 電子發燒友App
電子發燒友App


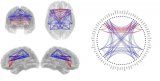
隨著近幾年深度學習、神經科學、數字孿生和量子計算的迅速發展,人工智能成為了無論學術界還是互聯網領域的一個重要的研究熱點。然而,人類在認識世界和改造世界的過程中從自然界和生物特征汲取了大量的靈感和經驗。追根溯源,人工智能的發展離不開腦科學的研究。歷史上,神經科學和人工智能兩個領域一直存在交叉,對生物腦更好的理解,將對智能機器的建造起到及其重要的作用。
人工智能是模擬腦的一項主要應用,現在深度學習這種生物學簡化的模型有其優點:具有很好的數學解釋性,可以在現有的計算機架構(馮諾依曼)上實現,但是同樣有瓶頸。如:計算代價高,不利于硬件實現等。盡管近年來深度學習和大數據的出現使得模型在一些任務上超越人類,但是對于人腦可以處理的復雜問題卻無能為力,同時需要大量的計算資源和數據資源作為支撐。
相反人類大腦是一個極度優化的系統,它的工作耗能僅為25瓦,神經元的數量卻在10的11次方的數量級上(其中的突觸達到每個神經元10000個)。這樣龐大的網絡卻有如此低的能耗,使得人類大腦在復雜問題的處理有絕對優勢。
因此,人們希望能模仿人腦的工作方式來處理信息,構建神經網絡模型,成為了模擬腦的關鍵。類腦計算這一個研究方向逐漸受到各個國家的重視,例如歐盟在2013年將“人腦計劃”納入其未來旗艦技術項目,2013年4月2日,美國總統奧巴馬宣布啟動名為“通過推動創新型神經技術開展大腦研究(Brain Research through Advancing Innovative Neurotechnologies)”計劃,簡稱為腦科學研究計劃(BRAIN),以及中國在2017年提出的“一體兩翼”的腦科學與類腦科學研究,可以看到腦科學研究尤其是類腦計算將是繼深度學習之后的又一大人工智能的突破點。目前許多國家專門成立腦科學研究中心,例如哥倫比亞大學的基礎腦科學研究中心,清華大學類腦計算研究中心等。
類腦計算是什么?
類腦計算是近年來新興的研究領域。它類似于人工智能、機器學習等領域,很難準確定義。目前,業界還沒有普遍認可的類腦計算定義。類腦計算的描述性定義是“受人腦信息處理方式啟發,以更通用的人工智能和高效智能邊緣端、云端為目標構建信息系統的技術總稱”。類腦計算整合腦科學、計算神經科學、認知科學甚至統計物理的知識來解決現有傳統計算技術的一些問題,進而構建更通用、高效、智能的新型信息系統。
?
狹義的類腦計算是指神經形態計算,主要是開發神經形態芯片支持來自計算神經科學的脈沖神經網絡(SNN)。廣義的類腦計算還包括內存計算、憶阻器芯片甚至支持傳統人工神經網絡(ANN)的人工智能芯片的開發。所以類腦計算的研發和人工智能一樣,需要從模型算法、軟件、芯片、數據等各個方向協同。
?
類腦計算模型
突破神經科學與AI的鴻溝
目前,神經科學和人工智能之間存在巨大的差距。神經科學側重于重建大腦內部的精細結構和生理細節,而人工智能側重于通過數學抽象神經結構來實現高計算的高效率。
?
