡(luò)能夠在移動嵌入式設(shè)備上運(yùn)行.Sandler等[78]將殘差模塊與深度可分離卷積相結(jié)合,提出了帶有線性瓶頸的反向殘差模塊(Inverted residual with linear bottleneck),由此構(gòu)造的MobileNet v2在速度和準(zhǔn)確性上都優(yōu)于MobileNet.Zhang 等[79]在MobileNet 的基礎(chǔ)上進(jìn)一步提出了基于逐點(diǎn)群卷積(Pointwise group convolution)和通道混洗(Channel shuffle)的ShuffleNet,在圖像分類和目標(biāo)檢測任務(wù)中均獲得極大提速.
5 結(jié)束語
隨著硬件條件的飛速發(fā)展和數(shù)據(jù)集規(guī)模的顯著增長,深度卷積神經(jīng)網(wǎng)絡(luò)目前已成為計(jì)算機(jī)視覺、語音識別、自然語言處理等研究領(lǐng)域的主流方法.具體地,更深的網(wǎng)絡(luò)層數(shù)增強(qiáng)了模型的非線性擬合能力,同時大規(guī)模數(shù)據(jù)增強(qiáng)了模型的泛化能力,而較高水平的硬件設(shè)施條件則保證了模型運(yùn)行所需要的計(jì)算能力和存儲要求.深度卷積神經(jīng)網(wǎng)絡(luò)已在諸多領(lǐng)域證明了強(qiáng)大的特征學(xué)習(xí)和表達(dá)能力,但高昂的時間復(fù)雜度和空間復(fù)雜度制約其在更廣闊領(lǐng)域的實(shí)施與應(yīng)用.在時間維度上,大型復(fù)雜網(wǎng)絡(luò)計(jì)算量巨大,在圖形處理單元(Graphic processing unit,GPU)加速運(yùn)算的支持下,仍不能滿足自動駕駛汽車等一些強(qiáng)實(shí)時場景的要求.在空間維度上,隨著模型規(guī)模日益龐大特別是網(wǎng)絡(luò)深度劇增,對模型的存儲提出了更高的要求,這制約了深度卷積神經(jīng)網(wǎng)絡(luò)在移動手機(jī)、嵌入式設(shè)備等資源受限環(huán)境的應(yīng)用.
為加快以卷積神經(jīng)網(wǎng)絡(luò)為代表的深度學(xué)習(xí)技術(shù)的推廣及應(yīng)用,進(jìn)一步強(qiáng)化在安防、移動設(shè)備、自動駕駛等多個行業(yè)的優(yōu)勢,學(xué)術(shù)界和工業(yè)界對其結(jié)構(gòu)的優(yōu)化展開了大量研究.現(xiàn)階段常用的網(wǎng)絡(luò)結(jié)構(gòu)優(yōu)化技術(shù)包括網(wǎng)絡(luò)剪枝與稀疏化、張量分解、知識遷移和精細(xì)模塊設(shè)計(jì),前三種方法通常是在已有高性能模型的基礎(chǔ)上改進(jìn)并加以創(chuàng)新,在不損害精度甚至有所提高的前提下盡可能降低模型復(fù)雜度和計(jì)算復(fù)雜度.精細(xì)模塊設(shè)計(jì)方法從網(wǎng)絡(luò)構(gòu)造的角度出發(fā),創(chuàng)造性地設(shè)計(jì)高效模塊以提升網(wǎng)絡(luò)性能,從根本解決深度卷積神經(jīng)網(wǎng)絡(luò)面臨的時間復(fù)雜度和空間復(fù)雜度過高的問題.筆者整理了近幾年的研究成果,根據(jù)自己的理解總結(jié)了該領(lǐng)域以下的難點(diǎn)問題以及發(fā)展趨勢:
1)網(wǎng)絡(luò)剪枝與稀疏化能夠穩(wěn)定地優(yōu)化并調(diào)整網(wǎng)絡(luò)結(jié)構(gòu),以較小精度損失的代價(jià)壓縮網(wǎng)絡(luò)規(guī)模,是應(yīng)用最為廣泛的網(wǎng)絡(luò)結(jié)構(gòu)優(yōu)化設(shè)計(jì)方法.目前大多數(shù)的方法是剔除網(wǎng)絡(luò)中冗余的連接或神經(jīng)元,這種低層級的剪枝具有非結(jié)構(gòu)化(Non-structural)風(fēng)險(xiǎn),在計(jì)算機(jī)運(yùn)行過程中的非正則化(Irregular)內(nèi)存存取方式反而會阻礙網(wǎng)絡(luò)進(jìn)一步加速.一些特殊的軟硬件措施能夠緩解這一問題,然而會給模型的部署帶來額外的花銷.另一方面,盡管一些針對卷積核和卷積圖的結(jié)構(gòu)化剪枝方法能夠獲得硬件友好型網(wǎng)絡(luò),在CPU 和GPU 上速度提升明顯,但由于剪枝卷積核和卷積通道會嚴(yán)重影響下一隱含層的輸入,有可能存在網(wǎng)絡(luò)精度損失嚴(yán)重的問題.
