 電子發燒友App
電子發燒友App


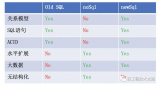
OLAP與OLTP數據庫由于關注的業務不同,所以軟件在工作方式和優化方法會有一些不同。
OLTP業務主要業務場景是交易記錄的準確性,因此需要寫入具有唯一性,所以傳統針對OLTP數據庫的優化方法將負責寫入的“一夫”節點性能大幅提升,如使用更快的CPU,增加更多的內存,使用將內存當做磁盤用的傲騰存儲,使用IB網絡(InfiniBand network)等。
但個體設備的配置提升,會遇到天花板。于是近年來有人提出將數據庫進行分庫分表,增加寫入節點的數量而提升寫入能力。通過將數據復制到多個只讀節點,提升數據讀的能力。
比如對于一個記錄用戶名數據庫,按姓名拼音的第一個字母拆成26個數據庫,這樣就可以將原來只能由一個庫來寫,變成分別由26個庫來寫入,從而提升寫入能力。但每個分開的庫還是只能有一個寫入,還是有種“一夫當關,萬夫莫開”的意思。
舉個例子說明,柏睿自研的分布式全內存數據庫RapidsDB是基于MPP并行計算架構,集群的性能隨著節點規模的增加而增加。RapidsDB的技術架構類似于“團體作戰”風格,所有的數據庫節點都能同時協同戰斗,因此提升的性能不是由個體決定的。例如在一個具有5個數據庫節點的RapidsDB集群里,用戶要導入1000T的數據文件任務,是由5個數據庫節點將1000T任務分散同時完成。如果性能不夠,再加數據庫節點就可以實現性能提升了。
以上分析,僅從技術架構而言,并不能完全說明哪種技術是最好。只有適合業務,才是最好的技術。
審核編輯:符乾江
































































 工商網監
工商網監
評論