因此,如何將人工智能和神經科學交叉很好地融合成為一個艱巨的挑戰。在類腦計算中,脈沖神經網絡兼具生物合理性和計算效率,或能為人工智能提供新范式。簡單來說,可以認為SNN = ANN+Neuronal Dynamics。如何找到一個兼具生物合理性和計算效率的脈沖神經元模型,如何建立脈沖神經元模型與AI任務之間的關系,是類腦計算領域的核心問題。
目前,SNN一般使用LIF神經元作為構建神經網絡的基本單位。原因是LIF神經元是一個典型的綜合模型,不僅具有IF模型的簡單性,還能像H-H神經元模型一樣模擬生物神經元豐富的生理特性。
眾所周知,ANN和SNN各有特色和長處。ANN能夠充分利用現有計算機的計算特性,以神經元狀態表達信息,在空間領域傳遞信息,其主要運算是稠密矩陣向量乘法。相比之下,SNN使用脈沖序列在空間域和時間域表達信息和傳遞信息,其主要操作是事件驅動的稀疏加法,既有計算效率又有生物可信度。
類腦學習算法
與ANN訓練相比,SNN的有效訓練面臨許多問題和挑戰。如脈沖神經元內復雜的時空動態過程、脈沖神經元間傳遞的非導數脈沖信息、脈沖退化和訓練精度損失等。目前,SNN訓練方法主要包括無監督學習、間接監督學習和直接監督學習。這些訓練方法試圖從不同角度解決上述問題和挑戰。
一、基于STDP的無監督學習
脈沖時間相關突觸可塑性(STDP)是一種典型的無監督學習方法,可以控制大腦神經元之間權重連接的更新。一般來說,兩個神經元的放電時間越接近,它們之間的綁定關系就越緊密。如上圖所示,當兩個神經元相繼被激活時,順序關系緊密的兩邊會加強連接,相反關系的兩邊會減弱連接。所以神經元之間往往建立單向的強化連接。
如果兩個神經元同時被激活,就與共同的下游神經元形成了更緊密的聯系,這樣它們就是同級神經元,彼此之間存在間接關系。例如,由STDP規則和WTA規則組成的學習模型就是一種簡單有效的無監督學習方法。具體來說,在輸入層,畫面被轉換成脈沖序列(脈沖發射率與像素值成正比)。
神經元以全連接方式向前連接,接收興奮輸入,并根據STDP規則進行更新。它們與抑制性神經元向后一對一連接,產生側抑制(即軟WTA),脈沖發放率由適應性閾值平衡。
STDP模型通過調整局部規則來學習,易于在神經形態芯片上分布式實現,具有在線學習的能力。但局部突觸可塑性不足以解釋單個突觸的變化如何協調神經系統整體目標的實現。這種無監督學習訓練方法存在一些問題,如:難以獲得高性能網絡,無法用于大規模深度神經網絡。
二、基于ANN轉SNN的間接有監督學習
神經網絡轉換的SNN方法是指訓練一個神經網絡模型,然后將學習到的神經網絡權重轉移到具有相同結構的SNN。其基本思想是用SNN的平均脈率來近似神經網絡中的ReLU激活值。
因此,人工神經網絡轉換的SNN方法在模型精度和模型模擬步驟T之間有一個折衷問題。該方法利用監督信號在原始神經網絡模型中訓練梯度反向傳播,然后將其轉化為SNN模型,因此是一種間接的監督學習。
人工神經網絡轉換的SNN方法具有很強的可擴展性,很容易將新的或大規模的人工神經網絡結構轉換成相應的SNN版本。一般情況下,模擬時間步長T越大,SNN的平均脈率越接近ANN中的激活值,兩個模型之間的誤差越小,從而實現ANN-SNN的幾乎無損轉換。但時間步長T過長會導致訓練和推理效率下降,SNN的功耗優勢也會降低。
三、SNN直接有監督學習的發展
直接訓練算法的難點在于SNN復雜的時空動力學和脈沖發射的不可微性問題。將脈沖神經元的微分方程形式轉化為便于計算機模擬的差分方程形式,同時沿空間和時間維度擴展信息,采用脈沖梯度近似法。由于近似替代函數保留了脈沖發射的“非線性特性”,其梯度近似曲線具有一定的魯棒性。
STBP雖然解決了SNN網絡反向傳播訓練的梯度替代問題,但只能訓練不超過10層的小規模網絡。主要問題是:網絡一旦深入,與ANN相比,脈沖神經元的二元激活方式及其復雜的時空動態更容易造成網絡的梯度消失或爆炸。
通過進一步分析SNN的時空動態特性可以看出,為了獲得合適的網絡脈沖率,在神經元膜電位和閾值之間建立平衡對于網絡的性能是非常重要的。過低的分發率可能導致有效信息不足,而過高的分發率會降低SNN網絡對輸入的區分度。
因此,結合脈沖神經元閾值的BN算法,即閾值依賴BN方法(TDBN),緩解了SNN的規模瓶頸。首次將SNN的網絡規模提升到50層,在ImageNet等大規模數據集上取得具有競爭力的性能,并證明該方法可以緩解深度SNN的梯度消失和爆炸。
雖然TDBN增加了SNN的規模,但與傳統的數百層深度網絡相比,其性能仍不足以在大規模數據集上與ANN抗衡。為了進一步提高SNN的網絡表達能力,擴大網絡規模,提高任務性能,借鑒經典的ResNet結構似乎是一種可行的方法。
但是將ResNet結構直接復制到SNN (Vanilla Res-SNN)中存在脈沖退化的問題,即網絡越深,精度越低。因此,一種新的Ms-Rse-SNN結構被提出,其中LIF神經元被置于殘余塊中,不同層神經元的膜電位被縮短。利用動態均勻性理論證明該結構不存在脈沖退化問題。在較大范圍內解決了大規模SNN直接訓練問題(482層CIFAR-10,104層ImageNet),后者取得76%分類準確率TOP-1的SOTA結果。
此外,根據SNN處理數據的不同,采用數據相關的處理模式可以為直接訓練SNN的某些任務帶來額外的性能增益。如:在神經形態學視覺的任務中,事件流數據往往是稀疏和不均勻的。
根據事件流在不同時刻的輸入信噪比,結合時間注意力機制,使用SNN以數據驅動的方式處理任務,進一步降低網絡能耗,提高性能。實驗結果表明,即使去掉一半的輸入,SNN的性能也能基本保持不變或略有提高。總之,SNN已經進入大規模深度模型和算法的開發階段,并將進一步應用于傳統人工智能領域的諸多下游任務。
?