2)目前主流的精細(xì)模塊設(shè)計(jì)方法仍然依賴于設(shè)計(jì)者的工程經(jīng)驗(yàn)和理論基礎(chǔ),在網(wǎng)絡(luò)構(gòu)造過程中要考慮到大量因素,如卷積核尺寸、全連接層數(shù)、池化層數(shù)等超參數(shù)(Hyper parameter).不同的選擇對于網(wǎng)絡(luò)最終性能有可能造成完全不同的影響,需要進(jìn)行大量的實(shí)驗(yàn)來論證不同參數(shù)的優(yōu)劣,使得網(wǎng)絡(luò)結(jié)構(gòu)設(shè)計(jì)耗費(fèi)大量的人力物力,不利于深度模型的快速部署及應(yīng)用.因此,研究如何自動設(shè)計(jì)網(wǎng)絡(luò)有助于卷積神經(jīng)網(wǎng)絡(luò)的設(shè)計(jì)空間探索(Design space exploration,DSE),對于加快網(wǎng)絡(luò)設(shè)計(jì)過程和推動深度學(xué)習(xí)落地于工程化應(yīng)用具有重要的促進(jìn)作用.
3)網(wǎng)絡(luò)結(jié)構(gòu)優(yōu)化設(shè)計(jì)的評價(jià)指標(biāo).目前對于深度卷積神經(jīng)網(wǎng)絡(luò)的結(jié)構(gòu)優(yōu)化設(shè)計(jì)主要側(cè)重于準(zhǔn)確率、運(yùn)行時間、模型大小等方面的評價(jià),但使用更加全面的評價(jià)指標(biāo)對于發(fā)現(xiàn)不同網(wǎng)絡(luò)的優(yōu)點(diǎn)和缺點(diǎn)是大有裨益的.除了準(zhǔn)確率、運(yùn)行時間、模型大小等傳統(tǒng)指標(biāo),有必要將乘加(Multiply-and-accumulate)操作量、推導(dǎo)時間、數(shù)據(jù)吞吐量、硬件能耗等指標(biāo)納入評價(jià)體系,這為從不同方面評價(jià)優(yōu)化模型提供了更加完備的信息,也有助于解決了不同網(wǎng)絡(luò)性能評價(jià)指標(biāo)不統(tǒng)一的問題.
4)在過去,深度卷積神經(jīng)網(wǎng)絡(luò)的結(jié)構(gòu)優(yōu)化更多著眼于算法的設(shè)計(jì)與實(shí)現(xiàn),而對于模型的具體部署平臺和硬件設(shè)施欠缺考慮.考慮到硬件條件仍是制約著深度模型部署于移動手機(jī)、機(jī)器人、自動駕駛等資源受限場景下的主要因素,若統(tǒng)籌兼顧網(wǎng)絡(luò)模型和硬件設(shè)施的優(yōu)化與設(shè)計(jì),使算法與硬件相匹配,不僅能夠進(jìn)一步提高數(shù)據(jù)吞吐量與運(yùn)行速度,還可以減少網(wǎng)絡(luò)規(guī)模與能耗.因此,設(shè)計(jì)硬件友好型深度模型將有助于加速推進(jìn)深度學(xué)習(xí)的工程化實(shí)現(xiàn),也是網(wǎng)絡(luò)結(jié)構(gòu)優(yōu)化的重點(diǎn)研究方向.
5)本文歸納與總結(jié)的網(wǎng)絡(luò)結(jié)構(gòu)優(yōu)化方法有不同的側(cè)重點(diǎn)和局限性,其中網(wǎng)絡(luò)剪枝與稀疏化方法能夠獲得較大的壓縮比,同時對于網(wǎng)絡(luò)精度的影響較小,在需要模型穩(wěn)定運(yùn)行的場景下較為適用.張量分解能夠極大加速模型的運(yùn)行過程,而且端到端的逐層優(yōu)化方式也使其容易實(shí)施,然而該方法不能較好地壓縮模型規(guī)模,而且在卷積核尺寸較小時加速效果不明顯.知識遷移方法能夠利用教師網(wǎng)絡(luò)的領(lǐng)域知識指導(dǎo)學(xué)生網(wǎng)絡(luò)的訓(xùn)練,在小樣本環(huán)境下有較高的使用價(jià)值.同時,知識遷移和精細(xì)模塊設(shè)計(jì)都面臨網(wǎng)絡(luò)結(jié)構(gòu)如何構(gòu)造的問題,要求設(shè)計(jì)者具有較高的理論基礎(chǔ)和工程經(jīng)驗(yàn),與其他方法相比其調(diào)試周期較長.因此,在使用網(wǎng)絡(luò)結(jié)構(gòu)優(yōu)化技術(shù)時應(yīng)考慮實(shí)際情況,綜合應(yīng)用以上方法以壓縮并加速網(wǎng)絡(luò).
6)深度神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)優(yōu)化的遷移應(yīng)用.本文分析了卷積神經(jīng)網(wǎng)絡(luò)目前存在的挑戰(zhàn)和問題,并且探討了卷積神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)優(yōu)化領(lǐng)域的主流方法、思想及其應(yīng)用.由于目前其他主流的深度網(wǎng)絡(luò)(如循環(huán)神經(jīng)網(wǎng)絡(luò)、生成對抗網(wǎng)絡(luò))同樣面臨模型規(guī)模大、運(yùn)行速度慢的問題,因此借鑒卷積神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)優(yōu)化的思想以優(yōu)化其模型是一種有效的解決方式.此外,目前很多優(yōu)化方法一般都是針對圖像分類問題,若將其應(yīng)用于目標(biāo)檢測、語義分割等領(lǐng)域也應(yīng)取得較好效果.
審核編輯:湯梓紅














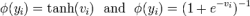







 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論