類腦計算軟件
類腦計算軟件框架和工具通常包括三個方面:神經形態學芯片工具鏈、神經系統仿真模擬和SNN學習框架。
目前神經芯片的工具鏈還處于早期階段,存在軟硬件耦合緊密、通用性和自動化程度低、使用便捷性差等諸多問題。神經系統軟件模擬框架可以詳細模擬生物神經網絡,但需要用戶具有一定的計算神經科學基礎。
現有仿真工具軟件框架通常采用C語言開發,缺乏跨平臺能力和對各種后端硬件的深度優化支持。而且這些軟件通常是為CPU、GPU等商用硬件設計,不支持不同類型的神經形態芯片。SNN學習框架的目標是結合深度學習框架開發的便利和SNN特點,充分利用深度學習領域的各種資源,加速SNN網絡訓練。相關工作基本處于早期且不夠穩定,無法適應不同的軟硬件接口。即使是基于GPU架構開發,也很難充分利用SNN自身的特點來加速。
類腦計算芯片
從功能上看,類腦芯片主要四類:
人工神經網絡的深度學習加速器(TPU、寒武紀、華為升騰等);
脈沖神經網絡的神經形態學芯片(TrueNorth、Loihi、達爾文等芯片);
人工/脈沖神經網絡的異構融合芯片(天機芯片);
大腦模擬芯片(SpiNNaker,ROLLS,Loihi等。)支持以低延遲、高動態的神經形態學相機為代表的神經元編程和感知芯片。
類腦芯片的架構包括主流深度學習加速器采用的存儲-存儲分離架構,主流眾核分散架構芯片的近存計算架構,以及內存計算芯片和憶阻器芯片采用的存儲-計算一體化架構。從芯片設計的角度來看,路由器連接的多核架構芯片具有更好的可擴展性,多個功能核獨立工作,核之間定期同步共享數據。因此可以支持更大網絡規模和更廣應用范圍的SNN。
使用純數字信號的小規模單核芯片可以通過內存計算進行矩陣向量乘法,具有同步和異步設計流程,往往具有更高的能效和更低的靜態功耗,更便于技術移植,但神經元和突觸的規模有限。數模混合的小規模單核芯片采用數字異步脈沖路由,使用內存中數字計算方法進行矩陣向量乘法,使用模擬膜電位進行激活和更新,因此能效最高,但也存在神經元和突觸數量少、設計不方便等問題。
類腦計算數據
眾所周知,深度學習發展四要素為算法、算力、開發工具以及大規模的數據。在深度學習領域,成百上千個開源數據集覆蓋分類、檢測、跟蹤、自然語言等,極大地促進了深度學習的繁榮。
相比之下,類腦數據集十分匱乏,現有的數據集主要包括四類:
一、通過轉換算法將ANN數據集轉變為事件信號數據集,典型數據集包括基于ImageNet轉換而來的ES-ImageNet,基于UCF101轉化的事件信號數據集ES-UCF101,基于BDD100K轉化的事件信號數據集BDD100K-DVS等;
二、利用神經形態相機DVS將圖像或視頻數據庫轉化為事件數據集,比如N-MNIST、CIFA10-DVS等數據集;
三、通過神經形態相機DVS直接拍攝獲取的數據集,比如DVS-Gesture、PKU-DDD17-CAR、Gen1 Detection、1Mpx Detection、PKU-DAVIS-SOD等;
四、其它類型的類腦數據集,比如EEG數據集、腦機接口(BCI)相關的數據集、幀數據和事件的混合數據等。
類腦計算的未來:
在學科交叉與突破創新中
蓬勃發展
模型算法方面
?
不僅可以通過增加模型參數、網絡深度或寬度使得SNN模型變大變強,更重要的提供向內增加神經元復雜程度的能力支撐,縮減神經科學與人工智能之間存在的鴻溝。因此,構造包含更豐富動力學的神經元模型、神經網絡及對應的算法是未來的重要方向。
?
類腦軟件方面
如何提升SNN的研究生態是未來發展的必經之路,重要的方向包括神經形態工具鏈的軟硬件去耦合、SNN訓練加速框架及高效的神經系統仿真和模擬等。在類腦數據方面,如何構建具備稀疏事件特征、具備豐富的時間尺度/空間尺度特征的大規模多模態混合數據集十分重要。
類腦芯片方面
主要關注神經形態芯片如何進行更高效的感知、存儲和計算,如何構建融合感存算一體化的計算系統。研究更高效的芯片架構、研制更具有類腦元素的芯片功能也是未來發展的重要方向。芯片架構上可以探索類腦芯片的分層存儲體系、高效在線學習架構及與其它硬件平臺的高效兼容能力;芯片功能上可以探索如何融入更多的算子支持比如微分方程、線性方程求解,以及如何在算子層面上支持更類腦的神經元模型和網絡結構等。
類腦系統的總體框架包括類腦的模型、算法、軟件以及芯片,并結合豐富類腦數據構造的計算系統,在人工智能領域可以朝著高效云端/邊緣端類腦計算系統的構造方向發展,在腦科學領域可利用現有的超算服務器集群進行神經動力學的仿真和模擬,構建更為復雜的腦仿真和神經模擬系統。
中國類腦計算的研究成果
我國的類腦智能研究水平處于國際前沿。2016年,“腦科學與類腦科學研究”(簡稱“中國腦計劃”)被作為連接腦科學和信息科學的橋梁正式提出。此外,多所高校也積極參與類腦計算的研究。其中,中科院開發的類腦認知引擎平臺能夠模仿哺乳動物的大腦,實現多感覺融合、決策等多種功能。
?
中國科學家研制出新型類腦計算芯片
我國科學家研制成功面向人工通用智能的新型類腦計算芯片——“天機芯”芯片,而且成功在無人駕駛自行車上進行了實驗。清華大學類腦計算研究中心施路平教授團隊的相關論文《面向人工通用智能的異構“天機芯”芯片架構》,曾在國際期刊《自然》雜志以封面文章的形式發表。
世界首款多陣列憶阻器存算一體系統誕生
清華大學微電子所、未來芯片技術高精尖創新中心錢鶴、吳華強教授團隊,與合作者共同研發出一款基于多個憶阻器陣列的存算一體系統,在處理卷積神經網絡時的能效,比圖形處理器芯片高兩個數量級,大幅提升計算設備的算力,且比傳統芯片的功耗降低100倍,相關成果發表于《自然》。
?
我科學家首次提出“類腦計算完備性”
清華大學計算機系張悠慧團隊和精儀系施路平團隊與合作者在《自然》雜志發表題為《一種類腦計算系統層次結構》的論文,填補了類腦計算系統領域完備性理論與相應的類腦計算系統層次結構方面的空白。
藍海大腦液冷散熱服務器可搭建NVIDIA 4 × A100 / 3090 / P6000 / RTX6000,并將液冷冷板固定在服務器的主要發熱器件上,依靠流經冷板的液體將熱量帶走達到散熱目的。冷板液冷解決了服務器里發熱量大的器件的散熱,其他散熱器件還得依靠風冷。所以采用冷板式液冷的服務器也稱為氣液雙通道服務器。冷板的液體不接觸被冷卻器件,中間采用導熱板傳熱,安全性高。
藍海大腦擁有完全自主研發和靈活定制能力,是國內最早從事液冷GPU服務器的廠商之一,并且在獨到的加固、保密和安全等產品技術領域有深厚的積累。藍海大腦端到端的解決方案,賦能AI、云計算、大數據、5G、區塊鏈、元宇宙等新興技術創新和應用,積極為中國類腦計算、新基建、信創、東數西算、社會經濟的數字化和智能化轉型升級提供堅實的算力保證。同時重視全球合作共贏,與英特爾、英偉達、希捷、華為、飛騰等國內外產業鏈伙伴保持緊密的戰略合作關系,加速產品方案的適配和應用場景拓展,更好地為各行各業服務。
審核編輯:符乾江














 工商網監
工商網監
評論